左耳听风:分布式
分布式系统介绍
分布式系统和单体系统
使用分布式系统主要有两方面原因。
- 增大系统容量。我们的业务量越来越大,而要能应对越来越大的业务量,一台机器的性能已经无法满足了,我们需要多台机器才能应对大规模的应用场景。所以,我们需要垂直或是水平拆分业务系统,让其变成一个分布式的架构。
- 加强系统可用。我们的业务越来越关键,需要提高整个系统架构的可用性,这就意味着架构中不能存在单点故障。这样,整个系统不会因为一台机器出故障而导致整体不可用。所以,需要通过分布式架构来冗余系统以消除单点故障,从而提高系统的可用性。
当然,分布式系统还有一些优势,比如:
- 因为模块化,所以系统模块重用度更高;
- 因为软件服务模块被拆分,开发和发布速度可以并行而变得更快;
- 系统扩展性更高;
- 团队协作流程也会得到改善;
- ……
单体应用和分布式架构的优缺点
| 传统单体架构 | 分布式服务化架构 | |
|---|---|---|
| 新功能开发 | 需要时间 | 容易开发和实现 |
| 部署 | 不经常发布,容易部署 | 经常发布,部署复杂 |
| 隔离性 | 故障影响范围大 | 故障影响范围小 |
| 架构设计 | 难度小 | 难度大 |
| 系统性能 | 响应时间快,吞吐量小 | 响应时间慢,吞吐量大 |
| 系统运维 | 简单 | 复杂 |
| 新人上手 | 学习曲线大(应用逻辑) | 学习曲线大(架构逻辑) |
| 技术 | 技术单一且封闭 | 技术多样且开放 |
| 测试和查错 | 简单 | 复杂 |
| 系统扩展性 | 扩展性差 | 扩展性好 |
| 系统管理 | 重点在于开发成本 | 重点在于服务治理和调度 |
从上面的表格我们可以看到,分布式系统虽然有一些优势,但也存在一些问题。
- 架构设计变得复杂(尤其是其中的分布式事务)。
- 部署单个服务会比较快,但是如果一次部署需要多个服务,流程会变得复杂。
- 系统的吞吐量会变大,但是响应时间会变长。
- 运维复杂度会因为服务变多而变得很复杂。
- 架构复杂导致学习曲线变大。
- 测试和查错的复杂度增大。
- 技术多元化,这会带来维护和运维的复杂度。
- 管理分布式系统中的服务和调度变得困难和复杂。
也就是说,分布式系统架构的难点在于系统设计,以及管理和运维。所以,分布式架构解决了“单点”和“性能容量”的问题,但却新增了一堆问题。而对于这些新增的问题,还会衍生出更多的子问题,这就需要我们不断地用各式各样的技术和手段来解决这些问题。
分布式系统的演变
从 20 世纪 70 年代的模块化编程,80 年代的面向事件设计,90 年代的基于接口 / 构件设计,这个世界很自然地演化出了 SOA——基于服务的架构。SOA 架构是构造分布式计算应用程序的方法。它将应用程序功能作为服务发送给最终用户或者其他服务。它采用开放标准与软件资源进行交互,并采用标准的表示方式。
开发、维护和使用 SOA 要遵循以下几条基本原则。
- 可重用,粒度合适,模块化,可组合,构件化以及有互操作性。
- 符合开放标准(通用的或行业的)。
- 服务的识别和分类,提供和发布,监控和跟踪。
面向服务的架构有以下三个阶段。
- 20 世纪 90 年代前,是单体架构,软件模块高度耦合。当然,这张图同样也说明了有的 SOA 架构其实和单体架构没什么两样,因为都是高度耦合在一起的。就像图中的齿轮一样,当你调用一个服务时,这个服务会调用另一个服务,然后又调用另外的服务……于是整个系统就转起来了。但是这本质是比较耦合的做法。
- 而 2000 年左右出现了比较松耦合的 SOA 架构,这个架构需要一个标准的协议或是中间件来联动其它相关联的服务(如 ESB)。这样一来,服务间并不直接依赖,而是通过中间件的标准协议或是通讯框架相互依赖。这其实就是 IoC(控制反转)和 DIP(依赖倒置原则)设计思想在架构中的实践。它们都依赖于一个标准的协议或是一个标准统一的交互方式,而不是直接调用。
- 而 2010 年后,出现了微服务架构,这个架构更为松耦合。每一个微服务都能独立完整地运行(所谓的自包含),后端单体的数据库也被微服务这样的架构分散到不同的服务中。而它和传统 SOA 的差别在于,服务间的整合需要一个服务编排或是服务整合的引擎。
一般来说,这个编排和组织引擎可以是工作流引擎,也可以是网关。当然,还需要辅助于像容器化调度这样的技术方式,如 Kubernetes。
微服务的出现使得开发速度变得更快,部署快,隔离性高,系统的扩展度也很好,但是在集成测试、运维和服务管理等方面就比较麻烦了。所以,需要一套比较好的微服务 PaaS 平台。就像 Spring Cloud 一样需要提供各种配置服务、服务发现、智能路由、控制总线……还有像 Kubernetes 提供的各式各样的部署和调度方式。
没有这些 PaaS 层的支撑,微服务也是很难被管理和运维的。
分布式系统中需要注意的问题
我们再来看一下分布式系统在技术上需要注意的问题。
问题一:异构系统的不标准问题
这主要表现在:
- 软件和应用不标准。
- 通讯协议不标准。
- 数据格式不标准。
- 开发和运维的过程和方法不标准。
不同的软件,不同的语言会出现不同的兼容性和不同的开发、测试、运维标准。不同的标准会让我们用不同的方式来开发和运维,引起架构复杂度的提升。比如:有的软件修改配置要改它的.conf 文件,而有的则是调用管理 API 接口。
在通讯方面,不同的软件用不同的协议,就算是相同的网络协议里也会出现不同的数据格式。还有,不同的团队因为使用不同的技术,也会有不同的开发和运维方式。这些不同的东西,会让我们的整个分布式系统架构变得异常复杂。所以,分布式系统架构需要有相应的规范。
比如,我看到,很多服务的 API 出错不返回 HTTP 的错误状态码,而是返回个正常的状态码 200,然后在 HTTP Body 里的 JSON 字符串中写着个:error,bla bla error message。这简直就是一种反人类的做法。我实在不明白为什么会有众多这样的设计。这让监控怎么做啊?现在,你应该使用 Swagger 的规范了。
再比如,我看到很多公司的软件配置管理里就是一个 key-value 的东西,这样的东西灵活到可以很容易地被滥用。不规范的配置命名,不规范的值,甚至在配置中直接嵌入前端展示内容……
一个好的配置管理,应该分成三层:底层和操作系统相关,中间层和中间件相关,最上面和业务应用相关。于是底层和中间层是不能让用户灵活修改的,而是只让用户选择。比如:操作系统的相关配置应该形成模板来让人选择,而不是让人乱配置的。只有配置系统形成了规范,我们才 hold 得住众多的系统。
再比如:数据通讯协议。通常来说,作为一个协议,一定要有协议头和协议体。协议头定义了最基本的协议数据,而协议体才是真正的业务数据。对于协议头,我们需要非常规范地让每一个使用这个协议的团队都使用一套标准的方式来定义,这样我们才容易对请求进行监控、调度和管理。
问题二:系统架构中的服务依赖性问题
对于传统的单体应用,一台机器挂了,整个软件就挂掉了。但是你千万不要以为在分布式的架构下不会发生这样的事。分布式架构下,服务是会有依赖的,一个服务依赖链上的某个服务挂掉了,可能会导致出现“多米诺骨牌”效应。
所以,在分布式系统中,服务的依赖也会带来一些问题。
- 如果非关键业务被关键业务所依赖,会导致非关键业务变成一个关键业务。
- 服务依赖链中,出现“木桶短板效应”——整个 SLA 由最差的那个服务所决定。
这是服务治理的内容了。服务治理不但需要我们定义出服务的关键程度,还需要我们定义或是描述出关键业务或服务调用的主要路径。没有这个事情,我们将无法运维或是管理整个系统。
这里需要注意的是,很多分布式架构在应用层上做到了业务隔离,然而,在数据库结点上并没有。如果一个非关键业务把数据库拖死,那么会导致全站不可用。所以,数据库方面也需要做相应的隔离。也就是说,最好一个业务线用一套自己的数据库。这就是亚马逊服务器的实践——系统间不能读取对方的数据库,只通过服务接口耦合。这也是微服务的要求。我们不但要拆分服务,还要为每个服务拆分相应的数据库。
问题三:故障发生的概率更大
在分布式系统中,因为使用的机器和服务会非常多,所以,故障发生的频率会比传统的单体应用更大。只不过,单体应用的故障影响面很大,而分布式系统中,虽然故障的影响面可以被隔离,但是因为机器和服务多,出故障的频率也会多。另一方面,因为管理复杂,而且没人知道整个架构中有什么,所以非常容易犯错误。
你会发现,对分布式系统架构的运维,简直就是一场噩梦。我们会慢慢地明白下面这些道理。
- 出现故障不可怕,故障恢复时间过长才可怕。
- 出现故障不可怕,故障影响面过大才可怕。
运维团队在分布式系统下会非常忙,忙到每时每刻都要处理大大小小的故障。我看到,很多大公司,都在自己的系统里拼命地添加各种监控指标,有的能够添加出几万个监控指标。我觉得这完全是在“使蛮力”。一方面,信息太多等于没有信息,另一方面,SLA 要求我们定义出“Key Metrics”,也就是所谓的关键指标。然而,他们却没有。这其实是一种思维上的懒惰。
但是,上述的都是在“救火阶段”而不是“防火阶段”。所谓“防火胜于救火”,我们还要考虑如何防火,这需要我们在设计或运维系统时都要为这些故障考虑,即所谓 Design for Failure。在设计时就要考虑如何减轻故障。如果无法避免,也要使用自动化的方式恢复故障,减少故障影响面。
因为当机器和服务数量越来越多时,你会发现,人类的缺陷就成为了瓶颈。这个缺陷就是人类无法对复杂的事情做到事无巨细的管理,只有机器自动化才能帮助人类。 也就是,人管代码,代码管机器,人不管机器!
问题四:多层架构的运维复杂度更大
通常来说,我们可以把系统分成四层:基础层、平台层、应用层和接入层。
- 基础层就是我们的机器、网络和存储设备等。
- 平台层就是我们的中间件层,Tomcat、MySQL、Redis、Kafka 之类的软件。
- 应用层就是我们的业务软件,比如,各种功能的服务。
- 接入层就是接入用户请求的网关、负载均衡或是 CDN、DNS 这样的东西。
对于这四层,我们需要知道:
- 任何一层的问题都会导致整体的问题;
- 没有统一的视图和管理,导致运维被割裂开来,造成更大的复杂度。
很多公司都是按技能分工的,他们按照技能把技术团队分为产品开发、中间件开发、业务运维、系统运维等子团队。这样的分工导致的结果就是大家各管一摊,很多事情完全连不在一起。整个系统会像 “多米诺骨牌”一样,一个环节出现问题,就会倒下去一大片。因为没有一个统一的运维视图,不知道一个服务调用是如何经过每一个服务和资源,也就导致在出现故障时要花大量的时间在沟通和定位问题上。
之前我在某云平台的一次经历就是这样的。从接入层到负载均衡,再到服务层,再到操作系统底层,设置的 KeepAlive 的参数完全不一致,导致用户发现,软件运行的行为和文档中定义的完全不一样。工程师查错的过程简直就是一场恶梦,以为找到了一个,结果还有一个,来来回回花了大量的时间才把所有 KeepAlive 的参数设置成一致的,浪费了太多的时间。
分工不是问题,问题是分工后的协作是否统一和规范。这点,你一定要重视。
分布式系统的技术栈
构建分布式系统的目的是增加系统容量,提高系统的可用性,转换成技术方面,也就是完成下面两件事。
- 大流量处理。通过集群技术把大规模并发请求的负载分散到不同的机器上。
- 关键业务保护。提高后台服务的可用性,把故障隔离起来阻止多米诺骨牌效应(雪崩效应)。如果流量过大,需要对业务降级,以保护关键业务流转。
说白了就是干两件事。一是提高整体架构的吞吐量,服务更多的并发和流量,二是为了提高系统的稳定性,让系统的可用性更高。
提高架构的性能
咱们先来看看,提高系统性能的常用技术。

- 缓存系统。加入缓存系统,可以有效地提高系统的访问能力。从前端的浏览器,到网络,再到后端的服务,底层的数据库、文件系统、硬盘和 CPU,全都有缓存,这是提高快速访问能力最有效的手段。对于分布式系统下的缓存系统,需要的是一个缓存集群。这其中需要一个 Proxy 来做缓存的分片和路由。
- 负载均衡系统。负载均衡系统是水平扩展的关键技术,它可以使用多台机器来共同分担一部分流量请求。
- 异步调用。异步系统主要通过消息队列来对请求做排队处理,这样可以把前端的请求的峰值给“削平”了,而后端通过自己能够处理的速度来处理请求。这样可以增加系统的吞吐量,但是实时性就差很多了。同时,还会引入消息丢失的问题,所以要对消息做持久化,这会造成“有状态”的结点,从而增加了服务调度的难度。
- 数据分区和数据镜像。数据分区是把数据按一定的方式分成多个区(比如通过地理位置),不同的数据区来分担不同区的流量。这需要一个数据路由的中间件,会导致跨库的 Join 和跨库的事务非常复杂。而数据镜像是把一个数据库镜像成多份一样的数据,这样就不需要数据路由的中间件了。你可以在任意结点上进行读写,内部会自行同步数据。然而,数据镜像中最大的问题就是数据的一致性问题。
对于一般公司来说,在初期,会使用读写分离的数据镜像方式,而后期会采用分库分表的方式。
提高架构的稳定性
接下来,咱们再来看看提高系统系统稳定性的一些常用技术。

- 服务拆分。服务拆分主要有两个目的:一是为了隔离故障,二是为了重用服务模块。但服务拆分完之后,会引入服务调用间的依赖问题。
- 服务冗余。服务冗余是为了去除单点故障,并可以支持服务的弹性伸缩,以及故障迁移。然而,对于一些有状态的服务来说,冗余这些有状态的服务带来了更高的复杂性。其中一个是弹性伸缩时,需要考虑数据的复制或是重新分片,迁移的时候还要迁移数据到其它机器上。
- 限流降级。当系统实在扛不住压力时,只能通过限流或者功能降级的方式来停掉一部分服务,或是拒绝一部分用户,以确保整个架构不会挂掉。这些技术属于保护措施。
- 高可用架构。通常来说高可用架构是从冗余架构的角度来保障可用性。比如,多租户隔离,灾备多活,或是数据可以在其中复制保持一致性的集群。总之,就是为了不出单点故障。
- 高可用运维。高可用运维指的是 DevOps 中的 CI/CD(持续集成 / 持续部署)。一个良好的运维应该是一条很流畅的软件发布管线,其中做了足够的自动化测试,还可以做相应的灰度发布,以及对线上系统的自动化控制。这样,可以做到“计划内”或是“非计划内”的宕机事件的时长最短。
上述这些技术非常有技术含量,而且需要投入大量的时间和精力。
分布式系统的关键技术
引入分布式系统,会引入一堆技术问题,需要从以下几个方面来解决。
- 服务治理。服务拆分、服务调用、服务发现、服务依赖、服务的关键度定义……服务治理的最大意义是需要把服务间的依赖关系、服务调用链,以及关键的服务给梳理出来,并对这些服务进行性能和可用性方面的管理。
- 架构软件管理。服务之间有依赖,而且有兼容性问题,所以,整体服务所形成的架构需要有架构版本管理、整体架构的生命周期管理,以及对服务的编排、聚合、事务处理等服务调度功能。
- DevOps。分布式系统可以更为快速地更新服务,但是对于服务的测试和部署都会是挑战。所以,还需要 DevOps 的全流程,其中包括环境构建、持续集成、持续部署等。
- 自动化运维。有了 DevOps 后,我们就可以对服务进行自动伸缩、故障迁移、配置管理、状态管理等一系列的自动化运维技术了。
- 资源调度管理。应用层的自动化运维需要基础层的调度支持,也就是云计算 IaaS 层的计算、存储、网络等资源调度、隔离和管理。
- 整体架构监控。如果没有一个好的监控系统,那么自动化运维和资源调度管理只可能成为一个泡影,因为监控系统是你的眼睛。没有眼睛,没有数据,就无法进行高效的运维。所以说,监控是非常重要的部分。这里的监控需要对三层系统(应用层、中间件层、基础层)进行监控。
- 流量控制。最后是我们的流量控制,负载均衡、服务路由、熔断、降级、限流等和流量相关的调度都会在这里,包括灰度发布之类的功能也在这里。
有一个技术叫——Docker,通过 Docker 以及其衍生出来的 Kubernetes 之类的软件或解决方案,大大地降低了做上面很多事情的门槛。Docker 把软件和其运行的环境打成一个包,然后比较轻量级地启动和运行。在运行过程中,因为软件变成了服务可能会改变现有的环境。但是没关系,当你重新启动一个 Docker 的时候,环境又会变成初始化状态。
这样一来,我们就可以利用 Docker 的这个特性来把软件在不同的机器上进行部署、调度和管理。如果没有 Docker 或是 Kubernetes,那么你可以认为我们还活在“原始时代”。
现在你知道为什么 Docker 这样的容器化虚拟化技术是未来了吧。因为分布式系统已经是完全不可逆转的技术趋势了。
但是,上面还有很多的技术是 Docker 及其周边技术没有解决的,所以,依然还有很多事情要做。那么,如果是一个一个地去做这些技术的话,就像是我们在撑开一张网里面一个一个的网眼,本质上这是使蛮力的做法。我们希望可以找到系统的“纲”,一把就能张开整张网。那么,这个纲在哪里呢?
分布式系统的“纲”
分布式系统有五个关键技术,它们是:
- 全栈系统监控;
- 服务 / 资源调度;
- 流量调度;
- 状态 / 数据调度;
- 开发和运维的自动化。
而最后一项——开发和运维的自动化,是需要把前四项都做到了,才有可能实现的。所以,最为关键是下面这四项技术,即应用整体监控、资源和服务调度、状态和数据调度及流量调度,它们是构建分布式系统最最核心的东西。

小结
首先,我总结了分布式系统需要干的两件事:一是提高整体架构的吞吐量,服务更多的并发和流量,二是为了提高系统的稳定性,让系统的可用性更高。然后分别从这两个方面阐释,需要通过哪些技术来实现,并梳理出其中的技术难点及可能会带来的问题。最后,欢迎你分享一下你在解决系统的性能和可用性方面使用到的方法和技巧。
虽然 Docker 及其衍生出来的 Kubernetes 等软件或解决方案,能极大地降低很多事儿的门槛。但它们没有解决的问题还有很多,需要掌握分布式系统的五大关键技术,从根本上解决问题。
分布式系统关键技术:全栈监控
在分布式或 Cloud Native 的情况下,系统分成多层,服务各种关联,需要监控的东西特别多。没有一个好的监控系统,我们将无法进行自动化运维和资源调度。
这个监控系统需要完成的功能为:
- 全栈监控;
- 关联分析;
- 跨系统调用的串联;
- 实时报警和自动处置;
- 系统性能分析。
多层体系的监控
所谓全栈监控,其实就是三层监控。
- 基础层:监控主机和底层资源。比如:CPU、内存、网络吞吐、硬盘 I/O、硬盘使用等。
- 中间层:就是中间件层的监控。比如:Nginx、Redis、ActiveMQ、Kafka、MySQL、Tomcat 等。
- 应用层:监控应用层的使用。比如:HTTP 访问的吞吐量、响应时间、返回码,调用链路分析,性能瓶颈,还包括用户端的监控。
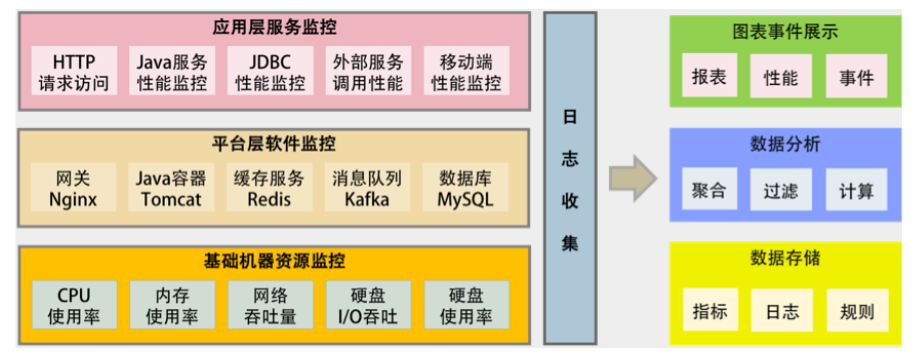
还需要一些监控的标准化。
- 日志数据结构化;
- 监控数据格式标准化;
- 统一的监控平台;
- 统一的日志分析。
什么才是好的监控系统
这里还要多说一句,现在我们的很多监控系统都做得很不好,它们主要有两个很大的问题。
- 监控数据是隔离开来的。因为公司分工的问题,开发、应用运维、系统运维,各管各的,所以很多公司的监控系统之间都有一道墙,完全串不起来。
- 监控的数据项太多。有些公司的运维团队把监控的数据项多做为一个亮点到处讲,比如监控指标达到 5 万多个。老实说,这太丢人了。因为信息太多等于没有信息,抓不住重点的监控才会做成这个样子,完全就是使蛮力的做法。
一个好的监控系统应该有以下几个特征。
- 关注于整体应用的 SLA。主要从为用户服务的 API 来监控整个系统。
- 关联指标聚合。 把有关联的系统及其指标聚合展示。主要是三层系统数据:基础层、平台中间件层和应用层。其中,最重要的是把服务和相关的中间件以及主机关联在一起,服务有可能运行在 Docker 中,也有可能运行在微服务平台上的多个 JVM 中,也有可能运行在 Tomcat 中。总之,无论运行在哪里,我们都需要把服务的具体实例和主机关联在一起,否则,对于一个分布式系统来说,定位问题犹如大海捞针。
- 快速故障定位。 对于现有的系统来说,故障总是会发生的,而且还会频繁发生。故障发生不可怕,可怕的是故障的恢复时间过长。所以,快速地定位故障就相当关键。快速定位问题需要对整个分布式系统做一个用户请求跟踪的 trace 监控,我们需要监控到所有的请求在分布式系统中的调用链,这个事最好是做成没有侵入性的。
换句话说,一个好的监控系统主要是为以下两个场景所设计的。
“体检”
- 容量管理。 提供一个全局的系统运行时数据的展示,可以让工程师团队知道是否需要增加机器或者其它资源。
- 性能管理。可以通过查看大盘,找到系统瓶颈,并有针对性地优化系统和相应代码。
“急诊”
- 定位问题。可以快速地暴露并找到问题的发生点,帮助技术人员诊断问题。
- 性能分析。当出现非预期的流量提升时,可以快速地找到系统的瓶颈,并帮助开发人员深入代码。
只有做到了上述的这些关键点才能是一个好的监控系统。
如何做出一个好的监控系统
下面是我认为一个好的监控系统应该实现的功能。
-
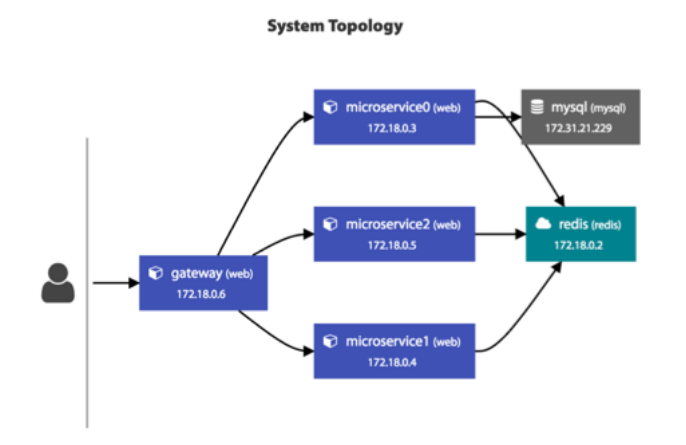
服务调用链跟踪。这个监控系统应该从对外的 API 开始,然后将后台的实际服务给关联起来,然后再进一步将这个服务的依赖服务关联起来,直到最后一个服务(如 MySQL 或 Redis),这样就可以把整个系统的服务全部都串连起来了。这个事情的最佳实践是 Google Dapper 系统,其对应于开源的实现是 Zipkin。对于 Java 类的服务,我们可以使用字节码技术进行字节码注入,做到代码无侵入式。
如下图所示(截图来自我做的一个 APM 的监控系统)。
-
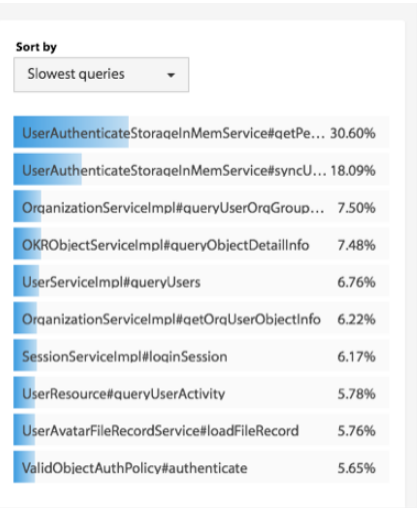
服务调用时长分布。使用 Zipkin,可以看到一个服务调用链上的时间分布,这样有助于我们知道最耗时的服务是什么。下图是 Zipkin 的服务调用时间分布。

-
服务的 TOP N 视图。所谓 TOP N 视图就是一个系统请求的排名情况。一般来说,这个排名会有三种排名的方法:a)按调用量排名,b) 按请求最耗时排名,c)按热点排名(一个时间段内的请求次数的响应时间和)。
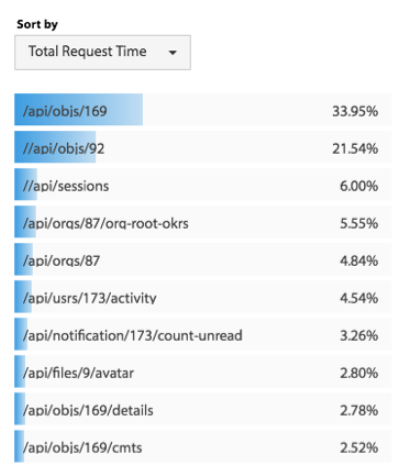
-
数据库操作关联。对于 Java 应用,我们可以很方便地通过 JavaAgent 字节码注入技术拿到 JDBC 执行数据库操作的执行时间。对此,我们可以和相关的请求对应起来。
-
服务资源跟踪。我们的服务可能运行在物理机上,也可能运行在虚拟机里,还可能运行在一个 Docker 的容器里,Docker 容器又运行在物理机或是虚拟机上。我们需要把服务运行的机器节点上的数据(如 CPU、MEM、I/O、DISK、NETWORK)关联起来。
这样一来,我们就可以知道服务和基础层资源的关系。如果是 Java 应用,我们还要和 JVM 里的东西进行关联,这样我们才能知道服务所运行的 JVM 中的情况(比如 GC 的情况)。
有了这些数据上的关联,我们就可以达到如下的目标。
- 当一台机器挂掉是因为 CPU 或 I/O 过高的时候,我们马上可以知道其会影响到哪些对外服务的 API。
- 当一个服务响应过慢的时候,我们马上能关联出来是否在做 Java GC,或是其所在的计算结点上是否有资源不足的情况,或是依赖的服务是否出现了问题。
- 当发现一个 SQL 操作过慢的时候,我们能马上知道其会影响哪个对外服务的 API。
- 当发现一个消息队列拥塞的时候,我们能马上知道其会影响哪些对外服务的 API。
总之,我们就是想知道用户访问哪些请求会出现问题,这对于我们了解故障的影响面非常有帮助。
一旦了解了这些信息,我们就可以做出调度。比如:
- 一旦发现某个服务过慢是因为 CPU 使用过多,我们就可以做弹性伸缩。
- 一旦发现某个服务过慢是因为 MySQL 出现了一个慢查询,我们就无法在应用层上做弹性伸缩,只能做流量限制,或是降级操作了。
所以,一个分布式系统,或是一个自动化运维系统,或是一个 Cloud Native 的云化系统,最重要的事就是把监控系统做好。在把数据收集好的同时,更重要的是把数据关联好。这样,我们才可能很快地定位故障,进而才能进行自动化调度。
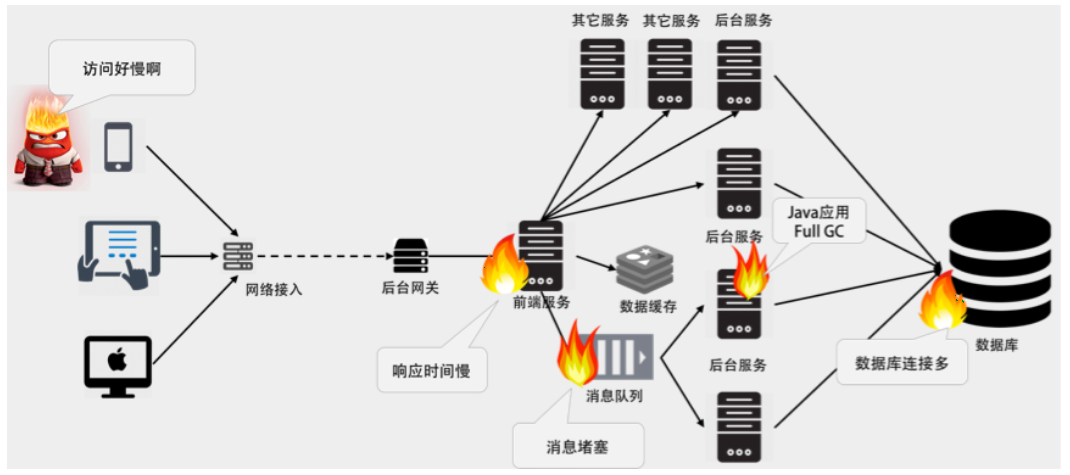
上图只是简单地展示了一个分布式系统的服务调用链接上都在报错,其根本原因是数据库链接过多,服务不过来。另外一个原因是,Java 在做 Full GC 导致处理过慢。于是,消息队列出现消息堆积堵塞。这个图只是一个示例,其形象地体现了在分布式系统中监控数据关联的重要性。
分布式系统关键技术:服务调度
服务治理上的一些关键技术,主要有以下几点。
- 服务关键程度
- 服务依赖关系
- 服务发现
- 整个架构的版本管理
- 服务应用生命周期全管理
服务关键程度和服务的依赖关系
下面,我们先看看服务关键程度和服务的依赖关系。关于服务关键程度,主要是要我们梳理和定义服务的重要程度。这不是使用技术可以完成的,它需要细致地管理对业务的理解,才能定义出架构中各个服务的重要程度。
然后,我们还要梳理出服务间的依赖关系,这点也非常重要。我们常说,“没有依赖,就没有伤害”。这句话的意思就是说,服务间的依赖是一件很易碎的事。依赖越多,依赖越复杂,我们的系统就越易碎。
因为依赖关系就像“铁锁连环”一样,一个服务的问题很容易出现一条链上的问题。因此,传统的 SOA 希望通过 ESB 来解决服务间的依赖关系,这也是为什么微服务中希望服务间是没有依赖的,而让上层或是前端业务来整合这些个后台服务。
但是要真正做到服务无依赖,我认为还是比较有困难的,总是会有一些公有服务会被依赖。我们只能是降低服务依赖的深度和广度,从而让管理更为简单和简洁。在这一点上,以 Spring Boot 为首的微服务开发框架就开了一个好头。
微服务是服务依赖最优解的上限,而服务依赖的下限是千万不要有依赖环。如果系统架构中有服务依赖环,那么表明你的架构设计是错误的。循环依赖有很多的副作用,最大的问题是这是一种极强的耦合,会导致服务部署相当复杂和难解,而且会导致无穷尽的递归故障和一些你意想不到的问题。
解决服务依赖环的方案一般是,依赖倒置的设计模式。在分布式架构上,你可以使用一个第三方的服务来解决这个事。比如,通过订阅或发布消息到一个消息中间件,或是把其中的依赖关系抽到一个第三方的服务中,然后由这个第三方的服务来调用这些原本循环依赖的服务。
服务的依赖关系是可以通过技术的手段来发现的,这其中,Zipkin是一个很不错的服务调用跟踪系统,它是通过 Google Dapper这篇论文来实现的。这个工具可以帮你梳理服务的依赖关系,以及了解各个服务的性能。
腾讯的tars也带有versionset,配合序列化协议实现兼容和升级也是非常便利。
在梳理完服务的重要程度和服务依赖关系之后,我们就相当于知道了整个架构的全局。就好像我们得到了一张城市地图,在这张地图上可以看到城市的关键设施,以及城市的主干道。再加上相关的监控,我们就可以看到城市各条道路上的工作和拥堵情况。这对于我们整个分布式架构是非常非常关键的。
我给很多公司做过相关的咨询。当他们需要我帮忙解决一些高并发或是架构问题的时候,我一般都会向他们要一张这样的“地图”,但是几乎所有的公司都没有这样的地图。
服务状态和生命周期的管理
有了上面这张地图后,我们还需要有一个服务发现的中间件,这个中间件是非常非常关键的。因为这个“架构城市”是非常动态的,有的服务会新加进来,有的会离开,有的会增加更多的实例,有的会减少,有的服务在维护过程中(发布、伸缩等),所以我们需要有一个服务注册中心,来知道这么几个事。
- 整个架构中有多少种服务?
- 这些服务的版本是什么样的?
- 每个服务的实例数有多少个,它们的状态是什么样的?
- 每个服务的状态是什么样的?是在部署中,运行中,故障中,升级中,还是在回滚中,伸缩中,或者是在下线中……
这个服务注册中心有点像我们系统运维同学说的 CMDB 这样的东西,它也是非常之关键的,因为没有它,我们将无法知道这些服务运作的状态和情况。
有了这些服务的状态和运行情况之后,你就需要对这些服务的生命周期进行管理了。服务的生命周期通常会有以下几个状态:
- Provision,代表在供应一个新的服务;
- Ready,表示启动成功了;
- Run,表示通过了服务健康检查;
- Update,表示在升级中;
- Rollback,表示在回滚中;
- Scale,表示正在伸缩中(可以有 Scale-in 和 Scale-out 两种);
- Destroy,表示在销毁中;
- Failed,表示失败状态。
这几个状态需要管理好,不然的话,你将不知道这些服务在什么样的状态下。不知道在什么样的状态下,你对整个分布式架构也就无法控制了。
有了这些服务的状态和生命周期的管理,以及服务的重要程度和服务的依赖关系,再加上一个服务运行状态的拟合控制(后面会提到),你一下子就有了管理整个分布式服务的手段了。
一个纷乱无比的世界从此就可以干干净净地管理起来了。
整个架构的版本管理
对于整个架构的版本管理这个事,我只见到亚马逊有这个东西,叫 VersionSet,也就是由一堆服务的版本集所形成的整个架构的版本控制。
除了各个项目的版本管理之外,还需要在上面再盖一层版本管理。如果 Build 过 Linux 分发包,那么你就会知道,Linux 分发包中各个软件的版本上会再盖一层版本控制。毕竟,这些分发包也是有版本依赖的,这样可以解决各个包的版本兼容性问题。
所以,在分布式架构中,我们也需要一个架构的版本,用来控制其中各个服务的版本兼容。比如,A 服务的 1.2 版本只能和 B 服务的 2.2 版本一起工作,A 服务的上个版本 1.1 只能和 B 服务的 2.0 一起工作。这就是版本兼容性。
如果架构中有这样的问题,那么我们就需要一个上层架构的版本管理。这样,如果我们要回滚一个服务的版本,就可以把与之有版本依赖的服务也一起回滚掉。
当然,一般来说,在设计过程中,我们希望没有版本的依赖性问题。但可能有些时候,我们会有这样的问题,那么就需要在架构版本中记录下这个事,以便可以回滚到上一次相互兼容的版本。
要做到这个事,你需要一个架构的 manifest,一个服务清单,这个服务清单定义了所有服务的版本运行环境,其中包括但不限于:
- 服务的软件版本;
- 服务的运行环境——环境变量、CPU、内存、可以运行的结点、文件系统等;
- 服务运行的最大最小实例数。
每一次对这个清单的变更都需要被记录下来,算是一个架构的版本管理。而我们上面所说的那个集群控制系统需要能够解读并执行这个清单中的变更,以操作和管理整个集群中的相关变更。
资源 / 服务调度
服务和资源的调度有点像操作系统。操作系统一方面把用户进程在硬件资源上进行调度,另一方面提供进程间的通信方式,可以让不同的进程在一起协同工作。服务和资源调度的过程,与操作系统调度进程的方式很相似,主要有以下一些关键技术。
- 服务状态的维持和拟合。
- 服务的弹性伸缩和故障迁移。
- 作业和应用调度。
- 作业工作流编排。
- 服务编排。
服务状态的维持和拟合
所谓服务状态不是服务中的数据状态,而是服务的运行状态,换句话说就是服务的 Status,而不是 State。也就是上述服务运行时生命周期中的状态——Provision,Ready,Run,Scale,Rollback,Update,Destroy,Failed……
服务运行时的状态是非常关键的。服务运行过程中,状态也是会有变化的,这样的变化有两种。
- 一种是不预期的变化。比如,服务运行因为故障导致一些服务挂掉,或是别的什么原因出现了服务不健康的状态。而一个好的集群管理控制器应该能够强行维护服务的状态。在健康的实例数变少时,控制器会把不健康的服务给摘除,而又启动几个新的,强行维护健康的服务实例数。
- 另外一种是预期的变化。比如,我们需要发布新版本,需要伸缩,需要回滚。这时,集群管理控制器就应该把集群从现有状态迁移到另一个新的状态。这个过程并不是一蹴而就的,集群控制器需要一步一步地向集群发送若干控制命令。这个过程叫“拟合”——从一个状态拟合到另一个状态,而且要穷尽所有的可能,玩命地不断地拟合,直到达到目的。
详细说明一下,对于分布式系统的服务管理来说,当需要把一个状态变成另一个状态时,我们需要对集群进行一系列的操作。比如,当需要对集群进行 Scale 的时候,我们需要:
- 先扩展出几个结点;
- 再往上部署服务;
- 然后启动服务;
- 再检查服务的健康情况;
- 最后把新扩展出来的服务实例加入服务发现中提供服务。
可以看到,这是一个比较稳健和严谨的 Scale 过程,这需要集群控制器往生产集群中进行若干次操作。
这个操作的过程一定是比较“慢”的。一方面,需要对其它操作排它;另一方面,在整个过程中,我们的控制系统需要努力地逼近最终状态,直到完全达到。此外,正在运行的服务可能也会出现问题,离开了我们想要的状态,而控制系统检测到后,会强行地维持服务的状态。
我们把这个过程就叫做“拟合”。基本上来说,集群控制系统都是要干这个事的。没有这种设计的控制系统都不能算做设计精良的控制系统,而且在运行时一定会有很多的坑和 bug。
如果研究过 Kubernetes 这个调度控制系统,你就会看到它的思路就是这个样子的。
服务的弹性伸缩和故障迁移
有了上述的服务状态拟合的基础工作之后,我们就能很容易地管理服务的生命周期了,甚至可以通过底层的支持进行便利的服务弹性伸缩和故障迁移。
对于弹性伸缩,在上面我已经给出了一个服务伸缩所需要的操作步骤。还是比较复杂的,其中涉及到了:
- 底层资源的伸缩;
- 服务的自动化部署;
- 服务的健康检查;
- 服务发现的注册;
- 服务流量的调度。
而对于故障迁移,也就是服务的某个实例出现问题时,我们需要自动地恢复它。对于服务来说,有两种模式,一种是宠物模式,一种是奶牛模式。
- 所谓宠物模式,就是一定要救活,主要是对于 stateful 的服务。
- 而奶牛模式,就是不救活了,重新生成一个实例。
对于这两种模式,在运行中也是比较复杂的,其中涉及到了:
- 服务的健康监控(这可能需要一个 APM 的监控)。
- 如果是宠物模式,需要:服务的重新启动和服务的监控报警(如果重试恢复不成功,需要人工介入)。
- 如果是奶牛模式,需要:服务的资源申请,服务的自动化部署,服务发现的注册,以及服务的流量调度。
我们可以看到,弹性伸缩和故障恢复需要很相似的技术步骤。但是,要完成这些事情并不容易,你需要做很多工作,而且有很多细节上的问题会让你感到焦头烂额。
当然,好消息是,我们非常幸运地生活在了一个比较不错的时代,因为有 Docker 和 Kubernetes 这样的技术,可以非常容易地让我们做这个工作。
但是,需要把传统的服务迁移到 Docker 和 Kubernetes 上来,再加上更上层的对服务生命周期的控制系统的调度,我们就可以做到一个完全自动化的运维架构了。
服务工作流和编排
正如上面和操作系统做的类比一样,一个好的操作系统需要能够通过一定的机制把一堆独立工作的进程给协同起来。在分布式的服务调度中,这个工作叫做 Orchestration,国内把这个词翻译成“编排”。
从《分布式系统架构的冰与火》一文中的 SOA 架构演化图来看,要完成这个编排工作,传统的 SOA 是通过 ESB(Enterprise Service Bus)——企业服务总线来完成的。ESB 的主要功能是服务通信路由、协议转换、服务编制和业务规则应用等。
注意,ESB 的服务编制叫 Choreography,与我们说的 Orchestration 是不一样的。
- Orchestration 的意思是,一个服务像大脑一样来告诉大家应该怎么交互,就跟乐队的指挥一样。(查看Service-oriented Design:A Multi-viewpoint Approach,了解更多信息)。
- Choreography 的意思是,在各自完成专属自己的工作的基础上,怎样互相协作,就跟芭蕾舞团的舞者一样。
而在微服务中,我们希望使用更为轻量的中间件来取代 ESB 的服务编排功能。
简单来说,这需要一个 API Gateway 或一个简单的消息队列来做相应的编排工作。在 Spring Cloud 中,所有的请求都统一通过 API Gateway(Zuul)来访问内部的服务。这个和 Kubernetes 中的 Ingress 相似。
我觉得,关于服务的编排会直接导致一个服务编排的工作流引擎中间件的产生,这可能是因为我受到了亚马逊的软件工程文化的影响所致——亚马逊是一家超级喜欢工作流引擎的公司。通过工作流引擎,可以非常快速地将若干个服务编排起来形成一个业务流程。(你可以看一下 AWS 上的 Simple Workflow 服务。)
这就是所谓的 Orchestration 中的 conductor 指挥了。
小结
总结一下今天的主要内容:我们从服务关键程度、服务依赖关系、整个架构的版本管理等多个方面,全面阐述了分布式系统架构五大关键技术之一——服务资源调度。希望这些内容能对你有所启发。
分布式系统关键技术:流量与数据调度
关于流量调度,现在很多架构师都把这个事和服务治理混为一谈了。我觉得还是应该分开的。一方面,服务治理是内部系统的事,而流量调度可以是内部的,更是外部接入层的事。另一方面,服务治理是数据中心的事,而流量调度要做得好,应该是数据中心之外的事,也就是我们常说的边缘计算,是应该在类似于 CDN 上完成的事。
所以,流量调度和服务治理是在不同层面上的,不应该混在一起,所以在系统架构上应该把它们分开。
流量调度的主要功能
对于一个流量调度系统来说,其应该具有的主要功能是:
- 依据系统运行的情况,自动地进行流量调度,在无需人工干预的情况下,提升整个系统的稳定性;
- 让系统应对爆品等突发事件时,在弹性计算扩缩容的较长时间窗口内或底层资源消耗殆尽的情况下,保护系统平稳运行。
这还是为了提高系统架构的稳定性和高可用性。
此外,这个流量调度系统还可以完成以下几方面的事情。
- 服务流控。服务发现、服务路由、服务降级、服务熔断、服务保护等。
- 流量控制。负载均衡、流量分配、流量控制、异地灾备(多活)等。
- 流量管理。协议转换、请求校验、数据缓存、数据计算等。
所有的这些都应该是一个 API Gateway 应该做的事。
流量调度的关键技术
但是,作为一个 API Gateway 来说,因为要调度流量,首先需要扛住流量,而且还需要有一些比较轻量的业务逻辑,所以一个好的 API Gateway 需要具备以下的关键技术。
- 高性能。API Gateway 必须使用高性能的技术,所以,也就需要使用高性能的语言。
- 扛流量。要能扛流量,就需要使用集群技术。集群技术的关键点是在集群内的各个结点中共享数据。这就需要使用像 Paxos、Raft、Gossip 这样的通讯协议。因为 Gateway 需要部署在广域网上,所以还需要集群的分组技术。
- 业务逻辑。API Gateway 需要有简单的业务逻辑,所以,最好是像 AWS 的 Lambda 服务一样,可以让人注入不同语言的简单业务逻辑。
- 服务化。一个好的 API Gateway 需要能够通过 Admin API 来不停机地管理配置变更,而不是通过一个.conf 文件来人肉地修改配置。
基于上述的这几个技术要求,就其本质来说,目前可以做成这样的 API Gateway 几乎没有。这也是为什么我现在自己自主开发的原因(你可以到我的官网 MegaEase.com 上查看相关的产品和技术信息)。
状态数据调度
对于服务调度来说,最难办的就是有状态的服务了。这里的状态是 State,也就是说,有些服务会保存一些数据,而这些数据是不能丢失的,所以,这些数据是需要随服务一起调度的。
一般来说,我们会通过“转移问题”的方法来让服务变成“无状态的服务”。也就是说,会把这些有状态的东西存储到第三方服务上,比如 Redis、MySQL、ZooKeeper,或是 NFS、Ceph 的文件系统中。
这些“转移问题”的方式把问题转移到了第三方服务上,于是自己的 Java 或 PHP 服务中没有状态,但是 Redis 和 MySQL 上则有了状态。所以,我们可以看到,现在的分布式系统架构中出问题的基本都是这些存储状态的服务。
因为数据存储结点在 Scale 上比较困难,所以成了一个单点的瓶颈。
分布式事务一致性的问题
要解决数据结点的 Scale 问题,也就是让数据服务可以像无状态的服务一样在不同的机器上进行调度,这就会涉及数据的 replication 问题。而数据 replication 则会带来数据一致性的问题,进而对性能带来严重的影响。
要解决数据不丢失的问题,只能通过数据冗余的方法,就算是数据分区,每个区也需要进行数据冗余处理。这就是数据副本。当出现某个节点的数据丢失时,可以从副本读到。数据副本是分布式系统解决数据丢失异常的唯一手段。简单来说:
- 要想让数据有高可用性,就得写多份数据。
- 写多份会引起数据一致性的问题。
- 数据一致性的问题又会引发性能问题。
在解决数据副本间的一致性问题时,我们有一些技术方案。
- Master-Slave 方案。
- Master-Master 方案。
- 两阶段和三阶段提交方案。
- Paxos 方案。
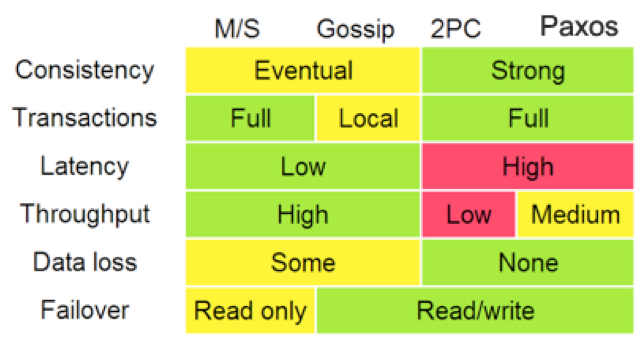
你可以仔细地读一下我在 3 年前写的《分布式系统的事务处理》这篇文章。其中我引用了 Google App Engine 联合创始人赖安·巴里特(Ryan Barrett)在 2009 年 Google I/O 上的演讲Transaction Across DataCenter 视频 中的一张图。

从上面这张经典的图中,我们可以看到各种不同方案的对比。
现在,很多公司的分布式系统事务基本上都是两阶段提交的变种。比如:阿里推出的 TCC–Try–Confirm–Cancel,或是我在亚马逊见到的 Plan–Reserve–Confirm 的方式,等等。凡是通过业务补偿,或是在业务应用层上做的分布式事务的玩法,基本上都是两阶段提交,或是两阶段提交的变种。
换句话说,迄今为止,在应用层上解决事务问题,只有“两阶段提交”这样的方式,而在数据层解决事务问题,Paxos 算法则是不二之选。
数据结点的分布式方案
真正完整解决数据 Scale 问题的应该还是数据结点自身。只有数据结点自身解决了这个问题,才能做到对上层业务层的透明,业务层可以像操作单机数据库一样来操作分布式数据库,这样才能做到整个分布式服务架构的调度。
也就是说,这个问题应该解决在数据存储方。但是因为数据存储结果有太多不同的 Scheme,所以现在的数据存储也是多种多样的,有文件系统,有对象型的,有 Key-Value 式,有时序的,有搜索型的,有关系型的……
这就是为什么分布式数据存储系统比较难做,因为很难做出来一个放之四海皆准的方案。类比一下编程中的各种不同的数据结构你就会明白为什么会有这么多的数据存储方案了。
但是我们可以看到,这个“数据存储的动物园”中,基本上都在解决数据副本、数据一致性和分布式事务的问题。
比如 AWS 的 Aurora,就是改写了 MySQL 的 InnoDB 引擎。为了承诺高可用的 SLA,所以需要写 6 个副本,但实现方式上,它不像 MySQL 通过 bin log 的数据复制方式,而是更为“惊艳”地复制 SQL 语句,然后拼命地使用各种 tricky 的方式来降低 latency。比如,使用多线程并行、使用 SQL 操作的 merge 等。
MySQL 官方也有 MySQL Cluster 的技术方案。此外,MongoDB、国内的 PingCAP 的 TiDB、国外的 CockroachDB,还有阿里的 OceanBase 都是为了解决大规模数据的写入和读取的问题而出现的数据库软件。所以,我觉得成熟的可以用到生产线上的分布式数据库这个事估计也不远了。
而对于一些需要文件存储的,则需要分布式文件系统的支持。试想,一个 Kafka 或 ZooKeeper 需要把它们的数据存储到文件系统上。当这个结点有问题时,我们需要再启动一个 Kafka 或 ZooKeeper 的实例,那么也需要把它们持久化的数据搬迁到另一台机器上。
(注意,虽然 Kafka 和 ZooKeeper 是 HA 的,数据会在不同的结点中进行复制,但是我们也应该搬迁数据,这样有利用于新结点的快速启动。否则,新的结点需要等待数据同步,这个时间会比较长,可能会导致数据层的其它问题。)
于是,我们就需要一个底层是分布式的文件系统,这样新的结点只需要做一个简单的远程文件系统的 mount 就可以把数据调度到另外一台机器上了。
所以,真正解决数据结点调度的方案应该是底层的数据结点。在它们上面做这个事才是真正有效和优雅的。而像阿里的用于分库分表的数据库中间件 TDDL 或是别的公司叫什么 DAL 之类的这样的中间件都会成为过渡技术。
状态数据调度小结
接下来,我们对状态数据调度做个小小的总结。
- 对于应用层上的分布式事务一致性,只有两阶段提交这样的方式。
- 而底层存储可以解决这个问题的方式是通过一些像 Paxos、Raft 或是 NWR 这样的算法和模型来解决。
- 状态数据调度应该是由分布式存储系统来解决的,这样会更为完美。但是因为数据存储的 Scheme 太多,所以,导致我们有各式各样的分布式存储系统,有文件对象的,有关系型数据库的,有 NoSQL 的,有时序数据的,有搜索数据的,有队列的……
总之,我相信状态数据调度应该是在 IaaS 层的数据存储解决的问题,而不是在 PaaS 层或者 SaaS 层来解决的。
在 IaaS 层上解决这个问题,一般来说有三种方案,一种是使用比较廉价的开源产品,如:NFS、Ceph、TiDB、CockroachDB、ElasticSearch、InfluxDB、MySQL Cluster 和 Redis Cluster 之类的;另一种是用云计算厂商的方案。当然,如果不差钱的话,可以使用更为昂贵的商业网络存储方案。
小结
回顾一下今天分享的主要内容。首先,我先明确表态,不要将流量调度和服务治理混为一谈(当然,服务治理是流量调度的前提),并比较了两者有何不同。
然后,讲述了流量调度的主要功能和关键技术。接着进入本文的第二个话题——状态数据调度,讲述了真正完整解决数据 Scale 问题的应该还是数据结点自身,并给出了相应的技术方案,随后对状态数据调度进行了小结。
洞悉PaaS平台的本质
谈谈软件工程的本质。
我认为,一家商业公司的软件工程能力主要体现在三个地方。
第一,提高服务的 SLA。
所谓服务的 SLA,也就是我们能提供多少个 9 的系统可用性,而每提高一个 9 的可用性都是对整个系统架构的重新洗礼。在我看来,提高系统的 SLA 主要表现在两个方面:
- 高可用的系统;
- 自动化的运维。
你可以看一下我在 CoolShell 上写的《关于高可用系统》这篇文章,它主要讲了构建高可用的系统需要使用的分布式系统设计思路。然而这还不够,我们还需要一个高度自动化的运维和管理系统,因为故障是常态,如果没有自动化的故障恢复,就很难提高服务的 SLA。
第二,能力和资源重用或复用。
软件工程还有一个重要的能力就是让能力和资源可以重用。其主要表现在如下两个方面:
- 软件模块的重用;
- 软件运行环境和资源的重用。
为此,需要我们有两个重要的能力:一个是“软件抽象的能力”,另一个是“软件标准化的能力”。你可以认为软件抽象就是找出通用的软件模块或服务,软件标准化就是使用统一的软件通讯协议、统一的开发和运维管理方法……这样能让整体软件开发运维的能力和资源得到最大程度的复用,从而增加效率。
第三,过程的自动化。
编程本来就是把一个重复工作自动化的过程,所以,软件工程的第三个本质就是把软件生产和运维的过程自动化起来。也就是下面这两个方面:
- 软件生产流水线;
- 软件运维自动化。
为此,我们除了需要 CI/CD 的 DevOps 式的自动化之外,也需要能够对正在运行的生产环境中的软件进行自动化运维。
通过了解软件工程的这三个本质,你会发现,我们上面所说的那些分布式的技术点是高度一致的,也就是下面这三个方面的能力。(是的,世界就是这样的。当参透了本质之后,你会发现世界是大同的。)
- 分布式多层的系统架构。
- 服务化的能力供应。
- 自动化的运维能力。
只有做到了这些,我们才能够真正拥有云计算的威力。这就是所谓的 Cloud Native。而这些目标都完美地体现在 PaaS 平台上。
前面讲述的分布式系统关键技术和软件工程的本质,都可以在 PaaS 平台上得到完全体现。所以,需要一个 PaaS 平台把那么多的东西给串联起来。这里,我结合自己的认知给你讲一下 PaaS 相关的东西,并把前面讲过的所有东西做一个总结。
PaaS 平台的本质
一个好的 PaaS 平台应该具有分布式、服务化、自动化部署、高可用、敏捷以及分层开放的特征,并可与 IaaS 实现良好的联动。
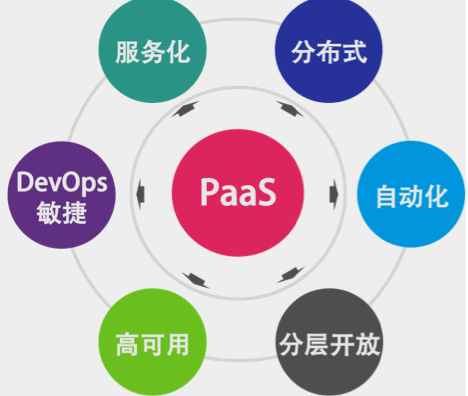
下面这三件事是 PaaS 跟传统中间件最大的差别。
- 服务化是 PaaS 的本质。软件模块重用,服务治理,对外提供能力是 PaaS 的本质。
- 分布式是 PaaS 的根本特性。多租户隔离、高可用、服务编排是 PaaS 的基本特性。
- 自动化是 PaaS 的灵魂。自动化部署安装运维,自动化伸缩调度是 PaaS 的关键。
PaaS 平台的总体架构
从下面的图中可以看到,我用了 Docker+Kubernetes 层来做了一个“技术缓冲层”。也就是说,如果没有 Docker 和 Kubernetes,构建 PaaS 将会复杂很多。当然,如果你正在开发一个类似 PaaS 的平台,那么你会发现自己开发出来的东西会跟 Docker 和 Kubernetes 非常像。相信我,最终你还是会放弃自己的轮子而采用 Docker+Kubernetes 的。
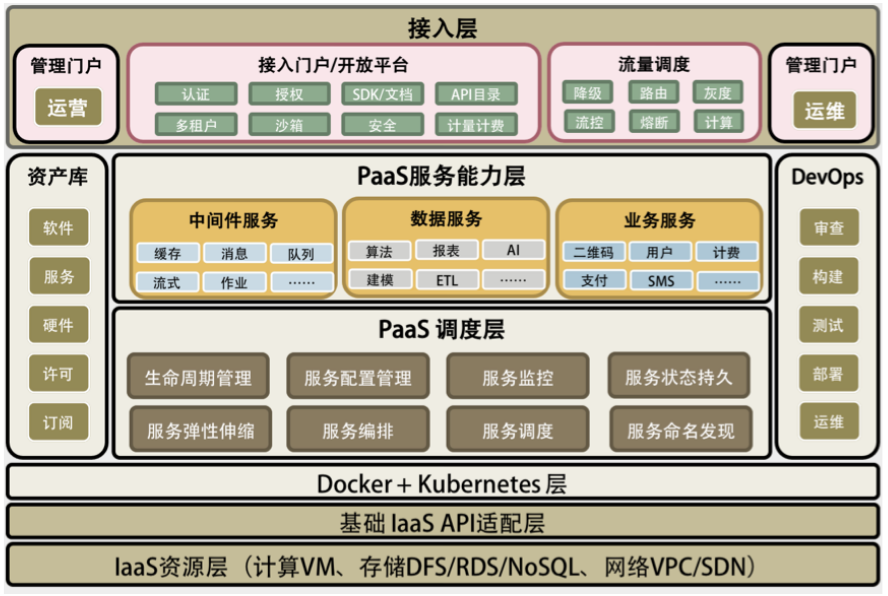
在 Docker+Kubernetes 层之上,我们看到了两个相关的 PaaS 层。一个是 PaaS 调度层,很多人将其称为 iPaaS;另一个是 PaaS 能力层,通常被称为 aPaaS。没有 PaaS 调度层,PaaS 能力层很难被管理和运维,而没有 PaaS 能力层,PaaS 就失去了提供实际能力的业务价值。而本文更多的是在讲 PaaS 调度层上的东西。
在两个相关的 PaaS 层之上,有一个流量调度的接入模块,这也是 PaaS 中非常关键的东西。流控、路由、降级、灰度、聚合、串联等等都在这里,包括最新的 AWS Lambda Service 的小函数等也可以放在这里。这个模块应该是像 CDN 那样来部署的。
然后,在这个图的两边分别是与运营和运维相关的。运营这边主要是管理一些软件资源方面的东西(类似 Docker Hub 和 CMDB),以及外部接入和开放平台上的东西,这主要是对外提供能力的相关组件;而运维这边主要是对内的相关东西,主要就是 DevOps。
总结一下,一个完整的 PaaS 平台会包括以下几部分。
- PaaS 调度层 – 主要是 PaaS 的自动化和分布式对于高可用高性能的管理。
- PaaS 能力服务层 – 主要是 PaaS 真正提供给用户的服务和能力。
- PaaS 的流量调度 – 主要是与流量调度相关的东西,包括对高并发的管理。
- PaaS 的运营管理 – 软件资源库、软件接入、认证和开放平台门户。
- PaaS 的运维管理 – 主要是 DevOps 相关的东西。
因为我画的是一个大而全的东西,所以看上去似乎很重很复杂。实际上,其中的很多组件是可以根据自己的需求被简化和裁剪的,而且很多开源软件能帮你简化好多工作。虽然构建 PaaS 平台看上去很麻烦,但是其实并不是很复杂,不要被我吓到了。哈哈。
PaaS 平台的生产和运维
下面的图我给出了一个大概的软件生产、运维和服务接入的流程,它把之前的东西都串起来了。
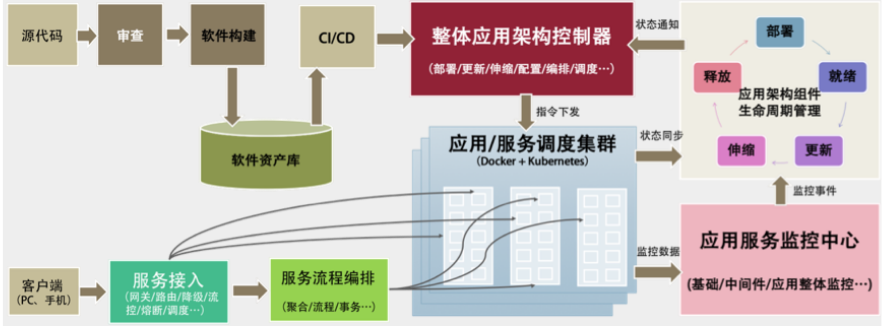
从左上开始软件构建,进入软件资产库(Docker Registry+ 一些软件的定义),然后走 DevOps 的流程,通过整体架构控制器进入生产环境,生产环境通过控制器操作 Docker+Kubernetes 集群进行软件部署和生产变更。
其中,同步服务的运行状态,并通过生命周期管理来拟合状态,如图右侧部分所示。服务运行时的数据会进入到相关应用监控,应用监控中的一些监控事件会同步到生命周期管理中,再由生命周期管理器来做出决定,通过控制器来调度服务运行。当应用监控中心发现流量变化,要进行强制性伸缩时,它通过生命周期管理来通知控制系统进行伸缩。
左下是服务接入的相关组件,主要是网关服务,以及 API 聚合编排和流程处理。这对应于之前说过的流量调度和 API Gateway 的相关功能。
总结
传统的单体架构系统容量显然是有上限的。同时,为了应对有计划和无计划的下线时间,系统的可用性也是有其极限的。分布式系统为以上两个问题提供了解决方案,并且还附带有其他优势。但是,要同时解决这两个问题决非易事。为了构建分布式系统,我们面临的主要问题如下。
- 分布式系统的硬件故障发生率更高,故障发生是常态,需要尽可能地将运维流程自动化。
- 需要良好地设计服务,避免某服务的单点故障对依赖它的其他服务造成大面积影响。
- 为了容量的可伸缩性,服务的拆分、自治和无状态变得更加重要,可能需要对老的软件逻辑做大的修改。
- 老的服务可能是异构的,此时需要让它们使用标准的协议,以便可以被调度、编排,且互相之间可以通信。
- 服务软件故障的处理也变得复杂,需要优化的流程,以加快故障的恢复。
- 为了管理各个服务的容量,让分布式系统发挥出最佳性能,需要有流量调度技术。
- 分布式存储会让事务处理变得复杂;在事务遇到故障无法被自动恢复的情况下,手动恢复流程也会变得复杂。
- 测试和查错的复杂度增大。
- 系统的吞吐量会变大,但响应时间会变长。
为了解决这些问题,我们深入了解了以下这些解决方案。
- 需要有完善的监控系统,以便对服务运行状态有全面的了解。
- 设计服务时要分析其依赖链;当非关键服务故障时,其他服务要自动降级功能,避免调用该服务。
- 重构老的软件,使其能被服务化;可以参考 SOA 和微服务的设计方式,目标是微服务化;使用 Docker 和 Kubernetes 来调度服务。
- 为老的服务编写接口逻辑来使用标准协议,或在必要时重构老的服务以使得它们有这些功能。
- 自动构建服务的依赖地图,并引入好的处理流程,让团队能以最快速度定位和恢复故障,详见《故障处理最佳实践:应对故障》一文。
- 使用一个 API Gateway,它具备服务流向控制、流量控制和管理的功能。
- 事务处理建议在存储层实现;根据业务需求,或者降级使用更简单、吞吐量更大的最终一致性方案,或者通过二阶段提交、Paxos、Raft、NWR 等方案之一,使用吞吐量小的强一致性方案。
- 通过更真实地模拟生产环境,乃至在生产环境中做灰度发布,从而增加测试强度;同时做充分的单元测试和集成测试以发现和消除缺陷;最后,在服务故障发生时,相关的多个团队同时上线自查服务状态,以最快地定位故障原因。
- 通过异步调用来减少对短响应时间的依赖;对关键服务提供专属硬件资源,并优化软件逻辑以缩短响应时间。
你已经看到,解决分布式服务的吞吐量和可用性问题不是件容易的事,以及目前的主流技术是怎么办到的。衍生出来的许多子问题,每一个都值得去细化、去研究其解决方案。这已经超出本文的篇幅所能及的了,但的确都是值得我们做技术的人去深入思考的。
分布式系统架构经典资料
基础理论
- CAP 定理
- Fallacies of Distributed Computing
经典资料
- Distributed systems theory for the distributed systems engineer
- FLP Impossibility Result
- An introduction to distributed systems
- Distributed Systems for fun and profit
- Distributed Systems: Principles and Paradigms
- Scalable Web Architecture and Distributed Systems
- Principles of Distributed Systems
- Making reliable distributed systems in the presence of software errors
- Designing Data Intensive Applications
基础理论
下面这些基础知识有可能你已经知道了,不过还是容我把它分享在这里。我希望用比较通俗易懂的文字将这些枯燥的理论知识讲请楚。
CAP 定理
CAP 定理是分布式系统设计中最基础,也是最为关键的理论。它指出,分布式数据存储不可能同时满足以下三个条件。
- 一致性(Consistency):每次读取要么获得最近写入的数据,要么获得一个错误。
- 可用性(Availability):每次请求都能获得一个(非错误)响应,但不保证返回的是最新写入的数据。
- 分区容忍(Partition tolerance):尽管任意数量的消息被节点间的网络丢失(或延迟),系统仍继续运行。
也就是说,CAP 定理表明,在存在网络分区的情况下,一致性和可用性必须二选一。而在没有发生网络故障时,即分布式系统正常运行时,一致性和可用性是可以同时被满足的。这里需要注意的是,CAP 定理中的一致性与 ACID 数据库事务中的一致性截然不同。
掌握 CAP 定理,尤其是能够正确理解 C、A、P 的含义,对于系统架构来说非常重要。因为对于分布式系统来说,网络故障在所难免,如何在出现网络故障的时候,维持系统按照正常的行为逻辑运行就显得尤为重要。你可以结合实际的业务场景和具体需求,来进行权衡。
例如,对于大多数互联网应用来说(如门户网站),因为机器数量庞大,部署节点分散,网络故障是常态,可用性是必须要保证的,所以只有舍弃一致性来保证服务的 AP。而对于银行等,需要确保一致性的场景,通常会权衡 CA 和 CP 模型,CA 模型网络故障时完全不可用,CP 模型具备部分可用性。

- CA (consistency + availability),这样的系统关注一致性和可用性,它需要非常严格的全体一致的协议,比如“两阶段提交”(2PC)。CA 系统不能容忍网络错误或节点错误,一旦出现这样的问题,整个系统就会拒绝写请求,因为它并不知道对面的那个结点是否挂掉了,还是只是网络问题。唯一安全的做法就是把自己变成只读的。
- CP (consistency + partition tolerance),这样的系统关注一致性和分区容忍性。它关注的是系统里大多数人的一致性协议,比如:Paxos 算法(Quorum 类的算法)。这样的系统只需要保证大多数结点数据一致,而少数的结点会在没有同步到最新版本的数据时变成不可用的状态。这样能够提供一部分的可用性。
- AP (availability + partition tolerance),这样的系统关心可用性和分区容忍性。因此,这样的系统不能达成一致性,需要给出数据冲突,给出数据冲突就需要维护数据版本。Dynamo 就是这样的系统。
然而,还是有一些人会错误地理解 CAP 定理,甚至误用。Cloudera 工程博客中,CAP Confusion: Problems with ‘partition tolerance’一文中对此有详细的阐述。
在谷歌的Transaction Across DataCenter 视频中,我们可以看到下面这样的图。这个是 CAP 理论在具体工程中的体现。
Fallacies of Distributed Computing
本文是英文维基百科上的一篇文章。它是 Sun 公司的劳伦斯·彼得·多伊奇(Laurence Peter Deutsch)等人于 1994~1997 年提出的,讲的是刚刚进入分布式计算领域的程序员常会有的一系列错误假设。
多伊奇于 1946 年出生在美国波士顿。他创办了阿拉丁企业(Aladdin Enterprises),并在该公司编写出了著名的 Ghostscript 开源软件,于 1988 年首次发布。
他在学生时代就和艾伦·凯(Alan Kay)等比他年长的人一起开发了 Smalltalk,并且他的开发成果激发了后来 Java 语言 JIT 编译技术的创造灵感。他后来在 Sun 公司工作并成为 Sun 的公司院士。在 1994 年,他成为了 ACM 院士。
基本上,每个人刚开始建立一个分布式系统时,都做了以下 8 条假定。随着时间的推移,每一条都会被证明是错误的,也都会导致严重的问题,以及痛苦的学习体验。
- 网络是稳定的。
- 网络传输的延迟是零。
- 网络的带宽是无穷大。
- 网络是安全的。
- 网络的拓扑不会改变。
- 只有一个系统管理员。
- 传输数据的成本为零。
- 整个网络是同构的。
阿尔农·罗特姆 - 盖尔 - 奥兹(Arnon Rotem-Gal-Oz)写了一篇长文Fallacies of Distributed Computing Explained来解释这些点。
由于他写这篇文章的时候已经是 2006 年了,所以从中能看到这 8 条常见错误被提出十多年后还有什么样的影响:一是,为什么当今的分布式软件系统也需要避免这些设计错误;二是,在当今的软硬件环境里,这些错误意味着什么。比如,文中在谈“延迟为零”假设时,还谈到了 AJAX,而这是 2005 年开始流行的技术。
而加勒思·威尔逊(Gareth Wilson)的文章则用日常生活中的例子,对这些点做了更为通俗的解释。
这 8 个需要避免的错误不仅对于中间件和底层系统开发者及架构师是重要的知识,而且对于网络应用程序开发者也同样重要。分布式系统的其他部分,如容错、备份、分片、微服务等也许可以对应用程序开发者部分透明,但这 8 点则是应用程序开发者也必须知道的。
为什么我们要深刻地认识这 8 个错误?是因为,这要我们清楚地认识到——在分布式系统中错误是不可能避免的,我们能做的不是避免错误,而是要把错误的处理当成功能写在代码中。
后面,我会写一个系列的文章来谈一谈,分布式系统容错设计中的一些常见设计模式。敬请关注!
经典资料
Distributed systems theory for the distributed systems engineer
本文作者认为,推荐大量的理论论文是学习分布式系统理论的错误方法,除非这是你的博士课程。因为论文通常难度大又很复杂,需要认真学习,而且需要理解这些研究成果产生的时代背景,才能真正的领悟到其中的精妙之处。
在本文中,作者给出了他整理的分布式工程师必须要掌握的知识列表,并直言掌握这些足够设计出新的分布式系统。首先,作者推荐了 4 份阅读材料,它们共同概括了构建分布式系统的难点,以及所有工程师必须克服的技术难题。
- Distributed Systems for Fun and Profit,这是一本小书,涵盖了分布式系统中的关键问题,包括时间的作用和不同的复制策略。后文中对这本书有较详细的介绍。
- Notes on distributed systems for young bloods,这篇文章中没有理论,是一份适合新手阅读的分布式系统实践笔记。
- A Note on Distributed Systems,这是一篇经典的论文,讲述了为什么在分布式系统中,远程交互不能像本地对象那样进行。
- The fallacies of distributed computing,每个分布式系统新手都会做的 8 个错误假设,并探讨了其会带来的影响。上文中专门对这篇文章做了介绍。
随后,分享了几个关键点。
- 失败和时间(Failure and Time)。分布式系统工程师面临的很多困难都可以归咎于两个根本原因:1. 进程可能会失败;2. 没有好方法表明进程失败。这就涉及到如何设置系统时钟,以及进程间的通讯机制,在没有任何共享时钟的情况下,如何确定一个事件发生在另一个事件之前。
可以参考 Lamport 时钟和 Vector 时钟,还可以看看Dynamo 论文。
- 容错的压力(The basic tension of fault tolerance)。能在不降级的情况下容错的系统一定要像没有错误发生的那样运行。这就意味着,系统的某些部分必须冗余地工作,从而在性能和资源消耗两方面带来成本。
最终一致性以及其他技术方案在以系统行为弱保证为代价,来试图避免这种系统压力。阅读Dynamo 论文和帕特·赫尔兰(Pat Helland)的经典论文Life Beyond Transactions能获很得大启发。
- 基本原语(Basic primitives)。在分布式系统中几乎没有一致认同的基本构建模块,但目前在越来越多地在出现。比如 Leader 选举,可以参考Bully 算法;分布式状态机复制,可以参考维基百科和Lampson 的论文,后者更权威,只是有些枯燥。
- 基本结论(Fundamental Results)。某些事实是需要吸收理解的,有几点:如果进程之间可能丢失某些消息,那么不可能在实现一致性存储的同时响应所有的请求,这就是 CAP 定理;一致性不可能同时满足以下条件:a. 总是正确,b. 在异步系统中只要有一台机器发生故障,系统总是能终止运行——停止失败(FLP 不可能性);一般而言,消息交互少于两轮都不可能达成共识(Consensus)。
- 真实系统(Real systems)。学习分布式系统架构最重要的是,结合一些真实系统的描述,反复思考和点评其背后的设计决策。如谷歌的 GFS、Spanner、Chubby、BigTable、Dapper 等,以及 Dryad、Cassandra 和 Ceph 等非谷歌系统。
FLP Impossibility Result
FLP 不可能性的名称起源于它的三位作者,Fischer、Lynch 和 Paterson。它是关于理论上能做出的功能最强的共识算法会受到怎样的限制的讨论。
所谓共识问题,就是让网络上的分布式处理者最后都对同一个结果值达成共识。该解决方案对错误有恢复能力,处理者一旦崩溃以后,就不再参与计算。在同步环境下,每个操作步骤的时间和网络通信的延迟都是有限的,要解决共识问题是可能的,方式是:等待一个完整的步长来检测某个处理者是否已失败。如果没有收到回复,那就假定它已经崩溃。
共识问题有几个变种,它们在“强度”方面有所不同——通常,一个更“强”问题的解决方案同时也能解决比该问题更“弱”的问题。共识问题的一个较强的形式如下。
给出一个处理者的集合,其中每一个处理者都有一个初始值:
- 所有无错误的进程(处理过程)最终都将决定一个值;
- 所有会做决定的无错误进程决定的都将是同一个值;
- 最终被决定的值必须被至少一个进程提出过。
这三个特性分别被称为“终止”、“一致同意”和“有效性”。任何一个具备这三点特性的算法都被认为是解决了共识问题。
FLP 不可能性则讨论了异步模型下的情况,主要结论有两条。
- 在异步模型下不存在一个完全正确的共识算法。不仅上述较“强”形式的共识算法不可能实现,FLP 还证明了比它弱一些的、只需要有一些无错误的进程做决定就足够的共识算法也是不可能实现的。
- 在异步模型下存在一个部分正确的共识算法,前提是所有无错误的进程都总能做出一个决定,此外没有进程会在它的执行过程中死亡,并且初始情况下超过半数进程都是存活状态。
FLP 的结论是,在异步模型中,仅一个处理者可能崩溃的情况下,就已经没有分布式算法能解决共识问题。这是该问题的理论上界。其背后的原因在于,异步模型下对于一个处理者完成工作然后再回复消息所需的时间并没有上界。因此,无法判断出一个处理者到底是崩溃了,还是在用较长的时间来回复,或者是网络有很大的延迟。
FLP 不可能性对我们还有别的启发。一是网络延迟很重要,网络不能长时间处于拥塞状态,否则共识算法将可能因为网络延迟过长而导致超时失败。二是计算时间也很重要。对于需要计算共识的处理过程(进程),如分布式数据库提交,需要在短时间里就计算出能否提交的结果,那就要保证计算结点资源充分,特别是内存容量、磁盘空闲时间和 CPU 时间方面要足够,并在软件层面确保计算不超时。
另一个问题是,像 Paxos 这样的共识算法为什么可行?实际上它并不属于 FLP 不可能性证明中所说的“完全正确”的算法。它的正确性会受超时值的影响。但这并不妨碍它在实践中有效,因为我们可以通过避免网络拥塞等手段来保证超时值是合适的。
An introduction to distributed systems
它是分布式系统基础课的课程提纲,也是一份很棒的分布式系统介绍,几乎涵盖了所有知识点,并辅以简洁并切中要害的说明文字,非常适合初学者提纲挈领地了解知识全貌,快速与现有知识结合,形成知识体系。此外,还可以把它作为分布式系统的知识图谱,根据其中列出的知识点一一搜索,你能学会所有的东西。
Distributed Systems for fun and profit
这是一本免费的电子书。作者撰写此书的目的是希望以一种更易于理解的方式,讲述以亚马逊的 Dynamo、谷歌的 BigTable 和 MapReduce 等为代表的分布式系统背后的核心思想。
因而,书中着力撰写分布式系统中的关键概念,以便让读者能够快速了解最为核心的知识,并且进行了足够详实的讲述,方便读者体会和理解,又不至于陷入细节。
全书分为五章,讲述了扩展性、可用性、性能和容错等基础知识,FLP 不可能性和 CAP 定理,探讨了大量的一致性模型;讨论了时间和顺序,及时钟的各种用法。随后,探讨了复制问题,如何防止差异,以及如何接受差异。此外,每章末尾都给出了针对本章内容的扩展阅读资源列表,这些资料是对本书内容的很好补充。
[Distributed Systems: Principles and Paradigms](http://barbie.uta.edu/~jli/Resources/MapReduce&Hadoop/Distributed Systems Principles and Paradigms.pdf)
本书是由计算机科学家安德鲁·斯图尔特·塔能鲍姆(Andrew S. Tanenbaum)和其同事马丁·范·斯蒂恩(Martin van Steen)合力撰写的,是分布式系统方面的经典教材。
语言简洁,内容通俗易懂,介绍了分布式系统的七大核心原理,并给出了大量的例子;系统讲述了分布式系统的概念和技术,包括通信、进程、命名、同步化、一致性和复制、容错以及安全等;讨论了分布式应用的开发方法(即范型)。
但本书不是一本指导“如何做”的手册,仅适合系统性地学习基础知识,了解编写分布式系统的基本原则和逻辑。中文翻译版为《分布式系统原理与范型》(第二版)。
Scalable Web Architecture and Distributed Systems
这是一本免费的在线小册子,其中文翻译版为可扩展的 Web 架构和分布式系统。
本书主要针对面向的互联网(公网)的分布式系统,但其中的原理或许也可以应用于其他分布式系统的设计中。作者的观点是,通过了解大型网站的分布式架构原理,小型网站的构建也能从中受益。本书从大型互联网系统的常见特性,如高可用、高性能、高可靠、易管理等出发,引出了一个类似于 Flickr 的典型的大型图片网站的例子。
首先,从程序模块化易组合的角度出发,引出了面向服务架构(SOA)的概念。同时,引申出写入和读取两者的性能问题,及对此二者如何调度的考量——在当今的软硬件架构上,写入几乎总是比读取更慢,包括软件层面引起的写入慢(如数据库的一致性要求和 B 树的修改)和硬件层面引起的写入慢(如 SSD)。
网络提供商提供的下载带宽也通常比上传带宽更大。读取往往可以异步操作,还可以做 gzip 压缩。写入则往往需要保持连接直到数据上传完成。因此,往往我们会想把服务做成读写分离的形式。然后通过一个 Flickr 的例子,介绍了他们的服务器分片式集群做法。
接下来讲了冗余。数据的冗余异地备份(如 master-slave)、服务的多版本冗余、避免单点故障等。
随后,在冗余的基础上,讲了多分区扩容,亦即横向扩容。横向扩容是在单机容量无法满足需求的情况下不得不做的设计。但横向扩容会带来一个问题,即数据的局域性会变差。本来数据可以存在于同一台服务器上,但现在数据不得不存在于不同服务器上,潜在地降低了系统的性能(主要是可能延长响应时间)。另一个问题是多份数据的不一致性。
之后,本书开始深入讲解数据访问层面的设计。首先抛出一个大型数据(TB 级以上)的存储问题。如果内存都无法缓存该数据量,性能将大幅下降,那么就需要缓存数据。数据可以缓存在每个节点上。
但如果为所有节点使用负载均衡,那么分配到每个节点的请求将十分随机,大大降低缓存命中率,从而导致低效的缓存。接下来考虑全局缓存的设计。再接下来考虑分布式缓存的设计。进一步,介绍了 Memcached,以及 Facebook 的缓存设计方案。
代理服务器则可以用于把多个重复请求合并成一个,对于公网上的公共服务来说,这样做可以大大减少对数据层访问的次数。Squid 和 Varnish 是两个可用于生产的代理服务软件。
当知道所需要读取的数据的元信息时,比如知道一张图片的 URL,或者知道一个要全文搜索的单词时,索引就可以帮助找到那几台存有该信息的服务器,并从它们那里获取数据。文中扩展性地讨论了本话题。
接下来谈负载均衡器,以及一些典型的负载均衡拓扑。然后讨论了对于用户会话数据如何处理。比如,对于电子商务网站,用户的购物车在没有下单之前都必须保持有效。
一种办法是让用户会话与服务器产生关联,但这样做会较难实现自动故障转移,如何做好是个问题。另外,何时该使用负载均衡是个问题。有时节点数量少的情况下,只要使用轮换式 DNS 即可。负载均衡也会让在线性能问题的检测变得更麻烦。
对于写入的负载,可以用队列的方式来减少对服务器的压力,保证服务器的效率。消息队列的开源实现有很多,如 RabbitMQ、ActiveMQ、BeanstalkD,但有些队列方案也使用了如 Zookeeper,甚至是像 Redis 这样的存储服务。
本书主要讲述了高性能互联网分布式服务的架构方案,并介绍了许多实用的工具。作者指出这是一个令人兴奋的设计领域,虽然只讲了一些皮毛,但这一领域不仅现在有很多创新,将来也会越来越多。
Principles of Distributed Systems
本书是苏黎世联邦理工学院的教材。它讲述了多种分布式系统中会用到的算法。虽然分布式系统的不同场景会用到不同算法,但并不表示这些算法都会被用到。不过,对于学生来说,掌握了算法设计的精髓也就能举一反三地设计出解决其他问题的算法,从而得到分布式系统架构设计中所需的算法。
本书覆盖的算法有:
- 顶点涂色算法(可用于解决互相冲突的任务分配问题)
- 分布式的树算法(广播算法、会聚算法、广度优先搜索树算法、最小生成树算法)
- 容错以及 Paxos(Paxos 是最经典的共识算法之一)
- 拜占庭协议(节点可能没有完全宕机,而是输出错误的信息)
- 全互联网络(服务器两两互联的情况下算法的复杂度)
- 多核计算的工程实践(事务性存储、资源争用管理)
- 主导集(又一个用随机化算法打破对称性的例子;这些算法可以用于路由器建立路由)
- ……
这些算法对你迈向更高级更广阔的技术领域真的相当有帮助的。
Making reliable distributed systems in the presence of software errors
这本书的书名直译过来是在有软件错误的情况下,构建可靠的分布式系统,Erlang 之父乔·阿姆斯特朗(Joe Armstrong)的力作。书中撰写的内容是从 1981 年开始的一个研究项目的成果,这个项目是寻找更好的电信应用编程方式。
当时的电信应用都是大型程序,虽然经过了仔细的测试,但投入使用时程序中仍会存在大量的错误。作者及其同事假设这些程序中确实有错误,然后想法设法在这些错误存在的情况下构建可靠的系统。他们测试了所有的编程语言,没有一门语言拥有电信行业所需要的所有特性,所以促使一门全新的编程语言 Erlang 的开发,以及随之出现的构建健壮系统(OTP)的设计方法论和库集。
书中抽象了电信应用的所有需求,定义了问题域,讲述了系统构建思路——模拟现实,简单通用,并给出了指导规范。阿姆斯特朗认为,在存在软件错误的情况下,构建可靠系统的核心问题可以通过编程语言或者编程语言的标准库来解决。所以本书有很大的篇幅来介绍 Erlang,以及如何运用其构建具有容错能力的电信应用。
虽然书中的内容是以构建 20 世纪 80 年代的电信系统为背景,但是这种大规模分布式的系统开发思路,以及对系统容错能力的核心需求,与互联网时代的分布式系统架构思路出奇一致。书中对问题的抽象、总结,以及解决问题的思路和方案,有深刻的洞察和清晰的阐释,所以此书对现在的项目开发和架构有极强的指导和借鉴意义。
Designing Data Intensive Applications
这是一本非常好的书。我们知道,在分布式的世界里,数据结点的扩展是一件非常麻烦的事。而这本书则深入浅出地用很多工程案例讲解了如何让数据结点做扩展。
作者马丁·科勒普曼(Martin Kleppmann)在分布式数据系统领域有着很深的功底,并在这本书中完整地梳理各类纷繁复杂设计背后的技术逻辑,不同架构之间的妥协与超越,很值得开发人员与架构设计者阅读。
这本书深入到 B-Tree、SSTables、LSM 这类数据存储结构中,并且从外部的视角来审视这些数据结构对 NoSQL 和关系型数据库所产生的影响。它可以让你很清楚地了解到真正世界的大数据架构中的数据分区、数据复制的一些坑,并提供了很好的解决方案。
最赞的是,作者将各种各样的技术的本质非常好地关联在一起,帮你触类旁通。而且抽丝剥茧,循循善诱,从“提出问题”,到“解决问题”,到“解决方案”,再到“优化方案”和“对比不同的方案”,一点一点地把非常晦涩的技术和知识展开。
本书的引用相当多,每章后面都有几百个 Reference。通过这些 Reference,你可以看到更为广阔更为精彩的世界。
这本书是 2017 年 3 月份出版的,目前还没有中译版,不过英文也不难读。非常推荐。这里有这本书的 PPT,你可从这个 PPT 中管中窥豹一下。
小结
在今天的文章中,我给出了一些分布式系统的基础理论知识和几本很不错的图书和资料,需要慢慢消化吸收。也许你看到这么庞大的书单和资料列表有点望而却步,但是我真的希望你能够花点时间来看看这些资料。相信你看完这些资料后,一定能上一个新的台阶。再加上一些在工程项目中的实践,我保证你,一定能达到大多数人难以企及的技术境界。
自从 2002 年开始接触分布式计算系统至今,我学习分布式系统已经有 15 年了,发现还有很多东西还要继续学习。是的,学无止境啊。如果你想成为一名很不错的架构师,你一定要好好学习这些知识。
分布式数据调度相关论文
我们在之前的系列文章《分布式系统架构的本质》中说过,分布式系统的一个关键技术是“数据调度”。因为我们需要扩充节点,提高系统的高可用性,所以必需冗余数据结点。
建立数据结点的副本看上去容易,但其中最大的难点就是分布式一致性的问题。下面,我会带你看看数据调度世界中的一些技术点以及相关的技术论文。
对于分布式的一致性问题,相信你在前面看过好几次下面这张图。从中,我们可以看出,Paxos 算法的重要程度。还有人说,分布式下真正的一致性算法只有 Paxos。
Paxos 算法
Paxos 算法,是莱斯利·兰伯特(Lesile Lamport)于 1990 年提出来的一种基于消息传递且具有高度容错特性的一致性算法。但是这个算法太过于晦涩,所以,一直以来都属于理论上的论文性质的东西。
其进入工程圈的源头在于 Google 的 Chubby lock——一个分布式的锁服务,用在了 Bigtable 中。直到 Google 发布了下面的这两篇论文,Paxos 才进入到工程界的视野中来。
- Bigtable: A Distributed Storage System for Structured Data
- The Chubby lock service for loosely-coupled distributed systems
Google 与 Big Table 相齐名的还有另外两篇论文。
- The Google File System
- MapReduce: Simplifed Data Processing on Large Clusters
不过,这几篇论文中并没有讲太多的 Paxos 算法细节上的内容,反而在论文Paxos Made Live – An Engineering Perspective 中提到了很多工程实现的细节。比如,Google 实现 Paxos 时遇到的各种问题和解决方案,讲述了从理论到实际应用二者之间巨大的鸿沟。
尤其在满地都是坑的分布式系统领域,这篇论文没有过多讨论 Paxos 算法本身,而是在讨论如何将理论应用到实践,如何弥补理论在实践中的不足,如何取舍,如何测试,这些在实践中的各种问题才是工程的魅力。所以建议你读一读。
Paxos 算法的原版论文我在这里就不贴了,因为一来比较晦涩,二来也不易懂。推荐一篇比较容易读的——Neat Algorithms - Paxos ,这篇文章中还有一些小动画帮助你读懂。还有一篇可以帮你理解的文章是Paxos by Examples。
如果你要自己实现 Paxos 算法,这里有几篇文章供你参考。
- Paxos Made Code ,作者是马克罗·普里米 (Macro Primi),他实现了一个 Paxos 开源库libpaxos。
- Paxos for System Builders ,从一个系统实现者的角度讨论了实现 Paxos 的诸多具体问题,比如 Leader 选举、数据及消息类型、流控等。
- Paxos Made Moderately Complex,这篇文章比较新,是 2011 年才发表的。文中介绍了很多实现细节,并提供了很多伪代码,一方面可以帮助理解 Paxos,另一方面也可以据此实现一个 Paxos。
- Paxos Made Practical主要介绍如何采用 Paxos 实现 replication。
除了马克罗·普里米的那个开源实现外,到 GitHub 上找一下,你就会看到这些项目:Plain Paxos Implementations Python & Java、A go implementation of the Paxos algorithm 。
ZooKeeper 有和 Paxos 非常相似的一些特征,比如领导选举、提案号等,但是它本质上不是 Paxos 协议,而是自己发明的 Zab 协议,有兴趣的话,可以读一下这篇论文:
Zab: High-Performance broadcast for primary-backup systems。
上述的 Google File System、MapReduce、Bigtable 并称为“谷三篇”。基本上来说,整个世界工程系统因为这三篇文章,开始向分布式系统演化,而云计算中的很多关键技术也是因为这三篇文章才得以成熟。 后来,雅虎公司也基于这三篇论文开发了一个开源的软件——Hadoop。
Raft 算法
因为 Paxos 算法太过于晦涩,而且在实际的实现上有太多的坑,并不太容易写对。所以,有人搞出了另外一个一致性的算法,叫 Raft。其原始论文是 In search of an Understandable Consensus Algorithm (Extended Version) 寻找一种易于理解的 Raft 算法。这篇论文的译文在 InfoQ 上《Raft 一致性算法论文译文》,推荐你读一读。
Raft 算法和 Paxos 的性能和功能是一样的,但是它和 Paxos 算法的结构不一样,这使 Raft 算法更容易理解并且更容易实现。那么 Raft 是怎样做到的呢?
Raft 把这个一致性的算法分解成了几个部分,一个是领导选举(Leader Selection),一个是日志复制(Log Replication),一个是安全性(Safety),还有一个是成员变化(Membership Changes)。对于一般人来说,Raft 协议比 Paxos 的学习曲线更低,也更平滑。
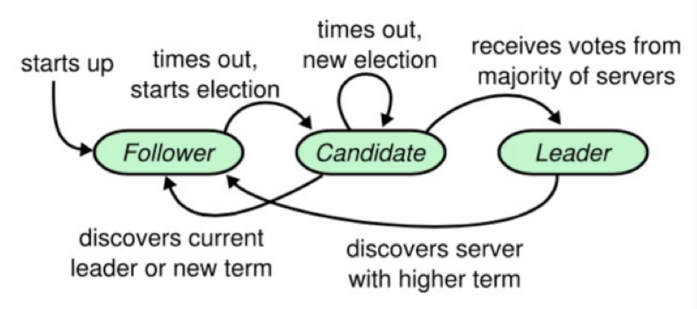
Raft 协议中有一个状态机,每个结点会有三个状态,分别是 Leader、Candidate 和 Follower。Follower 只响应其他服务器的请求,如果没有收到任何信息,它就会成为一个 Candidate,并开始进行选举。收到大多数人同意选票的人会成为新的 Leader。
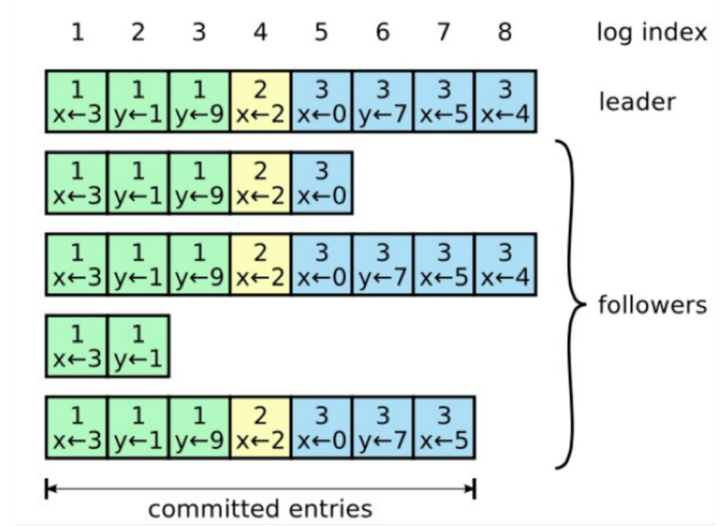
一旦选举出了一个 Leader,它就开始负责服务客户端的请求。每个客户端的请求都包含一个要被复制状态机执行的指令。Leader 首先要把这个指令追加到 log 中形成一个新的 entry,然后通过 AppendEntries RPC 并行地把该 entry 发给其他服务器(server)。如果其他服务器没发现问题,复制成功后会给 Leader 一个表示成功的 ACK。
Leader 收到大多数 ACK 后应用该日志,返回客户端执行结果。如果 Follower 崩溃 (crash)或者丢包,Leader 会不断重试 AppendEntries RPC。
这里推荐几个不错的 Raft 算法的动画演示。
- Raft – The Secret Lives of Data
- Raft Consensus Algorithm
- Raft Distributed Consensus Algorithm Visualization
逻辑钟和向量钟
后面,业内又搞出来一些工程上的东西,比如 Amazon 的 DynamoDB,其论文Dynamo: Amazon’s Highly Available Key Value Store 的影响力也很大。这篇论文中讲述了 Amazon 的 DynamoDB 是如何满足系统的高可用、高扩展和高可靠要求的,其中还展示了系统架构是如何做到数据分布以及数据一致性的。
GFS 采用的是查表式的数据分布,而 DynamoDB 采用的是计算式的,也是一个改进版的通过虚拟结点减少增加结点带来数据迁移的一致性哈希。另外,这篇论文中还讲述了一个 NRW 模式用于让用户可以灵活地在 CAP 系统中选取其中两项,这使用到了 Vector Clock——向量时钟来检测相应的数据冲突。最后还介绍了使用 Handoff 的机制对可用性的提升。
这篇文章中有几个关键的概念,一个是 Vector Clock,另一个是 Gossip 协议。
提到向量时钟就需要提一下逻辑时钟。所谓逻辑时间,也就是在分布系统中为了解决消息有序的问题,由于在不同的机器上有不同的本地时间,这些本地时间的同步很难搞,会导致消息乱序。
于是 Paxos 算法的发明人兰伯特(Lamport)搞了个向量时钟,每个系统维护一个本地的计数器,这就是所谓的逻辑时钟。每执行一个事件(例如向网络发送消息,或是交付到应用层)都对这个计数器做加 1 操作。当跨系统的时候,在消息体上附着本地计算器,当接收端收到消息时,更新自己的计数器(取对端传来的计数器和自己当成计数器的最大值),也就是调整自己的时钟。
逻辑时钟可以保证,如果事件 A 先于事件 B,那么事件 A 的时钟一定小于事件 B 的时钟,但是返过来则无法保证,因为返过来没有因果关系。所以,向量时钟解释了因果关系。向量时钟维护了数据更新的一组版本号(版本号其实就是使用逻辑时钟)。
假如一个数据需要存在三个结点上 A、B、C。那么向量维度就是 3,在初始化的时候,所有结点对于这个数据的向量版本是 [A:0, B:0, C:0]。当有数据更新时,比如从 A 结点更新,那么,数据的向量版本变成 [A:1, B:0, C:0],然后向其他结点复制这个版本,其在语义上表示为我当前的数据是由 A 结果更新的,而在逻辑上则可以让分布式系统中的数据更新的顺序找到相关的因果关系。
这其中的逻辑关系,你可以看一下 马萨诸塞大学课程 Distributed Operating System 中第 10 节 Clock Synchronization 这篇讲议。关于 Vector Clock,你可以看一下 Why Vector Clocks are Easy和Why Vector Clocks are Hard 这两篇文章。
Gossip 协议
另外,DynamoDB 中使用到了 Gossip 协议来做数据同步,这个协议的原始论文是 Efficient Reconciliation and Flow Control for Anti-Entropy Protocols。Gossip 算法也是 Cassandra 使用的数据复制协议。这个协议就像八卦和谣言传播一样,可以 “一传十、十传百”传播开来。但是这个协议看似简单,细节上却非常麻烦。
根据这篇论文,节点之间存在三种通信方式。
- push 方式。A 节点将数据 (key,value,version) 及对应的版本号推送给 B 节点,B 节点更新 A 中比自己新的数据。
- pull 方式。A 仅将数据 key,version 推送给 B,B 将本地比 A 新的数据 (key,value,version) 推送给 A,A 更新本地。
- push/pull 方式。与 pull 类似,只是多了一步,A 再将本地比 B 新的数据推送给 B,B 更新本地。
如果把两个节点数据同步一次定义为一个周期,那么在一个周期内,push 需通信 1 次,pull 需 2 次,push/pull 则需 3 次。从效果上来讲,push/pull 最好,理论上一个周期内可以使两个节点完全一致。直观感觉上,也是 push/pull 的收敛速度最快。
另外,每个节点上的又需要一个协调机制,也就是如何交换数据能达到最快的一致性——消除节点的不一致性。上面所讲的 push、pull 等是通信方式,协调是在通信方式下的数据交换机制。
协调所面临的最大问题是,一方面需要找到一个经济的方式,因为不可能每次都把一个节点上的数据发送给另一个节点;另一方面,还需要考虑到相关的容错方式,也就是当因为网络问题不可达的时候,怎么办?
一般来说,有两种机制:一种是以固定概率传播的 Anti-Entropy 机制,另一种是仅传播新到达数据的 Rumor-Mongering 机制。前者有完备的容错性,但是需要更多的网络和 CPU 资源,后者则反过来,不耗资源,但在容错性上难以保证。
Anti-Entropy 的机制又分为 Precise Reconciliation(精确协调)和 Scuttlebutt Reconciliation(整体协调)这两种。前者希望在每次通信周期内都非常精确地消除双方的不一致性,具体表现就是互发对方需要更新的数据。因为每个结点都可以读写,所以这需要每个数据都要独立维护自己的版本号。
而整体协调与精确协调不同的是,整体协调不是为每个数据都维护单独的版本号,而是每个节点上的数据统一维护一个版本号,也就是一个一致的全局版本。这样与其他结果交换数据的时候,就只需要比较节点版本,而不是数据个体的版本,这样会比较经济一些。如果版本不一样,则需要做精确协调。
因为篇幅问题,这里就不多说了,你可以看看原始的论文,还可以去看看 Cassandra 中的源码,以及到 GitHub 搜一下其他人的实现。多说一句,Cassandra 的实现是基于整体协调的 push/pull 模式。
关于 Gossip 的一些图示化的东西,你可以看一下动画gossip visualization。
分布式数据库方面
上面讲的都是一些基本概念相关的东西,下面我们来谈谈数据库方面的一些论文。
一篇是 AWS Aurora 的论文 Amazon Aurora: Design Considerations for High Throughput Cloud –Native Relation Databases。
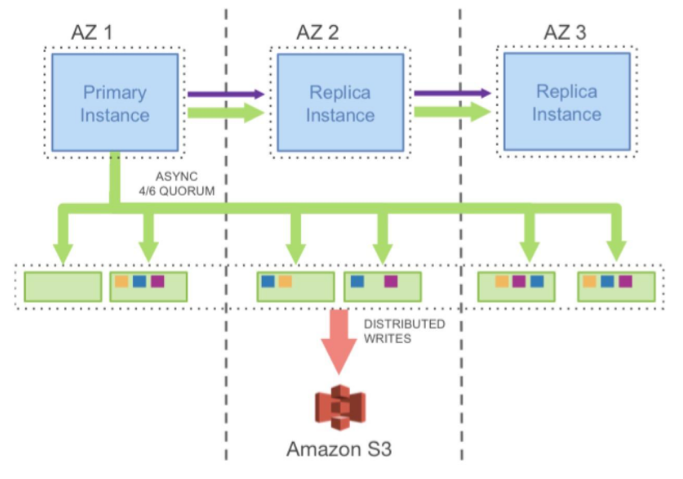
Aurora 是 AWS 将 MySQL 的计算和存储分离后,计算节点 scale up,存储节点 scale out。并把其 redo log 独立设计成一个存储服务,把分布式的数据方面的东西全部甩给了底层存储系统。从而提高了整体的吞吐量和水平的扩展能力。
Aurora 要写 6 份拷贝,但是其只需要把一个 Quorum 中的日志写成功就可以了。如下所示。可以看到,将存储服务做成一个跨数据中心的服务,提高数据库容灾,降低性能影响。
对于存储服务的设计,核心的原理就是 latency 一定要低,毕竟写 6 个 copy 是一件开销很大的事。所以,基本上来说,Aurora 用的是异步模型,然后拼命地做并行处理,其中用到的也是 Gossip 协议。如下所示。
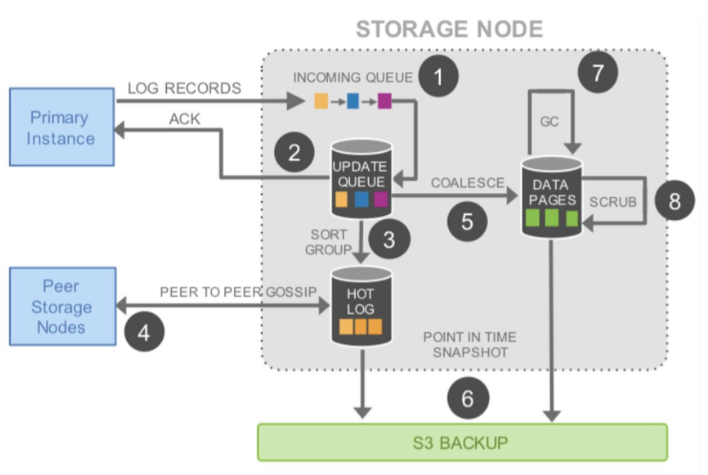
在上面这个图中,我们可以看到,完成前两步,就可以 ACK 回调用方。也就是说,只要数据在本地落地了,就可以返回成功了。然后,对于六个副本,这个 log 会同时发送到 6 个存储结点,只需要有大于 4 个成功 ACK,就算写成功了。第 4 步我们可以看到用的是 Gossip 协议。然后,第 5 步产生 cache 页,便于查询。第 6 步在 S3 做 Snapshot,类似于 Checkpoint。
第二篇比较有代表的论文是 Google 的 Spanner: Google’s Globally-Distributed Database。
Spanner 是 Google 的全球分布式数据库 Globally-Distributed Database) 。Spanner 的扩展性达到了令人咋舌的全球级,可以扩展到数百万台机器,数以百计的数据中心,上万亿的行。更给力的是,除了夸张的扩展性之外,它还能同时通过同步复制和多版本来满足外部一致性,可用性也是很好的。
下面是 Spanserver 的一个架构。
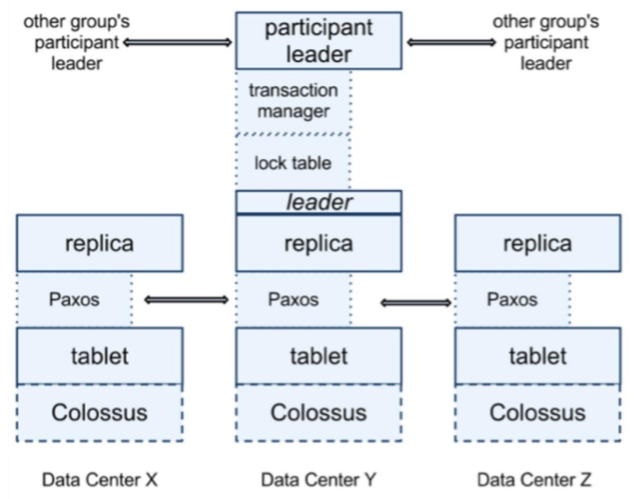
我们可以看到,每个数据中心都会有一套 Colossus,这是第二代的 GFS。每个机器有 100-1000 个 tablet,也就是相当数据库表中的行集,物理存储就是数据文件。比如,一张表有 2000 行,然后有 20 个 tablet,那么每个 tablet 分别有 100 行数据。
在 tablet 上层通过 Paxos 协议进行分布式跨数据中心的一致性数据同步。Paxos 会选出一个 replica 做 Leader,这个 Leader 的寿命默认是 10s,10s 后重选。Leader 就相当于复制数据的 master,其他 replica 的数据都是从它那里复制的。读请求可以走任意的 replica,但是写请求只有去 Leader。这些 replica 统称为一个 Paxos Group。
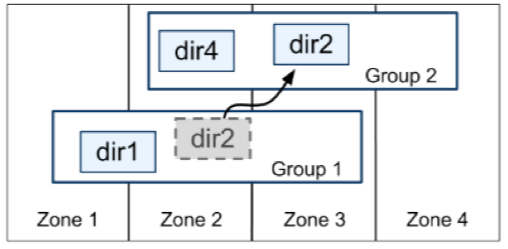
Group 之间也有数据交互传输,Google 定义了最小传输复制单元 directory,是一些有共同前缀的 key 记录,这些 key 也有相同的 replica 配置属性。
目前,基于 Spanner 论文的开源实现有两个,一个是 Google 公司自己的人出来做的CockroachDB,另一个是国人做的TiDB。
小结
正如我在之前的分布式系统的本质文章里所说到的,分布式的服务的调度需要一个分布式的存储系统来支持服务的数据调度。而我们可以看到,各大公司都在分布式的数据库上做各种各样的创新,他们都在使用底层的分布式文件系统来做存储引擎,把存储和计算分离开来,然后使用分布式一致性的数据同步协议的算法来在上层提供高可用、高扩展的支持。
从这点来看,可以预见到,过去的分库分表并通过一个数据访问的代理服务的玩法,应该在不久就会过时就会成为历史。真正的现代化的分布式数据存储就是 Aurora 和 Spanner 这样的方式。
通过上面的这些论文和相关的工程实践以及开源项目,相信可以让你在细节方面对分布式中最难的一块——数据调度方面有更多的认识。