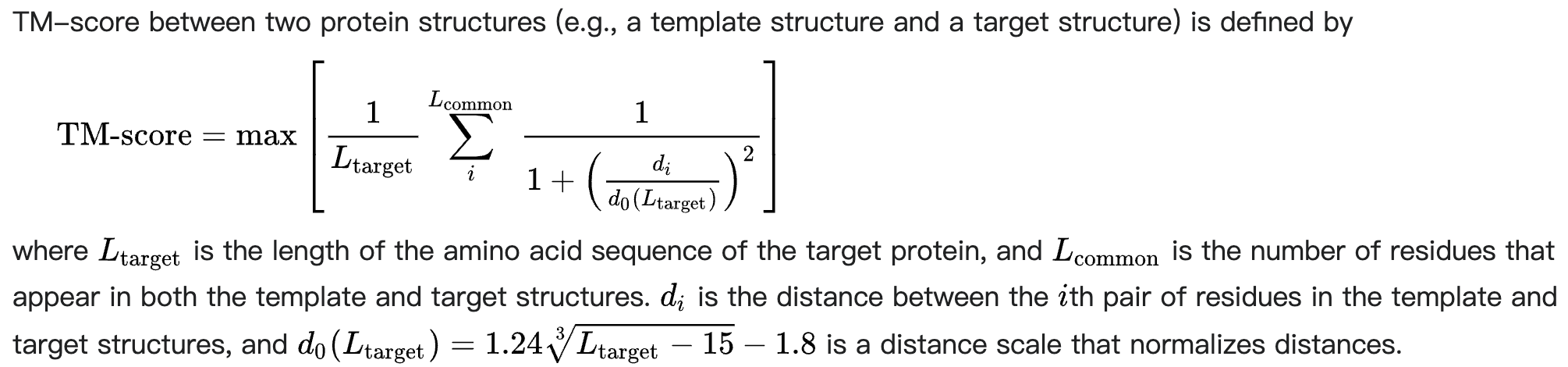
对于二元分类问题来说,分类的结果和数据的特征之间仍呈现相关关系,但是y的值不再是连续的,是0~1的跃迁。但是在这个过程中,什么仍然是连续的呢?”是概率,概率是逐渐升高的,当达到一个关键点(阈值),概率就超过了0.5。那么从这个点开始,之后y的预测值都为1。
文章目录
- 1. 导入CSV文件
- 2.如果是二元分类,看一下分类比例
- 3.画图
- 4. 构建特征集和标签集
- 5. 拆分数据集为训练集和测试集
- 6.对数据集进行归一化(用或不用均可,都用看看谁的准确率高)
- 7.使用哑特征
- 7. 使用逻辑回归创建模型
1. 导入CSV文件
import numpy as np # 导入Num Py库import pandas as pd # 导入Pandas库df_heart = pd.read_csv('/kaggle/input/myheart/heart.csv') # 读取文件df_heart.head() # 显示前5行数据
2.如果是二元分类,看一下分类比例
如果非二元分类,可以忽略
df_heart.分类列名.value_counts() # 输出分类值, 及各个类别数目
如果两种分类的总数相差很大,那么说明数据集很差
3.画图
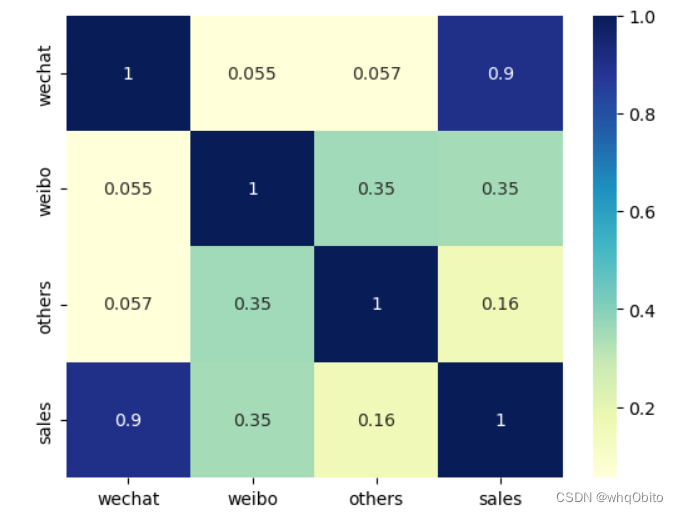
可以画热力图,适用于字段少的情况,代码:
import matplotlib.pyplot as plt #Matplotlib为Python画图工具库import seaborn as sns #Seaborn为统计学数据可视化工具库#对所有的标签和特征两两显示其相关性的热力图sns.heatmap(df_heart.corr(), cmap='YlGnBu', annot = True)plt.show() #plt代表英文plot, 就是画图的意思
也可以画散点图,可以判断两个字段
plt.scatter(x=df_heart.age[df_heart.target==1],y=df_heart.thalach[(df_heart.target==1)], c='red')plt.scatter(x=df_heart.age[df_heart.target==0],y=df_heart.thalach[(df_heart.target==0)], marker='^')plt.legend(['Disease', 'No Disease']) # 显示图例plt.xlabel('Age') # x轴标签plt.ylabel('Heart Rate') # y轴标签
plt.show()
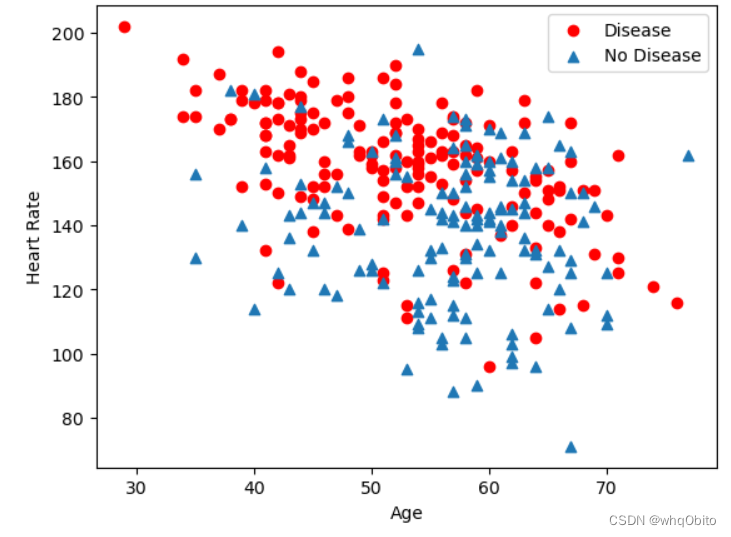
4. 构建特征集和标签集
特征集就是自变量集,标签集就是因变量集
X = df_heart.drop(['判断的列名'], axis = 1) # 构建特征集y = df_heart.判断的列名.values # 构建标签集y = y.reshape(-1, 1) # -1是相对索引, 等价于len(y)print('张量X的形状:', X.shape)print('张量X的形状:', y.shape)
5. 拆分数据集为训练集和测试集
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
6.对数据集进行归一化(用或不用均可,都用看看谁的准确率高)
这步就是把所有值都变成0-1
from sklearn.preprocessing import MinMaxScaler # 导入数据缩放器scaler = MinMaxScaler() # 选择归一化数据缩放器Min Max ScalerX_train = scaler.fit_transform(X_train) # 特征归一化训练集fit_transformX_test = scaler.transform(X_test) # 特征归一化测试集transform
y_train, y_test因为原本就是非0即1所以不用归一化,否则仍然需要
训练集和测试集使用不同的方法归一化
7.使用哑特征
就是比如一个字段有4种取值,0,1,2,3分别是代表不同类型,和大小无关,但是如果直接把那些字段创建模型,可能会把数字以大小判断,解决方案就是可以变成多4个字段,每个字段用1或0,
如这种类型
变成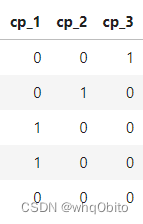
这样做之后会发现模型的准确率将有显著的提升
7. 使用逻辑回归创建模型
模型就是函数的意思
from sklearn.linear_model import LogisticRegression #导入逻辑回归模型lr = LogisticRegression() # lr, 就代表是逻辑回归模型lr.fit(X_train, y_train) # fit, 就相当于是梯度下降print('SK learn逻辑回归测试准确率{:.2f}%'.format(lr.score(X_test, y_test)*100))