目录
前言
一.键值对
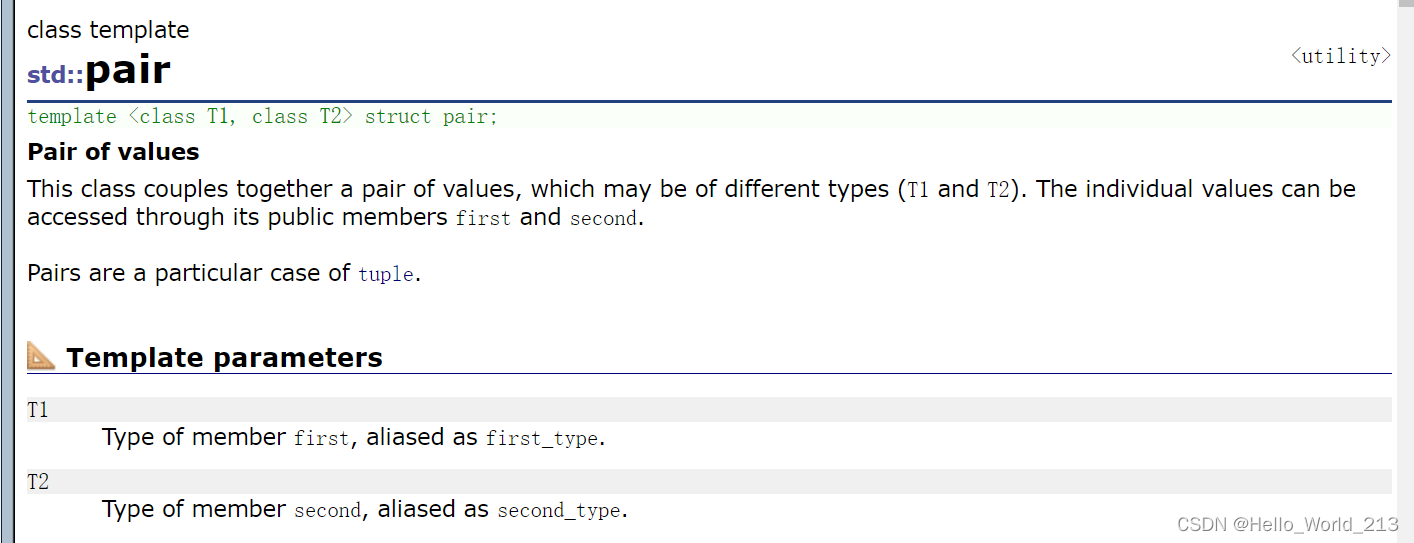
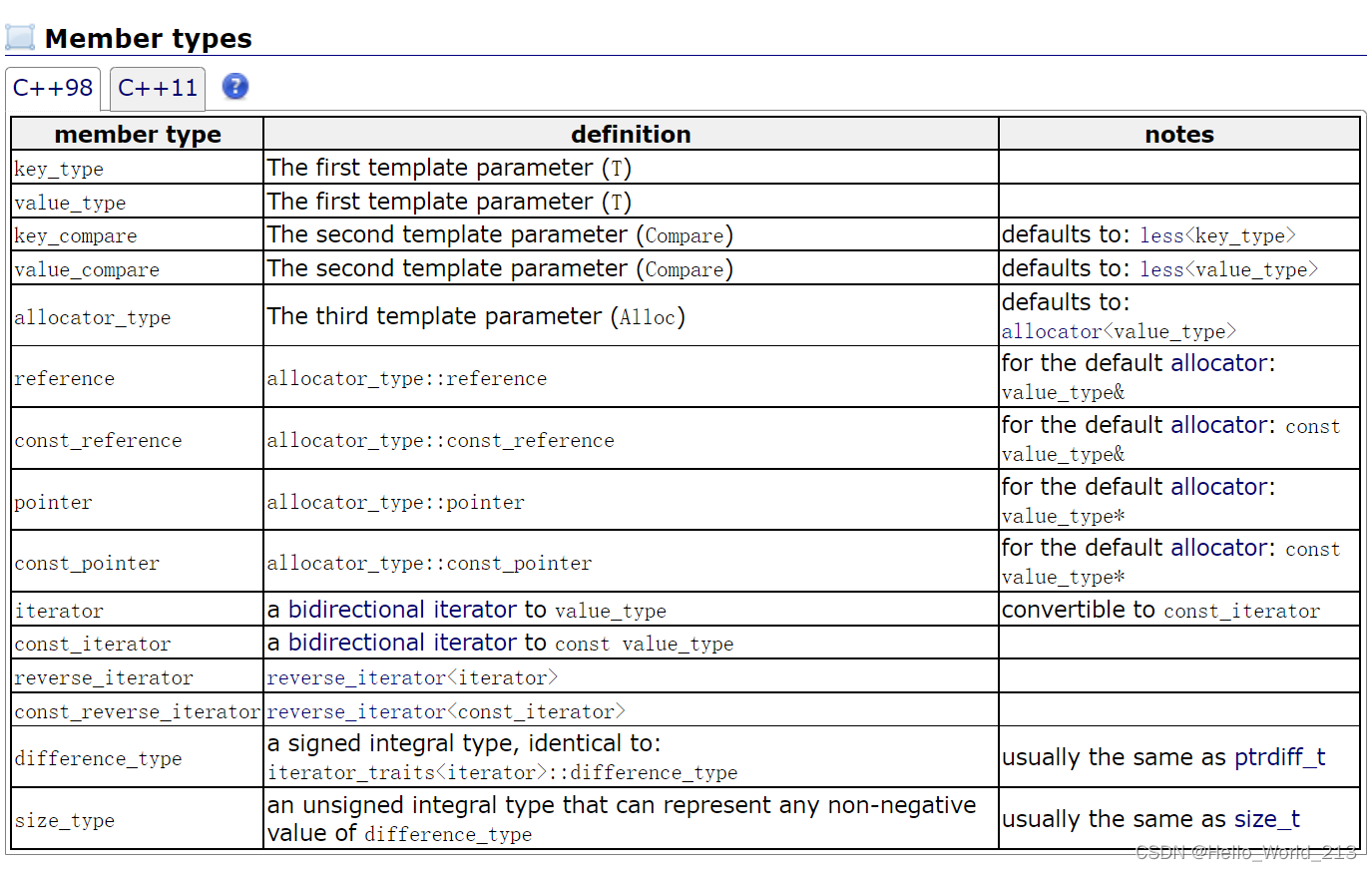
1.在SGI - STL中对键值对的定义:
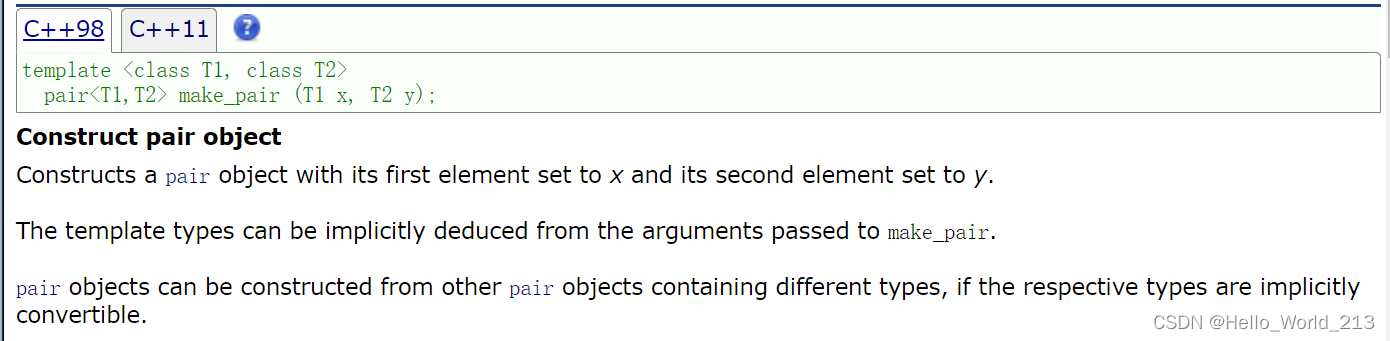
2.make_pair
二.set
1.set的概念与注意事项
2.set的使用(常用接口)
<1>.构造函数
<2>.迭代器与范围for
<3>.插入和查找
<4>.删除erase
<5>.计数count
三.map
1.map的概念与注意事项
2.map的使用(常用接口)
<1>.构造函数
<2>.迭代器与范围for
<3>.查找find
<4>插入insert
<5>.删除erase
<6>.计数count
<7>.operator[]与at(重点)
前言
序列式容器与关联式容器
序列式容器:
string, vector, list, deque是序列式容器, 其底层都为线性结构, 在结构上没有其余特点, 里面存储的值是元素本身
关联式容器:
set, map, multiset, multimap是关联式容器, 其底层的结构有一定的特性与规则, 存储的是<key, value>键值对, 对于数据检索而言效率更高
注: set虽然是只存储key的容器, set也可以看为是<key, value>模型, 其中value就是key, 即为<key, key>, 在实际存储中只需要存储一个key即可
set和map, multiset和multimap
set和map的底层都是用红黑树实现的, 都自带去重
set和map的区别: set存储key, map存储key/value
multiset, multimap和set, map的区别: multiset, multimap不会去重, 其余都相同
由于其他内容过于相似, 只是去不去重的问题, 本篇博客主要介绍set和map, 对于multiset和multimap的介绍更像是基于map和set的扩展
一.键值对
一对用来表示一对对应关系, 经典的<key, value>模型, key代表键值, value表示对应的信息
在stl中, 用pair类将键值对进行了封装, 一个pair类对象就是一个键值对
1.在SGI - STL中对键值对的定义:
template<class T1, class T2>
struct pair
{typedef T1 first_type;typedef T2 second_type;//默认构造pair():first(T1()), second(T2()){}//有参构造pair(const T1& a, const T2& b):first(a), second(b){}//成员变量T1 first; // keyT2 second;// value
};2.make_pair
make_pair是C++提供的一个函数模板, 用来构建pair对象
为了使用者在创建键值对对象时更加轻松, 不用再去写过长的模板参数, 而是可以通过函数模板自动类型推导(这一点在使用map时会深有体会)
//模拟实现
template<class T1, class T2>
pair<T1, T2>& make_pair(const T1& first, const T2& second)
{return pair<T1, T2>(first, second);
}二.set

1.set的概念与注意事项
1.set中只可以存储值, 这个值既是key, 又是value, 不需要构建键值对
2.set支持增删查, 而并不支持修改操作, 因为key是不可以被修改的
3.set的底层使用红黑树实现
4.set的查找效率是OlogN
5.set中不可以存储相同数据, 故可以达到去重的效果
6.set可以自己控制仿函数, 可以按照自己的比较规则来实现, 默认情况下使用less仿函数, 中序遍历是一个升序序列, 相反如果使用greater仿函数, 中序遍历就是一个降序序列
2.set的使用(常用接口)
set中元素不是连续存储的, 每个元素也只是一个单一的值, 所以不支持operator[]
<1>.构造函数

//构造函数
void set_test1()
{//默认构造set<int> s1;//迭代器区间构造vector<int> v = { 7,2,4,3,5,1,9 };set<int> s2(v.begin(), v.end());//拷贝构造set<int> s3(s2);//or: set<int> s3 = s2;//C++11新增构造函数set<int> s = { 7,2,4,3,5,1,9 };
}<2>.迭代器与范围for
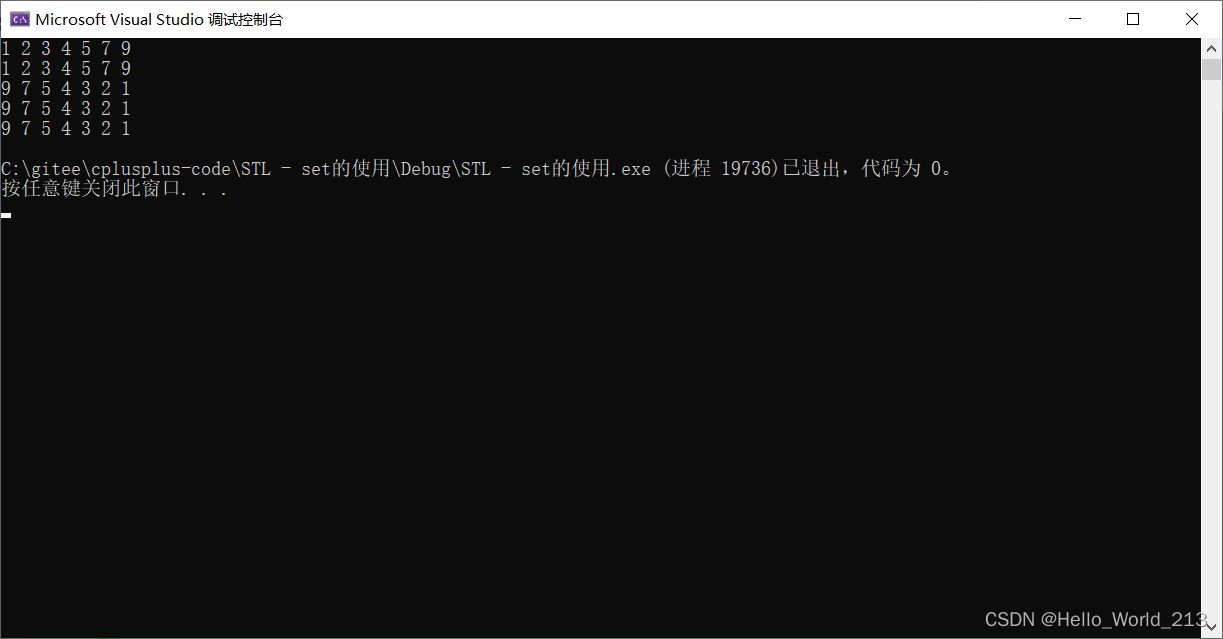
void set_test2()
{//正向遍历://默认使用less仿函数set<int> s = { 7,2,4,3,5,1,9 };//正向迭代器 - 底层是中序遍历set<int>::iterator it = s.begin();while (it != s.end()){cout << *it++ << ' ';}cout << endl;//范围forfor (auto& elem : s){cout << elem << ' ';}cout << endl;//反向遍历://方法一: 反向迭代器 reverse_iterator, rbegin(), rend()set<int>::reverse_iterator rit = s.rbegin();while (rit != s.rend()){cout << *rit++ << ' ';}cout << endl;//方法二://显式使用greater仿函数, 改变值的比较规则, 需要包头文件functionalset<int, greater<int>> s2 = { 7,2,4,3,5,1,9 };set<int>::iterator it2 = s2.begin();while (it2 != s2.end()){cout << *it2++ << ' ';}cout << endl;//范围forfor (auto& elem : s2){cout << elem << ' ';}cout << endl;
}
<3>.插入和查找
void set_test4()
{set<int> s = { 7,2,4 };s.insert(3);s.insert(5);s.insert(1);s.insert(9);for (auto& elem : s){cout << elem << ' ';}cout << endl;set<int>::iterator pos = s.find(5);if (pos != s.end()){cout << *pos << " is find" << endl;}
}在multiset中查找会找到中序遍历中的第一个符合条件的值
multiset<int> ms = { 5,6,8,12,1,5,3,12,9,4,2,5 };
for (auto& elem : ms)
{cout << elem << ' ';
}
cout << endl;
multiset<int>::iterator pos = ms.find(5);
while (pos != ms.end())
{cout << *pos << ' ';pos++;
}
cout << endl;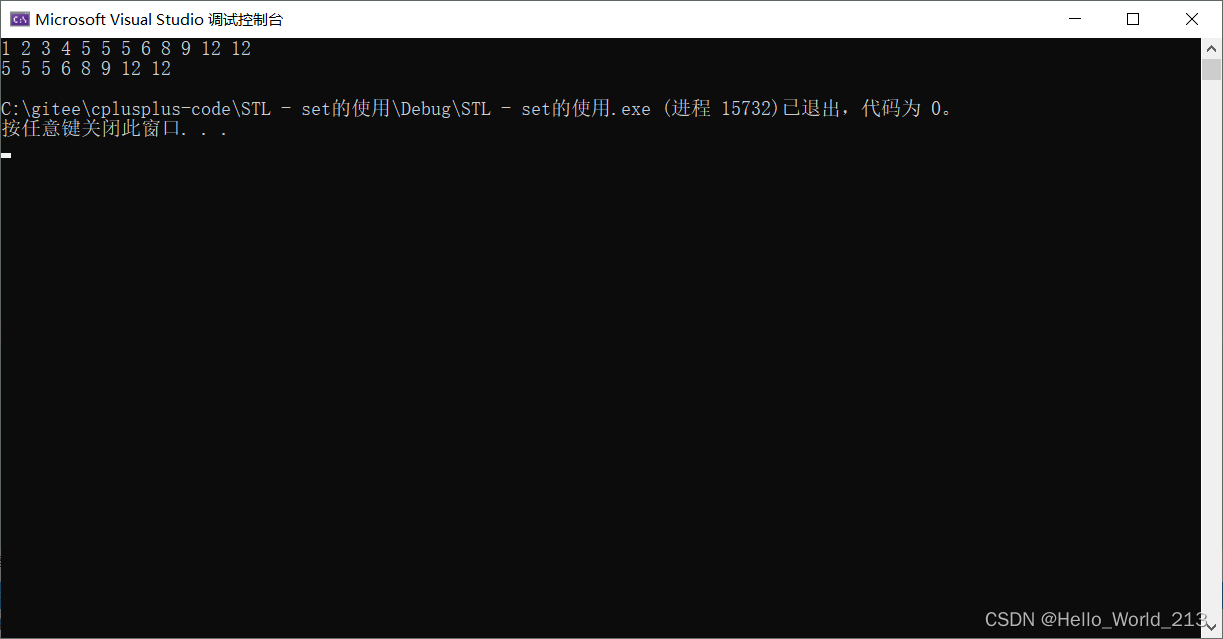
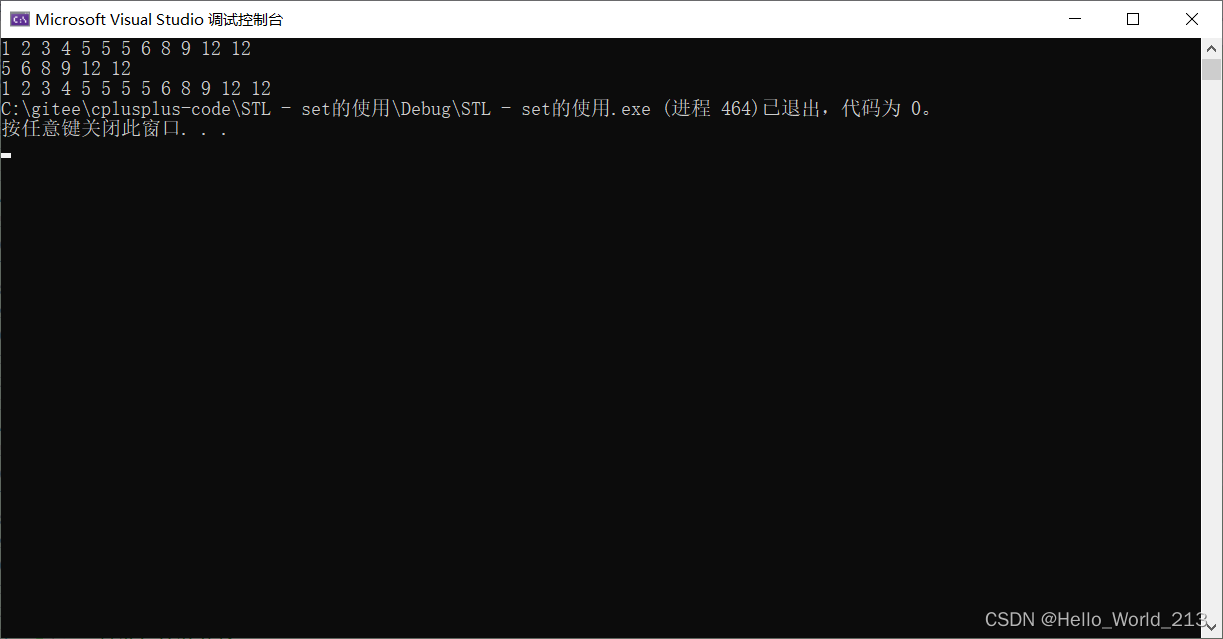
multiset的插入会插入到所有相同值的最右侧, 也就是中序遍历的最后一个
且set的insert与multiset的insert返回值类型不同


multiset<int> ms = { 5,6,8,12,1,5,3,12,9,4,2,5 };
for (auto& elem : ms)
{cout << elem << ' ';
}
cout << endl;
multiset<int>::iterator pos = ms.insert(5);;
while (pos != ms.end())
{cout << *pos << ' ';pos++;
}
cout << endl;
for (auto& elem : ms)
{cout << elem << ' ';
}
<4>.删除erase
void set_test3()
{set<int> s = { 7,2,4,3,5,1,9 };//set容器的erase接口既可以传值删除, 又可以传iterator删除//有什么区别?s.erase(3);for (auto& elem : s){cout << elem << ' ';}cout << endl;set<int>::iterator pos = s.find(4);if (pos != s.end()){s.erase(pos);}for (auto& elem : s){cout << elem << ' ';}cout << endl;
}
set容器的erase接口既可以传值删除, 又可以传iterator删除, 有什么区别?
如果传入的是iterator, 则必须要走一步find操作, 在底层看来erase的传值删除实际是封装了先调用find查找, 再使用find返回的iterator删除这两步
上面是删除存在的数据, 如果此时删除一个不存在的数据且不用if(pos != s.end())进行判断, 传iterator删除是有问题的, 因为如果find找不到对应数据会返回end(), 所以erase传值删除的底层也是封装了find, 如果返回end(), erase底层会有检查, 所以如果是传iterator删除, 需要手动添加if(pos != s.end())这个条件, 否则如果数据不存在就会有问题
在multiset中会存在重复元素, erase会删除所有存在的元素
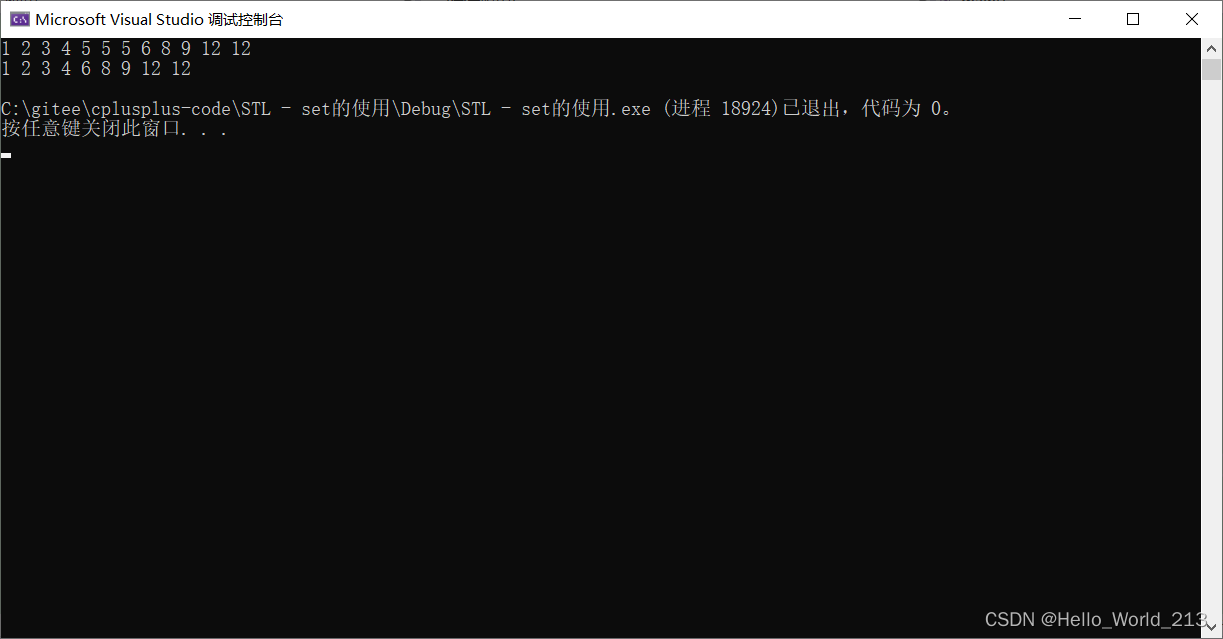
void multiset_test()
{multiset<int> ms = { 5 ,6,8,12,1,5,3,12,9,4,2,5 };for (auto& elem : ms){cout << elem << ' ';}cout << endl;ms.erase(5);for (auto& elem : ms){cout << elem << ' ';}cout << endl;
}
<5>.计数count
set为了与multiset保持一致也支持了这个接口, 因为set中不能存放重复数据所以count只有1或这是0
但在multiset中, count可以统计这个元素存在多少个
multiset<int> ms = { 5,6,8,12,1,5,3,5,9,4,2,5 };
for (auto& elem : ms)
{cout << elem << ' ';
}
cout << endl;
cout << "数字5有: " << ms.count(5) << "个" << endl;三.map

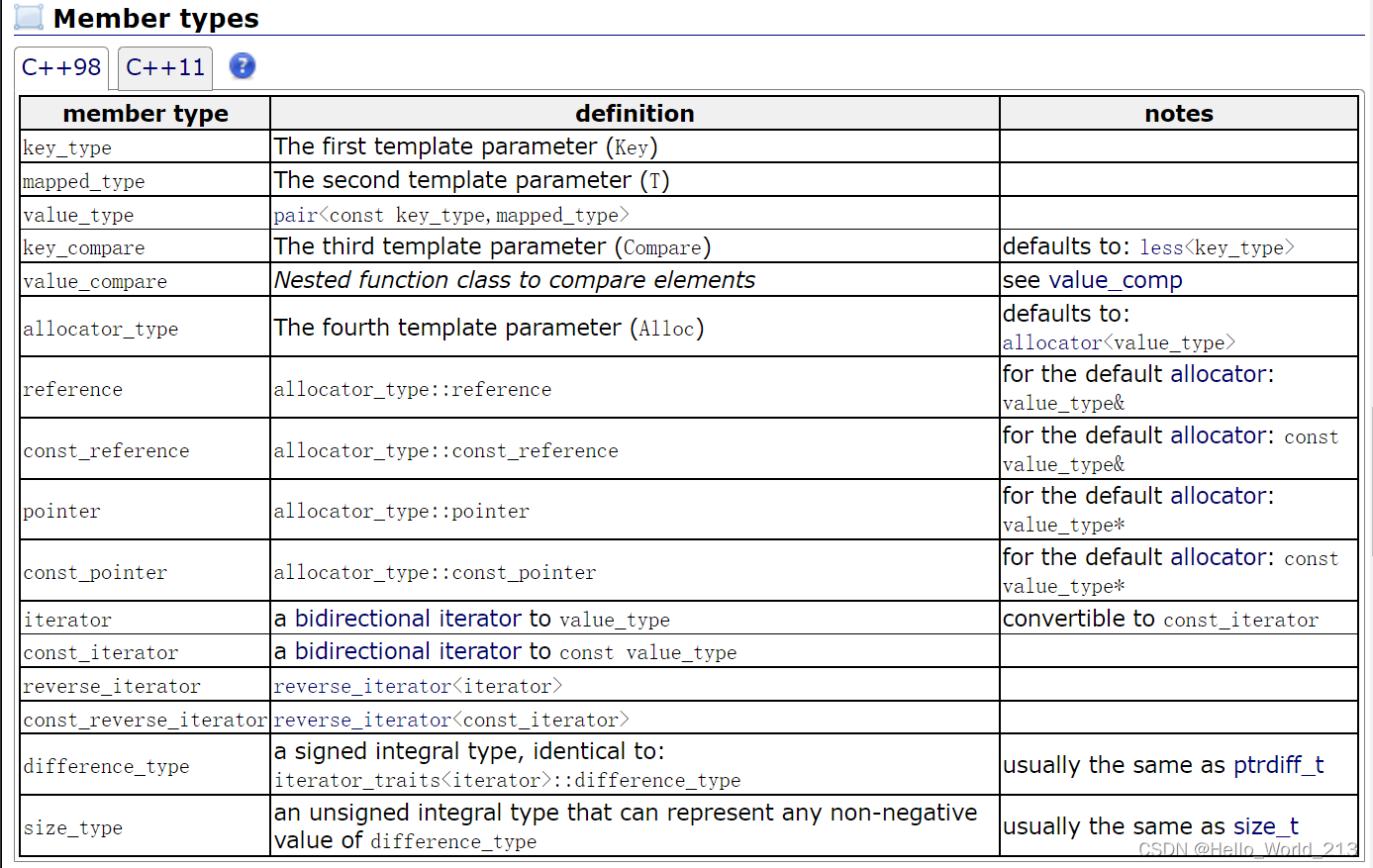
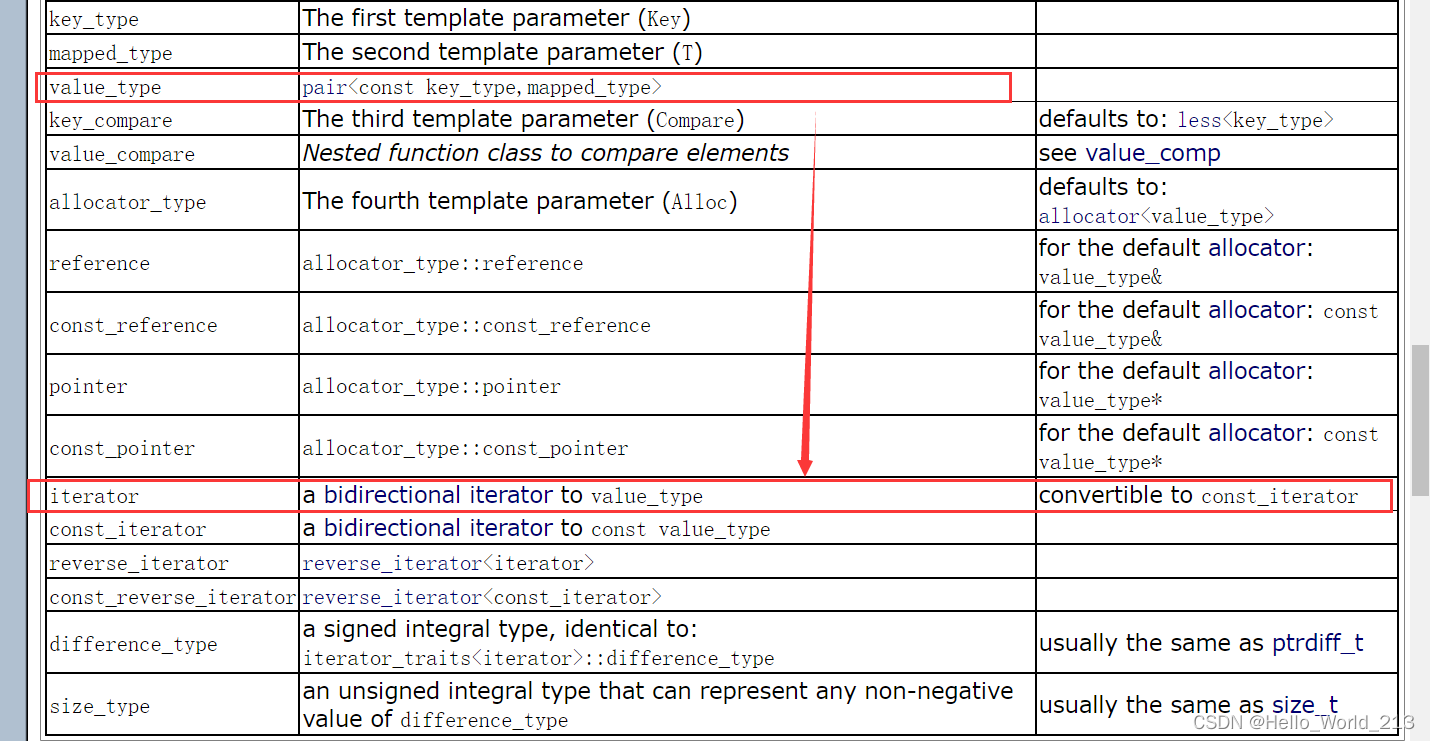
1.map的概念与注意事项
1.map中存储的是键值对 --- pair<key, value>
2.map支持增删查改, 这个改指的是value可以修改, key不可以修改
3.map的底层使用红黑树实现
4.map的查找效率是OlogN
5.map中不可以存储相同数据, 故可以达到去重的效果
6.map可以自己控制仿函数, 可以按照自己的比较规则来实现, 默认情况下使用less仿函数, 中序遍历是一个升序序列, 相反如果使用greater仿函数, 中序遍历就是一个降序序列
7.map中存储的是键值对pair<key, value>, 比较只能用key比
2.map的使用(常用接口)
<1>.构造函数
void map_test1()
{//默认构造map<string, string> m1;//迭代器区间构造pair<string, string> kv1("home", "家");pair<string, string> kv2("happy", "高兴");pair<string, string> kv3("sort", "排序");vector<pair<string, string>> v = { kv1,kv2,kv3 };map<string, string> m2(v.begin(), v.end());//拷贝构造map<string, string> m3(m2);
}<2>.迭代器与范围for
void map_test2()
{pair<string, string> kv1("home", "家");pair<string, string> kv2("happy", "高兴");pair<string, string> kv3("sort", "排序");vector<pair<string, string>> v = { kv1,kv2,kv3 };map<string, string> m(v.begin(), v.end());//迭代器遍历map<string, string>::iterator it = m.begin();while (it != m.end()){cout << it->first << "-" << it->second << ' ';it++;}cout << endl;//范围for遍历for (auto& elem : m){cout << elem.first << "-" << elem.second << ' ';}cout << endl;
}<3>.查找find

void map_test3()
{pair<string, string> kv1("home", "家");pair<string, string> kv2("happy", "高兴");pair<string, string> kv3("sort", "排序");vector<pair<string, string>> v = { kv1,kv2,kv3 };map<string, string> m(v.begin(), v.end());//根据键值查找map<string, string>::iterator pos = m.find("happy");//如果没找到, m.find()返回m.end()if (pos != m.end()){cout << pos->first << '-' << pos->second << endl;}
}<4>插入insert

这里insert的返回值是pair<iterator, bool>这是一个伏笔, 在后面operator[]的实现会体现他的作用
void map_test4()
{map<string, string> m;//第一种插入方式, 先构造对象, 再插入pair<string, string> kv("good", "好");m.insert(kv);//第二种插入方式, 匿名对象m.insert(pair<string, string>("bad", "坏"));//第三种插入方式, 使用make_pair函数模板m.insert(make_pair("beautiful", "漂亮"));for (auto& elem : m){cout << elem.first << "-" << elem.second << ' ';}cout << endl;
}<5>.删除erase

void map_test5()
{pair<string, string> kv1("home", "家");pair<string, string> kv2("happy", "高兴");pair<string, string> kv3("sort", "排序");vector<pair<string, string>> v = { kv1,kv2,kv3 };map<string, string> m(v.begin(), v.end());for (auto& elem : m){cout << elem.first << "-" << elem.second << ' ';}cout << endl;//传迭代器删除map<string, string>::iterator pos = m.find("happy");if (pos != m.end()){m.erase(pos);}for (auto& elem : m){cout << elem.first << "-" << elem.second << ' ';}cout << endl;//传key值删除cout << m.erase("home") << endl;for (auto& elem : m){cout << elem.first << "-" << elem.second << ' ';}cout << endl;
}<6>.计数count
与set一样, count函数也是为multimap准备的, map中的count只是为了与multimap保持一致
<7>.operator[]与at(重点)
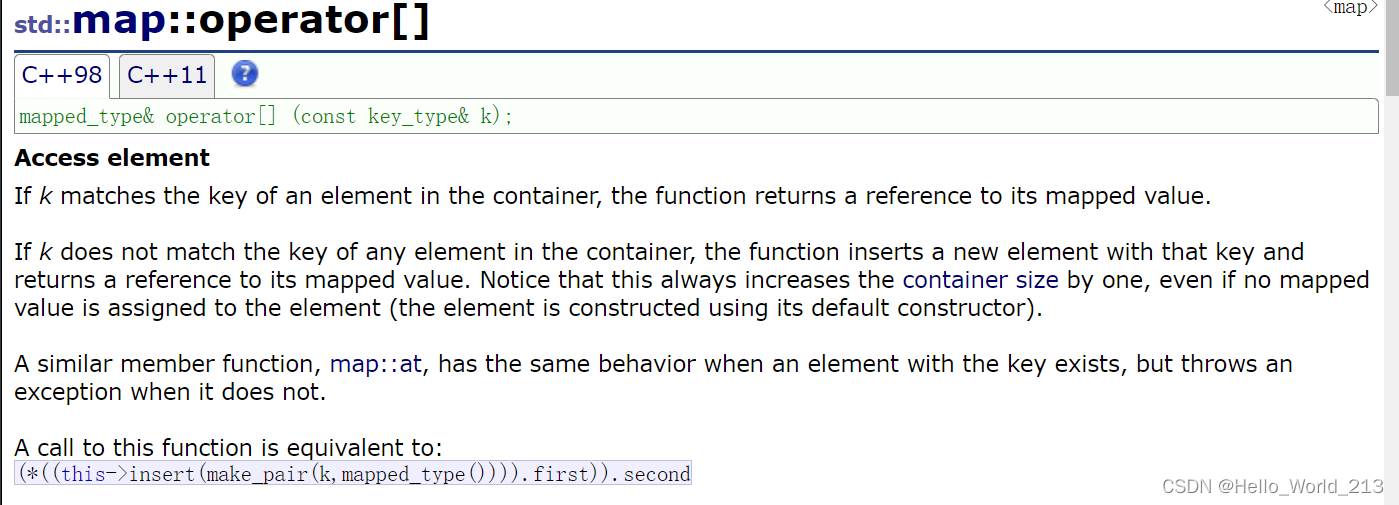
set是没有重载operator[]的, 在map中重载的operator[]是根据key返回对应的value的引用
map中的operator[]存在两种情况
1.传入的key值存在在map中, 则operator[]执行: 查找+修改value
2.传入的key值不存在于map中, 则operator[]执行: 插入+修改value

如果这里insert没有返回这个pair<iterator, bool>, 那么在第2种情况, operator[]就要遍历两次, 第一次遍历, 查找且没有找到; 则需第二次遍历, 执行插入
解释insert的返回值pair<iterator, bool>:
由于map不会插入重复的键值, 插入时如果该键值已经存在, 则直接返回存在的这个键值对的迭代器, 如果插入的键值不存在, 则先插入, 后返回插入的这个键值对的迭代器, 但是需要插入的是<key,value>, 这时value就通过一个value的匿名对象去调用他的默认构造, 来构造出一个键值对
注: 对于内置类型, 例如int而言, int()这难道也要去调用int的默认构造吗? C++为了兼容自定义类型, 规定如int()这样的值就默认为0, float()就是0.0
这样operator[]的实现就可以复用一个insert就可以了
void map_test6()
{string str_array[] = { "老师", "学生", "校长","学生" ,"学生" ,"学生" ,"学生" ,"学生" ,"学生","老师","老师" };//统计老师,学生,校长各自的人数map<string, int> m;for (int i = 0; i < sizeof(str_array) / sizeof(str_array[0]); ++i){m[str_array[i]]++;}for (auto& elem : m){cout << elem.first << "-" << elem.second << ' ';}cout << endl;
}
对operator[]实现的解读

(this->insert(make_pair(key, value))) --- 拿到insert返回值 --- pair<iterator, bool>对象
( (this->insert(make_pair(key, value))) ).first --- 根据拿到的返回值对象, 去访问第一个成员iterator, 这个iterator是新插入或者查找到的key的键值对
(* ( (this->insert(make_pair(key, value))) ).first ).second --- 对拿到的iterator解引用, 在去访问iterator的第二个成员value, 以引用的形式返回

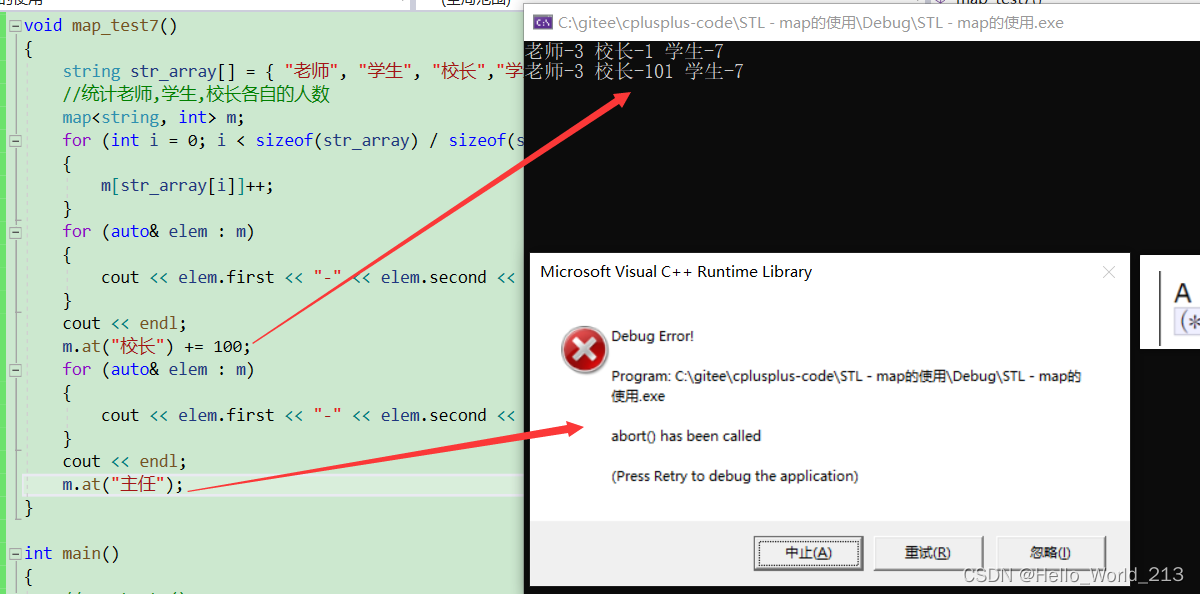
对于at而言, 只有查找+修改value的功能, 如果找不到就会抛出异常
void map_test7()
{string str_array[] = { "老师", "学生", "校长","学生" ,"学生" ,"学生" ,"学生" ,"学生" ,"学生","老师","老师" };//统计老师,学生,校长各自的人数map<string, int> m;for (int i = 0; i < sizeof(str_array) / sizeof(str_array[0]); ++i){m[str_array[i]]++;}for (auto& elem : m){cout << elem.first << "-" << elem.second << ' ';}cout << endl;m.at("校长") += 100;for (auto& elem : m){cout << elem.first << "-" << elem.second << ' ';}cout << endl;m.at("主任");
}