什么是消息队列
可以简单理解为存放消息的队列,数据结构模型和队列一样,都是先进先出。主要用不同线程(Thread)/进程(Process)
为什么需要消息队列
(1)不同进程之间传递消息是,因为进程的耦合度高,改动一个进程,引发必须修改另一个进程。为了隔离两个进程,因此需要在进程间抽离出一层(一个模块),所有两进程之间传递的消息,都必须通过消息队列来传递,不会影响另一个。
(2)在两个不停运行的线程中,一个线程对另一个线程,进行通信,往往容易因为消息量大,而导致另一个线程处理不过来,导致请求丢失或是请求顺序错乱。当出现多生产多消费者的情况时,这种消息错乱的问题会更加明显。因此,我们需要一个消息队列维护消息的规范。
消息队列的应用场景
(1)上游不关心下游处理结果的场景
这一类场景就是类似请求生产者-消费者的场景。这种场景往往就是生产者(只需要生产,将消息给到消费者,打印机拿到消息后只需要消费,并且生产者不需要等待回应结果。举例说,A线程是负责对数据进行计算分析,B线程是负责对A分析的结果进行打印输出的,A+B线程完成一个数据计算分析后,打印输出的任务。A完成一次计算分析任务是不需要去等待B的回应,A只管计算分析,B只管拿到A的结果输出。这种情况下去使用消息队列是比较合适的,A只需要把分析结果写入消息队列,B只需要拿消息队列里面的消息进行打印,这样两者是互不影响的,也能解决并发引起的顺序和丢失问题。
值得注意的是,消息队列传递的是线程的输入输出数据,而且上游线程不需要关注输出数据。
(2)基于数据驱动的场景
这两类任务往往是多个线程配合完成一个工作,而且每一个线程的处理时长都比较久,外部传进来一个data数据包,A线程进行操作1,B线程要等待A线程处理后的data数据包完成操作2,C线程也同样需要B线程的处理结果进行操作3。
这种场景最常用的解决方案,往往是根据经验统计每一个任务的执行时间,然后人工定制一个排班时间表,然后通过时间表执行,这样往往会出现执行时长变化导致的任务无法正常执行
这时候消息队列主要的任务不是传输输入输出数据,传输的是信号,是通知下游线程执行的信号。同样这种场景也是和场景(1)一样,生产者不需要等待回应结果。那为什么不用场景(1)那样去直接用消息队列去传输处理完的data包呢?根据不同的业务可能会有以下原因:a,data数据包体积大,用在消息队列上面传输影响存储性能,这种情况往往是data数据包在一个地方因为某些原因不方便转移,而ABC线程是分别取到那里进行处理的。
(3)上游关注下游执行结果,但是执行时间很长。
有时候上游需要关注执行结果,但是执行结果时间很长(典型的就是调用离线处理,或是跨公网调用),也常用回调网关+MQ来解耦。
例如:微信支付,跨公网调用微信接口,执行时间会比较长,但调用方式又非常关注执行结果
这时候的解决方案流程就是
1)调用方直接跨公网调用微信接口
2)微信返回调用成功,此时不代表返回成功
3)微信执行完成后,回调统一网关
4)网关将返回结果通知MQ
5)请求方收到通知结果
这里需要注意的是,不应该由回调网关调用上游来通知结果,如果是这样的话,每次新增调用方,回调网关都需要修改代码,仍然会反向依赖,使用回调网关+MQ的方案,新增任何对微信支付的调用,都不需要修改代码,因为微信支付直接把调用接口的行为结果返回给你,告诉调用者已经成功调用了支付功能,但是微信后台可能也存在一个消息队列去接收这些支出请求去处理,处理完成了才会通知网关回调通知,至于支付有没有真正成功,就由网关这边进行进行MQ通知。所以这种场景,上游得到的执行结果也不是真正的执行结果,只是通知主线程可以进行下一个异步处理的通知,因为也会有调用支付成功的返回,但是又因为内部系统原因,没有支付成功的情况。所以,消息队列并不适合上游需要实时处理结果的场景
总结:
什么时候使用MQ?
1)数据驱动的任务依赖
2)上游不关心多下游执行结果
3)异步返回执行时间长
其他思考
MQ的缺点
(1)系统复杂程度提升,逻辑变得复杂。同时引入MQ组件,将会对原来的系统设计,通信方式产生大变化。同时系统的改造需要花费大量的资源,同时也要承担引入新组件带来的系统不稳定性。
(2)系统可用性降低,引入mq组件后,通信模型将会发生改变,消息的传递将会依赖于MQ,假如MQ挂了,将会直接导致系统崩溃,这应该怎么处理
(3)一致性问题。一个任务需要ABCD四个系统轮流去处理,A 系统处理完了直接返回成功了,大家都以为你这个请求就成功了;但是问题是,要是 BCD 三个系统那里,BD 两个系统写库成功了,结果 C 系统写库失败了,咋整?这样就会导致数据不一致。
流量整形,削峰填谷
(1)为什么要流量整形?
流量冲击(高并发情况下带来的突发流量):上游调用方(push)不限速。很快就会把下游压垮,这种场景往往发生在上游逻辑容易突然暴增,而同时下游的操作非常多,完成一次需要较多的时间。例如:上游发起下单操作,下游完成秒杀业务逻辑(库存检查,库存加锁,余额检查,订单生成,余额扣减,库存扣减,生成流水,余额解锁,库存解锁),上游业务简单,每秒发生10000个请求,下游业务复杂,每秒只能处理2000个请求,上游不限速下单,会导致下游系统处理不了庞大信息量,引发雪崩。
(2)常见的优化方案
a.上游队列缓冲(put阻塞),限速发送
b.下游队列缓冲(定时或者批量拉取pull,可以起到削平流量),限速执行
ps:如果上流发送流量过大,mq提供拉模式可以起到下游自我保护的作用,会不会引起mq队列的消息堆积呢?
答:下游MQ-client拉取消息,消息接收方能够批量获取消息,需要下游消息接收方进行优化(提供批处理,比如批量写),否则整体吞吐量低,也会导致mq堆积。
高并发系统保护策略
1.缓存
缓存不单单能够提升系统访问速度,也是保护数据库,保护系统的有效方式。大型网站一般主要是”读“,数据先进数据库,然后再走缓存。在大型”写“系统中,先走缓存,在走数据库,对数据库进行批处理操作。(积累一些数据,批量写入;内存里面的缓存队列,mq像是缓存队列)
2.降级
根据服务器压力,指定某些服务或者页面的级别(需求不同,降级策略也不同),为此释放服务器资源,保证核心任务的正常运行
根据服务方式:可以拒接服务,可以延迟服务,也有时候可以随机服务。
根据服务范围:可以砍掉某个功能,可以砍掉某些模块
如果不是核心链路,那么就把这个服务降级掉。打个比喻,现在的APP都讲究千人千面,拿到数据后,做个性化排序展示,如果在大流量下,这个排序就可以降级掉!
3.限流
限制系统的输入和输出流量以达到保护系统的目的。一般来说系统的吞吐量是可以被测算的,一旦达到阈值,就需要限制流量。比如:延迟处理,拒绝处理,部分处理等等
实际场景中常用的限流策略:
(1)nginx前端限流,
按照一定的规则如ip,账号,调用逻辑等在nginx层面做限流
(2)业务应用系统限流
(a)客户端限流(验证码;获取动态请求路径pathvariable,达到接口地址隐藏的效果)
(b)服务端限流(redis限速器,延迟队列)
(3)数据库限流
数据库连接池化,mysql(如max_connections),redis(如tcp-backlog)都会有类似的限制连接数的配置
限流算法
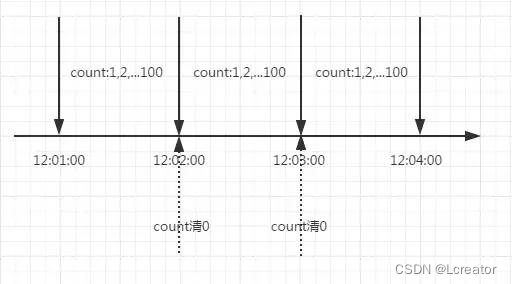
(1)计算器
计算器是一种比较简单的限流算法,用途比较广泛,在接口层面,很多地方使用这种方式限流。在一段时间内,进行计数,与阈值进行比较,到了时间临界点,将计数清0.
示例代码:
public class CustomerDemo {private static long timeStamp = System.currentTimeMillis();//限制为1s内 限制100请求private static long limitCount = 100;private static long interval = 1000;//请求数private static long reqCount = 0;public static boolean grant(){ //判断是否需要限流long now = System.currentTimeMillis();if (now < timeStamp+interval){ //当前时间在1s内if (reqCount < limitCount){//当前请求的数量不超过最大限制数,允许请求++reqCount;return true;}else{//否则限流return false;}}else{//超过了当前时间,计数器清0 timeStamp = System.currentTimeMillis();reqCount = 0;return false;}}public static void main(String[] args) {for (int i =0;i<500;i++){//模拟500个订单同时请求new Thread(new Runnable() {@Overridepublic void run() {if(grant()){System.out.println("执行业务逻辑");}else{System.out.println("限流");}}}).start();}}
}这里需要注意的是,存在一个时间临界点缺陷的问题。举个栗子,在12:01:00到12:01:58这段时间内没有用户请求,然后在12:01:59这一瞬时发出100个请求,OK,然后在12:02:00这一瞬时又发出了100个请求。这里你应该能感受到,在这个临界点可能会承受恶意用户的大量请求,甚至超出系统预期的承受。
滑动窗口
由于计数器存在临界点缺陷,后来出现了 滑动窗口算法来解决
滑动窗口的意思是说把固定时间片,进行划分,并且随着时间的流逝,进行移动,这样就巧妙的避开了计数器的临界点问题。也就是说这些固定数量的可以移动的格子,将会进行计数判断阈值,因此格子的数量影响这滑动窗口算法的精度。
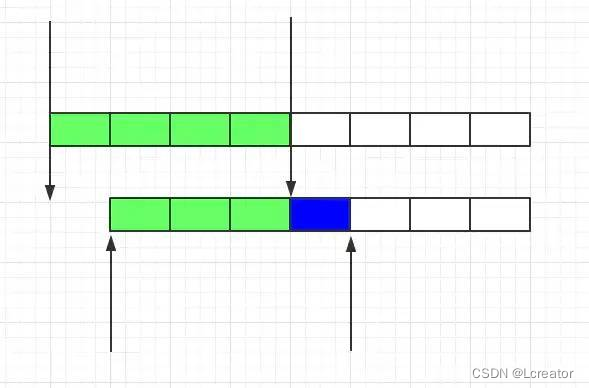
漏桶算法
虽然滑动窗口有效避免了时间临界点的问题,但是依然有时间片的概念,而漏桶算法在这方面比滑动窗口而言更加先进。
思想:有一个固定的桶,进水的速率是不确定的,但是出水的速率是恒定的,当水满的时候会溢出。
代码实现
public class LeakBucketDemo {//时间刻度private static long time = System.currentTimeMillis();//桶里面现在的水private static int water = 0;//桶的大小private static int size = 10;//出水率private static int rate = 3;public static boolean grant(){//计算出水数量long now = System.currentTimeMillis();int out = (int)((now - time)/700*rate);//出水量//漏水后的剩余water = Math.max(0,water-out);//避免剩余水量为负数time = now;if((water+1)<size){++water;return true;}else{return false;}}public static void main(String[] args) {for (int i =0;i<500;i++){ //模拟500个订单同时请求new Thread(new Runnable() {@Overridepublic void run() {if(grant()){System.out.println("执行业务逻辑");}else{System.out.println("限流");}}}).start();}}
}令牌桶算法
注意到,漏桶的出水速度是恒定的,那么意味着如果瞬时大流量的话,将有大部分请求被丢弃掉(也就是所谓的溢出)。为了解决这个问题,令牌桶进行了算法的改进
思想:令牌桶算法和漏桶算法不同的是,令牌桶是将以恒定的速度生成令牌放入到桶中,然后让请求过来了,拿到了令牌就请求,否则就丢弃;而漏桶是把请求放入漏桶,恒定速度去处理。这种方式可以避免了瞬间大流量而丢掉大量的请求。
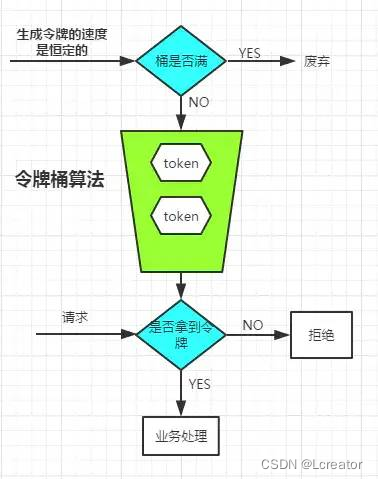
生成令牌的速度是恒定的,而请求去拿令牌是没有速度限制的。这意味,面对瞬时大流量,该算法可以在短时间内请求拿到大量令牌,而且拿令牌的过程并不是消耗很大的事情。(有一点生产令牌,消费令牌的意味) 不论是对于令牌桶拿不到令牌被拒绝,还是漏桶的水满了溢出,都是为了保证大部分流量的正常使用,而牺牲掉了少部分流量,这是合理的,如果因为极少部分流量需要保证的话,那么就可能导致系统达到极限而挂掉,得不偿失。
代码实现
public class TokenBucketDemo {private static long time = System.currentTimeMillis();private static int createTokenRate = 3;private static int size = 10;//当前令牌数量private static int token = 0;public static boolean grant(){long now = System.currentTimeMillis();//当前时间需要生产令牌数int in = (int)((now-time)/50*createTokenRate);token = Math.min(size,token+in);time = now;if (token>0){--token;return true;}else{return false;}}public static void main(String[] args) {for (int i =0;i<500;i++){ //模拟500个订单同时请求new Thread(new Runnable() {@Overridepublic void run() {if(grant()){System.out.println("执行业务逻辑");}else{System.out.println("限流");}}}).start();}}
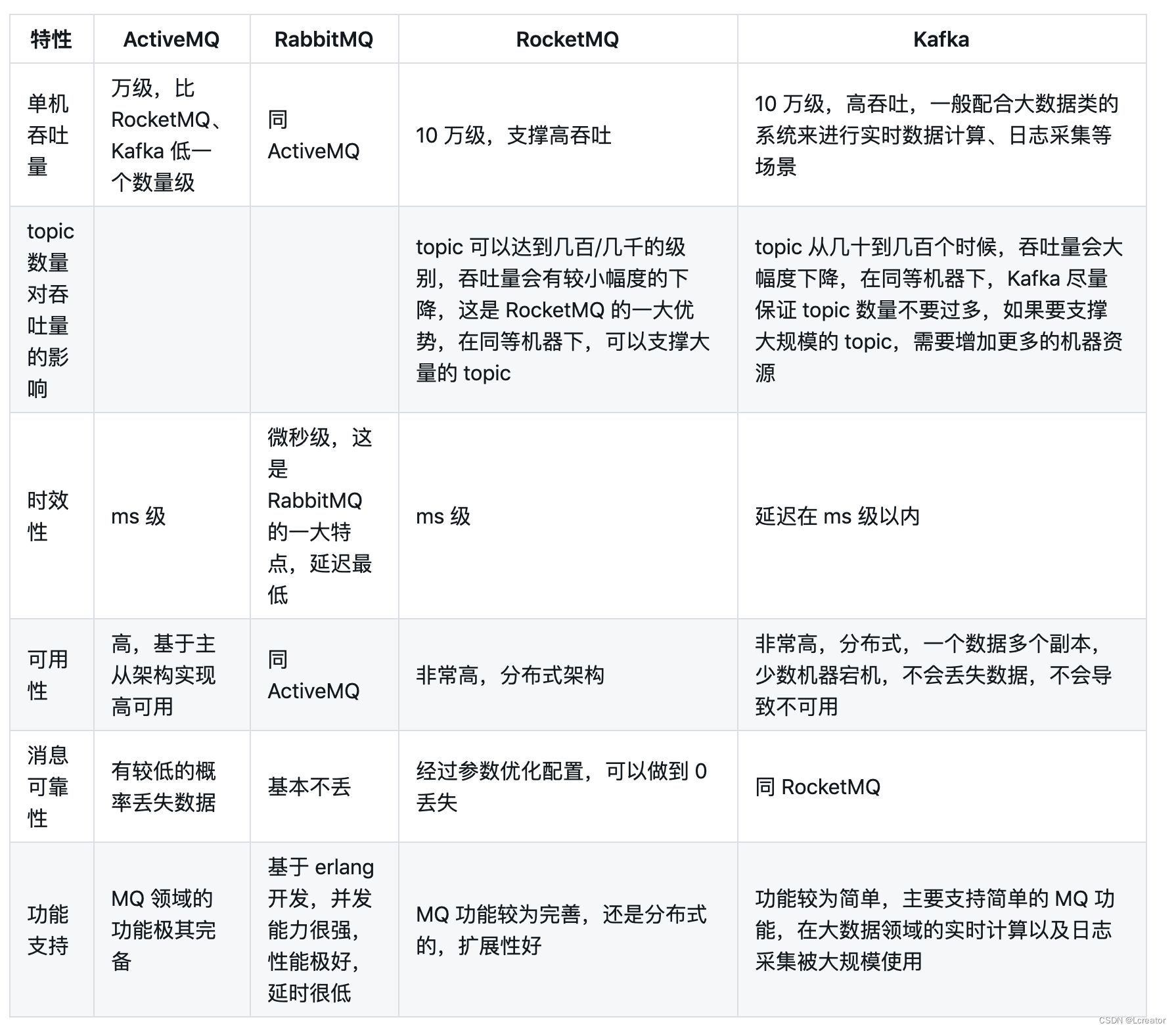
}常见消息队列对比
C++实现简单消息队列
在目前的工作中也用到多线程技术去完成一些相关的业务,其中利用消息队列在多线程之间通信中起到了非常重要的作用。因为我现在工作主要是用c++,所以下面附上自己在工作中要到c++简单实现的消息队列代码
MessageQueue.h
#ifndef MESSAGEQUEUE_H
#define MESSAGEQUEUE_H#include <queue>
#include <map>
#include <string>
#include <pthread.h>#define MSG_QUIT 0using namespace std;typedef struct {int code;void* data;
} MSG;typedef struct {pthread_mutex_t qmutex;pthread_cond_t qready;
} CondMutex;typedef struct {int id;string strJson;
} CONFIG_PACKET;class MessageQueue
{
public:MessageQueue();virtual ~MessageQueue();bool push(int code, void* data, int max_msg = 100);bool pop(MSG** pmsg);void wait(void);void wait(MSG** pmsg);protected:CondMutex m_mutex;queue<MSG*> m_msgs;map<int, int> msg_cnt;
};#endif // MESSAGEQUEUE_HMessageQueue.cpp
#include "MessageQueue.h"MessageQueue::MessageQueue()
{pthread_mutex_init(&m_mutex.qmutex, NULL);pthread_cond_init(&m_mutex.qready, NULL);
}MessageQueue::~MessageQueue()
{pthread_mutex_destroy(&m_mutex.qmutex);pthread_cond_destroy(&m_mutex.qready);
}bool MessageQueue::push(int code, void* data, int max_msg)
{bool bSuccess = false;pthread_mutex_lock(&m_mutex.qmutex);int& cnt = msg_cnt[code];if (cnt < max_msg) {MSG* pmsg = new MSG;pmsg->code = code;pmsg->data = data;m_msgs.push(pmsg);cnt++;pthread_cond_signal(&m_mutex.qready);bSuccess = true;}pthread_mutex_unlock(&m_mutex.qmutex);return bSuccess;
}bool MessageQueue::pop(MSG** pmsg)
{*pmsg = NULL;pthread_mutex_lock(&m_mutex.qmutex);if (!m_msgs.empty()) {*pmsg = m_msgs.front();msg_cnt[(*pmsg)->code]--;m_msgs.pop();}pthread_mutex_unlock(&m_mutex.qmutex);return *pmsg != NULL;
}void MessageQueue::wait(void)
{pthread_mutex_lock(&m_mutex.qmutex);while (m_msgs.empty()) {pthread_cond_wait(&m_mutex.qready, &m_mutex.qmutex);}pthread_mutex_unlock(&m_mutex.qmutex);
}void MessageQueue::wait(MSG** pmsg)
{*pmsg = NULL;pthread_mutex_lock(&m_mutex.qmutex);while (m_msgs.empty()) {pthread_cond_wait(&m_mutex.qready, &m_mutex.qmutex);}*pmsg = m_msgs.front();msg_cnt[(*pmsg)->code]--;m_msgs.pop();pthread_mutex_unlock(&m_mutex.qmutex);
}







![论文解读 | [CVPR2019] 基于自适应文本区域表示的任意形状场景文本检测](https://img-blog.csdnimg.cn/b80f82f5ab5b4ad0a79665af539a39fb.png)