目录
前言
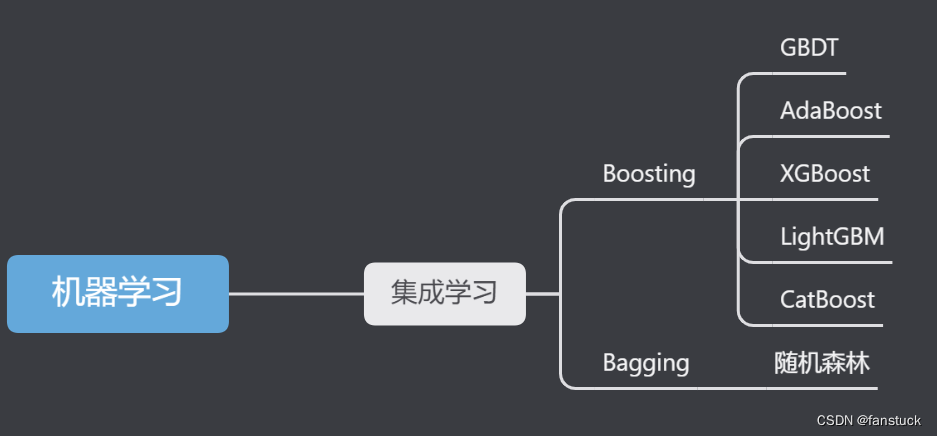
一、Adaboost算法概述
二、Adaboost模型原理
类推
计算原理
特点
适应较小量数据集,训练时间长
三、Python实例运用
AdaBoostClassifier分类
参数
实例实现分类
导入数据集
划分数据集
训练模型
评估算法
模型效果
前言
集成学习的方法在全球各大机器学习、数据挖掘竞赛中使用的非常广泛,其概念和思想也是风靡学术界和工业界,我的期刊论文以及毕业百优论文也是用到了集成学习算法。而Adaboost作为最早开始流行的集成算法,必然包含boosting最核心的思想。作为一种元算法框架,Boosting几乎可以应用于所有目前流行的机器学习算法以进一步加强原算法的预测精度,应用十分广泛,产生了极大的影响。而AdaBoost正是其中最成功的代表,被评为数据挖掘十大算法之一。在AdaBoost提出至今的十几年间,机器学习领域的诸多知名学者不断投入到算法相关理论的研究中去,扎实的理论为AdaBoost算法的成功应用打下了坚实的基础。
在上篇文章给集成算法学习开了个小头,也较为详细的把每个Boosting算法都简述了一遍,但差点就把Adaboost算法给全部讲完了。Adaboost算是最最经典的Boosting算法了,也最能体现Boosting的思想和建模流程,那么下面我们就来了解一下Adaboost算法的原理和建模流程。
一、Adaboost算法概述
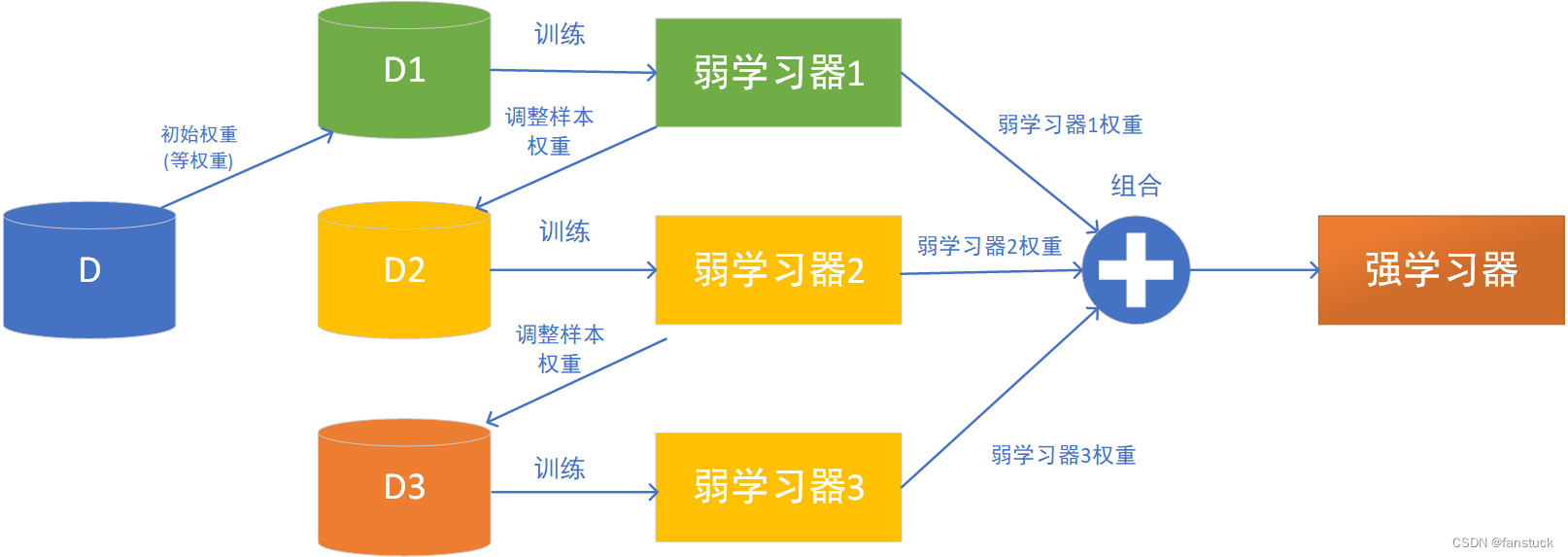
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。这在直接构造强学习器非常困难的情况下,为学习算法的设计提供了一种有效的新思路和新方法。
对adaBoost算法的研究以及应用大多集中于分类问题,同时也出现了一些在回归问题上的应用。就其应用adaBoost系列主要解决了: 两类问题、多类单标签问题、多类多标签问题、大类单标签问题、回归问题。它用全部的训练样本进行学习。
二、Adaboost模型原理
在上篇文章我曾经用一个简单易懂的例子说过:
最近上映一部影片你想要去看,你想要确定是否值得去观看。那么首先最直观的就是去看其电影的评分,首先可以考虑各个电影APP给出的评分,再者去看看豆瓣知乎其他人给出的评分,以及其他同事朋友给出的评分,最终你收集这些所有评分,根据不同的渠道给他们给予一定的权重(比如豆瓣评分占比高一些,但是电影APP评分少一些),计算出得到你觉得此片应有的评分,再去看此部电影。
类推
以上案例就是基本的集成学习思想,把各种渠道当作是学习器,给出的评分就是这些学习器预测出的结果。当然你可以去收集足够多的渠道,让几百个人评价你的电影,这种情况的回答普遍会更加的多元化,事实证明,这是获得最佳评价的方法。
Adaboost算法其算法原理是通过调整样本权重和弱分类器权值,从训练出的弱分类器中筛选出权值系数最小的弱分类器组合成一个最终强分类器。基于训练集训练弱分类器,每次下一个弱分类器都是在样本的不同权值集上训练获得的。每个样本被分类的难易度决定权重,而分类的难易度是经过前面步骤中的分类器的输出估计得到的。
计算原理
以下是AdaBoost算法的伪代码描述:
输入:
- 训练集 D = {(x_1, y_1), (x_2, y_2), ..., (x_m, y_m)},其中
表示第 i 个样本的特征向量,
表示第 i 个样本的类别标签。
- 弱学习算法
- 迭代次数 T
输出:
AdaBoost算法得到的强分类器
- 初始化训练数据的权值分布:对所有样本 i,令
- 迭代 T次:
- 使用权值分布
训练弱分类器
:
- 计算分类误差率
:
- 计算弱分类器
:
- 更新样本权值分布
:对所有样本
,令
- 构建强分类器
:
- 使用权值分布
其中, 是一个能够训练弱分类器的算法,例如决策树、神经网络等。
表示第 t 轮迭代中第 i个样本的权值,初始值为
。
是弱分类器
的权重,用于组合成强分类器 H(x)。最后,
表示符号函数,即正数返回1,负数返回-1。
特点
Aadboost 算法系统具有较高的检测速率,且不易出现过适应现象。但是该算法在实现过程中为取得更高的检测精度则需要较大的训练样本集,在每次迭代过程中,训练一个弱分类器则对应该样本集中的每一个样本,每个样本具有很多特征,因此从庞大的特征中训练得到最优弱分类器的计算量增大。
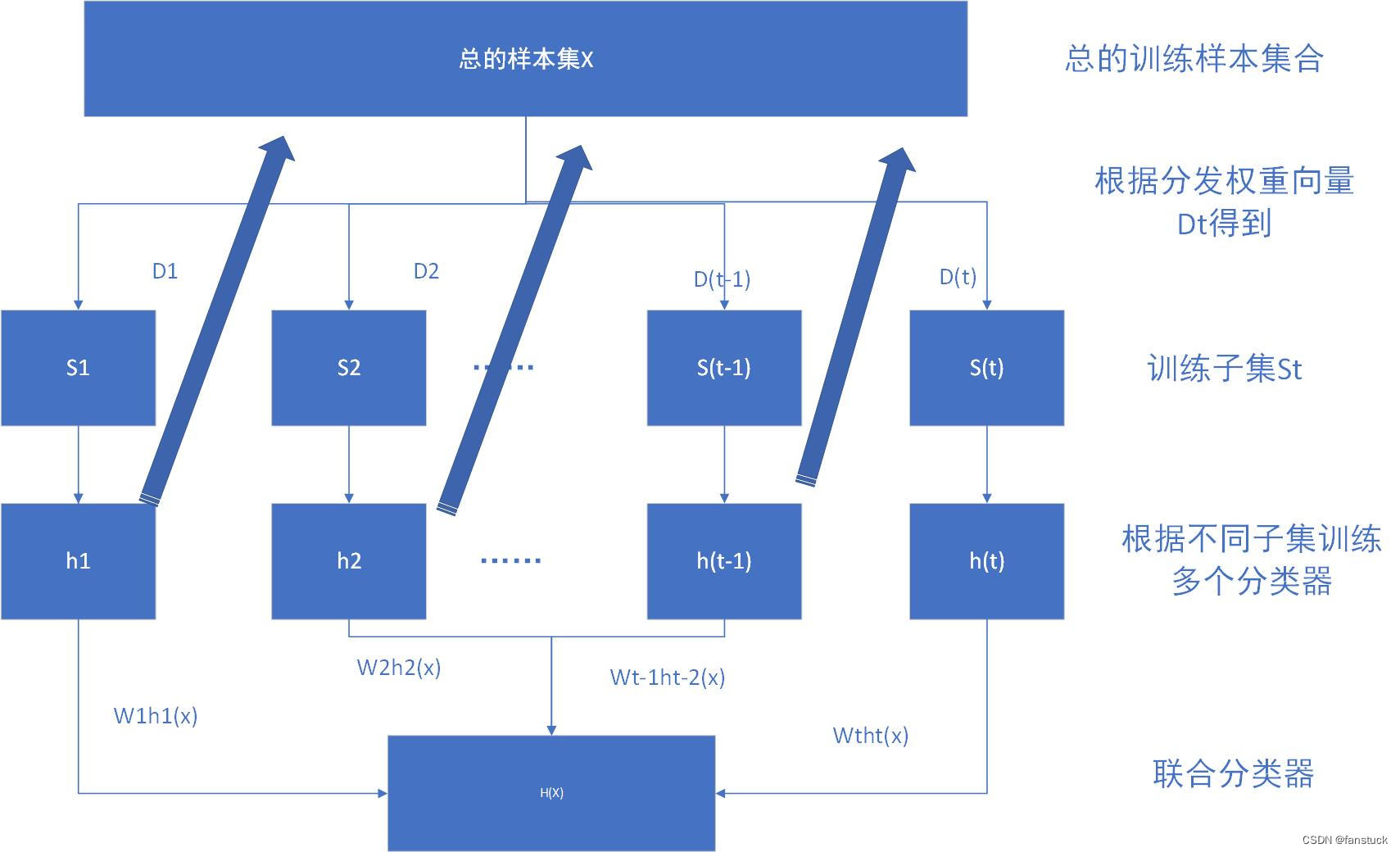
上面图h1是指的s2,有点贴图错误大家见谅。
适应较小量数据集,训练时间长
典型的 Adaboost 算法采用的搜索机制是回溯法,虽然在训练弱分类器时每一次都是由贪心算法来获得局部最佳弱分类器,但是却不能确保选择出来加权后的是整体最佳。在选择具有最小误差的弱分类器之后,对每个样本的权值进行更新,增大错误分类的样本对应的权值,相对地减小被正确分类的样本权重。且执行效果依赖于弱分类器的选择,搜索时间随之增加,故训练过程使得整个系统的所用时间非常大,也因此限制了该算法的广泛应用。另一方面,在算法实现过程中,从检测率和对正样本的误识率两个方面向预期值逐渐逼近来构造级联分类器,迭代训练生成大量的弱分类器后才能实现这一构造过程。由此推出循环逼近的训练分类器需要消耗更多的时间。
三、Python实例运用
这里如果了解了整个建模原理不需要再通过流程公式再去推算一遍AdaBoost算法了,直接可以通过sklearn.ensemble模块调出AdaBoot模型:

AdaBoost可用于分类和回归问题:
- 对于多类分类,AdaBoostClassifier实现了AdaBoost SAMME和AdaBooster SAMME。
- 对于回归,AdaBoostProgressor实现AdaBoost R2。
AdaBoostClassifier分类
通过AdaBoostClassifier函数可以构建AdaBoost分类器:
class sklearn.ensemble.AdaBoostClassifier(estimator=None,*, n_estimators=50,learning_rate=1.0,algorithm='SAMME.R',random_state=None,base_estimator='deprecated')此类实现称为AdaBoost SAMME的算法。
参数
estimator:object, default=None
构建增强系综的基础估计器。需要支持样本权重,以及正确的classes_和n_classes_属性。如果None,则基础估计器是DecisionTreeClassifier,初始化为max_depth=1。
n_estimators:int, default=50
提升终止时的最大估计数。在完美匹配的情况下,学习过程会提前停止。值必须在范围[1,inf)内。
learning_rate:float, default=1.0
在每个增强迭代中应用于每个分类器的权重。较高的学习率增加了每个分类器的贡献。在learning_rate和n_估计器参数之间存在权衡。值必须在范围(0.0,inf)内。
algorithm:{‘SAMME’, ‘SAMME.R’}, default=’SAMME.R’
如果“SAMME.R”,则使用SAMME.RR实增强算法。估计器必须支持类概率的计算。如果“SAMME”,则使用SAMME离散升压算法。SAMME.R算法的收敛速度通常比SAMME更快,通过较少的提升迭代实现了较低的测试误差。
random_state:int, RandomState instance or None, default=None
控制在每个增强迭代中在每个估计器处给出的随机种子。因此,它仅在估计器公开random_state时使用。在多个函数调用之间传递一个int以获得可复制的输出。
base_estimator:object, default=None
构建增强系综的基础估计器。需要支持样本权重,以及正确的classes_和n_classes_属性。如果None,则基础估计器是DecisionTreeClassifier,初始化为max_depth=1。
实例实现分类
导入数据集
分类的场景还是挺多的,我们拿现成的鸢尾花例子来实验一会:
from sklearn.datasets import load_iris
import pandas as pd
iris_data = load_iris()
iris_data_feature=list(iris_data.data)
iris_data_df=pd.DataFrame(iris_data_feature,columns=['花萼长度','花萼宽度','花瓣长度','花瓣宽度'])
iris_data_class=list(iris_data.target)
iris_class_df=pd.DataFrame(iris_data_class,columns=['花朵类型'])
iris_true_df=pd.concat([iris_data_df,iris_class_df],axis=1)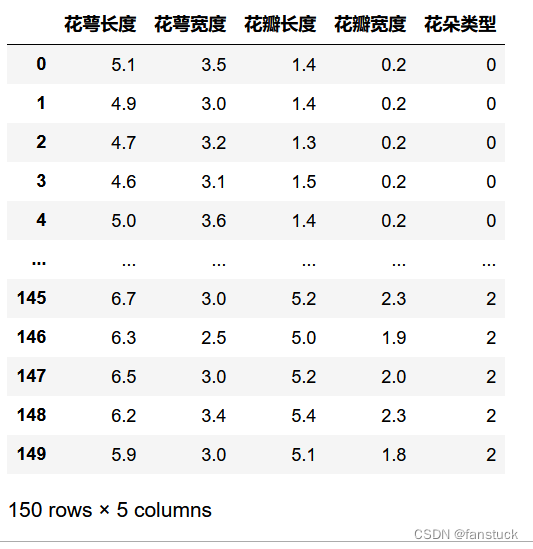
划分数据集
一般划分数据集采取2/8切分,其中80%的数据用作训练,20%的数据用作验证。
from sklearn.model_selection import train_test_split
iris_array=iris_true_df.values
X=iris_array[:,0:4]
Y=iris_array[:,4]
test_model=0.2
seed=5
X_train,X_test,Y_train,Y_test=train_test_split(X,Y,test_size=test_model,random_state=seed)
训练模型
clf = AdaBoostClassifier(n_estimators=100,learning_rate=0.8,algorithm='SAMME.R',random_state=1)
AdaBoost_model=clf.fit(X_train,Y_train)评估算法
我这里就使用十折交叉验证法来评估算法的准确度。十折交叉验证就是随机将数据分成10份:9份用来训练模型,1份用来评估算法。
from sklearn.model_selection import KFold
results=[]
kfold=KFold(n_splits=10,shuffle=True,random_state=seed)
cv_results=cross_val_score(clf,X_train,Y_train,cv=kfold,scoring='accuracy')
results.append(cv_results)
print('%s:%f(%f)'%('AdaBoost_model',cv_results.mean(),cv_results.std()))AdaBoost_model:0.966667(0.055277)
那么我们通过混淆矩阵来看看效果如何:
模型效果
from sklearn.metrics import confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
labels=[0,1,2]
cm= confusion_matrix(Y_test, Y_predict)
sns.heatmap(cm,annot=True ,fmt="d",xticklabels=labels,yticklabels=labels)
plt.title('confusion matrix') # 标题
plt.xlabel('Predict lable') # x轴
plt.ylabel('True lable') # y轴
plt.show()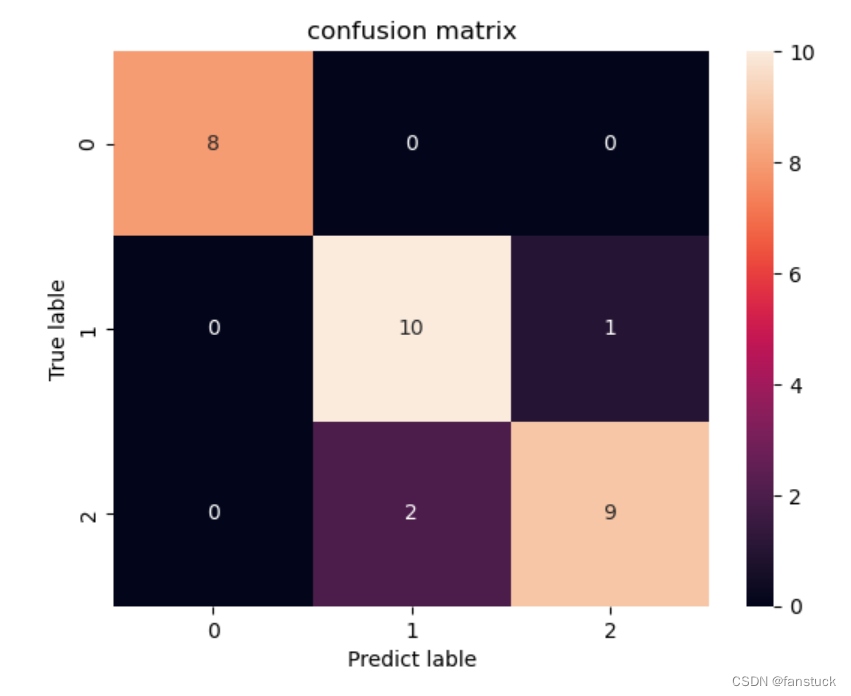
那么本章内容已经足够多了,消耗需要一定的时间,内容也不能过多造成学习疲劳,后续将继续补充AdaBoost算法的一些高阶运用和项目案例实现。
![[NOIP2002 普及组] 过河卒](https://img-blog.csdnimg.cn/b816aaea74df43e99e02192b8569591a.png)