spring的扫描一般可以通过两种方式:
测试类:
@Component
public class Scan_A {@PostConstructpublic void init(){System.out.println("-----------Scan_A");}}1)、@ComponentSscan注解
public class ComponentScanTest {public static void main(String[] args) {AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(ContextConfig.class);}
}配置类:(可配@Compnent,也可不配,都会生效)
@ComponentScan("com.spring.demo.scan")
public class ContextConfig {
}
启动此时控制台:
----------Scan_A
则表示扫描到了。
2)、使用api调用扫描
public class ApplicationContextTest {public static void main(String[] args) {AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext();context.scan("com.spring.demo.scan");context.refresh();}
}此时运行,照样能打印----------Scan_A
两种方法实例化了各自实例化了自己的扫描器,但最终都是调用doscan方法完成解析的。
(关于两种方式的区别,后面说明,不过我们最常用的应该就是第一种方式)
==========================我们先以第一种情况作为分析========================
上一篇文章中,invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors,registry)代码行中(情况2),ConfigurationClassPostProcessor执行了其子接口实现类。我们说到这个实现类完成对注解类的扫描。我们就以此为入口。
调用链:ConfigurationClassPostProcessor#postProcessBeanDefinitionRegistry(子接口实现方法)
--------》processConfigBeanDefinitions(registry)
/*** ConfigurationClassPostProcessor实现了BeanDefinitionRegistryPostProcessor接口的实现类* 功能:完成对注解的扫描解析,并放入BeanDefinitionMap(此时未进行实例化为bean,应为采用的是ASM字节码技术,所以不会在这里实例化)* registry------容器对象* *//*** Build and validate a configuration model based on the registry of* {@link Configuration} classes.*/public void processConfigBeanDefinitions(BeanDefinitionRegistry registry) {List<BeanDefinitionHolder> configCandidates = new ArrayList<>();//获取内置的+我们提供的配置类的BeanDefinition名称String[] candidateNames = registry.getBeanDefinitionNames();for (String beanName : candidateNames) {BeanDefinition beanDef = registry.getBeanDefinition(beanName);//判断是否已经被解析了if (beanDef.getAttribute(ConfigurationClassUtils.CONFIGURATION_CLASS_ATTRIBUTE) != null) {if (logger.isDebugEnabled()) {logger.debug("Bean definition has already been processed as a configuration class: " + beanDef);}}//判断配置类是全配置类(除了用@CompnentScan注解外还用了@Compnent)或者半配置类(只用了@CompnentScan)//是则加入集合(我们这里一般会有6个配置类,5个内置的+1个我们提供的(当然我们可以提供多个,不过一般是一个)// 此时只有我们提供配置类有用到@CompnentScan,所以这里只会加入一个else if (ConfigurationClassUtils.checkConfigurationClassCandidate(beanDef, this.metadataReaderFactory)) {configCandidates.add(new BeanDefinitionHolder(beanDef, beanName));}}// Return immediately if no @Configuration classes were foundif (configCandidates.isEmpty()) {return;}//排序,由于一般情况下是一个,所以没什么影响// Sort by previously determined @Order value, if applicableconfigCandidates.sort((bd1, bd2) -> {int i1 = ConfigurationClassUtils.getOrder(bd1.getBeanDefinition());int i2 = ConfigurationClassUtils.getOrder(bd2.getBeanDefinition());return Integer.compare(i1, i2);});//获取Bean名称的生成策略// Detect any custom bean name generation strategy supplied through the enclosing application contextSingletonBeanRegistry sbr = null;if (registry instanceof SingletonBeanRegistry) {sbr = (SingletonBeanRegistry) registry;if (!this.localBeanNameGeneratorSet) {BeanNameGenerator generator = (BeanNameGenerator) sbr.getSingleton(AnnotationConfigUtils.CONFIGURATION_BEAN_NAME_GENERATOR);if (generator != null) {this.componentScanBeanNameGenerator = generator;this.importBeanNameGenerator = generator;}}}//环境变量if (this.environment == null) {this.environment = new StandardEnvironment();}//实例化一个配置类的解析器//此时构造方法传入一个componentScanBeanNameGenerator----类型AnnotationBeanNameGenerator(即一个Bean的名称生成策略)// Parse each @Configuration classConfigurationClassParser parser = new ConfigurationClassParser(this.metadataReaderFactory, this.problemReporter, this.environment,this.resourceLoader, this.componentScanBeanNameGenerator, registry);//去重Set<BeanDefinitionHolder> candidates = new LinkedHashSet<>(configCandidates);Set<ConfigurationClass> alreadyParsed = new HashSet<>(configCandidates.size());//开始循环解析配置类do {//调用parse方法进行解析parser.parse(candidates);parser.validate();Set<ConfigurationClass> configClasses = new LinkedHashSet<>(parser.getConfigurationClasses());configClasses.removeAll(alreadyParsed);// Read the model and create bean definitions based on its contentif (this.reader == null) {this.reader = new ConfigurationClassBeanDefinitionReader(registry, this.sourceExtractor, this.resourceLoader, this.environment,this.importBeanNameGenerator, parser.getImportRegistry());}this.reader.loadBeanDefinitions(configClasses);alreadyParsed.addAll(configClasses);candidates.clear();if (registry.getBeanDefinitionCount() > candidateNames.length) {String[] newCandidateNames = registry.getBeanDefinitionNames();Set<String> oldCandidateNames = new HashSet<>(Arrays.asList(candidateNames));Set<String> alreadyParsedClasses = new HashSet<>();for (ConfigurationClass configurationClass : alreadyParsed) {alreadyParsedClasses.add(configurationClass.getMetadata().getClassName());}for (String candidateName : newCandidateNames) {if (!oldCandidateNames.contains(candidateName)) {BeanDefinition bd = registry.getBeanDefinition(candidateName);if (ConfigurationClassUtils.checkConfigurationClassCandidate(bd, this.metadataReaderFactory) &&!alreadyParsedClasses.contains(bd.getBeanClassName())) {candidates.add(new BeanDefinitionHolder(bd, candidateName));}}}candidateNames = newCandidateNames;}}while (!candidates.isEmpty());// Register the ImportRegistry as a bean in order to support ImportAware @Configuration classesif (sbr != null && !sbr.containsSingleton(IMPORT_REGISTRY_BEAN_NAME)) {sbr.registerSingleton(IMPORT_REGISTRY_BEAN_NAME, parser.getImportRegistry());}if (this.metadataReaderFactory instanceof CachingMetadataReaderFactory) {// Clear cache in externally provided MetadataReaderFactory; this is a no-op// for a shared cache since it'll be cleared by the ApplicationContext.((CachingMetadataReaderFactory) this.metadataReaderFactory).clearCache();}}
进入parser.parse(candidates)---》parse()-----》processConfigurationClass()
protected void processConfigurationClass(ConfigurationClass configClass, Predicate<String> filter) throws IOException {if (this.conditionEvaluator.shouldSkip(configClass.getMetadata(), ConfigurationPhase.PARSE_CONFIGURATION)) {return;}//查看缓存是否存在(每解析完一个配置类会放进缓存)ConfigurationClass existingClass = this.configurationClasses.get(configClass);if (existingClass != null) {if (configClass.isImported()) {if (existingClass.isImported()) {existingClass.mergeImportedBy(configClass);}// Otherwise ignore new imported config class; existing non-imported class overrides it.return;}else {// Explicit bean definition found, probably replacing an import.// Let's remove the old one and go with the new one.this.configurationClasses.remove(configClass);this.knownSuperclasses.values().removeIf(configClass::equals);}}// Recursively process the configuration class and its superclass hierarchy.SourceClass sourceClass = asSourceClass(configClass, filter);do {//解析配置类sourceClass = doProcessConfigurationClass(configClass, sourceClass, filter);}while (sourceClass != null);this.configurationClasses.put(configClass, configClass);}进入doProcessConfigurationClass()
@Nullableprotected final SourceClass doProcessConfigurationClass(ConfigurationClass configClass, SourceClass sourceClass, Predicate<String> filter)throws IOException {//解析配置类是否加了@Compnent注解if (configClass.getMetadata().isAnnotated(Component.class.getName())) {// Recursively process any member (nested) classes first//如果加了,则处理内部类processMemberClasses(configClass, sourceClass, filter);}//处理配置类@propertySource注解(读取文件)// Process any @PropertySource annotationsfor (AnnotationAttributes propertySource : AnnotationConfigUtils.attributesForRepeatable(sourceClass.getMetadata(), PropertySources.class,org.springframework.context.annotation.PropertySource.class)) {if (this.environment instanceof ConfigurableEnvironment) {processPropertySource(propertySource);}else {logger.info("Ignoring @PropertySource annotation on [" + sourceClass.getMetadata().getClassName() +"]. Reason: Environment must implement ConfigurableEnvironment");}}//解析@ComponentScan注解(@ComponentScans即可扫描多个包)// Process any @ComponentScan annotationsSet<AnnotationAttributes> componentScans = AnnotationConfigUtils.attributesForRepeatable(sourceClass.getMetadata(), ComponentScans.class, ComponentScan.class);if (!componentScans.isEmpty() &&!this.conditionEvaluator.shouldSkip(sourceClass.getMetadata(), ConfigurationPhase.REGISTER_BEAN)) {//配置类存在@ComponentScan或@ComponentScans注解for (AnnotationAttributes componentScan : componentScans) {//解析这个@ComponentScan注解,完成对@Compnent注解的扫描,并返回Set<BeanDefinitionHolder>// The config class is annotated with @ComponentScan -> perform the scan immediatelySet<BeanDefinitionHolder> scannedBeanDefinitions =this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName());// Check the set of scanned definitions for any further config classes and parse recursively if neededfor (BeanDefinitionHolder holder : scannedBeanDefinitions) {BeanDefinition bdCand = holder.getBeanDefinition().getOriginatingBeanDefinition();if (bdCand == null) {bdCand = holder.getBeanDefinition();}if (ConfigurationClassUtils.checkConfigurationClassCandidate(bdCand, this.metadataReaderFactory)) {parse(bdCand.getBeanClassName(), holder.getBeanName());}}}}//解析@Import// Process any @Import annotationsprocessImports(configClass, sourceClass, getImports(sourceClass), filter, true);//解析@ImportResource // Process any @ImportResource annotationsAnnotationAttributes importResource =AnnotationConfigUtils.attributesFor(sourceClass.getMetadata(), ImportResource.class);if (importResource != null) {String[] resources = importResource.getStringArray("locations");Class<? extends BeanDefinitionReader> readerClass = importResource.getClass("reader");for (String resource : resources) {String resolvedResource = this.environment.resolveRequiredPlaceholders(resource);configClass.addImportedResource(resolvedResource, readerClass);}}//解析@Bean// Process individual @Bean methodsSet<MethodMetadata> beanMethods = retrieveBeanMethodMetadata(sourceClass);for (MethodMetadata methodMetadata : beanMethods) {configClass.addBeanMethod(new BeanMethod(methodMetadata, configClass));}// Process default methods on interfacesprocessInterfaces(configClass, sourceClass);// Process superclass, if anyif (sourceClass.getMetadata().hasSuperClass()) {String superclass = sourceClass.getMetadata().getSuperClassName();if (superclass != null && !superclass.startsWith("java") &&!this.knownSuperclasses.containsKey(superclass)) {this.knownSuperclasses.put(superclass, configClass);// Superclass found, return its annotation metadata and recursereturn sourceClass.getSuperClass();}}// No superclass -> processing is completereturn null;}进入this.componentScanParser.parse(componentScan,sourceClass.getMetadata().getClassName())
开始解析@CompnentScan注解:
public Set<BeanDefinitionHolder> parse(AnnotationAttributes componentScan, String declaringClass) {//实例化一个扫描器//registry----容器对象//useDefaultFilters----是否使用默认的过滤器//存在两种过滤器:icludeFilter引入过滤器、excludeFilter排除过滤器ClassPathBeanDefinitionScanner scanner = new ClassPathBeanDefinitionScanner(this.registry,componentScan.getBoolean("useDefaultFilters"), this.environment, this.resourceLoader);//看看@CompnentScan注解中的nameGenerator属性(bean名称的生成策略,可以自己配置)是否有配置,有则获取Class<? extends BeanNameGenerator> generatorClass = componentScan.getClass("nameGenerator");boolean useInheritedGenerator = (BeanNameGenerator.class == generatorClass);//设置bean名字的生成策略scanner.setBeanNameGenerator(useInheritedGenerator ? this.beanNameGenerator :BeanUtils.instantiateClass(generatorClass));//下面的都是对注解的属性的解析(scopedProxy、resourcePattern、includeFilters等等)ScopedProxyMode scopedProxyMode = componentScan.getEnum("scopedProxy");if (scopedProxyMode != ScopedProxyMode.DEFAULT) {scanner.setScopedProxyMode(scopedProxyMode);}else {Class<? extends ScopeMetadataResolver> resolverClass = componentScan.getClass("scopeResolver");scanner.setScopeMetadataResolver(BeanUtils.instantiateClass(resolverClass));}scanner.setResourcePattern(componentScan.getString("resourcePattern"));//加入Include过滤器for (AnnotationAttributes filter : componentScan.getAnnotationArray("includeFilters")) {for (TypeFilter typeFilter : typeFiltersFor(filter)) {scanner.addIncludeFilter(typeFilter);}}for (AnnotationAttributes filter : componentScan.getAnnotationArray("excludeFilters")) {for (TypeFilter typeFilter : typeFiltersFor(filter)) {scanner.addExcludeFilter(typeFilter);}}boolean lazyInit = componentScan.getBoolean("lazyInit");if (lazyInit) {scanner.getBeanDefinitionDefaults().setLazyInit(true);}Set<String> basePackages = new LinkedHashSet<>();String[] basePackagesArray = componentScan.getStringArray("basePackages");for (String pkg : basePackagesArray) {String[] tokenized = StringUtils.tokenizeToStringArray(this.environment.resolvePlaceholders(pkg),ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);Collections.addAll(basePackages, tokenized);}for (Class<?> clazz : componentScan.getClassArray("basePackageClasses")) {basePackages.add(ClassUtils.getPackageName(clazz));}if (basePackages.isEmpty()) {basePackages.add(ClassUtils.getPackageName(declaringClass));}//加入Exclude过滤器scanner.addExcludeFilter(new AbstractTypeHierarchyTraversingFilter(false, false) {@Overrideprotected boolean matchClassName(String className) {return declaringClass.equals(className);}});//return scanner.doScan(StringUtils.toStringArray(basePackages));}进入scanner.doScan()
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {Assert.notEmpty(basePackages, "At least one base package must be specified");Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();for (String basePackage : basePackages) {//使用ASM字节码技术读取对应的目录,解析符合的类(加了@Compnent注解)并返回BeanDefinition集合Set<BeanDefinition> candidates = findCandidateComponents(basePackage);for (BeanDefinition candidate : candidates) {ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);candidate.setScope(scopeMetadata.getScopeName());//根据bean名字生成策略生成bean名称String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);if (candidate instanceof AbstractBeanDefinition) {postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);}if (candidate instanceof AnnotatedBeanDefinition) {AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);}//查看是否已经存在BeanDefinition,不存在则进行注册if (checkCandidate(beanName, candidate)) {BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);definitionHolder =AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);beanDefinitions.add(definitionHolder);registerBeanDefinition(definitionHolder, this.registry);}}}return beanDefinitions;}
我们可以继续往findCandidateComponents方法看看,大概是怎么扫描的,再次进入
scanCandidateComponents方法。
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {//防止重复Set<BeanDefinition> candidates = new LinkedHashSet<>();try {//获取包全路径String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +resolveBasePackage(basePackage) + '/' + this.resourcePattern;//读取目录转为Resource[]对象Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);boolean traceEnabled = logger.isTraceEnabled();boolean debugEnabled = logger.isDebugEnabled();//遍历获取到单个Resource对象(即单个文件)for (Resource resource : resources) {if (traceEnabled) {logger.trace("Scanning " + resource);}try {//ASM技术读取文件内容转为MetadataReader对象MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);//判断该对象是否被@CompnentScan的excludeFilters排除被排除则false,// 被includeFilters或者存在@Compnent则实例化成ScannedGenericBeanDefinition对象放进集合//注意:这里判断是否有@Compnent是因为在实例化扫描器ClassPathBeanDefinitionScanner的时候会执行registerDefaultFilters()方法// 在该方法中默认就注入了Component到includeFilter中(this.includeFilters.add(new AnnotationTypeFilter(Component.class));)// 所以如果有@Compnent注解则在判断是否在includeFilter是返回true。if (isCandidateComponent(metadataReader)) {ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);sbd.setSource(resource);if (isCandidateComponent(sbd)) {if (debugEnabled) {logger.debug("Identified candidate component class: " + resource);}candidates.add(sbd);}else {if (debugEnabled) {logger.debug("Ignored because not a concrete top-level class: " + resource);}}}else {if (traceEnabled) {logger.trace("Ignored because not matching any filter: " + resource);}}}catch (FileNotFoundException ex) {if (traceEnabled) {logger.trace("Ignored non-readable " + resource + ": " + ex.getMessage());}}catch (Throwable ex) {throw new BeanDefinitionStoreException("Failed to read candidate component class: " + resource, ex);}}}catch (IOException ex) {throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);}return candidates;}
然后进入isCandidateComponent方法看看怎么判断的:
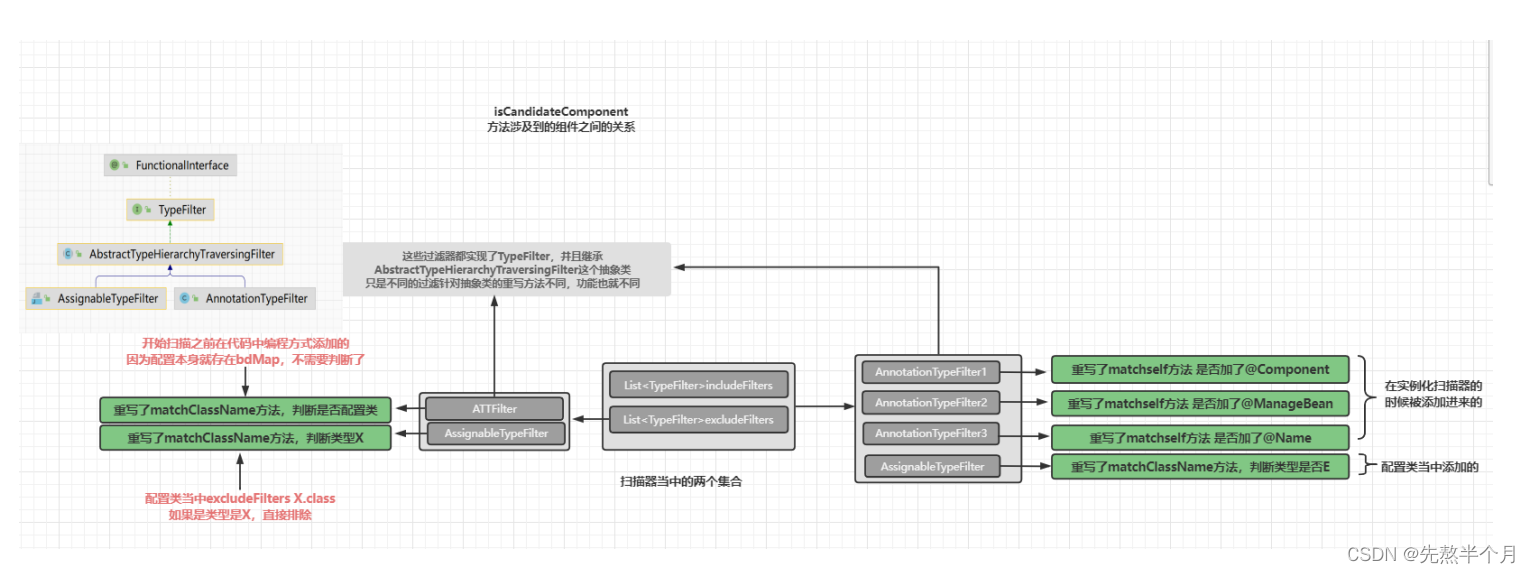
protected boolean isCandidateComponent(MetadataReader metadataReader) throws IOException {for (TypeFilter tf : this.excludeFilters) {if (tf.match(metadataReader, getMetadataReaderFactory())) {return false;}}for (TypeFilter tf : this.includeFilters) {if (tf.match(metadataReader, getMetadataReaderFactory())) {return isConditionMatch(metadataReader);}}return false;}可以看到只获取includeFilters中存在的,我们知道我们自己在配置类的@CompnentScan注解中手动加入了一个Scan_C类到includeFilters,所以Scan_C是可以扫到的,那么加了@Compnent注解的Scan_A又是怎么被扫描的?
其实在实例化一个扫描器时,就会默认加入Compnent.Class到IncludeFilters中,我们可以看看代码:进入扫描器类ClassPathBeanDefinitionScanner
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry, boolean useDefaultFilters,Environment environment, @Nullable ResourceLoader resourceLoader) {Assert.notNull(registry, "BeanDefinitionRegistry must not be null");this.registry = registry;//加入默认的类到includeFiltersif (useDefaultFilters) {registerDefaultFilters();}setEnvironment(environment);setResourceLoader(resourceLoader);}进去registerDefaultFilters方法看看加了哪些类:
protected void registerDefaultFilters() {//加入Compnent类this.includeFilters.add(new AnnotationTypeFilter(Component.class));ClassLoader cl = ClassPathScanningCandidateComponentProvider.class.getClassLoader();try {this.includeFilters.add(new AnnotationTypeFilter(((Class<? extends Annotation>) ClassUtils.forName("javax.annotation.ManagedBean", cl)), false));logger.trace("JSR-250 'javax.annotation.ManagedBean' found and supported for component scanning");}catch (ClassNotFoundException ex) {// JSR-250 1.1 API (as included in Java EE 6) not available - simply skip.}try {this.includeFilters.add(new AnnotationTypeFilter(((Class<? extends Annotation>) ClassUtils.forName("javax.inject.Named", cl)), false));logger.trace("JSR-330 'javax.inject.Named' annotation found and supported for component scanning");}catch (ClassNotFoundException ex) {// JSR-330 API not available - simply skip.}}
至此则解答了如何扫描出有@Compnent注解的类的疑问。
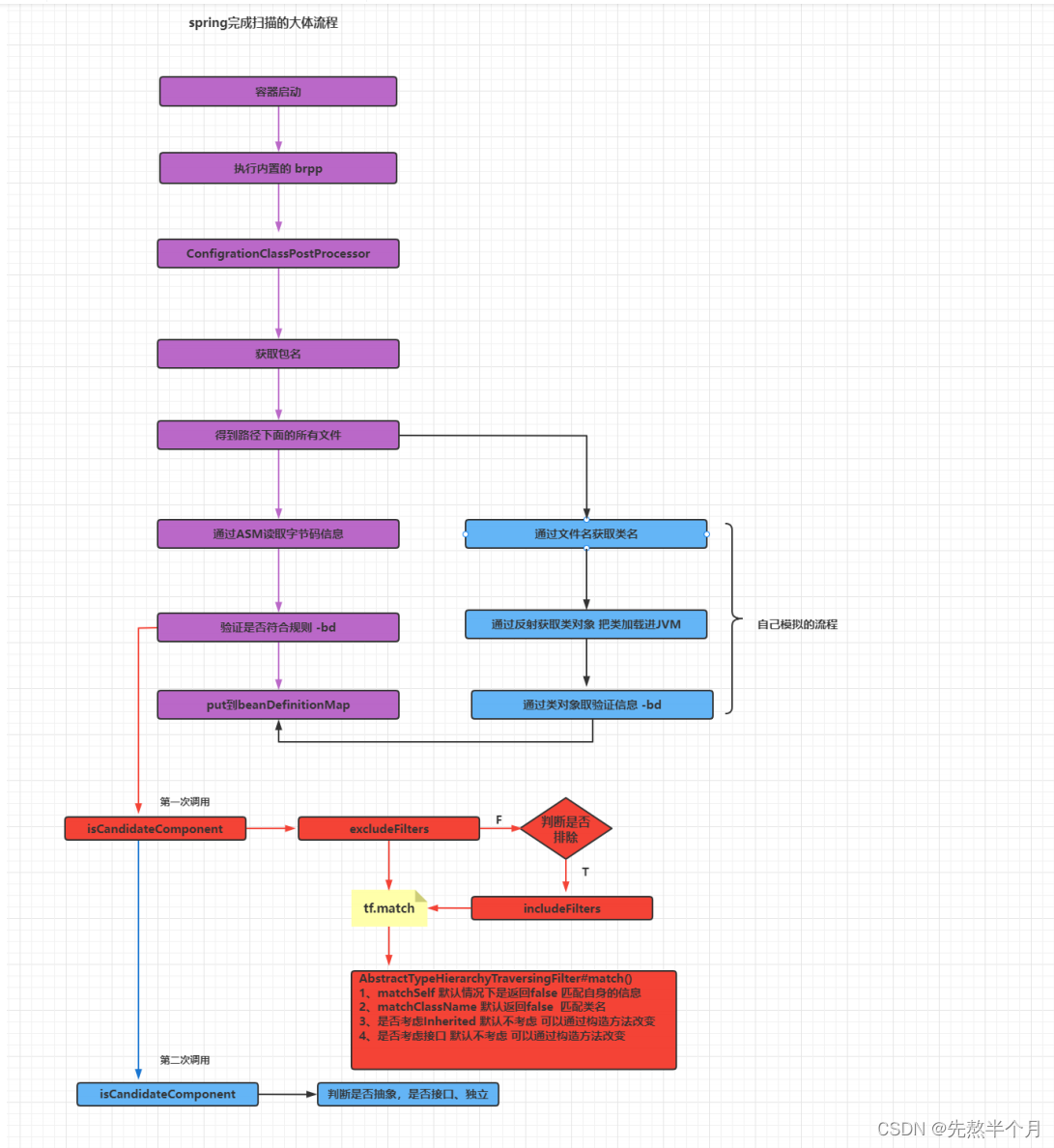
总体下来扫描的大概流程:
spring内置的ConfigurationClassPostProcessor执行子接口实现方法(postProcessBeanDefinitionRegistry) -----》通过容器registry获取spring内置类+传入的配置类 -----》依次判断是否为合格的配置类 -----》如是则获取配置类的部分属性,实例化一个扫描器(扫描器实例化的时候会将Compnent类加入到includeFilters中,为了后判断哪些类用了@Compnent注解) -----》解析配置类是否加了@Compnent、@Improt、@CompnentScan等等注解,有则进行解析 -----》解析@CompnentScan注解,解析注解中的各种属性(includeFilters、excludeFilters、beanNameGenerator等) ----》扫描包路径,使用ASM技术读取文件内容为MetadataReader对象,并判断是否能对应includeFilters中的类(并排除excludeFilters的类) ----》有则转化为ScannedGenericBeanDefifinition对象,并判断ScannedGenericBeanDefifinition是否接口是否抽象、是否加了LockUp注解等等 -----》然后加入Set<BeanDefinition>并返回,最后对其进行注册(put到BeanDefinitionMap,但还不会实例化为bean)。
=============================第二种情况做分析==============================
第二种情况非常简单,而且和第一种都是扫描器调用了doscan方法进行扫描解析的。
AnnotationConfigApplicationContext会实例化一个扫描器,然后该扫描器直接调用doScan(basePackages)方法。
=====================第一种情况下的excludeFilter、includeFilter===================
我们先看看怎么使用这两个@CompnentScan注解的属性。
新增两个测试类,一个加@Compnent,一个不加。
@Component
public class Scan_B {@PostConstructpublic void init(){System.out.println("-----------Scan_B");}
}public class Scan_C {@PostConstructpublic void init(){System.out.println("-----------Scan_C");}
}
修改下配置类:
/*** 排除Scan_B,加入Scan_C* */
@ComponentScan(value = "com.spring.demo.scan",excludeFilters = {@ComponentScan.Filter(type = FilterType.ASSIGNABLE_TYPE,classes = Scan_B.class)},includeFilters = {@ComponentScan.Filter(type = FilterType.ASSIGNABLE_TYPE,classes = Scan_C.class)})
public class ContextConfig {
}此时启动ComponentScanTest,查看控制台打印:
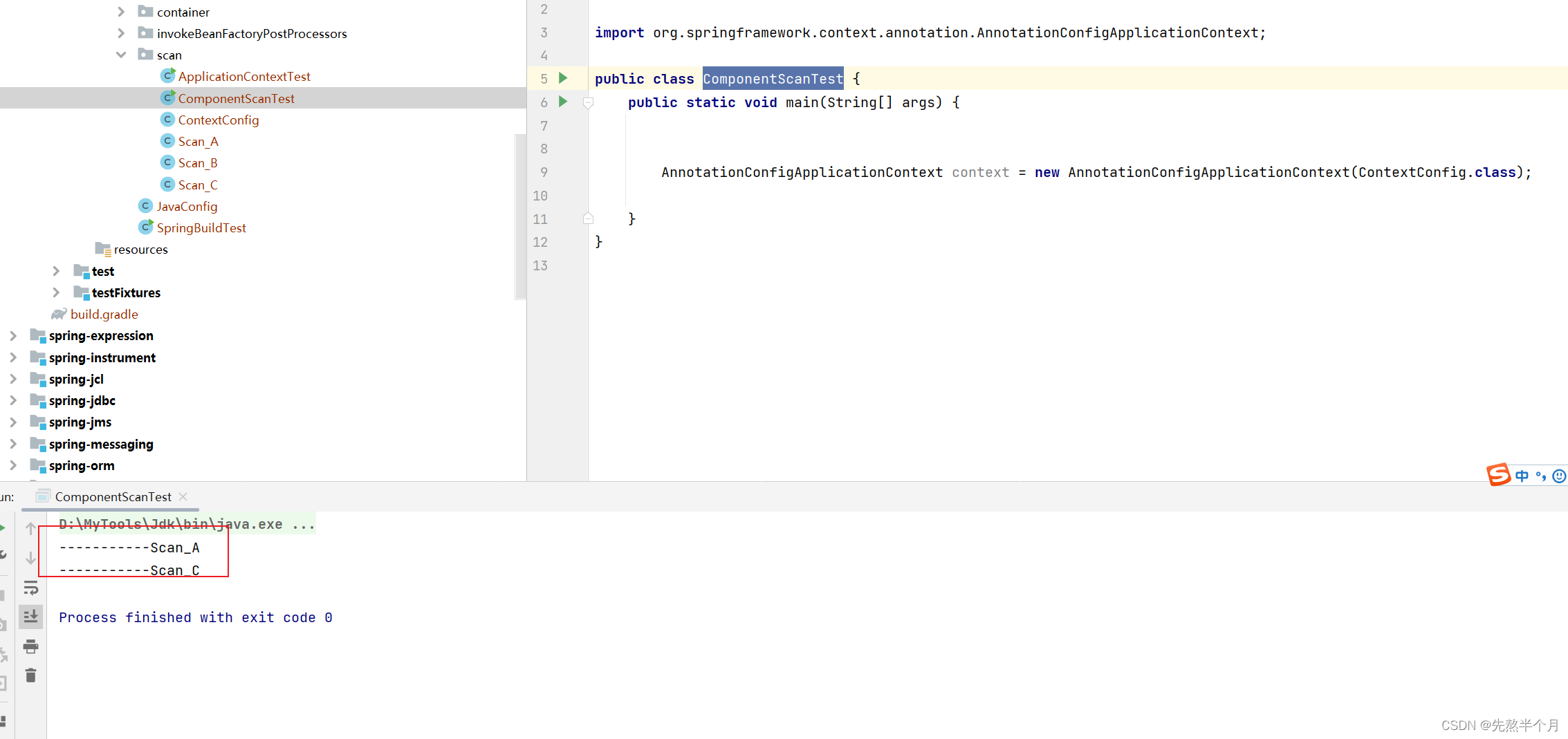
由此我们可以知道includeFilters 属性的作用是增加型过滤器,而excludeFilters是排除型过滤器。
》》》》》》》》》》》》》》》》》》》问题解答
1、为什么spring扫描要使用ASM获取字节码技术?
ASM是读取字节码文件,并不会提前加载类或执行类的方法,这样不会对类的生命周期等流程产生影响。且效率较高(比反射等方式效率高)
我们以第一种情况为例,看看完成扫描的时候Scan_A有没有被实例化(如被实例化会执行init方法)前一篇文章我们可以知道情况2执行invokeBeanDefinitionRegistryPostProcessors后会完成扫描,此时我们在这行打上断点。
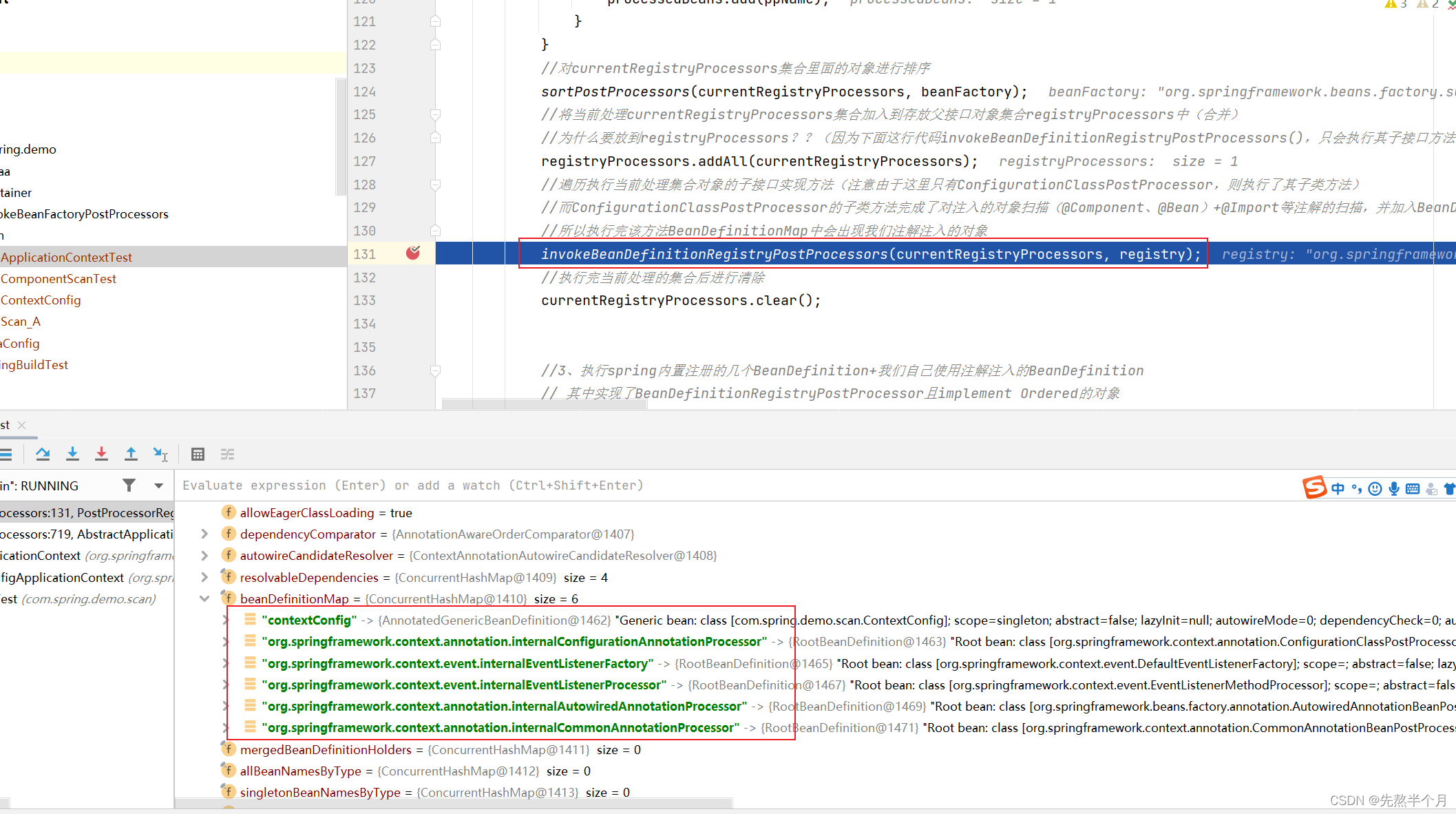
此时发现Scan_A还没被扫描到,控制台也没打印任何东西,让后我们执行这行代码后:
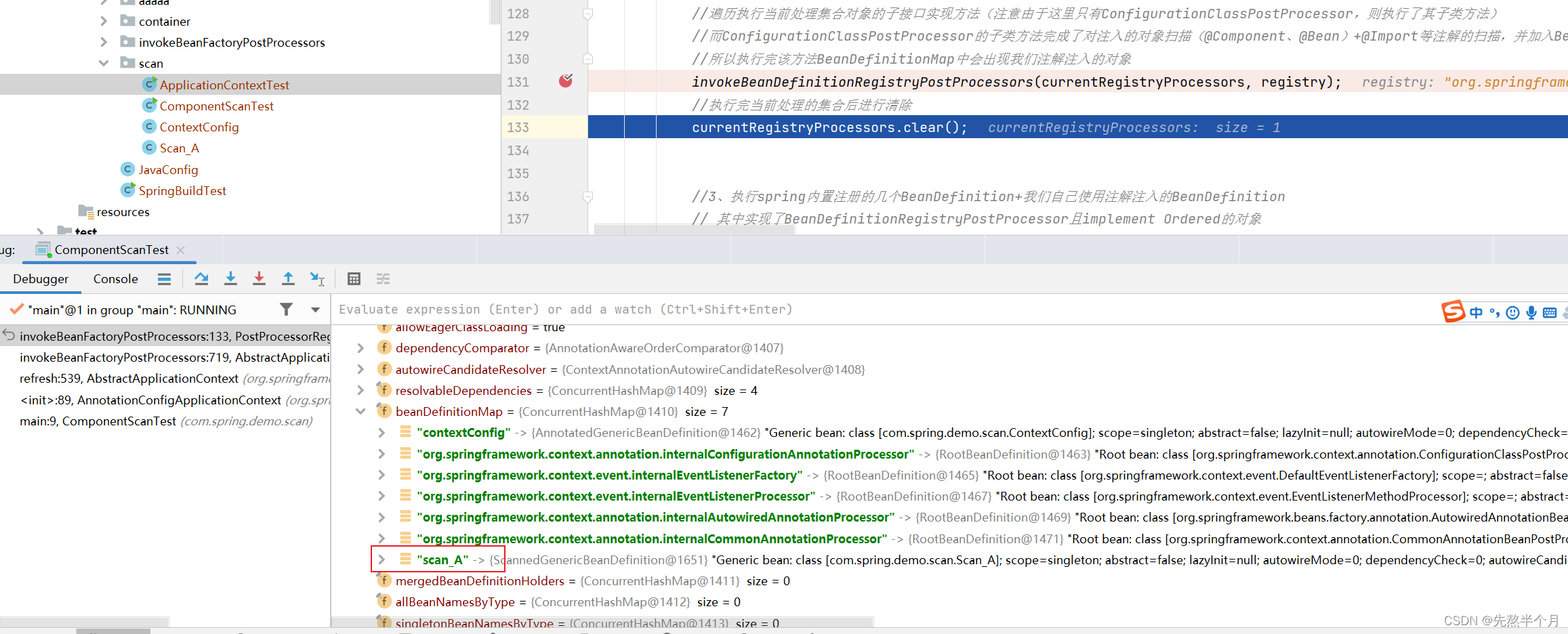
此时Scan_A被扫描到了,但ini方法并没有被实例化,所以spring采用ASM扫描并不会对对象实例化产生影响。(如果此时使用反射等方式,此时就会对对象进行实例化,从而打乱了原先对象实例化的顺序(提前进行实例化了))
2、两个扫描器的区别?
两种方式的扫描器类型都是ClassPathBeanDefinitionScanner,且都调用了doscan方法进行扫描解析。不同的是@CompnentScan注解提供了更多属性的配置,例如nameGenerator、includeFilters等。