PromQL语法
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.luyixian.cn/news_show_411665.aspx
如若内容造成侵权/违法违规/事实不符,请联系dt猫网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
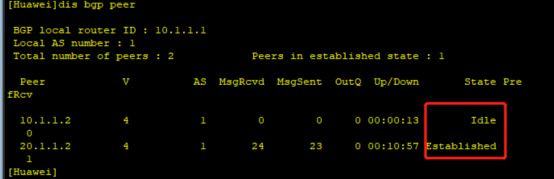
BGP BFD测试案例
一、BFD原理
1.1 BFD技术简介
一种全网统一、检测迅速、监控网络中链路或者IP路由的双向转发连通状况,并未上层应用提供服务的技术。 1.2 BFD会话建立方式和监测机制
●BFD的标识符:
(1)BFD建立会话存在标识符的概念ÿ…
中小企业数字化思考:数字化转型应该走自己的路
随着数字化的发展,以及数字中国概念的形成,和以前国央企宣布数字化转型时的不同,现在越来越多的企业开始寻求数字化转型,促使自身业务能够更好的发展。现在看过去,各行各业都有大量企业进行了数字化转型规划࿰…
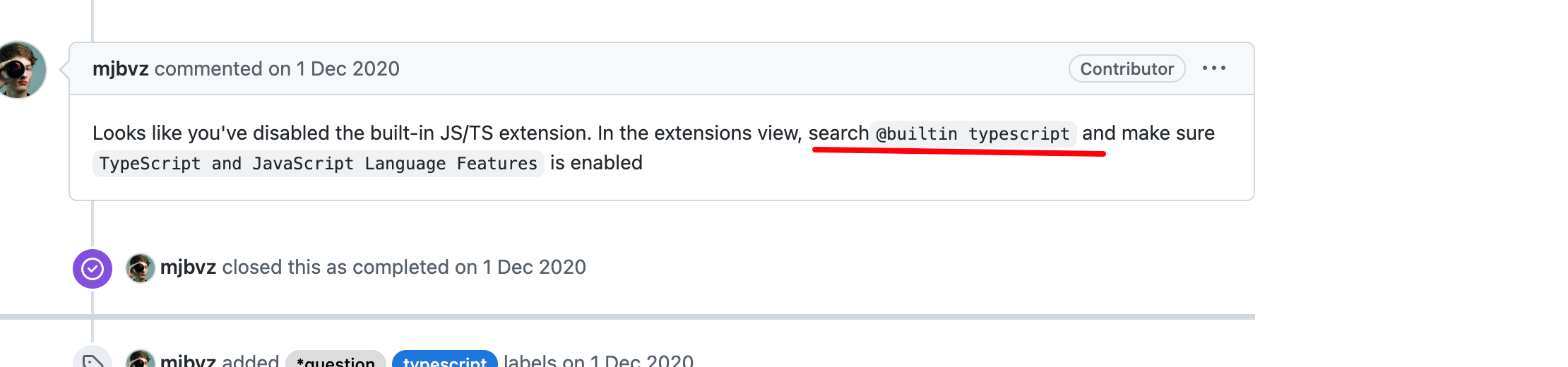
【Mac】VSCode 更新1.73版本后JSTS代码跳转异常
前言
今天有小伙伴MacOS更新了VS Code版本后,说工程内的代码跳转全部异常了,没法正确跳转。搞了两三个小时没搞出来,找到了我,让我帮忙瞧瞧。排查下来发现这问题有点意思,故此记录一下。 问题 排查姿势 1. 提示没有定…
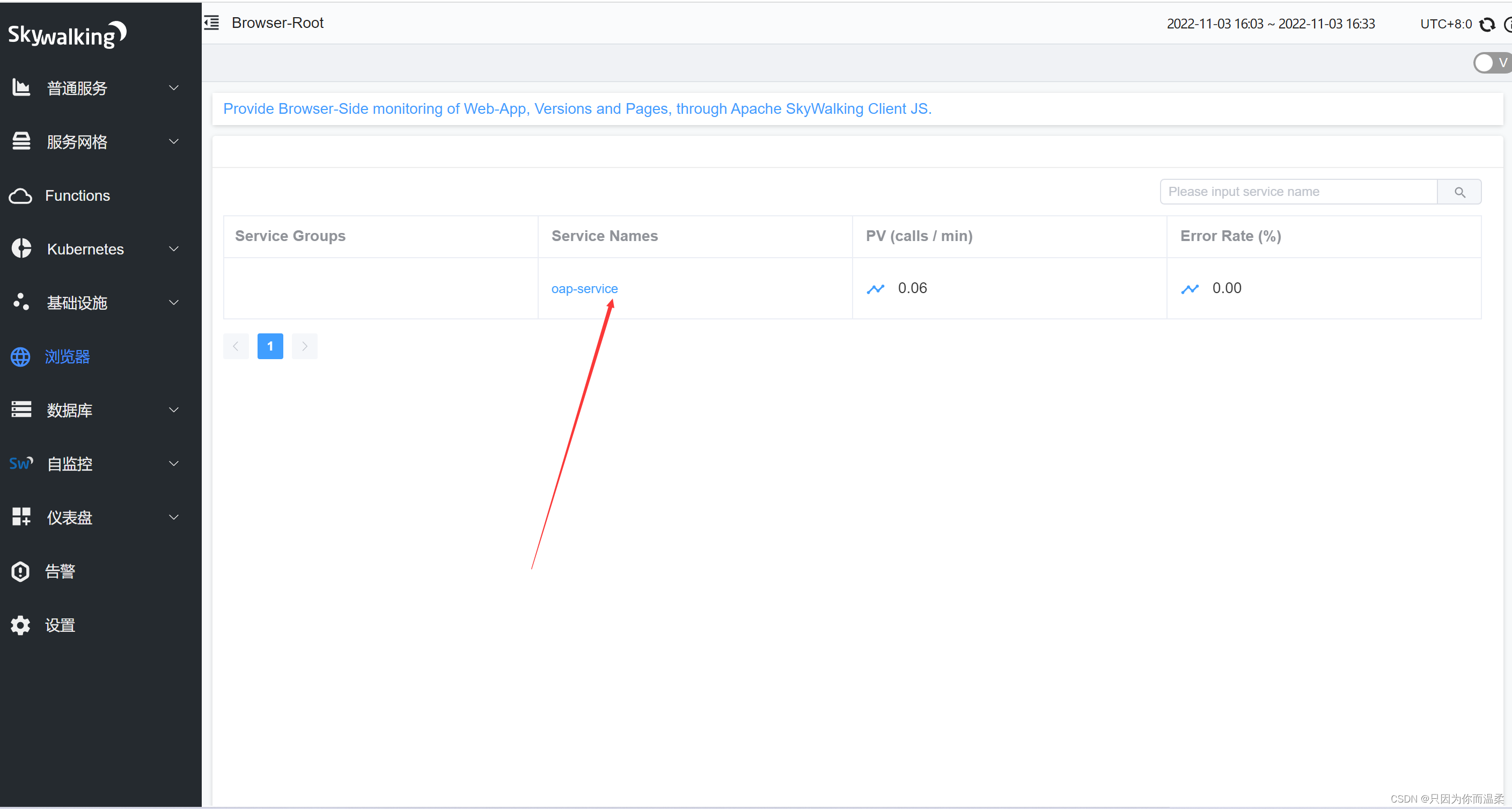
Skywalking9.2.0监控浏览器
Skywalking9.2.0监控浏览器 安装skywalking-client-js npm install skywalking-client-js --save在main.js添加信息 import ClientMonitor from skywalking-client-jsrouter.afterEach(() > {ClientMonitor.setPerformance({service: 服务名,serviceVersion: 版本号,pagePat…
基于模糊小波神经网络的空中目标威胁评估(Matlab代码实现)
目录
💥1 概述
📚2 运行结果
🎉3 参考文献
👨💻4 Matlab代码 💥1 概述
在现代战争中, 随着信息化和智能化的飞速发展, 以及作战环境的日益复杂, 实时而准确地评估目标威胁, 不仅为空战决策提供科学的…

程序人生:技术水平低,就这还敢写自动化项目实战经验丰富?
今年部门要招两个自动化测试,这几个月我面试了几十位候选人。发现一个很奇怪的现象,面试中一问到元素定位、框架api、脚本编写之类的,很多候选人都对答如流。但是一问到实际项目,比如 “如何从0开始搭建自动化体系”、“如果让你来…
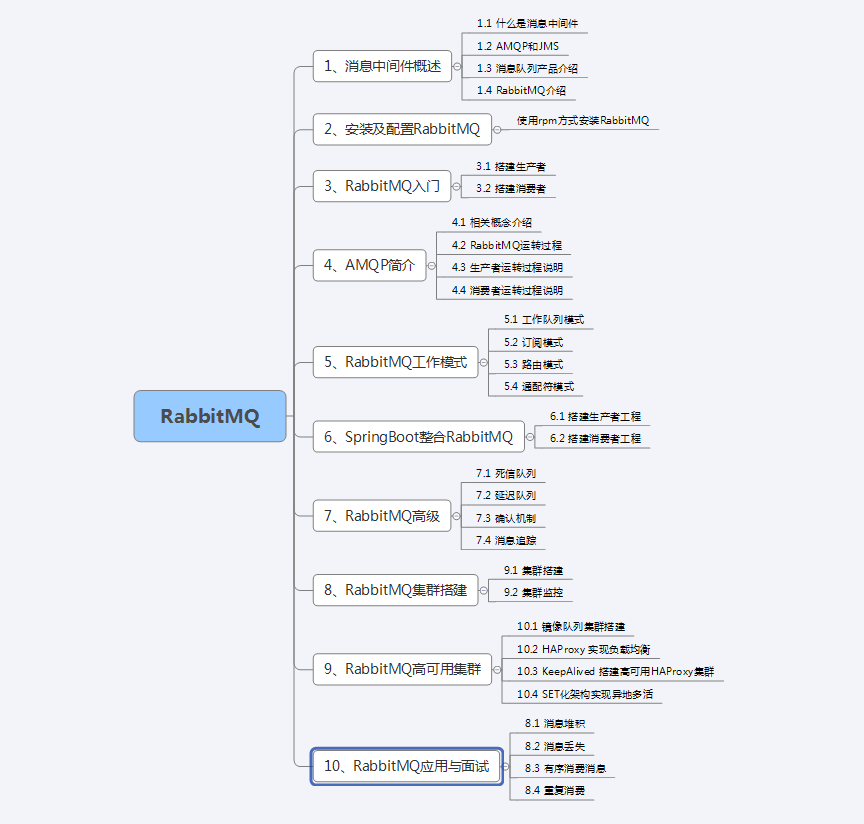
资深大牛纯手写RabbitMQ 核心笔记,还有谁?
RabbitMQ简介
RabbitMQ是消息代理(Message Broker),它支持多种异步消息处理方式,最常见的有:
Work Queue:将消息缓存到一个队列,默认情况下,多个worker按照Round Robin的方式处理队列中的消息。每个消息只…


一本通1064;奥运奖牌计数
#include <iostream>
using namespace std;
int main()
{int n, Jin, Yin, Tong;int JinSum 0, YinSum 0, TongSum 0, sum;cin >> n;for (int i 1; i < n; i) // 循环n次{cin >> Jin >> Yin >> Tong; // 输入一天获得的金银铜牌数JinSum …
IR信息检索前沿梳理
1. 检索预训练
1.1 PROP: Pre-training with Representative Words Prediction for Ad-hoc Retrieval
three types of pre-training tasks have been proposed including:
Inverse Cloze Task (ICT): The query is a sentence randomly drawn from the passage and the docu…
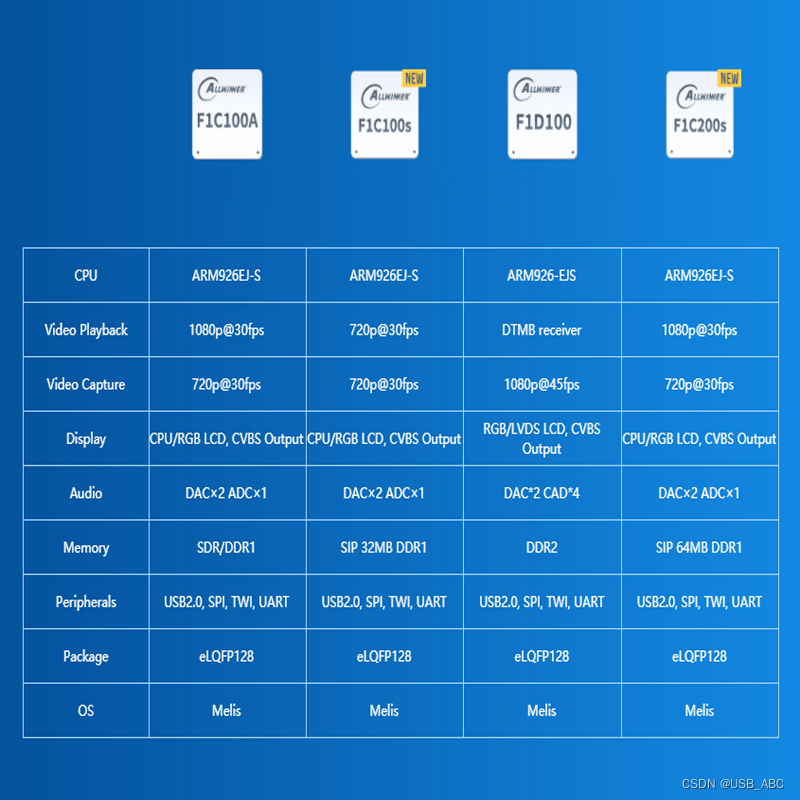
全志F1C芯片参数对比,供查阅
F1C600特性介绍
组合32M DDR1,QFN编解码模式,生产音频核心板(CPUNORWIFI)在WIFI站下播放的功率约0.5W组合I2S、SPDIF、CODEC等多功能接口支持全格式音频解码芯片
F1C600参数介绍
中央处理器
ARM926EJ-S
内存
SIP DDR1 SD2.0…

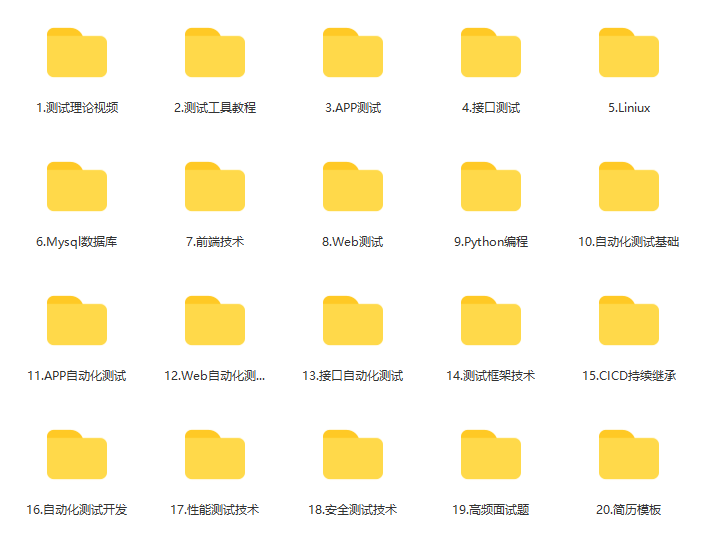
月入18000,0基础转行软件测试,实现薪资翻倍我只用了135天
在没做测试之前,我一直是个没自信的人,因为工作不稳定,收入也不高。
大学毕业做了2年酒店管理,月入4000提成,还经常上夜班,熬人又伤身体,于是不想再做服务行业,就转行做了电销。这之…
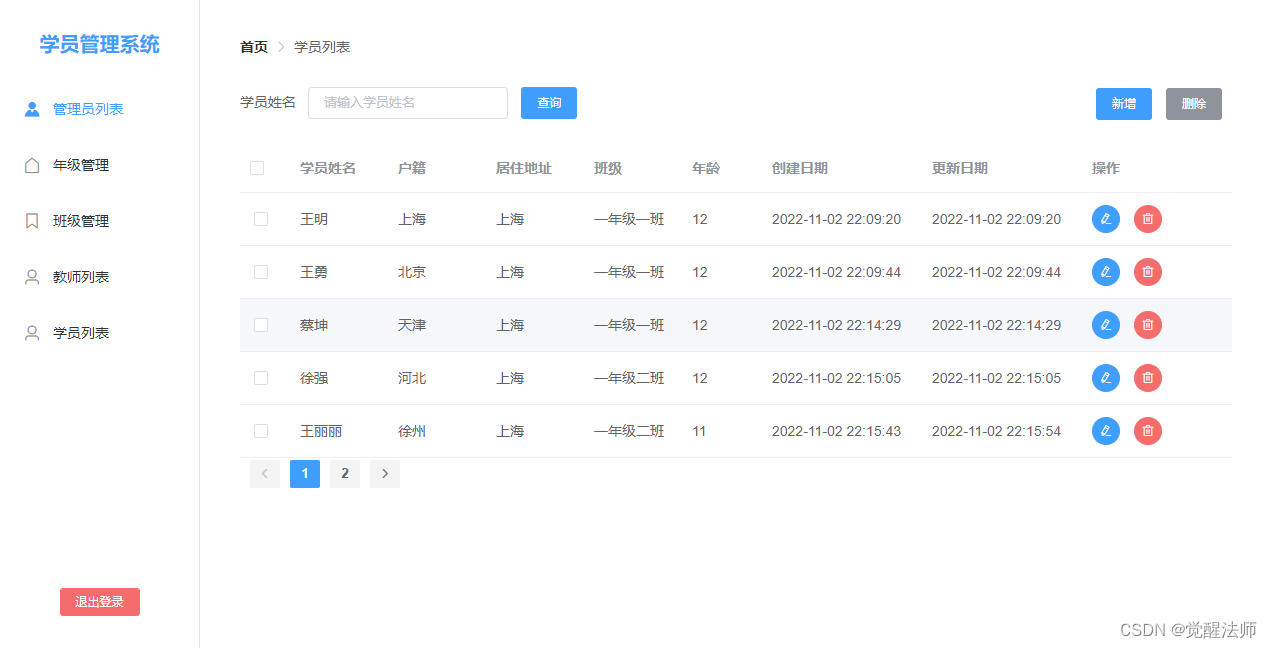
本地数据库IndexedDB - 学员管理系统之列表管理(二)
IndexedDB是浏览器提供的本地数据库,它可以被网页脚本创建和操作。IndexedDB允许存储大量数据,提供查找接口,还能建立索引。这些都是LocalStorage或Cookie不具备的。就数据库类型而言,IndexedDB不属于关系型数据库(不支…
使用VMware16克隆功能快速准备CentOS 7.9操作系统集群
记录:305
场景:使用VMware16克隆功能快速准备CentOS 7.9操作系统集群,主要内容:VMware16克隆功能功能使用、CentOS 7.9操作系统常用指令使用、制作本地yum源、安装JDK、配置集群NTP时间同步等。
版本:
虚拟机工具&a…

数据结构-难点突破(C++/Java详解实现串匹配算法KMP,next数组求法,KMP算法优化nextval数组)
文章目录1. 暴力匹配算法BF2. KMP算法next数组求法Java代码:C代码:KMP算法优化nextval数组1. 暴力匹配算法BF
在了解KMP算法前,就必须介绍串的暴力匹配算法(BF算法)
BF算法,即暴力(Brute Force)算法&…

大赛征集令|首届“万应杯”低代码应用开发大赛报名开启啦!
探索,寻觅低码边界。
创新,做成未曾有人做过的事。 首届“万应杯”低代码应用开发大赛
报名正式启动啦!
万元现金奖杯/证书项目转售收益
丰厚奖励,邀你来战! 大赛时间
低码掘金,就在此时! …
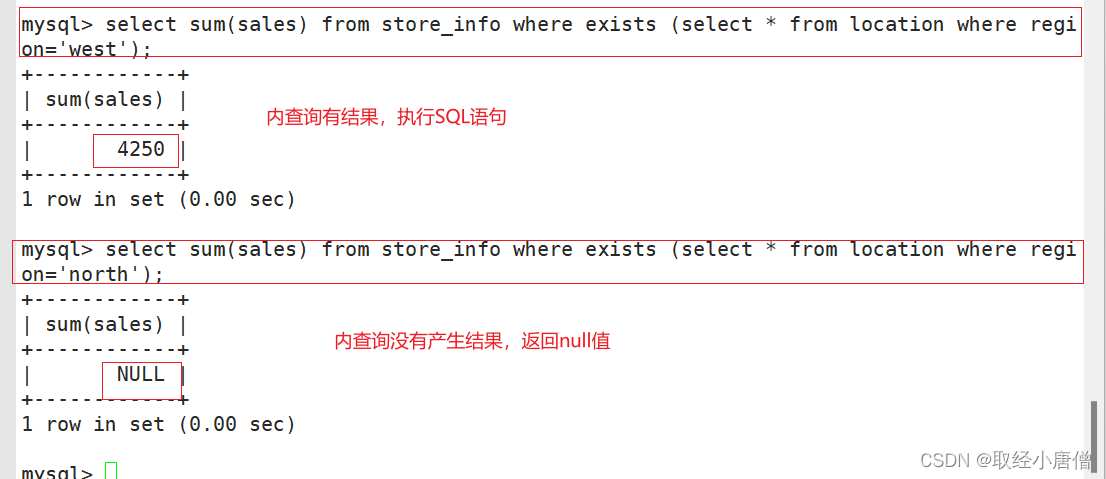
MySQL高级SQL语句(一)
MySQL高级SQL语句(一)MySQL高级SQL语句(一)一、高级SQL语句(进阶查询)1.1 select1.2 distinct1.3 where1.4 and 、or1.5 in1.6 between1.7 通配符1.8 like1.9 order by二、函数2.1 数学函数2.2 聚合函数2.3…
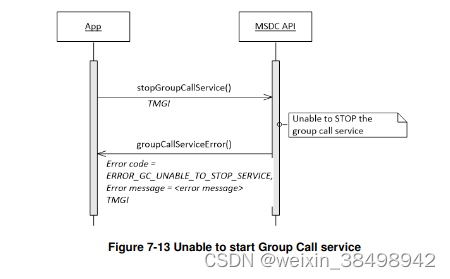
MSDC 4.3 接口规范(26)
MSDC 4.3 接口规范(26)7.4 组呼业务管理7.4.1 服务状态7.4.2 启动组呼业务7.4.2.1 接口函数7.4.2.2 先决条件7.4.2.3 说明7.4.2.4 调用流程7.4.2.4.1 启动组呼业务7.4.2.4.2 无法启动服务7.4.3 停止组呼服务7.4.3.1 接口函数7.4.3.2 先决条件7.4.3.3 说明…

SH-SSS丨《端到端音视频说话人日志网络》论文线上分享
SH Symposium Series on Speech (SH SSS 2022)
SH SSS 是由语音之家打造的AI语音技术相关的前沿论文成果分享平台。
来自AI语音技术领域的优秀论文作者、专家学者,用最精炼的表达来解读最新的高质量论文。 分享的论文成果来自国内外顶级会议收录的优秀文章、前沿…