Lightweight adaptive weighted network for single image super-resolution
(单幅图像超分辨率的轻量级自适应加权网络)
近年来,深度学习已成功应用于单幅图像超分辨率(SISR)任务,并取得了上级的性能。然而,大多数基于卷积神经网络(CNN)的SR模型都有大量的参数需要优化,这需要大量的计算,从而限制了它们的实际应用。针对这一问题,提出了一种新的轻量级SR网络–自适应加权超分辨率网络(LW-AWSRN)。在LW-AWSRN中提出了一种新的局部融合模块(LFB),该模块由多个**自适应加权残差单元(AWRU)和一个局部残差融合单元(LRFU)**组成。此外,提出了一种自适应加权多尺度(AWMS)模型,以充分利用特征进行HR图像重建。AWMS模块包含多个尺度的卷积,并根据自适应权值对网络的贡献去除冗余尺度分支。在常用数据集上的实验结果表明,在相似参数和计算开销下,LW-AWSRN在× 2、× 3、× 4和× 8尺度因子下的性能上级现有方法。这表明LW-AWSRN在重建质量和模型大小之间具有更好的平衡。
介绍
单一图像超分辨率(SISR)旨在重建高分辨率(人力资源)从低分辨率图像(LR)。近年来已经引起了相当大的关注由于其广泛的应用领域的图像处理、计算机视觉等等。虽然有些SISR提出了解决方案,这仍然是一个挑战性的任务是一个不适定逆过程。
传统的SISR模型主要分为三类,即基于插值、正则化和学习的方法。随着深度学习(DL)技术的快速发展,其在SISR领域中占据主导地位。在Dong等人提出基于卷积神经网络(CNN)的SR(SRCNN)算法之后,该算法显著优于几乎所有先前的工作,已经提出了各种基于DL的SR算法。
众所周知,具有更深架构和残差学习(RL)技术的DL模型通常在SR领域中实现上级的性能。因此,已经提出了许多具有大模型尺寸的基于深度RL的SR网络来追求最终性能,例如EDSR、RDN,RCAN。由于大量的参数,这些SR网络通常遭受大存储器消耗、长推断时间和高计算成本的问题、,这使得它们在现实应用中不太实用,尤其是在计算能力有限的平台上。因此,需要具有较少参数的深层SISR模型。
幸运的是,最近开发的轻量级CNN是这个问题的可行解决方案,已经引起了相当大的关注。几种策略,例如后上采样、递归学习和群卷积已被用于构建SR任务的轻量级模型。其中,后上采样策略直接从原始LR图像中提取特征,这由于较小的输入图像大小而大大减少了计算操作。递归学习策略递归地使用相同的网络模块来获得高级特征而不引入附加参数。在SR任务中也采用了组卷积策略,这大大减少了参数的数量,而只有很小的性能损失。然而,在重建质量和模型大小之间仍有更好的权衡余地。
另一方面,基于极深RL的SR网络容易受到爆炸梯度问题的影响,这可能导致模型训练的不稳定性。为了解决这个问题,提出了残差缩放技巧,通过为残差单元选择固定权重来限制梯度流。但是,这种伎俩并不能保证性能的提高。例如,HyoungHo等人提出的加权残差单元(wRU)是残差缩放的可行改进,但WRU也引入了额外参数和计算过载。
此外,值得注意的是,大多数现有SR网络仅具有使用转置卷积或像素混洗层的单尺度重构层,导致功能利用率不足。虽然MSRN采用多尺度策略进行残差单元(RU)的特征融合,并被证明对重建质量有帮助,但这会带来更多的参数,通常不适合开发轻量化模型。
为此,本文提出了一种新的轻量级自适应加权SR网络(LW-AWSRN),在一定程度上解决了上述问题。它包括一系列用于非线性特征变换的堆叠局部融合块(LFB)和用于重建的自适应加权多尺度(AWMS)模块。LFB自适应地学习RUs的权值,使得梯度的流动更加有效,AWMS模块充分利用非线性映射模块的输出特征重构高分辨率图像。与常用的基线模型和最先进的轻量化模型相比,所提出的LW-AWSRN模型以较少的参数实现了最先进的SISR性能。如图1所示,Set 5数据集的结果表明LW-AWSRN在重建质量和模型大小之间实现了更好的平衡。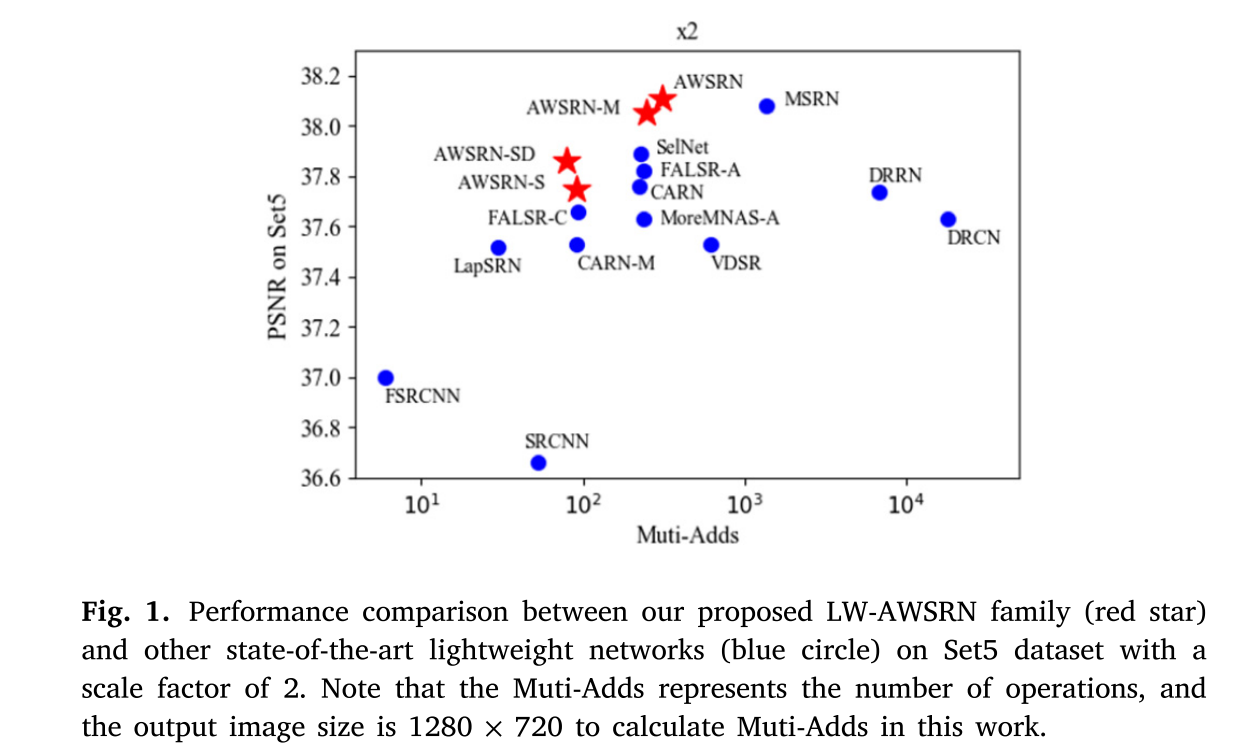
相关工作
Lightweight CNN for SR
目前基于神经网络的随机共振模型由于能够有效地表征更深层次的网络特征,因此无论模型大小,都倾向于追求最终的性能。例如,MDSR算法使用改进的RU堆叠超过160层的网络,而RCAN甚至通过残中残和信道注意机制构建了400多层的网络,以获得更好的性能。
随着结构的加深,参数和计算操作的数量也大大增加,这限制了它们的实际应用。
针对这一问题,提出了基于神经网络的轻量级随机共振模型。一些策略有助于构建轻量级模型,例如后上采样、递归学习和组卷积)。代替将内插的LR图像作为输入的预上采样策略,后上采样策略直接从原始小尺寸LR图像中提取特征,大大降低了计算复杂度。它已广泛用于SISR模型。
递归学习策略以递归方式多次应用相同的模块以构建用于更高级特征的非常深的结构,而不引入附加参数。因此,它已被采用在几种模型中。但是由于递归机制,计算操作(Multi-Adds)的数量仍然非常大。
受其他计算机视觉任务中高效轻量模型工作的激励,一些基本的轻量化设计也被用于SR。CARN-M也采用了几种基本的轻量化设计用群卷积代替了普通卷积,并以很小的性能代价获得了与计算量大的模型相当的结果。然而,在重建质量和计算操作之间仍有更好的折衷的余地。
神经结构搜索(NAS)是一种新兴的自动设计有效网络的方法,已将其引入SR任务,以开发MoreMNA-S和FALSR算法。如图1所示,MoreMNAS和FALSR算法都具有较少的计算操作和相当的性能。然而,由于NAS中搜索空间和策略的限制,其性能仍然有限,并且寻找最优结构的训练过程通常花费太多的时间和计算资源。
所有这些工作表明,轻量级SR网络可以在重建质量和模型大小之间保持良好的平衡。然而,如何构建轻量级的SR网络仍然是一个具有挑战性的任务。
Residual learning in SR
RL已广泛用于各种CV任务的CNN模型中。VDSR首先将RL应用于SISR,然后与SRCNN相比显著提高了重建质量,越来越多的变体通过利用RL产生。例如,SRResNet采用ResNet中的RU来构建更深层次的网络,以获得更好的性能;EDSR通过进一步改进SRResNet的RU赢得了NTIRE 2017超级分辨率挑战赛,而WDSR凭借广角激活RU赢得了NTIRE 2018超级分辨率挑战赛。这些工作表明了RL的有效性。
另一方面,基于深度RL的SR模型可能遭受爆炸梯度。残差缩放可以通过残差单元的固定权重来有效地缓解该问题。然而,固定权重可能不适合于一个模型中的不同残差单元。Jung等人提出了用于图像分类的wRU,其设计了一个模块(wSE)来生成RU的权重。作为残差尺度的一种扩展形式,小波变换可以应用于SR网络,以获得上级的重构效果。然而,wSE引入了额外的参数和计算操作来生成权重。
受wSE启发,提出了一种新的自适应加权RU(AWRU),用于自适应学习SR模型中RU的权重。所提出的AWRU有助于信息和梯度在RU内更有效地流动,并且其不引入附加参数。
Upsampling methods in SR
在SISR中,上采样是影响重建质量的核心因素。与早期SR模型中基于插值的方法不同,基于学习的上采样方法(如转置卷积和像素混洗)通常在网络的最后阶段实现上采样。由于与基于内插的方法相比,这两种基于学习的上采样方法提供了更有价值的上下文信息和更好的特征利用,因此它们在最近的研究中已经成为最广泛使用的上采样方法。然而,这些模型仅使用单尺度卷积分支进行重构,这没有充分利用来自非线性映射模块的特征信息。
另一方面,采用多尺度策略的模型一般在特征提取模块而不是重构模块中使用不同大小的卷积核,不能解决上述问题。此外,不同尺度的卷积分支将导致更多的参数和计算开销。
针对这种情况,提出了一种轻量级模型的AWMS重构模块,以更有效地利用非线性映射模块的特征,而不需要繁重的计算操作。
Contributions
综上所述,我们提出了一个LW-AWSRN算法,它在SR性能和模型大小之间有着上级的平衡。该算法在不增加计算开销的情况下,自适应地学习资源单元和AWMS中不同分支的权值。这项工作的主要贡献有三个方面:
1)我们提出了一种自适应加权策略,将自适应学习的权值分配给RU中的分支。然后将其嵌入到非线性映射模块中的LFB和LFB中的AWRU中,如图2所示。与wSE需要额外的参数和计算操作来生成权重不同,我们的LFB和AWRU中的权重是独立学习的,然后在网络中不需要任何额外的模块来生成。也就是说,在每个LFB和AWRU中不需要额外的计算操作。这种新的自适应加权策略还使得信息流和梯度在LFB和AWRU中更有效。
2)我们提出了一个AWMS重建模块,以更好地利用来自非线性映射模块的特征。如图2所示,AWMS模块中的分支具有不同大小的卷积核,以获得多尺度特征信息,充分利用了这些特征,进一步提高了重构性能。更重要的是,在测试阶段,可以根据自适应学习的权值去除冗余的尺度分支,这实际上是一种灵活的修剪策略,可以在不损失重建质量的情况下进一步减少网络参数。
3)我们在五个基准数据集上评估了我们的LW-AWSRN,与最先进的轻量级SISR算法(如图1所示的Set 5数据集示例)相比,它使用竞争性参数实现了上级的重建性能。实验结果表明,所提出的LW-AWSRN能够在重构质量和模型大小之间取得较好的折衷。
方法
Network architecture
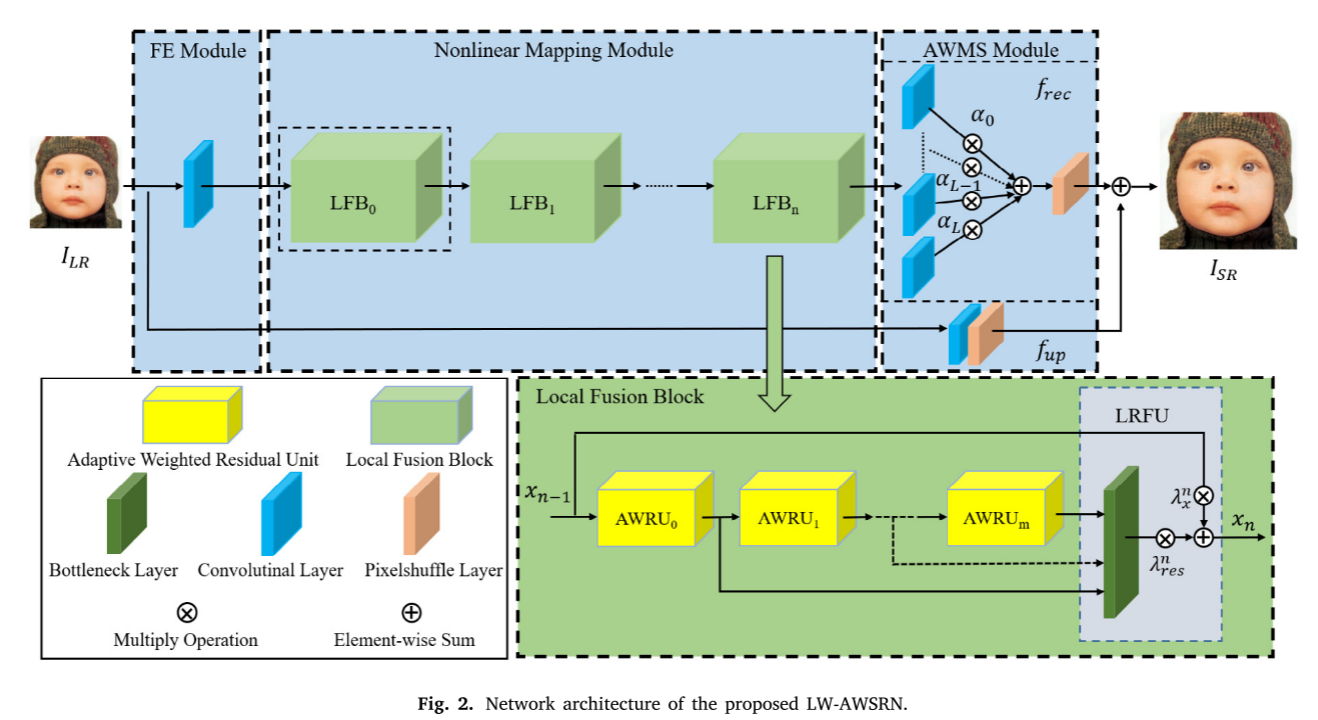
图2显示了所提出的LW-AWSRN的网络结构,其由三个模块组成,即特征提取(FE)模块、具有堆叠LFB的非线性映射模块和AWMS重构模块。
LR图像首先被馈送到包含卷积层的FE模块以提取浅部特征。FE模块可表示为:

其中𝑓𝑒𝑥𝑡(·)表示具有3 × 3内核的卷积层,用于从输入LR图像中提取特征𝐼𝐿𝑅,𝑥0是从卷积层中提取的特征图。值得注意的是,为了轻量化设计,这里只使用了一个卷积层。
从浅层网络学习的特征然后被输入到非线性映射模块以生成新的强大的特征表示,其包括若干堆叠的LFB。我们将所提出的LFB表示为𝑓𝐿𝐹𝐵(⋅),它可以由下式给出:
来自𝑥𝑛非线性映射模块的最后一个LFB的输出最终被上采样以在AWMS模块中重建HR图像。此外,我们在AWMS模块中通过堆叠卷积层和像素混洗层(𝐼𝐿𝑅用作输入)实现了全局残差路径𝑓up。AWMS重构模块公式如下:
其中𝑓rec(·)是多尺度重构模块,𝐼𝑆𝑅是网络的最终结果。具有较低贡献的尺度分支可以在推断阶段期间被去除以进一步减少计算操作。
Local fusion block
非线性映射模块包括若干个层叠的LFB,每个LFB由两部分组成:多个堆叠的AWRU和一个LRFU。
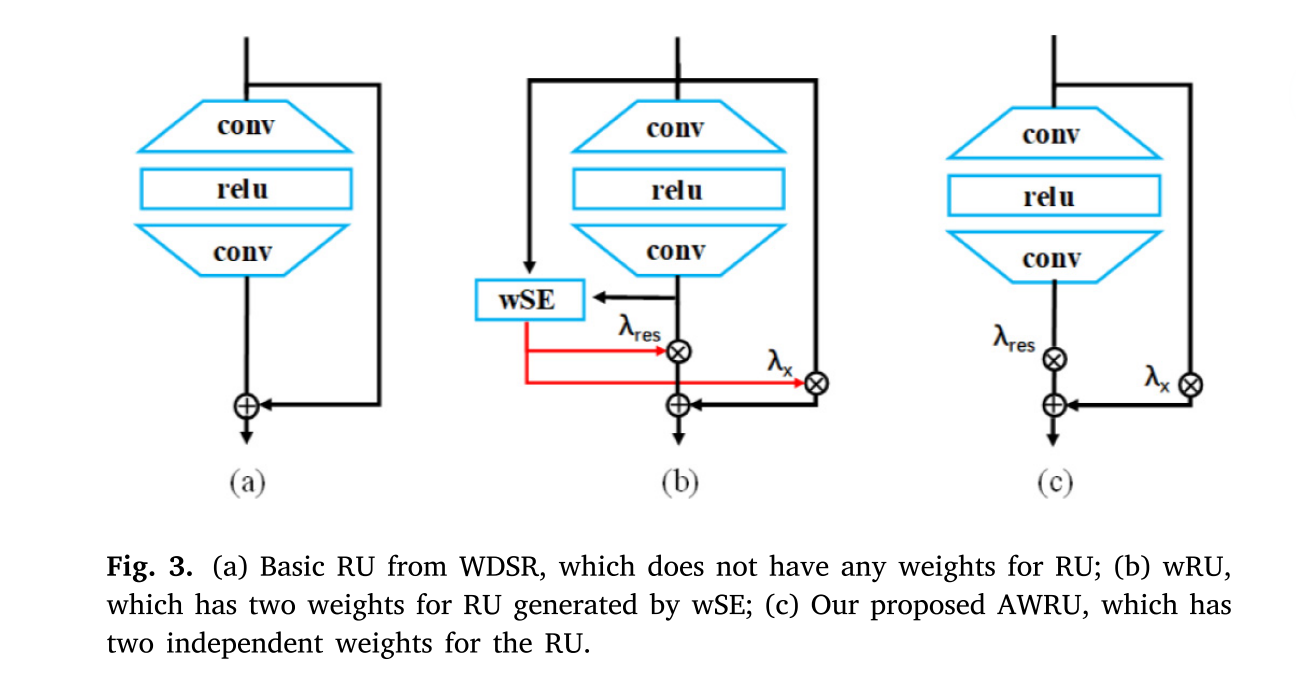
本文采用WDSR中的宽激活RU作为基本RU。EDSR中常用的RUs在激活函数之前具有相同数目的输入通道,在激活函数之后具有相同数目的输出通道。然而,如图3(a)所示,在WDSR中,输入声道数被设置为RU中输出声道数的r倍,其中r是扩展因子。因此,该单元通过在ReLU之前收缩单元的输入和输出通道的维度并扩展内部维度,允许激活更多低级信息而不增加参数。
然后,我们提出了基于基本RU的AWRU,如图3©所示。基本RU不具有任何RU权重,而图3(b)中所示的wRU具有由wSE生成的RU的两个权重。WSE通过多个全连通层和sigmoid函数生成两个权值,从而得到更多的参数。相反,我们提出的AWRU只包含两个独立的权值,在初始化后可以自适应地学习。应当注意,DL模型仅在训练阶段期间通过梯度下降基于训练数据更新其可学习参数,包括权重。在DL模型被训练之后,网络中的所有参数对于测试阶段是固定的。
定义𝑥𝑘-1和𝑥𝑘作为RU的输入和输出特征映射。基本RU可计算为
wRU和AWRU都可以计算为
AWRU由两个核大小为3 × 3的卷积层、一个ReLU激活层和两个独立的权值组成,主要用于特征提取和表示。定义𝑥𝑛-1和𝑥𝑛作为n个LFB的输入和输出。在每个LFB中,第m个AWRU的输出𝑥𝑚𝑥^{𝑚}xm𝑛将被馈送到LRFU。如图2所示,LRFU中嵌入了bottleneck层,以融合多个级别的信息,并匹配捷径分支的维度。因此,第n个LFB中的bottleneck层的计算可以被计算为
其中𝑓𝑛𝑓^{𝑛}fn𝑏𝑜𝑡(⋅)表示第n个LFB中LRFU的bottleneck层,𝑥𝑏𝑜𝑡 是bottleneck层的输出,[⋅]是来自不同AWRU的特征映射的连接。bottleneck层是1×1核的卷积层,而不是常用的3 × 3核,以减少输入特征图的数量。
将𝜆^𝑛𝑟𝑒𝑠和 𝜆^𝑛 𝑥分别定义为残差分支和主分支的相应自适应权重。LFB的输出特性𝑥𝑛可计算为

Adaptive weighted multi-scale reconstruction
我们进一步提出了一个AWMS模块,以更好地利用来自非线性映射模块的特征。如图2所示,AWMS模块中不同尺度分支具有不同的卷积核大小,这表明提取多尺度特征的感受域不同。
定义𝑥𝑛和𝑥𝑢𝑝分别作为AWMS重构的输入和输出𝛼𝑖是第𝑖尺度分支的自适应权重。AWMS重构模块可以表示为:
在测试阶段可以去除贡献较小的尺度分支,这些分支具有非常少的自适应学习权重𝛼𝑖,以进一步减少计算操作。值得注意的是,在这项工作中有四个分支,其对应的卷积核大小分别为3、5、7、9。更具体地,AWMS模块的输入特征没有被分成四个分支。实际上,来自非线性映射模块的所有特征图同时被馈送到四组滤波器。因此,这种网络结构可以更好地利用来自非线性映射模块的特征。