leetcode 21~30 学习经历
- 21. 合并两个有序链表
- 22. 括号生成
- 23. 合并K个升序链表
- 24. 两两交换链表中的节点
- 25. K 个一组翻转链表
- 26. 删除有序数组中的重复项
- 27. 移除元素
- 28. 找出字符串中第一个匹配项的下标
- 29. 两数相除
- 30. 串联所有单词的子串
- 小结
21. 合并两个有序链表
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
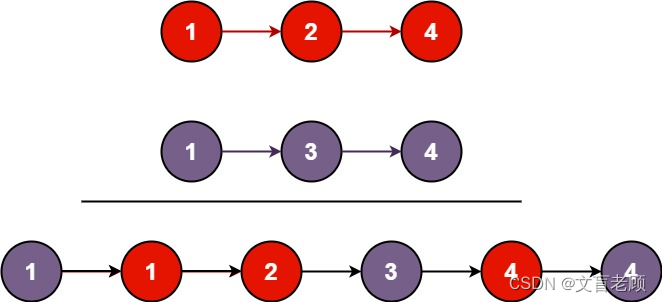
示例 1:
输入:l1 = [1,2,4], l2 = [1,3,4]
输出:[1,1,2,3,4,4]
示例 2:
输入:l1 = [], l2 = []
输出:[]
示例 3:
输入:l1 = [], l2 = [0]
输出:[0]
提示:
两个链表的节点数目范围是 [0, 50]
-100 <= Node.val <= 100
l1 和 l2 均按 非递减顺序 排列
通过次数1,291,915提交次数1,942,192
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/merge-two-sorted-lists
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
这是个评价为简单的题目,嗯,直接莽过去,没啥算法吧?
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:def mergeTwoLists(self, list1: Optional[ListNode], list2: Optional[ListNode]) -> Optional[ListNode]:r = ListNode()n = rwhile list1 or list2:if not list1:n.next = list2breakif not list2:n.next = list1breakif list1.val < list2.val:n.next = list1n = n.nextlist1 = list1.nextelse:n.next = list2n = n.nextlist2 = list2.nextreturn r.next大佬们的答案还是有些精巧的内容的,比如头部的递归,没啥好讲的,pass
22. 括号生成
数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
示例 1:
输入:n = 3
输出:[“((()))”,“(()())”,“(())()”,“()(())”,“()()()”]
示例 2:
输入:n = 1
输出:[“()”]
提示:
1 <= n <= 8
通过次数651,057提交次数839,224
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/generate-parentheses
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
呦,n的范围只有1-8,这么少用例啊,得,直接暴力搞吧
class Solution:def generateParenthesis(self, n: int) -> List[str]:if n < 1:return ['']r = []for i in range(1,n + 1):t = self.generateParenthesis(n - i)for x in t:if '(' * i + ')' * i + x not in r:r.append('(' * i + ')' * i + x)if '(' * i + x + ')' * i not in r:r.append('(' * i + x + ')' * i)return r
啊。。。。答案错误,一看,输入为4的时候,少了个(()())()的输出。。。额。。这就麻烦了
这个时候,我反应过来了,这个题目没我想的那么简单,递归里还得平衡左右,从新思考吧。。。结果掉递归的坑里出不来了。。。
然后我就又这么考虑了,不管n等于几,一共有n个左括号,然后插入同样数量的右括号,只要保证右括号数量小于左边的左括号数量,那就是另一个办法了,试试看
class Solution:def generateParenthesis(self, n: int) -> list[str]:if n < 1:return ['']r =self.makeGroup(n,n,'')r.sort()return rdef makeGroup(self,l,r,s):if l == 0:return [s + ')' * r]arr = []for j in range(r-l+1):ns = s + ')' * j for i in range(1,l + 1):nns = ns + '(' * ifor item in self.makeGroup(l - i, r - j,nns):if item not in arr:arr.append(item)return arr
马马虎虎弄出了一个,没有优化过的版本就这么累赘,再调整调整,简略一下代码,然后一个很意外的成绩排行出现了
class Solution:def generateParenthesis(self, n: int) -> list[str]:if n < 1:return ['']r =sorted(self.makeGroup(n,n,''))return rdef makeGroup(self,l,r,s):if l == 0:return {s + ')' * r}arr = set()for j in range(r-l+1):for i in range(1,l + 1):arr = arr.union(self.makeGroup(l - i, r - j,s + ')' * j + '(' * i))return arr
60ms竟然是倒数的成绩。。。。这。。。。。
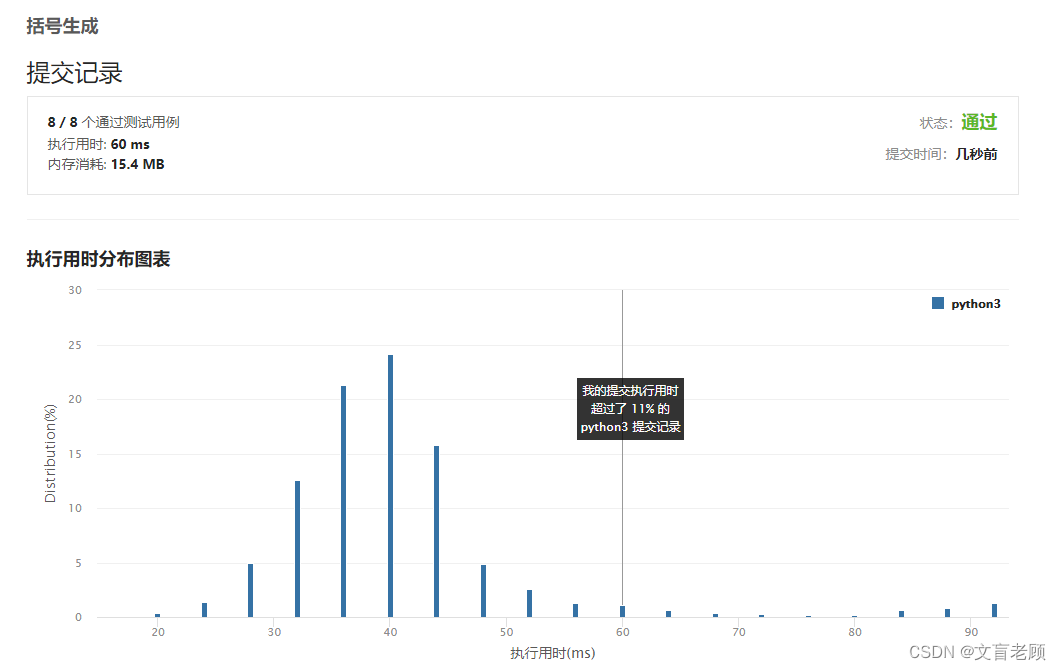
我就直接好家伙。。。。。还是瑟瑟发抖的继续学习吧
56ms的代码。。。把所有可能的组合都扔到list里去了,然后组合?
44ms的代码。。。好像把我的两个循环也变成递归,就可以了?
class Solution:def generateParenthesis(self, n: int) -> list[str]:if n < 1:return ['']r =sorted(self.makeGroup(n,n,''))return rdef makeGroup(self,l,r,s):print(l,r,s)if l == 0:return {s + ')' * r}arr = set()if l > 0:arr = arr.union(self.makeGroup(l - 1,r, s + '('))if r > l:arr = arr.union(self.makeGroup(l,r - 1, s + ')'))return arr
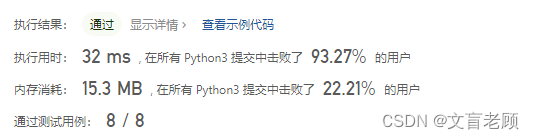
果然效率又高了一点点。。。。后边再看30ms以下的大佬们的答案,嗯比我效率高是应当的,人直接没用集合,不用并集去重就能得到答案,这是算法生成的问题,不是程序的问题了。。。
总之,这个题目耗费的时间有点出乎预料,中间还走错了几步路,还是要好好夯实基础啊
23. 合并K个升序链表
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
示例 1:
输入:lists = [[1,4,5],[1,3,4],[2,6]]
输出:[1,1,2,3,4,4,5,6]
解释:链表数组如下:
[
1->4->5,
1->3->4,
2->6
]
将它们合并到一个有序链表中得到。
1->1->2->3->4->4->5->6
示例 2:
输入:lists = []
输出:[]
示例 3:
输入:lists = [[]]
输出:[]
提示:
k == lists.length
0 <= k <= 10^4
0 <= lists[i].length <= 500
-10^4 <= lists[i][j] <= 10^4
lists[i] 按 升序 排列
lists[i].length 的总和不超过 10^4
通过次数602,178提交次数1,045,344
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/merge-k-sorted-lists
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
这个题评价为困难,但感觉做法不难啊,最后一看,lists[i].length的范围。。。。1万个,lists.length。。。500个,也就是最大500万个节点?瑟瑟发抖中。。。
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:def mergeKLists(self, lists: List[Optional[ListNode]]) -> Optional[ListNode]:z = []for node in lists:while node:z.append(node.val)node = node.nextif len(z) == 0:return Nonen = ListNode()r = nz.sort()for i in z:n.next = ListNode(i)n = n.nextreturn r.next
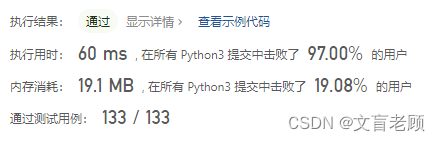
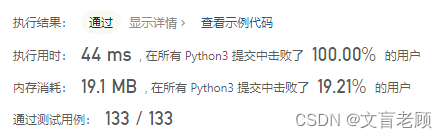
额。。。。。直接遍历得到所有值,然后排序,然后生成新的链表,这。。。。合适么?不知道用例中有没有大量的链表数据,感觉一次就过了,有点不真实,这个难度评为困难真是名不符实啊
# 以下内容抄自LeetCode第23题44ms答案
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:def mergeKLists(self, lists: List[Optional[ListNode]]) -> Optional[ListNode]:ans = []for i in lists:p = iwhile p:ans.append(p)p = p.nextif len(ans) == 0:return Noneans.sort(key = lambda x:x.val)for i in range(1,len(ans)):ans[i-1].next = ans[i]ans[-1].next = Nonereturn ans[0]
嗯,真不戳,可惜老顾暂时对 linq、lambda之类的指令用不惯,还得继续适应啊
24. 两两交换链表中的节点
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。
示例 1:
输入:head = [1,2,3,4]
输出:[2,1,4,3]
示例 2:
输入:head = []
输出:[]
示例 3:
输入:head = [1]
输出:[1]
提示:
链表中节点的数目在范围 [0, 100] 内
0 <= Node.val <= 100
通过次数579,151提交次数812,197
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/swap-nodes-in-pairs
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
哦吼,又是一个小数据题目,直接暴力上!
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:def swapPairs(self, head: Optional[ListNode]) -> Optional[ListNode]:if not head or not head.next:return headr = ListNode(0,head)p = rwhile head and head.next:n1 = headn2 = head.nextn3 = head.next.nextp.next = n2n2.next = n1n1.next = n3head = n3p = n1return r.next
这个题,感觉就是交换变量,并保持链表完整,不要断了,老顾这种没玩过链表的,试了两下就做出来了,这是个熟悉链表的题目,入门级,这个中等难度是怎么评的?看了眼20ms大佬的答案,写法基本一致,就是交换和链接更简洁,没什么可说的了
25. K 个一组翻转链表
给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。
k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
示例 1:
输入:head = [1,2,3,4,5], k = 2
输出:[2,1,4,3,5]
示例 2:
输入:head = [1,2,3,4,5], k = 3
输出:[3,2,1,4,5]
提示:
链表中的节点数目为 n
1 <= k <= n <= 5000
0 <= Node.val <= 1000
进阶:你可以设计一个只用 O(1) 额外内存空间的算法解决此问题吗?
通过次数434,044提交次数640,648
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/reverse-nodes-in-k-group
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
额。。。。。题目描述里有什么?改变节点值?我怎么没想到。。。。。合着前几个链表的题,还可以这么作弊完成啊。。。。嗯。。。虽然老顾对链表不熟,但xml玩的还不少,xmlnode改变值意义不大,htmldom 也一样,该移动节点的还是要移动节点,偶尔作弊也就算了,不能一直作弊下去吧。正好,学习了23题大佬的办法,直接用上看看
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:def reverseKGroup(self, head: Optional[ListNode], k: int) -> Optional[ListNode]:arr = []if not head:return Noneparent = ListNode(0,head)while head:arr.append(head)head = head.nextif len(arr) < k:return headfor i in range(len(arr) // k):arr = arr[:i * k] + arr[i * k:(i + 1) * k][::-1] + arr[(i + 1) * k:]parent.next = arr[0]arr[-1].next = Nonefor i in range(len(arr) - 1):arr[i].next = arr[i + 1]return parent.next
这还真是会者不难,难者不会了,有大佬的答案打底,这些评价困难的链表题,感觉就和送分题一样了
额。。。。再看了一遍大佬们的答案。。。头部答案全是自己实现 reverse 的。。。。一直在追随大佬们的脚步,一直在吃灰尘。这个仇(手动划掉)。。。方法我记住了
26. 删除有序数组中的重复项
给你一个 升序排列 的数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。
由于在某些语言中不能改变数组的长度,所以必须将结果放在数组nums的第一部分。更规范地说,如果在删除重复项之后有 k 个元素,那么 nums 的前 k 个元素应该保存最终结果。
将最终结果插入 nums 的前 k 个位置后返回 k 。
不要使用额外的空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
判题标准:
系统会用下面的代码来测试你的题解:
int[] nums = […]; // 输入数组
int[] expectedNums = […]; // 长度正确的期望答案
int k = removeDuplicates(nums); // 调用
assert k == expectedNums.length;
for (int i = 0; i < k; i++) {
assert nums[i] == expectedNums[i];
}
如果所有断言都通过,那么您的题解将被 通过。
示例 1:
输入:nums = [1,1,2]
输出:2, nums = [1,2,_]
解释:函数应该返回新的长度 2 ,并且原数组 nums 的前两个元素被修改为 1, 2 。不需要考虑数组中超出新长度后面的元素。
示例 2:
输入:nums = [0,0,1,1,1,2,2,3,3,4]
输出:5, nums = [0,1,2,3,4]
解释:函数应该返回新的长度 5 , 并且原数组 nums 的前五个元素被修改为 0, 1, 2, 3, 4 。不需要考虑数组中超出新长度后面的元素。
提示:
1 <= nums.length <= 3 * 10^4
-10^4 <= nums[i] <= 10^4
nums 已按 升序 排列
通过次数1,394,160提交次数2,549,147
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/remove-duplicates-from-sorted-array
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
啊。。。。猛的一看好像很简单,直接在 python 里,给 nums 重新赋值一下就好,结果。。。内存地址变了,修改的结果没有进入到原数组,直接失败。。。。。
看来,只能在原数组上修改了,又不想用 pop 方法作弊了,那就仔细琢磨吧
class Solution:def removeDuplicates(self, nums: List[int]) -> int:if len(nums) < 2:return len(nums)r = [0 for _ in range(len(nums))]z = [0 for _ in range(len(nums))]r[0] = nums[0]n = 1e = 0for i in range(1,len(nums)):if nums[i] == nums[i - 1]:z[e] = nums[i]e += 1else:r[n] = nums[i]n += 1for i in range(n):nums[i] = r[i]for i in range(e):nums[i + n] = z[i]return n
冒充 python 不支持不定长的数组,呵呵,成绩差强人意,试着用 pop 搞了啊,成绩居然上了1000ms

果然还是要自己写数组操作啊
class Solution:def removeDuplicates(self, nums: List[int]) -> int:n = len(nums)if n < 2:return nl,r = 0,1while r < n:if nums[r] != nums[l]:l += 1nums[l] = nums[r]r += 1return l + 1
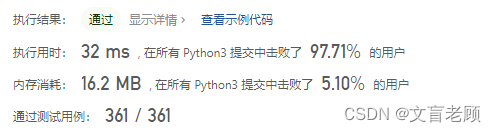
直接操作原数组,时间节省了一点点,内存怎么一直这么高?看大佬们的答案去了。。。结果答案和咱现在写法大差不大的一毛一样了,确认是老顾网络和电脑的性能差了
27. 移除元素
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参作任何拷贝
int len = removeElement(nums, val);
// 在函数里修改输入数组对于调用者是可见的。
// 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。
for (int i = 0; i < len; i++) {
print(nums[i]);
}
示例 1:
输入:nums = [3,2,2,3], val = 3
输出:2, nums = [2,2]
解释:函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。你不需要考虑数组中超出新长度后面的元素。例如,函数返回的新长度为 2 ,而 nums = [2,2,3,3] 或 nums = [2,2,0,0],也会被视作正确答案。
示例 2:
输入:nums = [0,1,2,2,3,0,4,2], val = 2
输出:5, nums = [0,1,4,0,3]
解释:函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0, 1, 3, 0, 4。注意这五个元素可为任意顺序。你不需要考虑数组中超出新长度后面的元素。
提示:
0 <= nums.length <= 100
0 <= nums[i] <= 50
0 <= val <= 100
通过次数957,786提交次数1,612,276
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/remove-element
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
这题目和上边那个26很类似啊,一个是排重,一个是删指定值,还是直觉题,倒是数组是引用的进行了说明,26题里还是隐藏条件呢
class Solution:def removeElement(self, nums: List[int], val: int) -> int:n = len(nums)z = 0pos = 0while pos < n:if z > 0:nums[pos - z] = nums[pos]if nums[pos] == val:z += 1pos += 1return n - z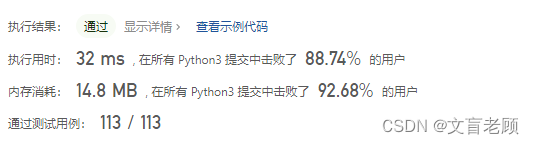
只要记录了删了几个数据,然后将数据回移就可以了,没什么可说的,自信这题,大佬也就这样,题目难度上限太低,体现不出大佬的能力
28. 找出字符串中第一个匹配项的下标
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1 。
示例 1:
输入:haystack = “sadbutsad”, needle = “sad”
输出:0
解释:“sad” 在下标 0 和 6 处匹配。
第一个匹配项的下标是 0 ,所以返回 0 。
示例 2:
输入:haystack = “leetcode”, needle = “leeto”
输出:-1
解释:“leeto” 没有在 “leetcode” 中出现,所以返回 -1 。
提示:
1 <= haystack.length, needle.length <= 10^4
haystack 和 needle 仅由小写英文字符组成
通过次数798,403提交次数1,898,322
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/find-the-index-of-the-first-occurrence-in-a-string
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
这题评价是中等,那我下边这个就是来搞笑的了
class Solution:def strStr(self, haystack: str, needle: str) -> int:if haystack.count(needle) > 0:return haystack.index(needle)else:return -1

这是要求自己写匹配啊,问题是,除了c,其他哪个语言没有字符串截取函数呢?substring、substr、[i:j]之类的,用了这个,也和上边差不多了啊
class Solution:def strStr(self, haystack: str, needle: str) -> int:for i in range(len(haystack) - len(needle) + 1):if haystack[i:i+len(needle)] == needle:return ireturn -1
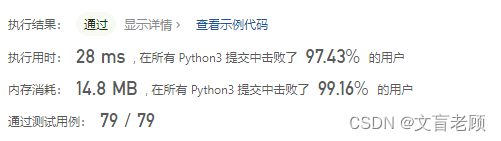
20ms大佬还真的用字符比较的方式完成的。佩服
另一个也是偷懒的答案,用find

29. 两数相除
给你两个整数,被除数 dividend 和除数 divisor。将两数相除,要求 不使用 乘法、除法和取余运算。
整数除法应该向零截断,也就是截去(truncate)其小数部分。例如,8.345 将被截断为 8 ,-2.7335 将被截断至 -2 。
返回被除数 dividend 除以除数 divisor 得到的 商 。
注意:假设我们的环境只能存储 32 位 有符号整数,其数值范围是 [−2^31, 2^31 − 1] 。本题中,如果商 严格大于 2^31 − 1 ,则返回 2^31 − 1 ;如果商 严格小于 -2^31 ,则返回 -2^31 。
示例 1:
输入: dividend = 10, divisor = 3
输出: 3
解释: 10/3 = 3.33333… ,向零截断后得到 3 。
示例 2:
输入: dividend = 7, divisor = -3
输出: -2
解释: 7/-3 = -2.33333… ,向零截断后得到 -2 。
提示:
-2^31 <= dividend, divisor <= 2^31 - 1
divisor != 0
通过次数199,432提交次数898,008
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/divide-two-integers
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
额。。。我的第一个暴力解法直接超时了,毕竟不用乘除和取余,人给了个很大的被除数,绝对值很小的除数。。。用循环减的办法直接pass。那么,这个题目明显就是要考二进制除法了,这真难为老顾了,毕竟野路子搞出来的,完全没学过理论,平时就完全用不上二进制啊。先补课学下二进制再继续。
一段时间过去了,然后了解到 python 里的位移,然后就会做了,尽管代码很累赘
class Solution:def divide(self, dividend: int, divisor: int) -> int:n = 0f = 1 # 默认是正数if divisor < 0:f = 0 - fdivisor = 0 - divisorif dividend < 0:f = 0 - fdividend = 0 - dividendm = [0] # 存放位移的次数和位移的数量while dividend >= divisor:d = divisorwhile dividend > d << 1:d = d << 1m[-1] += 1dividend -= dm.append(0)for i in range(len(m) - 1):n += 1 << m[i] # 将位移的结果相加,就是商if f < 0: # 补上符号n = 0 - nmx = 2 ** 31 -1mn = -2 ** 31n = n if n < mx else mxn = n if n > mn else mnreturn n
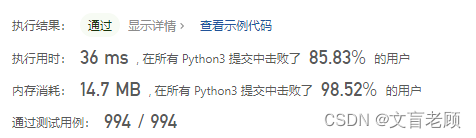
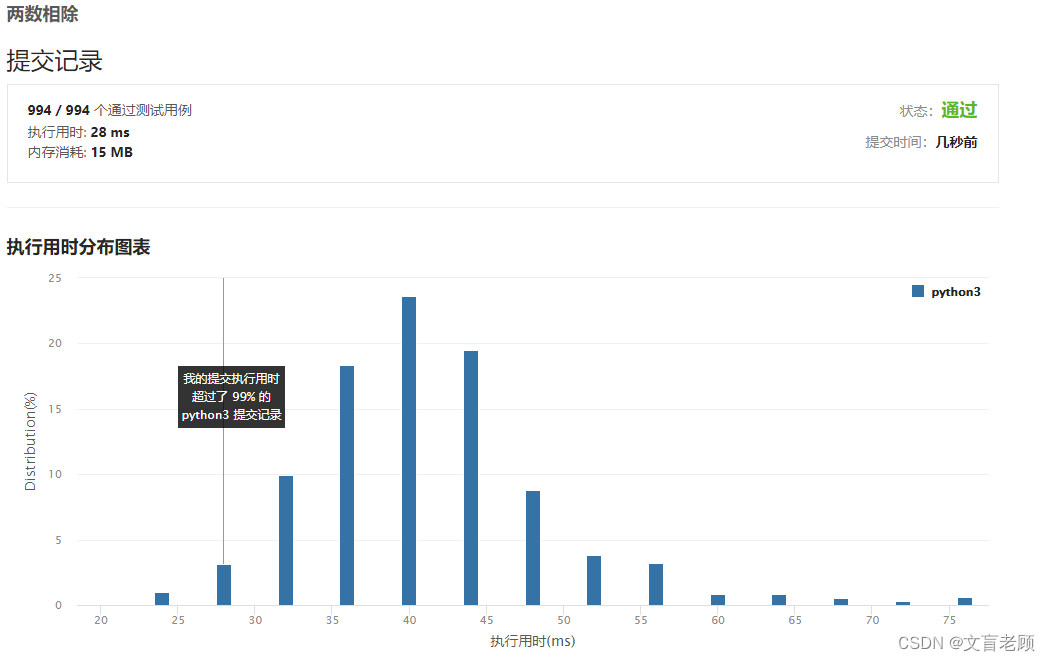
然后看大佬的答案

这个思路不错,是我的了,拿来吧您呐
24ms的答案思路清奇。。。。这个拿不过来。。。感觉不如用28ms大佬的实用和泛用
30. 串联所有单词的子串
给定一个字符串 s 和一个字符串数组 words。 words 中所有字符串 长度相同。
s 中的 串联子串 是指一个包含 words 中所有字符串以任意顺序排列连接起来的子串。
例如,如果 words = [“ab”,“cd”,“ef”], 那么 “abcdef”, “abefcd”,“cdabef”, “cdefab”,“efabcd”, 和 “efcdab” 都是串联子串。 “acdbef” 不是串联子串,因为他不是任何 words 排列的连接。
返回所有串联字串在 s 中的开始索引。你可以以 任意顺序 返回答案。
示例 1:
输入:s = “barfoothefoobarman”, words = [“foo”,“bar”]
输出:[0,9]
解释:因为 words.length == 2 同时 words[i].length == 3,连接的子字符串的长度必须为 6。
子串 “barfoo” 开始位置是 0。它是 words 中以 [“bar”,“foo”] 顺序排列的连接。
子串 “foobar” 开始位置是 9。它是 words 中以 [“foo”,“bar”] 顺序排列的连接。
输出顺序无关紧要。返回 [9,0] 也是可以的。
示例 2:
输入:s = “wordgoodgoodgoodbestword”, words = [“word”,“good”,“best”,“word”]
输出:[]
解释:因为 words.length == 4 并且 words[i].length == 4,所以串联子串的长度必须为 16。
s 中没有子串长度为 16 并且等于 words 的任何顺序排列的连接。
所以我们返回一个空数组。
示例 3:
输入:s = “barfoofoobarthefoobarman”, words = [“bar”,“foo”,“the”]
输出:[6,9,12]
解释:因为 words.length == 3 并且 words[i].length == 3,所以串联子串的长度必须为 9。
子串 “foobarthe” 开始位置是 6。它是 words 中以 [“foo”,“bar”,“the”] 顺序排列的连接。
子串 “barthefoo” 开始位置是 9。它是 words 中以 [“bar”,“the”,“foo”] 顺序排列的连接。
子串 “thefoobar” 开始位置是 12。它是 words 中以 [“the”,“foo”,“bar”] 顺序排列的连接。
提示:
1 <= s.length <= 10^4
1 <= words.length <= 5000
1 <= words[i].length <= 30
words[i] 和 s 由小写英文字母组成
通过次数153,336提交次数387,214
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/substring-with-concatenation-of-all-words
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
哦,又一个最大组合可能,且寻找组合子项
一段时间过去了。。。。连续提交超时,有一个用例, words 数量18 个,这要组合出来。。。6402373705728000种可能?得嘞,这题考的不是排列组合了,换个思路吧
活用字典就好
class Solution:def findSubstring(self, s: str, words: List[str]) -> List[int]: d = set(words)p = sorted(words)m = len(words)n = len(words[0])z = []for i in range(len(s) - m * n + 1):if s[i:i + n] not in d:continueq = sorted([s[_ * n + i:(_ + 1) * n + i] for _ in range(m)])if p == q:z.append(i)return z
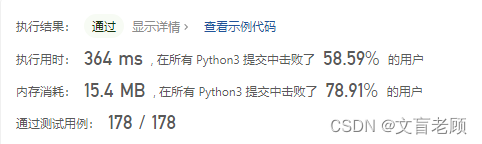
居然还在前一半里,我还以为排不上呢。整个思路就是,从任意位置判断,单词长度的字符串在不在words里,不在就不说了,在的话,取出同样数量的字串和 words 比较,我就不管你怎么组合了,直接看字符串能对不对的上就完了,本来是想用 set 差的,结果words里有重复的字符串。。。
结果,就这个思路下去的话,应该没办法优化执行时间了,去抄大佬们的思路看看,然后发现大佬们在用 collections 包,这。。。。python 不熟啊,纯粹兴趣,没用他工作过啊,包更不熟啊。。。算了,没有外部因素,估计300ms就是极限了。记下这个恨,以后再来报复。
小结
又10题做完了,感觉还是基础不牢。二进制居然还要回想补课,多简单的操作;括号生成也卡了一下,写了一片无用代码还没能完成;链表也才开始接触,还有很多需要学习的内容。
那么今天就到这里,下次继续刷题。