目录
一、分页
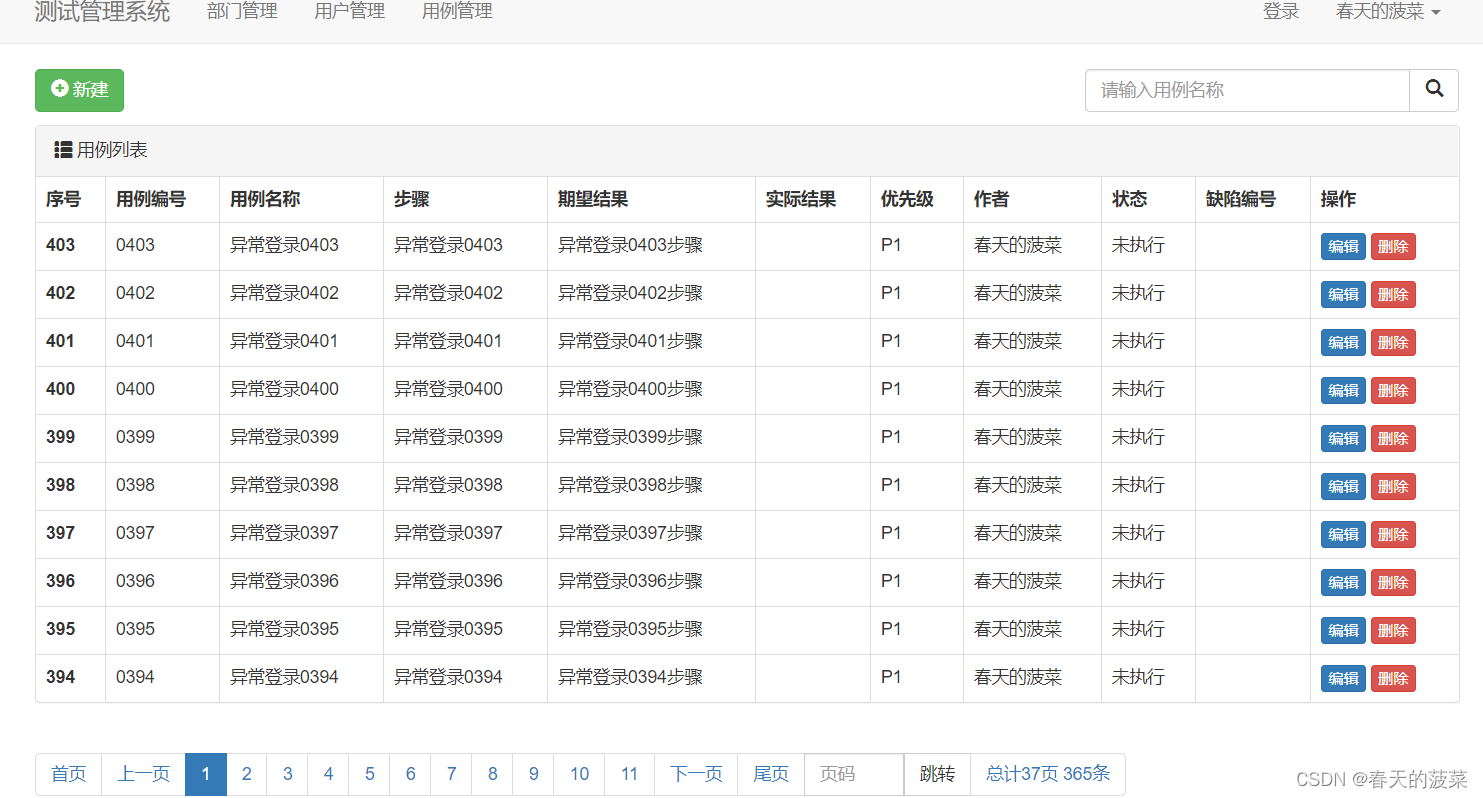
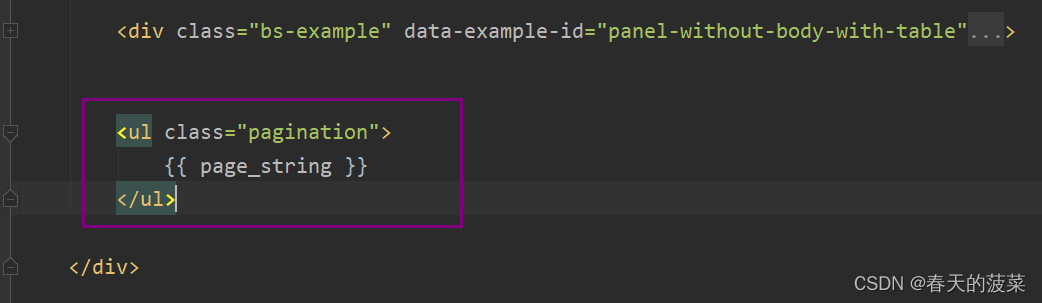
1、修改case_list.html页面
2、修改views.py的case_list方法(分页未封装)
二、分页封装
1、新建类Pagination
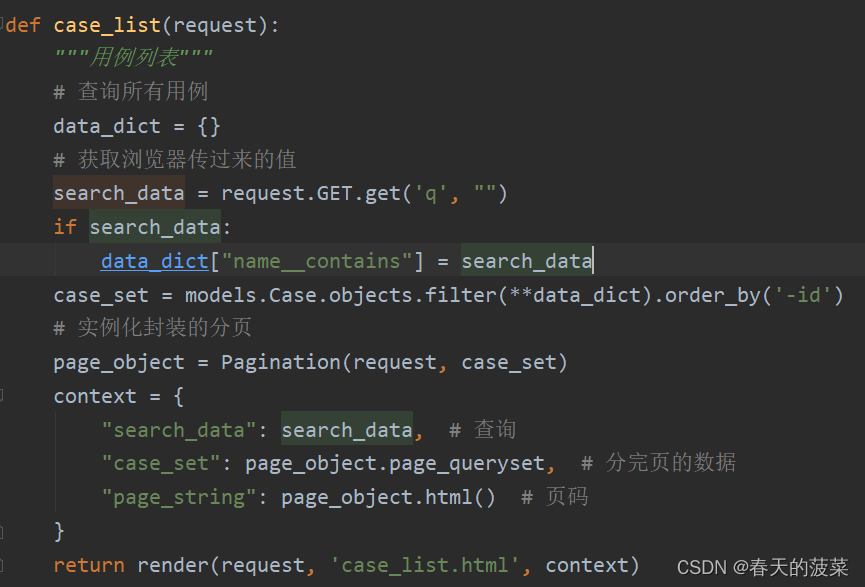
2、修改views.py的case_list方法
三、再优化,实现搜索+分页qing情况
四、优化其他查询页面实现分页和查询
五、优化分页显示总页数和总条数
接上一篇《django项目实战二(django+bootstrap实现增删改查)进阶查询》
知识点:
分页的封装
一、分页

1、修改case_list.html页面
{% extends 'layout.html' %}
{% block title %}<title>用例列表</title>
{% endblock %}
{% block content %}<div class="container"><div style="margin-bottom: 10px" class="clearfix"><a class="btn btn-success" href="/case/add/"><span class="glyphicon glyphicon-plus-sign" aria-hidden="true"></span>新建</a><div style="float: right;width: 300px"><form method="get"><div class="input-group"><input type="text" name="q" class="form-control" placeholder="请输入用例名称"value="{{ search_data }}"><span class="input-group-btn"><button class="btn btn-default" type="submit"><span class="glyphicon glyphicon-search" aria-hidden="true"></span></button></span></div></form></div></div><div class="bs-example" data-example-id="panel-without-body-with-table"><div class="panel panel-default"><!-- Default panel contents --><div class="panel-heading"><span class="glyphicon glyphicon-th-list" aria-hidden="true"></span>用例列表</div><!-- Table --><table class="table table-bordered"><thead><tr><th>序号</th><th>用例编号</th><th>用例名称</th><th>步骤</th><th>期望结果</th><th>实际结果</th><th>优先级</th><th>作者</th><th>状态</th><th>缺陷编号</th><th>操作</th></tr></thead><tbody>{% for obj in case_set %}<tr><th scope="row">{{ obj.id }}</th><td>{{ obj.number }}</td><td>{{ obj.name }}</td><td>{{ obj.step }}</td><td>{{ obj.expect }}</td><td>{{ obj.actual|default_if_none:" " }}</td><td>{{ obj.get_priority_display }}</td><td>{{ obj.author }}</td><td>{{ obj.get_status_display }}</td><td>{{ obj.bug_no|default_if_none:" " }}</td><td><a class="btn btn-primary btn-xs" href="/case/{{ obj.id }}/edit/">编辑</a><a class="btn btn-danger btn-xs" href="/case/{{ obj.id }}/delete/">删除</a></td></tr>{% endfor %}</tbody></table></div></div><ul class="pagination">{{ page_string }} </ul></div>{% endblock %}2、修改views.py的case_list方法(分页未封装)
from django.core.exceptions import ValidationError
from django.shortcuts import render, redirect, HttpResponse
from TestManagementSystem import models
from django import forms
from django.core.validators import RegexValidator
from django.utils.safestring import mark_safe
# Create your views here.def depart_list(request):"""部门列表"""# 查询所有部门print("部门列表")depart_set = models.Department.objects.all()return render(request, 'depart_list.html', {"depart_set": depart_set})def depart_add(request):"""新增部门"""# 新增部门# return HttpResponse("成功")if request.method =='GET':return render(request, 'depart_add.html')depart_name = request.POST.get("departname")models.Department.objects.create(name=depart_name)return redirect('/depart/list')def depart_delete(request):"""删除部门"""depart_id = request.GET.get("departid")models.Department.objects.filter(id=depart_id).delete()return redirect('/depart/list')def depart_edit(request, nid):"""编辑部门"""if request.method == 'GET':row_object = models.Department.objects.filter(id=nid).first()# print(row_object.id, row_object.name)return render(request, 'depart_edit.html', {"row_object": row_object})# 获取用户提交的部门名称edit_depart_name = request.POST.get("departname")# 根据编辑页面用户ID去更新部门的名称models.Department.objects.filter(id=nid).update(name=edit_depart_name)return redirect('/depart/list')def user_list(request):"""用户列表"""# 查询所有用户user_set = models.UserInfo.objects.all()"""for obj in user_set:print(obj.id, obj.name, obj.password, obj.account, obj.create_time.strftime("%Y-%m-%d-%H-%M-%S"),obj.get_gender_display(), obj.depart.name)"""return render(request, 'user_list.html', {"user_set": user_set})def user_add(request):"""新增用户(原始方式)"""if request.method == 'GET':# 这个是为了新增页面动态获取性别context = {"gender_choices": models.UserInfo.gender_choices,"depart_list": models.Department.objects.all()}return render(request, 'user_add.html', context)user_name = request.POST.get("username")password = request.POST.get("pwd")age = request.POST.get("age")account = request.POST.get("ac")create_time = request.POST.get("ctime")gender = request.POST.get("gd")depart_id = request.POST.get("dp")models.UserInfo.objects.create(name=user_name, password=password,age=age, account=account,create_time=create_time,gender=gender, depart_id=depart_id)return redirect('/user/list')class UserModelForm(forms.ModelForm):# 限制姓名的长度,至少为3位name = forms.CharField(min_length=3, label='用户名')# password = forms.CharField(label='密码',validators='这里写正则表达式')class Meta:model = models.UserInfofields = ["name", "password", "age", "account", "create_time", "gender", "depart"]'''widgets = {"name": forms.TextInput(attrs={"class": "form-control"}),"password": forms.PasswordInput(attrs={"class": "form-control"}),"age": forms.TextInput(attrs={"class": "form-control"}),"account": forms.TextInput(attrs={"class": "form-control"}) }''' # 下方方法更好def __init__(self, *args, **kwargs):super().__init__(*args, **kwargs)# 循环找到所有插件,添加了class: "from-control"for name, field in self.fields.items():field.widget.attrs = {"class": "form-control", "placeholder": field.label}def user_model_form_add(request):"""新增用户(ModelForm方式)"""if request.method == 'GET':form = UserModelForm()return render(request, 'user_model_form_add.html', {"form": form})# POST 请求提交的数据,数据校验form = UserModelForm(data=request.POST)if form.is_valid():# 如果数据合法,这里判断的是所有字段不能为空,则存储到数据库# models.UserInfo.objects.create(..) 常规存储方式form.save()return redirect('/user/list')# 如果不满足if判断进入到else返回错误信息return render(request, 'user_model_form_add.html', {"form": form})def user_edit(request, nid):"""编辑用户"""# 根据nid去数据库获取所在行数据row_object = models.UserInfo.objects.filter(id=nid).first()if request.method == 'GET':form = UserModelForm(instance=row_object)return render(request, 'user_edit.html', {"form": form})# POST 请求提交的数据,数据校验form = UserModelForm(data=request.POST, instance=row_object)if form.is_valid():# 如果数据合法,这里判断的是所有字段不能为空,则存储到数据库# models.UserInfo.objects.create(..) 常规存储方式# form.instance.字段名=值 # 如果需要存储用户输入之外的值使用这个form.save()return redirect('/user/list')# 如果不满足if判断进入到else返回错误信息return render(request, 'user_edit.html', {"form": form})def user_delete(request, nid):"""删除用户"""# 根据nid去数据库获取所在行数据进行删除models.UserInfo.objects.filter(id=nid).delete()return redirect('/user/list')def case_list(request):"""用例列表"""# 查询所有用例data_dict = {}# 获取浏览器传过来的值search_data = request.GET.get('q', "")if search_data:data_dict["name__contains"] = search_data# 根据用户想要的访问页码,计算出起止位置page = int(request.GET.get('page', 1))page_size = 10 # 每页显示数据量start = (page - 1) * page_sizeend = page * page_sizecase_set = models.Case.objects.filter(**data_dict).order_by('-id')[start:end]# 数据总条数total_count = models.Case.objects.filter(**data_dict).order_by('-id').count()total_page_count, div = divmod(total_count, page_size)if div:total_page_count += 1# 计算出,线上当前页的前5页,后5页,plus=5plus = 5# 数据未到达11页(数据量不达标时)if total_count <= 2 * plus + 1:start_page = 1end_page = total_page_countelse:# 当前页< 5(前面的异常考虑)if page <= plus:start_page = 1end_page = 2 * plus + 1else:# 当前页+plus大于总页面(后面的异常考虑)if page + plus > total_page_count:start_page = total_page_count - 2 * plusend_page = total_page_countelse:# 前五页,后五页start_page = page - plusend_page = page + plus# 页码page_str_list = []# 首页page_str_list.append('<li><a href="?page={}">首页</a></li>'.format(1))# 上一页if page > 1:prev = '<li><a href="?page={}">上一页</a></li>'.format(page-1)else:prev = '<li><a href="?page={}">上一页</a></li>'.format(1)page_str_list.append(prev)# 页面for i in range(start_page, end_page + 1):if i == page:ele = '<li class="active"><a href="?page={}">{}</a></li>'.format(i, i)else:ele = '<li><a href="?page={}">{}</a></li>'.format(i, i)page_str_list.append(ele)# 下一页if page < total_page_count:prev = '<li><a href="?page={}">下一页</a></li>'.format(page + 1)else:prev = '<li><a href="?page={}">下一页</a></li>'.format(total_page_count)page_str_list.append(prev)# 尾页page_str_list.append('<li><a href="?page={}">尾页</a></li>'.format(total_page_count))# 跳转search_string = """<li><form style="float: left;margin-left: -1px" method="get"><input name="page"style="position: relative;float: left;display: inline-block;width: 80px;border-radius: 0"type="text" class="form-control" placeholder="页码"><button style="border-radius: 0" class="btn btn-default" type="submit">跳转</button></span></form></li>"""page_str_list.append(search_string)# 拼接htmlpage_string = mark_safe("".join(page_str_list))return render(request, 'case_list.html', {"case_set": case_set, "search_data": search_data, "page_string": page_string})class CaseModelForm(forms.ModelForm):number = forms.CharField(label="用例编号",validators=[RegexValidator(r'^0\d{3}$', '数字必须以0开头的4位数字')],)class Meta:model = models.Case# fields = ["number", "name", "step", "expect", "actual", "priority", "author", "status", "bug_no"]fields = "__all__" # 这个表示所有字段# exclude = ["bug_no"] # 排除字段def __init__(self, *args, **kwargs):super().__init__(*args, **kwargs)# 循环找到所有插件,添加了class: "from-control"for name, field in self.fields.items():field.widget.attrs = {"class": "form-control", "placeholder": field.label}# 钩子函数进行判重验证,这个名字注意是clean_加字段名def clean_number(self):tex_number = self.cleaned_data['number']exists = models.Case.objects.filter(number=tex_number).exists()if exists:raise ValidationError("用例编号已存在")return tex_numberdef case_add(request):"""新增用例(ModelForm方式)"""if request.method == 'GET':form = CaseModelForm()return render(request, 'case_add.html', {"form": form})# POST 请求提交的数据,数据校验form = CaseModelForm(data=request.POST)if form.is_valid():# 如果数据合法,这里判断的是所有字段不能为空,则存储到数据库# models.UserInfo.objects.create(..) 常规存储方式form.save()return redirect('/case/list')# 如果不满足if判断进入到else返回错误信息return render(request, 'case_add.html', {"form": form})class CaseEditModelForm(forms.ModelForm):# 控制字段显示,但是不可编辑number = forms.CharField(disabled=True, label="用例编号")class Meta:model = models.Casefields = ["number", "name", "step", "expect", "actual", "priority", "author", "status", "bug_no"]# fields = "__all__" # 这个表示所有字段# exclude = ["bug_no"] # 排除字段def __init__(self, *args, **kwargs):super().__init__(*args, **kwargs)# 循环找到所有插件,添加了class: "from-control"for name, field in self.fields.items():field.widget.attrs = {"class": "form-control", "placeholder": field.label}# 钩子函数进行判重验证,这个名字注意是clean_加字段名def clean_number(self):# 获取当前编辑那一行的ID,从POST那里获取到了instance# print(self.instance.pk)tex_number = self.cleaned_data['number']exists = models.Case.objects.exclude(id=self.instance.pk).filter(number=tex_number).exists()if exists:raise ValidationError("用例编号已存在")return tex_numberdef case_edit(request, nid):"""编辑用户"""# 根据nid去数据库获取所在行数据row_object = models.Case.objects.filter(id=nid).first()if request.method == 'GET':form = CaseEditModelForm(instance=row_object)return render(request, 'case_edit.html', {"form": form})# POST 请求提交的数据,数据校验form = CaseEditModelForm(data=request.POST, instance=row_object)if form.is_valid():# 如果数据合法,这里判断的是所有字段不能为空,则存储到数据库# models.UserInfo.objects.create(..) 常规存储方式# form.instance.字段名=值 # 如果需要存储用户输入之外的值使用这个form.save()return redirect('/case/list')# 如果不满足if判断进入到else返回错误信息return render(request, 'case_edit.html', {"form": form})def case_delete(request, nid):"""删除用例"""# 根据nid去数据库获取所在行数据进行删除models.Case.objects.filter(id=nid).delete()return redirect('/case/list')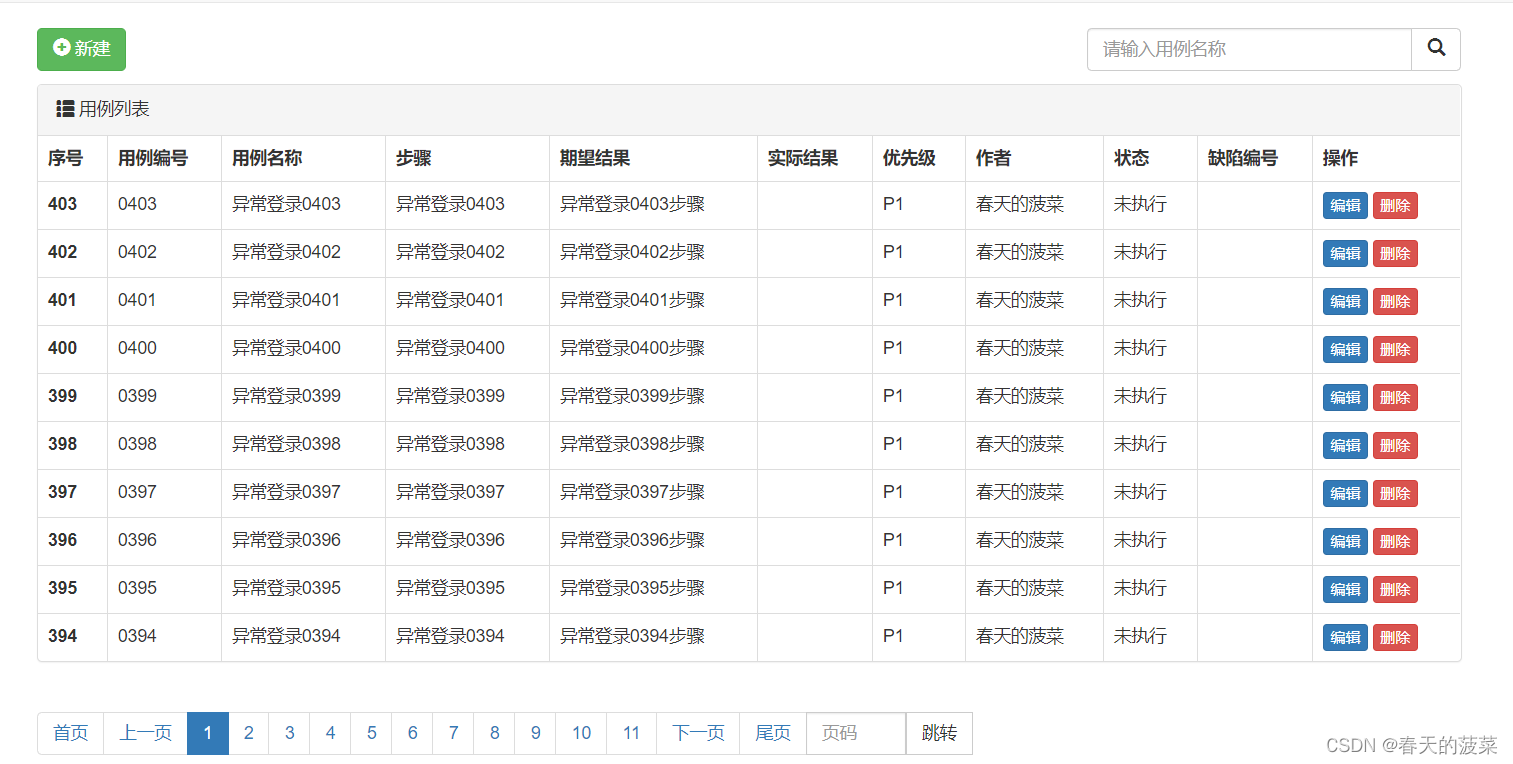
二、分页封装
1、新建类Pagination
在应用下新建文件夹utils,然后在下面创建pagination.py模块
# -*- coding: utf-8 -*-
# @Time : 2023/2/20 15:24
# @Author : caicloud
# @File : pagination.py
# @Software: PyCharm
# @Describe: 自定义分页组件
from django.utils.safestring import mark_safeclass Pagination(object):def __init__(self, request, queryset, page_size=10, page_param='page', plus=5):page = request.GET.get(page_param, "1")if page.isdecimal():page = int(page)else:page = 1self.page = pageself.page_size = page_sizeself.start = (self.page - 1) * self.page_sizeself.end = self.page * self.page_sizeself.page_queryset = queryset[self.start: self.end]# 数据总条数total_count = queryset.count()total_page_count, div = divmod(total_count, page_size)if div:total_page_count += 1self.total_page_count = total_page_countself.plus = plusdef html(self):# 计算出,线上当前页的前5页,后5页,plus=5# 数据未到达11页(数据量不达标时)if self.total_page_count <= 2 * self.plus + 1:start_page = 1end_page = self.total_page_countelse:# 当前页< 5(前面的异常考虑)if self.page <= self.plus:start_page = 1end_page = 2 * self.plus + 1else:# 当前页+plus大于总页面(后面的异常考虑)if self.page + self.plus > self.total_page_count:start_page = self.total_page_count - 2 * self.plusend_page = self.total_page_countelse:# 前五页,后五页start_page = self.page - self.plusend_page = self.page + self.plus# 页码page_str_list = []# 首页page_str_list.append('<li><a href="?page={}">首页</a></li>'.format(1))# 上一页if self.page > 1:prev = '<li><a href="?page={}">上一页</a></li>'.format(self.page - 1)else:prev = '<li><a href="?page={}">上一页</a></li>'.format(1)page_str_list.append(prev)# 页面for i in range(start_page, end_page + 1):if i == self.page:ele = '<li class="active"><a href="?page={}">{}</a></li>'.format(i, i)else:ele = '<li><a href="?page={}">{}</a></li>'.format(i, i)page_str_list.append(ele)# 下一页if self.page < self.total_page_count:prev = '<li><a href="?page={}">下一页</a></li>'.format(self.page + 1)else:prev = '<li><a href="?page={}">下一页</a></li>'.format(self.total_page_count)page_str_list.append(prev)# 尾页page_str_list.append('<li><a href="?page={}">尾页</a></li>'.format(self.total_page_count))# 跳转search_string = """<li><form style="float: left;margin-left: -1px" method="get"><input name="page"style="position: relative;float: left;display: inline-block;width: 80px;border-radius: 0"type="text" class="form-control" placeholder="页码"><button style="border-radius: 0" class="btn btn-default" type="submit">跳转</button></span></form></li>"""page_str_list.append(search_string)# 拼接htmlpage_string = mark_safe("".join(page_str_list))return page_string2、修改views.py的case_list方法
from django.core.exceptions import ValidationError
from django.shortcuts import render, redirect, HttpResponse
from TestManagementSystem import models
from django import forms
from django.core.validators import RegexValidator
from TestManagementSystem.utils.pagination import Pagination
# Create your views here.def depart_list(request):"""部门列表"""# 查询所有部门print("部门列表")depart_set = models.Department.objects.all()return render(request, 'depart_list.html', {"depart_set": depart_set})def depart_add(request):"""新增部门"""# 新增部门# return HttpResponse("成功")if request.method =='GET':return render(request, 'depart_add.html')depart_name = request.POST.get("departname")models.Department.objects.create(name=depart_name)return redirect('/depart/list')def depart_delete(request):"""删除部门"""depart_id = request.GET.get("departid")models.Department.objects.filter(id=depart_id).delete()return redirect('/depart/list')def depart_edit(request, nid):"""编辑部门"""if request.method == 'GET':row_object = models.Department.objects.filter(id=nid).first()# print(row_object.id, row_object.name)return render(request, 'depart_edit.html', {"row_object": row_object})# 获取用户提交的部门名称edit_depart_name = request.POST.get("departname")# 根据编辑页面用户ID去更新部门的名称models.Department.objects.filter(id=nid).update(name=edit_depart_name)return redirect('/depart/list')def user_list(request):"""用户列表"""# 查询所有用户user_set = models.UserInfo.objects.all()"""for obj in user_set:print(obj.id, obj.name, obj.password, obj.account, obj.create_time.strftime("%Y-%m-%d-%H-%M-%S"),obj.get_gender_display(), obj.depart.name)"""return render(request, 'user_list.html', {"user_set": user_set})def user_add(request):"""新增用户(原始方式)"""if request.method == 'GET':# 这个是为了新增页面动态获取性别context = {"gender_choices": models.UserInfo.gender_choices,"depart_list": models.Department.objects.all()}return render(request, 'user_add.html', context)user_name = request.POST.get("username")password = request.POST.get("pwd")age = request.POST.get("age")account = request.POST.get("ac")create_time = request.POST.get("ctime")gender = request.POST.get("gd")depart_id = request.POST.get("dp")models.UserInfo.objects.create(name=user_name, password=password,age=age, account=account,create_time=create_time,gender=gender, depart_id=depart_id)return redirect('/user/list')class UserModelForm(forms.ModelForm):# 限制姓名的长度,至少为3位name = forms.CharField(min_length=3, label='用户名')# password = forms.CharField(label='密码',validators='这里写正则表达式')class Meta:model = models.UserInfofields = ["name", "password", "age", "account", "create_time", "gender", "depart"]'''widgets = {"name": forms.TextInput(attrs={"class": "form-control"}),"password": forms.PasswordInput(attrs={"class": "form-control"}),"age": forms.TextInput(attrs={"class": "form-control"}),"account": forms.TextInput(attrs={"class": "form-control"}) }''' # 下方方法更好def __init__(self, *args, **kwargs):super().__init__(*args, **kwargs)# 循环找到所有插件,添加了class: "from-control"for name, field in self.fields.items():field.widget.attrs = {"class": "form-control", "placeholder": field.label}def user_model_form_add(request):"""新增用户(ModelForm方式)"""if request.method == 'GET':form = UserModelForm()return render(request, 'user_model_form_add.html', {"form": form})# POST 请求提交的数据,数据校验form = UserModelForm(data=request.POST)if form.is_valid():# 如果数据合法,这里判断的是所有字段不能为空,则存储到数据库# models.UserInfo.objects.create(..) 常规存储方式form.save()return redirect('/user/list')# 如果不满足if判断进入到else返回错误信息return render(request, 'user_model_form_add.html', {"form": form})def user_edit(request, nid):"""编辑用户"""# 根据nid去数据库获取所在行数据row_object = models.UserInfo.objects.filter(id=nid).first()if request.method == 'GET':form = UserModelForm(instance=row_object)return render(request, 'user_edit.html', {"form": form})# POST 请求提交的数据,数据校验form = UserModelForm(data=request.POST, instance=row_object)if form.is_valid():# 如果数据合法,这里判断的是所有字段不能为空,则存储到数据库# models.UserInfo.objects.create(..) 常规存储方式# form.instance.字段名=值 # 如果需要存储用户输入之外的值使用这个form.save()return redirect('/user/list')# 如果不满足if判断进入到else返回错误信息return render(request, 'user_edit.html', {"form": form})def user_delete(request, nid):"""删除用户"""# 根据nid去数据库获取所在行数据进行删除models.UserInfo.objects.filter(id=nid).delete()return redirect('/user/list')def case_list(request):"""用例列表"""# 查询所有用例data_dict = {}# 获取浏览器传过来的值search_data = request.GET.get('q', "")if search_data:data_dict["name__contains"] = search_datacase_set = models.Case.objects.filter(**data_dict).order_by('-id')# 实例化封装的分页page_object = Pagination(request, case_set)context = {"search_data": search_data, # 查询"case_set": page_object.page_queryset, # 分完页的数据"page_string": page_object.html() # 页码}return render(request, 'case_list.html', context)class CaseModelForm(forms.ModelForm):number = forms.CharField(label="用例编号",validators=[RegexValidator(r'^0\d{3}$', '数字必须以0开头的4位数字')],)class Meta:model = models.Case# fields = ["number", "name", "step", "expect", "actual", "priority", "author", "status", "bug_no"]fields = "__all__" # 这个表示所有字段# exclude = ["bug_no"] # 排除字段def __init__(self, *args, **kwargs):super().__init__(*args, **kwargs)# 循环找到所有插件,添加了class: "from-control"for name, field in self.fields.items():field.widget.attrs = {"class": "form-control", "placeholder": field.label}# 钩子函数进行判重验证,这个名字注意是clean_加字段名def clean_number(self):tex_number = self.cleaned_data['number']exists = models.Case.objects.filter(number=tex_number).exists()if exists:raise ValidationError("用例编号已存在")return tex_numberdef case_add(request):"""新增用例(ModelForm方式)"""if request.method == 'GET':form = CaseModelForm()return render(request, 'case_add.html', {"form": form})# POST 请求提交的数据,数据校验form = CaseModelForm(data=request.POST)if form.is_valid():# 如果数据合法,这里判断的是所有字段不能为空,则存储到数据库# models.UserInfo.objects.create(..) 常规存储方式form.save()return redirect('/case/list')# 如果不满足if判断进入到else返回错误信息return render(request, 'case_add.html', {"form": form})class CaseEditModelForm(forms.ModelForm):# 控制字段显示,但是不可编辑number = forms.CharField(disabled=True, label="用例编号")class Meta:model = models.Casefields = ["number", "name", "step", "expect", "actual", "priority", "author", "status", "bug_no"]# fields = "__all__" # 这个表示所有字段# exclude = ["bug_no"] # 排除字段def __init__(self, *args, **kwargs):super().__init__(*args, **kwargs)# 循环找到所有插件,添加了class: "from-control"for name, field in self.fields.items():field.widget.attrs = {"class": "form-control", "placeholder": field.label}# 钩子函数进行判重验证,这个名字注意是clean_加字段名def clean_number(self):# 获取当前编辑那一行的ID,从POST那里获取到了instance# print(self.instance.pk)tex_number = self.cleaned_data['number']exists = models.Case.objects.exclude(id=self.instance.pk).filter(number=tex_number).exists()if exists:raise ValidationError("用例编号已存在")return tex_numberdef case_edit(request, nid):"""编辑用户"""# 根据nid去数据库获取所在行数据row_object = models.Case.objects.filter(id=nid).first()if request.method == 'GET':form = CaseEditModelForm(instance=row_object)return render(request, 'case_edit.html', {"form": form})# POST 请求提交的数据,数据校验form = CaseEditModelForm(data=request.POST, instance=row_object)if form.is_valid():# 如果数据合法,这里判断的是所有字段不能为空,则存储到数据库# models.UserInfo.objects.create(..) 常规存储方式# form.instance.字段名=值 # 如果需要存储用户输入之外的值使用这个form.save()return redirect('/case/list')# 如果不满足if判断进入到else返回错误信息return render(request, 'case_edit.html', {"form": form})def case_delete(request, nid):"""删除用例"""# 根据nid去数据库获取所在行数据进行删除models.Case.objects.filter(id=nid).delete()return redirect('/case/list')三、再优化,实现搜索+分页qing情况
知识点,点击分页时保留原来的查询条件
# -*- coding: utf-8 -*-
# @Time : 2023/2/20 15:24
# @Author : caicloud
# @File : pagination.py
# @Software: PyCharm
# @Describe: 自定义分页组件
"""
这个翻页组件的使用说明(视图函数中):
def case_list(request):# 第一步查询数据case_set = models.Case.objects.all()# 第二步实例化封装的分页对象page_object = Pagination(request, case_set)context = {"case_set": page_object.page_queryset, # 分完页的数据"page_string": page_object.html() # 页码}return render(request, 'case_list.html', context)html页面:<ul class="pagination">{{ page_string }}</ul>"""
from django.utils.safestring import mark_safe
import copyclass Pagination(object):def __init__(self, request, queryset, page_size=10, page_param='page', plus=5):""":param request: 请求对象:param queryset: 查询符合条件的数据,根据这个数据进行分页处理:param page_size: 每页显示多少条数据:param page_param:在url中传递的获取分页的参数,例如/case/list/?page=5:param plus:显示当前页的前plus页 或后 plus页"""# 以下是为了解决查询翻页查询条件保留的问题query_dict = copy.deepcopy(request.GET)query_dict._mutable = Trueself.query_dict = query_dict# ########################################self.page_param = page_parampage = request.GET.get(self.page_param, "1")if page.isdecimal():page = int(page)else:page = 1self.page = pageself.page_size = page_sizeself.start = (self.page - 1) * self.page_sizeself.end = self.page * self.page_sizeself.page_queryset = queryset[self.start: self.end]# 数据总条数total_count = queryset.count()total_page_count, div = divmod(total_count, page_size)if div:total_page_count += 1self.total_page_count = total_page_countself.plus = plusdef html(self):# 计算出,线上当前页的前5页,后5页,plus=5# 数据未到达11页(数据量不达标时)if self.total_page_count <= 2 * self.plus + 1:start_page = 1end_page = self.total_page_countelse:# 当前页< 5(前面的异常考虑)if self.page <= self.plus:start_page = 1end_page = 2 * self.plus + 1else:# 当前页+plus大于总页面(后面的异常考虑)if self.page + self.plus > self.total_page_count:start_page = self.total_page_count - 2 * self.plusend_page = self.total_page_countelse:# 前五页,后五页start_page = self.page - self.plusend_page = self.page + self.plus# 页码page_str_list = []self.query_dict.setlist(self.page_param, [1])# 首页page_str_list.append('<li><a href="?{}">首页</a></li>'.format(self.query_dict.urlencode()))# 上一页if self.page > 1:self.query_dict.setlist(self.page_param, [self.page - 1])prev = '<li><a href="?{}">上一页</a></li>'.format(self.query_dict.urlencode())else:self.query_dict.setlist(self.page_param, [1])prev = '<li><a href="?{}">上一页</a></li>'.format(self.query_dict.urlencode())page_str_list.append(prev)# 页面for i in range(start_page, end_page + 1):self.query_dict.setlist(self.page_param, [i])if i == self.page:ele = '<li class="active"><a href="?{}">{}</a></li>'.format(self.query_dict.urlencode(), i)else:ele = '<li><a href="?{}">{}</a></li>'.format(self.query_dict.urlencode(), i)page_str_list.append(ele)# 下一页if self.page < self.total_page_count:self.query_dict.setlist(self.page_param, [self.page + 1])prev = '<li><a href="?{}">下一页</a></li>'.format(self.query_dict.urlencode())else:self.query_dict.setlist(self.page_param, [self.total_page_count])prev = '<li><a href="?{}">下一页</a></li>'.format(self.query_dict.urlencode())page_str_list.append(prev)# 尾页self.query_dict.setlist(self.page_param, [self.total_page_count])page_str_list.append('<li><a href="?{}">尾页</a></li>'.format(self.query_dict.urlencode()))# 跳转search_string = """<li><form style="float: left;margin-left: -1px" method="get"><input name="page"style="position: relative;float: left;display: inline-block;width: 80px;border-radius: 0"type="text" class="form-control" placeholder="页码"><button style="border-radius: 0" class="btn btn-default" type="submit">跳转</button></span></form></li>"""page_str_list.append(search_string)# 拼接htmlpage_string = mark_safe("".join(page_str_list))return page_string四、优化其他查询页面实现分页和查询
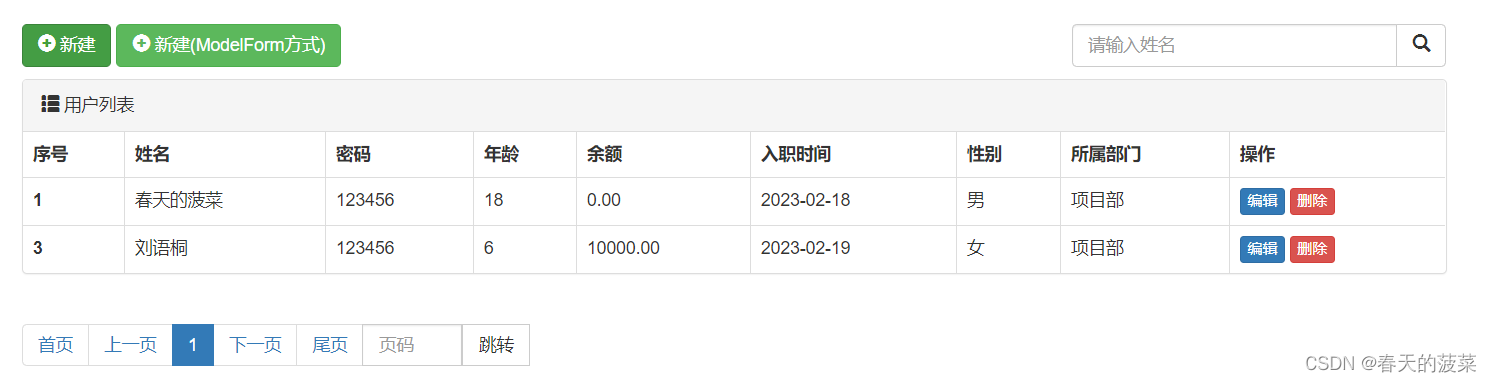
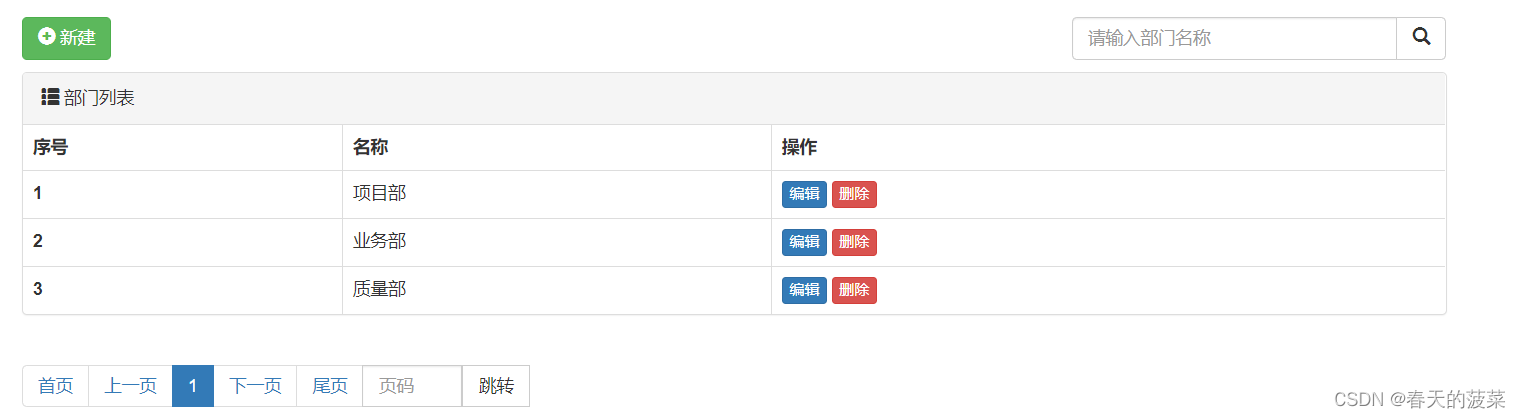
将查询条件、分页在用户管理、部门管理实现
五、优化分页显示总页数和总条数
略