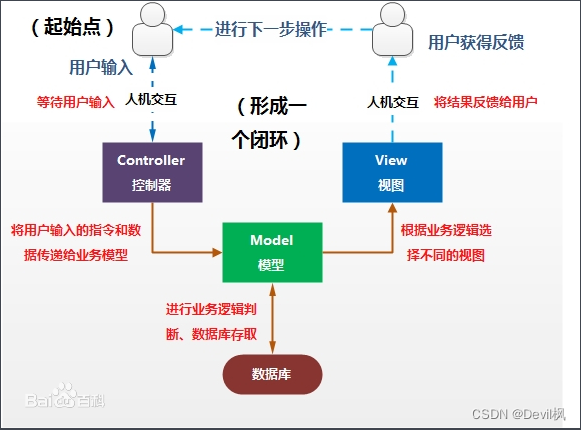
vue的模板编译原理
- 因为浏览器无法处理vue里面的template标签,所以vue的模板编译是指把template编译成render函数,这样浏览器才可以调用
- 总体分为三步:把template转化为AST树,对AST进行优化,调用函数把AST树转化为render函数
- 详细步骤
- 把template转化为AST树。这里主要针对是否有render函数,是否有el属性等等进行判断是否需要编译,如果需要就要通过正则表达式匹配标签、文本、注释等内容,同时用栈结构存放标签,如果匹配到开始标签就让开始标签入栈,匹配到结束标签就让栈里面对应的开始标签和上面的所有内容出栈。
- 对AST优化。这里主要是针对虚拟dom的更新,为了节省性能,就可以不对比静态虚拟dom节点,所以在AST树阶段,对静态节点进行标记进行优化。这里主要是通过递归遍历节点,标记节点的static属性来判断当前节点是否是静态的。
- 把AST树转为render函数。这里主要是根据AST树对各个节点的表示,来生成对应的字符串,其中包括可以让vue在运行的时候调用的函数,在这里把AST转为render函数,render函数调用就会生成虚拟dom[//]: # (这个过程会发生在vue组件created钩子里面)
参考文章:https://juejin.cn/post/6863241580753616903
vue-router原理
在vue中,我们会使用Vue.use以插件的形式来安装vue-router,同时会在vue的实例上挂载router的实例。在vueRouter里面有一个公共的方法install,这个方法接收的第一个参数是Vue构造器,第二个参数是可选的参数对象,同时在install文件里面,使用了mixin给每个组件创建了beforeCreate钩子,在这个钩子里面给Vue的实例初始化了一些私有属性,其中_router指向了vueRouter的实例,_route指向了vue的实例。
在vue中利用数据劫持defineProperty在原型上初始化了一些getter,分别是router和route,其中router指向全局的vue-router实例,route指向当前的router的信息。在install中也全局注册了router-view,router-link,其中Vue.util.defineReactive方法是vue里面观察者劫持数据的,劫持了_route,当_route触发了setter方法的时候,就会通知到依赖的组件。
然后在init里面,会挂载判断当前路由是hash或者history模式,当点击行为按钮的时候,会触发hashchange或者popstate方法更新_route,_route的更新会导致相应的router-view重新渲染。
参考文章:https://juejin.cn/post/6844903942178996237
hash路由和history路由
-
为什么要用这两种路由?
在普通页面用ajax请求时,如果刷新页面,不能让数据复现,在单页面应用里面,因为所有的内容都是在一个html里面完成的,所以需要一个东西来解决数据不复现的问题,恰好这两种路由都有监听机制,可以通过监听路由的变化返回要渲染的数据
-
两种模式
-
hash模式。
底层是通过监听hashchange事件以及根据window,location.hash执行相应的js去渲染页面实现的。用hash模式的路由后面会加上#,再加hash值,同时切换哈希值不会给服务器发请求,也就是不会再重新加载渲染页面了。点浏览器的前进后退按钮也会触发hashchange事件
-
history模式
底层是获取了浏览器的历史记录,通过调用go(),back(),forward()来通过获取浏览器历史记录显示页面,访问当前页面前的页面都是从浏览器缓存里拿的,没有去请求服务器。也可以用pushstate()和replacestate()来操作历史栈,用popstate事件来监听变化,但是只能监听到调用了go(),back(),forward()方法以及用户点击浏览器前进后退按钮。
history更换url的时候浏览器是不会发送请求的,但是如果直接通过url访问某个页面或者手动刷新,就会向服务器发送请求,如果后端没有配置就会有404报错
-
两个路由的区别
- 当向服务器发送请求时,hash路由不会携带哈希值,但是history会把整个url都携带上去
- hash兼容性更好
-
双向数据绑定
- 指:指vue中v-model,v-model实际上是返回了一个属性和一个方法,是
<input :value="mes" @input="mes = $event.target.value"/>的语法糖。 - 理解:通过这个属性和方法,同时利用响应式,实现了双向数据绑定
事件绑定的原理
- 事件绑定分为两种
- 原生的事件绑定,内部用addEventListener给标签添加事件.
<button @click="clickBtn">原生事件</button> - 组件的事件绑定,内部用$on添加事件.
<Component @click.native="clickComponent">组件事件绑定</Component>
- 原生的事件绑定,内部用addEventListener给标签添加事件.
vue2的diff算法
-
针对新旧节点的对比,根据新旧节点是否有子节点分成四种情况,当它们都有子节点的时候会发生diff。是否进行节点对比的原则是:只做同层对比,如果type变化,就不对比子节点。vue2的diff是全diff,比较暴力。vue3对diff进行了优化。
-
diff过程:
分别为新旧dom的子节点设置前后指针,通过四种命中方式依次进行判断,分别是:新前旧前;新后旧后;旧后新前;旧前新后。命中表示每次对比的两个指针指向的dom节点相同,根据相应情况进行操作。如果四种方式都没有命中,就要从第一个新的子节点开始,在旧子节点递归找有没有相同的节点,有就复用,如果递归结束也没有可复用节点,就新建节点。
-
四种命中方式对应的处理情况
- 新前旧前。如果两个指针命中,就都往后移,如果新节点指针先到界,说明需要删除一部分旧子节点,如果旧节点指针先到界,说明说要新增一些新子节点
- 新后旧后。命中就往前移。谁的指针先到界的处理情况和上一个相同
- 旧后新前。如果命中,就把旧后放到旧前前面
- 旧前新后。如果命中,就把旧后前到旧后后面
-
diff是深度优先还是广度优先
深度优先。在patchNode里面调用了updateChildren函数,在父子组件中更新父组件体现为:父组件beforeUpdate → 子组件beforeUpdate →子组件updated → 父组件updated
参考文章:https://juejin.cn/post/7113586699808014373
简单diff和双端diff
-
都是多节点对比的算法
-
简单diff
给新旧节点各一个指针,从前往后开始对比,新节点指针每移动一步,就需要对旧节点进行一次遍历。关键在:当新旧节点指针指向的节点相同,如果旧节点比新节点靠后就不动,如果旧节点比新节点考前,就要把对应的旧节点移动到新节点的对应位置。
-
双端diff
就是vue2采用的diff算法,关键在新旧节点各有两个指针
参考文章:https://juejin.cn/post/7114177684434845727
vue3的diff算法优化
-
事件缓存。
把组件绑定的事件缓存起来,组件更新的时候直接从缓存里面拿事件
-
静态标记
对不会更改的节点做标记,在vue2里面如果产生更新,无论节点是否是动态的都会重新渲染,但是在vue3里面,通过把静态标记了的节点储存起来,只有第一次渲染的时候会被创建,后续就会复用储存起来的节点变量
-
基于最长子序列的移动,添加或删除
在vue2的diff中,先进行四种命中方式,再兜底的深度遍历查找,但是在vue3里面,只有两种命中方式:新前旧前,新后旧后。这两种命中方式结束之后,开始找新子节点还没有处理的每个子节点在旧子节点对应的下标,如果没有就是-1,把下标放到数组里面,找最长连续的一个子数组,把对应的子节点从旧节点拿来复用,其他的在最长连续子数组的基础上进行移动删除或者添加
这里我有个地方不理解:vue编译过程里有个遍历AST树,给静态节点打标记的优化过程,相当于vue2就有静态标记了,为什么vue3的diff会把静态标记当作优化点??
参考文章:https://juejin.cn/post/7010594233253888013
vue2 vue3的区别
- 支持ts
- 生命周期钩子。vue3使用钩子需要引入,在vue2钩子名称前加上on
- 多根节点。
- 事件缓存。
- 异步组件(suspence)。
- teleport组件(可以添加加载动画,可以把包裹着的组件移动到app组件之外,可以用来包裹全局的弹窗)
- 响应式。
- 组合式API。vue2是选项式。
- 虚拟DOM添加patchFlag参数,用来判断是否是静态节点,是否需要进一步diff
- diff算法优化
参考文章:https://juejin.cn/post/7067413380922867725
keep-alive原理
-
使用
keep-alive是一个组件,可以用abstract参数来指定是否把这个组件渲染到页面上,被keep-alive包裹的组件在页面切换的时候不会被卸载。包括三个参数:include,exclude,max。被include匹配到的组件可以被缓存,被exclude匹配到的组件不会被缓存,max表示最多能缓存的组件个数
-
原理
-
keep-alive组件的created钩子期间。创建catch和keys用来储存缓存组建的信息,其中catch是一个对象,用来根据组件的key来缓存虚拟dom,keys是一个数组,用来储存缓存组件的key
-
keep-alive的mounted钩子期间。在这时监听include和exclude里的组件的变化。
-
keep-alive的destroyed钩子期间。在这里循环遍历调用缓存组件的$destory钩子,同时把catch[key]置为空,清除掉keys
-
render函数期间。在这里把include称作白名单,把exclude称作黑名单。在render函数期间,首先获取到keep-alibe包裹的第一个组件和组件名称,再根据组件名称判断是否在黑名单或者不在白名单,如果是的话就直接渲染组件,如果不是就往后走。
如果这个组件需要被缓存,就查看catch里面有没有它,如果有就根据key拿到虚拟dom,然后再更新它的key在keys里面的位置(这是实现LRU算法[//]: # (LRU算法:最近未使用页面被置换出来,是一种页面置换算法)的关键)。如果catch里没有这个缓存组件,就把它相应的加到catch和keys里面,再判断有没有超过max,如果超过就根据LRU算法删掉一个缓存组件。
最后要把组件实例的keepAlive属性设置为true(这个很关键)
-
被包裹组件的渲染。根据自己的keepAlive属性以及是否keep-alive组件的catch里面来决定拿缓存虚拟dom还是走流程生成虚拟dom
-
-
activated和deactivated钩子
被keep-alive包裹的组件多两个钩子:activated在组件被激活时调用,deactivated在组件被缓存时调用
参考文章:https://juejin.cn/post/7043401297302650917
tree-shaking
-
属于webpack的内容,可以用来减少打包体积。
-
原理
如果某些文件里面的变量或者函数没有被使用,就把定义这些变量、函数的代码给剔除掉,不参与打包。
-
有副作用的文件不能参与tree-shaking,有副作用的文件指:除了export导出的内容还有其他内容
参考链接:https://juejin.cn/post/7062180864968359943
SSR
- 理解:是指服务端渲染。把在浏览器运行js生成页面的工作放到服务端进行,服务端把生成的Html字符串返回给浏览器。
- 优点:这样可以加快首屏渲染的时间,利于SEO
- 缺点:对于vue ssr,每个组件的钩子都只有beforeCreate和created这两个,而且服务端只能依赖nodejs的环境,同时增大了服务端的负载压力
vue性能优化
-
使用函数式组件
在vue中,一个普通的组件会被解析成一个虚拟dom,在patch过程中,会对虚拟dom进行递归,函数组件和普通组件不同,生成的虚拟dom不会被递归,所以也代表函数组件没有生命周期钩子,没有响应式数据等等
-
拆分子组件(使用计算属性)
这两种办法的思想类似,都是利用了缓存。父组件更新,如果没有给子组件传参或者给子组件的参数没有变,或者计算属性依赖的值没有变,对应的子组件值或者计算属性都不会再次渲染
-
给变量设置局部作用域(减少通过this调用响应式数据)
因为用this.data拿数据会触发数据的getter,就会执行收集依赖等一系列逻辑,如果执行频率太高就会降低性能
-
不同场景下使用v-if或者v-show
在初始渲染阶段,v-show要比v-if消耗的性能要高,因为v-show会渲染两个分支,分别设置显示隐藏属性,v-if只渲染符合条件的一个分支。
在更新阶段v-show比v-if消耗性能低,因为v-if的切换会导致包裹的子组件的销毁和挂载,如果频繁的用v-if更新,会消耗性能
-
keep-alive
组件缓存,被缓存的组件在被切换掉的时候不会被卸载,用keep-alive会把缓存组件的虚拟dom放到内存里面,所以这属于空间换时间
-
减少在data里面定义的数据
因为vue给data里面的数据拦截下来了,如果很多深层次的对象没必要响应,但是放到data里面就会被递归遍历,会多一些没必要的操作
-
还有一些有的没的,比如图片懒加载,key保证唯一,路由动态引入,ssr,tree-shaking什么的
参考文章:https://juejin.cn/post/6922641008106668045