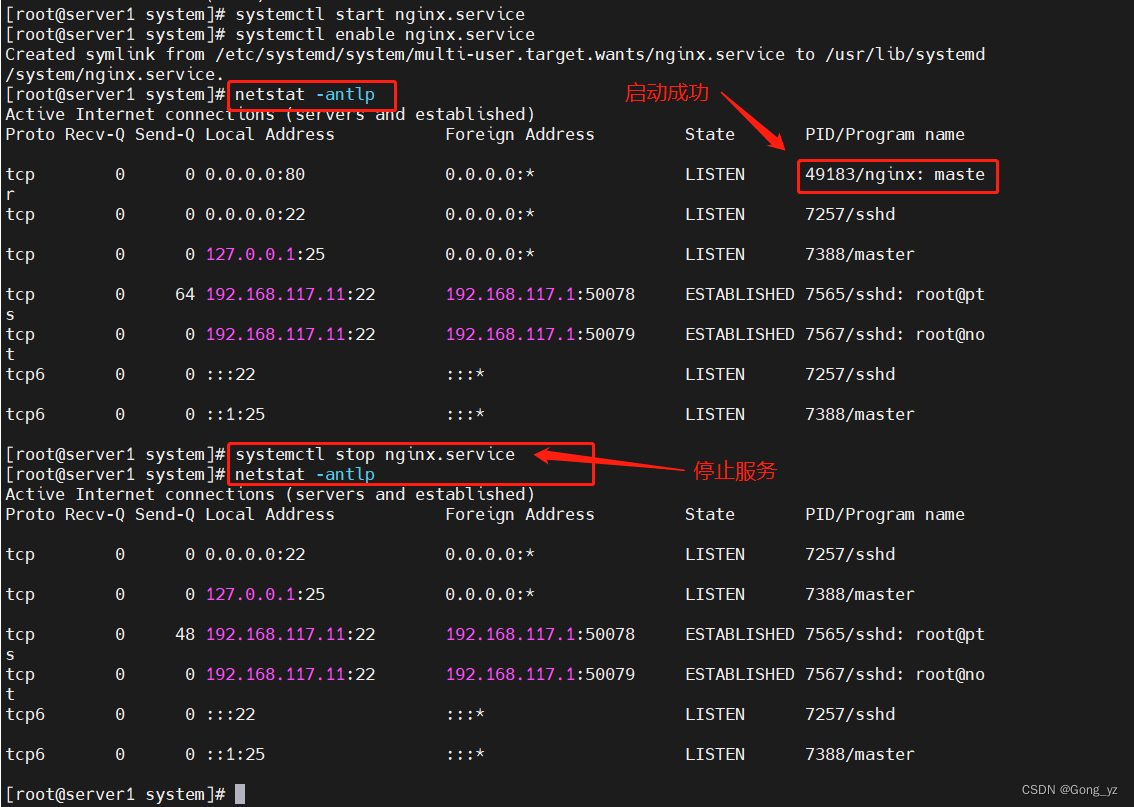
[NOIP2008 提高组] 笨小猴
题目描述
笨小猴的词汇量很小,所以每次做英语选择题的时候都很头疼。但是他找到了一种方法,经试验证明,用这种方法去选择选项的时候选对的几率非常大!
这种方法的具体描述如下:假设 maxn\text{maxn}maxn 是单词中出现次数最多的字母的出现次数,minn\text{minn}minn 是单词中出现次数最少的字母的出现次数,如果 maxn−minn\text{maxn}-\text{minn}maxn−minn 是一个质数,那么笨小猴就认为这是个 Lucky Word,这样的单词很可能就是正确的答案。
输入格式
一个单词,其中只可能出现小写字母,并且长度小于 100100100。
输出格式
共两行,第一行是一个字符串,假设输入的的单词是 Lucky Word,那么输出 Lucky Word,否则输出 No Answer;
第二行是一个整数,如果输入单词是 Lucky Word,输出 maxn−minn\text{maxn}-\text{minn}maxn−minn 的值,否则输出 000。
样例 #1
样例输入 #1
error
样例输出 #1
Lucky Word
2
样例 #2
样例输入 #2
olympic
样例输出 #2
No Answer
0
提示
【输入输出样例 1 解释】
单词 error 中出现最多的字母 r\texttt rr 出现了 333 次,出现次数最少的字母出现了 111 次,3−1=23-1=23−1=2,222 是质数。
【输入输出样例 2 解释】
单词 olympic 中出现最多的字母 i\texttt ii 出现了 111 次,出现次数最少的字母出现了 111 次,1−1=01-1=01−1=0,000 不是质数。
(本处原题面错误已经修正)
noip2008 提高第一题
所需变量
int a[30];//为了装所有字母的数组a,初始值均为0int max;//代表字幕出现最多的次数
int min;//代表字母出现最小的次数,初始值为100
int i;//循环变量
char temp;//用于接收字符串中的每个字母
我们首先要编写一个判断质数的小函数,只要从2开始,看是否能被这个数整除,如果能那么代表这个数不是质数,如果没有因子(即只有1和它本身),那么就代表是质数,返回1代表质数,返回0代表不是质数
int solution(int a){for(int i = 2;i<=a/2;i++){if(a%i == 0){return 0;}}return 1;
}
然后我们再一个字母一个字母接收的过程中,每当是a那么我就就让a[0]++,如果是b那么就让a[1]++;直到读取完毕,那么我们就获得所有字母的个数了,部分代码如下:
while(true){scanf("%c",&temp);if(temp == '\n'){break;}a[temp-96]++;}
然后就是对每个字母判断,首先如果是0,那么就表示这个字母根本没出现过,那么我们不能进行判断,因为如果把未出现的字母加入进去,那么最小值一定是0,就违背题目意思,然后就是判断谁是最大值,谁是最小值,得到之后然后让其相减,最后在判断是否是质数,如果是质数就输出Lucky Word,如果不是就输出 No Answer。
最后将上面的代码拼接起来就得到下面的代码:
该算法本人认为比较优,如果有更好的想法,欢迎q我!
#include<iostream>
using namespace std;
int solution(int a){for(int i = 2;i<=a/2;i++){if(a%i == 0){return 0;}}return 1;
}
int main(){int a[30] = {0},max = 0,min = 100,i;char temp;while(true){scanf("%c",&temp);if(temp == '\n'){break;}a[temp-96]++;}for(i = 1;i<=26;i++){if(a[i] == 0){continue;}if(a[i]<min){min = a[i];}if(a[i]>max){max = a[i];}}max = max-min;if(max<2){cout<<"No Answer\n0\n";}else{if(solution(max)){cout<<"Lucky Word"<<endl<<max<<endl;}else{cout<<"No Answer\n0\n";}}return 0;
}