论文:《Survey of the State of the Art in Natural Language Generation: Core tasks, applications and evaluation》
Journal of Artificial Intelligence Research 61 (2018) 65-170 Submitted 02/17; published 01/18
2018年的论文(live-5477-10398-jair.pdf)
目录
摘要
1.Introduction
1.1 什么是自然语言生成?
1.2 为什么要研究自然语言生成?
1.3 此项调查的目的
2.NLG任务
2.1内容确定
2.2文本结构
2.3句子聚合
2.4 词汇化
2.5引用表达式生成
2.6语言实现
2.6.1手工编写模板
2.6.2手工编写基于语法的系统
2.6.3统计方法
2.7讨论
摘要
本文综述了自然语言生成(nlg)的研究现状,自然语言生成是指从非语言输入中生成文本或语音的任务。
鉴于该领域在过去二十年中所经历的变化,特别是在新的(通常是数据驱动的)方法以及nlg技术的新应用方面,对nlg进行调查是及时的。
因此,本次调查的目的是:
(a)对nlg的核心任务和组织这些任务所采用的架构进行最新的综合研究;
(b)强调最近出现的一些研究主题,这些主题部分是由于NLG与其他人工智能领域之间日益增长的协同效应而产生的;
(c)提请注意国家自然资源资料评价方面的挑战,将这些挑战与国家自然资源资料其他领域面临的类似挑战联系起来,并强调不同的评价方法及其之间的关系。
1.Introduction
其他从现有(通常是人类编写的)文本生成新文本的示例应用程序包括:
- 机器翻译,从一种语言到另一种语言(例如,Hutchins & Somers, 1992;Och & Ney, 2003);
- 融合和总结相关的句子或文本,使它们更简洁(例如,Clarke & Lapata, 2010);
- 简化复杂的文本,例如使它们更容易为低读写能力的读者(例如,Siddharthan, 2014)或儿童(Macdonald & Siddharthan, 2016)所理解;
- 自动拼写、语法和文本更正(例如,Kukich, 1992;戴尔,阿尼西莫夫,和狭威,2012);
- 科学论文的同行评议自动生成(Bartoli, De Lorenzo, Medvet, & Tarlao, 2016);
- 输入句子的转述生成(例如,Bannard & callson - burch, 2005;Kauchak & Barzilay, 2006);
- 自动生成问题,用于教育和其他目的(例如,Brown, Frishkoff, & Eskenazi, 2005;罗斯,怀斯,Piwek, Lintean, Stoyanchev,和摩尔多瓦,2010)。
然而,通常有必要生成不以现有文本为基础的文本。
以2014年3月17日发生在加州比弗利山附近的小地震为例。《洛杉矶时报》是第一家报道地震的报纸,在地震发生后的3分钟内,提供了地震的时间、地点和强度的详细信息。该报告是由一个“机器人记者”自动生成的,它通过填补预定义模板文本中的空白,将传入的自动登记地震数据转换为文本(Oremus, 2014)。
机器人新闻和相关实践,如数据新闻,是通常被称为数据到文本生成的例子。他们在新闻和媒体研究领域有相当大的影响(van Dalen, 2012;Clerwall, 2014;Hermida, 2015)。《洛杉矶时报》使用的这种技术并不新鲜;多年来开发了许多从非语言数据自动生成文本的应用程序,包括但不限于以下系统:
- 足球报道(例如,Theune, Klabbers, de Pijper, Krahmer, & Odijk, 2001;Chen & Mooney, 2008);
- 来自传感器数据的虚拟“报纸”(Molina, Stent, & Parodi, 2011)和时事新闻报道(Lepp, Munezero, Granroth-wilding, & Toivonen, 2017);
- 解决环境问题的文本,如野生动物跟踪(Siddharthan, Green, van Deemter, Mellish, & van der Wal, 2013;Ponnamperuma, Siddharthan, Zeng, Mellish, & van der Wal, 2013),个性化环境信息(Wanner, Bosch, Bouayad-Agha, & Casamayor, 2015),以及通过生成反馈增强公民科学家的参与度(van der Wal, Sharma, Mellish, Robinson, & Siddharthan, 2016);
- 天气和财务报告(Goldberg, Driedger, & Kittredge, 1994;瑞特,斯里帕达,亨特,于,和戴维,2005;特纳、斯里帕达、瑞特和戴维,2008年;Ramos-Soto, Bugarin, Barro, & Taboada, 2015;Plachouras, Smiley, Bretz, Taylor, Leidner, Song, & Schilder, 2016);
- 临床背景下的患者信息摘要(H¨uske-Kraus, 2003;哈里斯,2008;波特、瑞特、盖特、亨特、斯里帕达、弗利尔和赛克斯,2009年;盖特,波特,瑞特,亨特,马哈穆德,蒙瑟尔,斯里帕达,2009;Banaee, Ahmed, & Loutfi, 2013);
- 关于文化文物的互动信息,例如在博物馆的背景下(例如,O’donnell, 2001;Stock, Zancanaro, Busetta, Callaway, Kr¨uger, Kruppa, Kuflik, Not, & Rocchi, 2007);
- 旨在说服(卡列尼尼和摩尔,2006)或激励行为修正(瑞特,罗伯逊,和奥斯曼,2003)的文本。
通常,所有的体育统计数据(谁参加了比赛?,谁得分?诸如此类的数据都被储存起来了,但这些统计数据并没有被体育记者作为一种规则来仔细研究。Narrative Science1等公司通过为这些游戏自动生成体育报道,填补了这一细分市场。Automated Insights2甚至根据用户提供的“梦幻足球”数据生成报告。与此类似,海上石油平台(Sripada, Reiter, & Davy, 2003)或从监测燃气轮机性能的传感器(Yu, Reiter, Hunter, & Mellish, 2006)自动生成天气预报已被证明是数据到文本技术的卓有成效的应用。这类应用程序现在是Arria-NLG.3等公司的主要业务。
将这个想法更进一步,数据到文本生成为针对特定受众定制文本铺平了道路。例如,根据目标读者是医生、护士还是家长,来自新生儿护理中的婴儿的数据可以不同程度地转换为文本,具有不同的技术细节和解释性语言(马哈穆德&瑞特,2011)。你也可以很容易地想象,为各自球队的球迷生成不同的体育报道;从输球队的角度来看,一支球队的获胜进球很可能被认为是一个幸运的进球,无论其“客观”品质如何。人类记者不会梦想着为一场体育比赛写独立的报道(如果只是因为时间不够的话),但对于计算机来说,这不是问题,而且这可能会受到读者的欣赏,因为他们会收到更适合自己的报道。
1.1 什么是自然语言生成?
文本到文本的生成和数据到文本的生成都是自然语言生成(nlg)的实例。在迄今为止引用最多的nlg方法调查中(Reiter & Dale, 1999,2000), nlg被描述为“人工智能和计算语言学的子领域,它与计算机系统的构建有关,可以从信息的一些潜在的非语言表示中生成英语或其他人类语言的可理解文本”(Reiter & Dale, 1997, p.1)。显然,这个定义更适合于数据到文本的生成,而不是文本到文本的生成,而且Reiter和Dale(2000)确实只关注前者,很有帮助且清楚地描述了当时在该领域占主导地位的基于规则的方法。
有人指出,精确定义nlg是相当困难的(例如,Evans, Piwek, & Cahill, 2002):每个人似乎都同意nlg系统的输出应该是什么(文本),但确切的输入可能有很大的不同(McDonald, 1993)。例子包括平面语义表示、数值数据和结构化知识库。最近,从图像或视频等视觉输入生成已经成为一个重要的挑战(例如,Mitchell, Dodge, Goyal, Yamaguchi, Stratos, Han, Mensch, Berg, Han, Berg, & Daume III, 2012;库尔卡尼,Premraj, Ordonez, Dhar, Li, Choi, Berg, & Berg, 2013;Thomason, Venugopalan, Guadarrama, Saenko, & Mooney, 2014,以及其他许多人)。
更复杂的是,不同方法之间的界限本身就很模糊。例如,上面描述的文本摘要是文本到文本的应用程序。然而,许多文本到文本生成的方法(特别是抽象摘要系统,它不从输入文档中批量提取内容)使用了数据到文本中也使用的技术,如从评论中提取意见并以全新的句子表达(例如,Labbé & Portet, 2012)。相反,数据到文本生成系统可以依赖文本到文本生成技术来学习如何以不同或创造性的方式表达数据片段(McIntyre & Lapata, 2009;Gatt et al, 2009;Kondadadi, Howald, & Schilder, 2013)。
考虑到nlg的其他应用程序,也同样强调了边界可能变得多么模糊。例如,对话系统中口语话语的生成(例如,Walker, Stent, Mairesse, & Prasad, 2007;Rieser & Lemon, 2009;Dethlefs, 2014)是nlg的另一个应用,但通常它与对话管理密切相关,因此管理和实现策略有时是同时学习的(例如,Rieser & Lemon, 2011)。
本调查所采取的立场是,最终区分数据到文本生成的是其输入。尽管差异很大,但我们将考虑的大多数系统和方法所面临的主要挑战正是这样的输入不是——或不完全是——语言的事实。在下文中,除非上下文另有说明,术语“自然语言生成”和“nlg”将用于指从非语言数据生成文本的系统。
1.2 为什么要研究自然语言生成?
可以说,Reiter和Dale(2000)仍然是可用的最完整的nlg调查。然而,nlg领域在过去15年发生了巨大的变化,出现了为特定受众生成定制报告的成功应用程序,以及文本到文本和视觉到文本生成应用程序的出现,这些应用程序也倾向于更多地依赖统计方法,而不是传统的数据到文本。这些都没有被Reiter和Dale(2000)所涵盖。同样值得注意的是,没有讨论超越标准的“事实”文本生成的应用程序,如那些解释个性和影响的文本,或创造性文本,如隐喻和叙事。最后,Reiter和Dale(2000)的一个显著遗漏是缺乏对评估方法的讨论。事实上,对自然资源小组产出的评价直到最近才开始受到系统的注意,部分原因是在自然资源小组内部进行了一些共同的任务。
自从Reiter和Dale(2000)出版了他们的书,各种其他的nlg概述文本也出现了。贝特曼和佐克(2005)涵盖了nlg的认知、社会和计算维度。McDonald(2010)将语言学习lg概括为“将思想转化为语言的过程”(第121页)。Wanner(2010)聚焦于报告的自动生成,而Di Eugenio和Green(2010)着眼于具体的应用,特别是在教育和医疗保健领域。也发表了各种专门的文章集,包括Krahmer和Theune(2010)的文章,其目标是数据驱动的方法;Bangalore和Stent(2014)的研究重点是交互系统。
该网站提供了各种未发表的技术报告,如Theune(2003)对对话系统的调查;Piwek(2003)和Belz(2003)关于情感nlg的报告;Gkatzia(2016)关于内容选择的调查。这些资源虽然有用,但没有讨论最近的发展或提供全面的审查。这表明进行最新的调查是非常及时的。
1.3 此项调查的目的
本文的目的是对自2000年以来nlg的发展进行一个全面的概述,以便为nlg研究人员提供一个综合和相关研究的指针,并向不太熟悉nlg的研究人员介绍该领域。尽管nlg从早期就已经是ai和nlp的一部分(例如,Winograd, 1972;Appelt, 1985),作为一个领域,它可能还没有被这些更广泛的社区完全接受,直到最近才开始充分利用数据驱动、机器学习和深度学习方法的最新进展。
继Reiter和Dale(2000)之后,我们的主要关注点(特别是在调查的第一部分)将放在数据到文本的生成上。在任何情况下,要对各种文本到文本生成应用的最新发展进行全面公正的调查已经超出了单一调查的范围,其中许多已经在其他调查中覆盖,包括Mani(2001)和Nenkova和McKeown(2011)的调查总结;Androutsopoulos和Malakasiotis(2010)关于释义;以及Piwek和Boyer(2012)关于自动生成问题的研究。
然而,我们将在不同的地方讨论数据到文本和文本到文本生成之间的联系,这既是因为——如上所述——边界是模糊的,但也许更重要的是,因为文本到文本系统长期以来都是在数据驱动的框架中实现的,而这种框架在数据到文本生成中越来越流行,还产生了一些混合系统,它们结合了规则总线和统计技术。
我们的回顾将从Reiter和Dale(2000)介绍的核心nlg任务的更新概述开始,然后讨论架构和方法,其中我们将特别注意那些在Reiter和Dale(2000)调查中没有涉及的内容。这两个部分构成了调查的“基础”部分。除此之外,我们还强调了一些新的发展,包括输入数据是可视化的方法;研究旨在产生更多样、更吸引人、更有创意、更有趣的文本,使NLG超越它有时被指责产生的事实性、重复性文本。我们相信,这些应用程序不仅本身有趣,而且还可能为更多“实用”驱动的文本生成应用程序提供信息。例如,通过包含来自叙事生成的见解,我们可能能够生成更吸引人的报告,通过包含来自隐喻生成的见解,我们可能能够在这些报告中以更原始的方式表达信息。最后,我们将讨论自然语言生成应用程序评估方面的最新进展。
简而言之,本次调查的目标是:
- 对nlg的核心任务以及该领域采用的架构的研究进行最新的综合,特别是考虑到利用数据驱动技术的最新发展(第2节和第3节);
- 强调一些相对近期的研究问题,这些问题部分是由于nlg与其他人工智能领域(如计算机视觉、文体学和计算创造力)之间日益增长的协同效应而产生的(第4、5和6节);
- 关注nlp评估中面临的挑战,将其与nlp其他领域面临的类似挑战联系起来,并强调不同的评估方法及其之间的关系(第7节)。
2.NLG任务
传统上,将输入数据转换为输出文本的nlg问题是通过将其分解为许多子问题来解决的。以下六种经常出现在许多nlg系统中(Reiter & Dale, 1997,2000);它们的作用见图1:
- 内容确定:决定在构建的文本中包含哪些信息;
- 文本结构:确定信息在文本中以何种顺序呈现;
- 句子聚合:决定在单个句子中呈现哪些信息;
- 词汇化:找到正确的单词和短语来表达信息,
- 引用表达式生成:选择单词和短语来识别领域对象
- 语言实现:将所有的单词和短语组合成结构良好的句子。
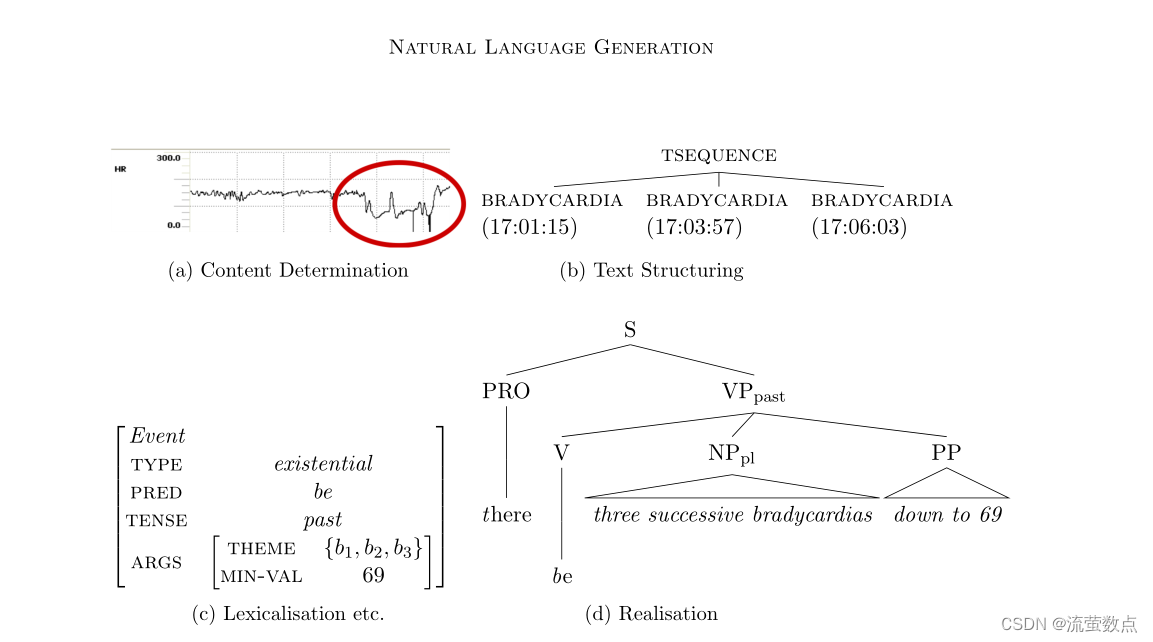
nlg的任务,用新生儿重症监护领域的一个简化例子来说明。首先,系统必须确定数据中的重要事件是什么(a,内容确定),在这种情况下,发生的低心率(心动过缓)。然后,它必须决定以何种顺序向读者呈现数据(b,文本结构),以及如何在单个句子计划中表达这些数据(c,聚合,词汇化,引用)。
最后,生成生成的句子(d,语言实现)。
这些任务可以从“早期”决策过程(向读者传达哪些信息?)到“晚期”决策过程(在特定的句子中使用哪些单词,以及如何将它们按正确的顺序排列?)这里,我们指的是“早期”和“晚期”任务,是通过区分更倾向于数据的选择(如说什么)和越来越具有语言性质的选择(如词汇化或实现)。
这种特征反映了nlg在战略和战术之间长期存在的区别(这种区别至少可以追溯到汤普森,1977年)。这种区别还表明了任务执行的时间顺序,至少在具有模块化、流水线架构的系统中是这样的(在3.1节中讨论过):例如,系统首先需要决定在文本中表达哪些输入数据,然后才能对信息进行排序以表示。然而,在下面讨论的数据驱动体系结构(第3节)中,这样的模块排序现在越来越受到质疑。
在本节中,我们将简要描述这六个任务,用例子说明它们,并强调每种情况的最新发展。正如我们将看到的,虽然“早期”任务对nlg系统的发展至关重要,它们通常与特定的应用程序密切相关。相比之下,“晚期”任务通常独立于应用程序进行调查,因此产生了可以在应用程序之间共享的方法。
2.1内容确定
作为生成过程的第一步,nlg系统需要决定哪些信息应该包括在正在构建的文本中,哪些不应该包括。通常情况下,数据中包含的信息比我们想要通过文本传达的要多,或者数据比我们想要用文本表达的要详细。这一点在图1a中很清楚,输入信号——病人的心率——只包含一些感兴趣的模式。选择也可能取决于目标受众(例如,它是由专家还是新手组成的)和整体的交际意图(例如,文本是通知读者还是说服他做某事)。
内容确定涉及选择。在一份足球报告中,我们可能不想详细描述每一次传球和犯规,即使数据可能包含这些信息。在新生儿护理的情况下,可以通过测量心率、血压和其他生理参数的传感器连续收集数据。因此,需要过滤数据并将其抽象为一组前言语信息,即信息的语义表示,这些信息通常用一种形式表示语言表示,如逻辑语言或数据库语言、属性-值矩阵或图结构。它们可以表达在领域实体之间的关系,例如,表达球员X在时间T为球队Y进了第一个球。
尽管在大多数nlg系统中存在内容确定(参见Mellish, Scott, Cahill, Paiva, Evans, & Reape, 2006),但方法通常与应用领域密切相关。一个显著的例外是Guhe(2007)的工作,他基于对说话人对动态事件的描述的研究,提供了一个认知上似是而非的内容确定的增量解释。这项工作属于一个研究链,认为nlg首先是一个非常适合理解人类语言产生的方法论。
近年来,研究人员已经开始探索数据驱动的内容确定技术(例如,Barzilay & Lee, 2004;Bouayad-Agha, Casamayor, Wanner, & Mellish, 2013;库特拉克、梅利什和范·迪默特,2013年;Venigalla & Di Eugenio, 2013)。例如,Barzilay和Lee(2004)使用隐马尔可夫模型来模拟特定话语领域(例如,地震报道)中的话题转移,其中隐状态代表“话题”,建模为根据相似度聚集在一起的句子。Duboue和McKeown(2003)在传记领域也使用了聚类方法,使用与知识库配对的文本,从知识库中对语义数据进行聚类,并根据其在文本中的出现情况进行评分。与此类似,Barzilay和Lapata(2005)使用了美国橄榄球记录和相应文本的数据库。他们的目的不仅是识别应该被提及的信息,还包括它们之间的依赖关系,因为提及某一事件(例如,四分卫的得分)可能会保证提及另一事件(例如,第二个四分卫的得分事件)。Barzilay和Lapata提出的解决方案是计算事件的个人偏好得分和链接偏好得分。
最近,各种研究人员已经解决了如何自动学习数据和文本之间的对齐的问题,也在基础语言习得的更广泛的背景下,即通过观察世界上物体和事件之间的对应关系以及我们在语言中引用它们的方式来建模我们如何学习语言(Roy, 2002;Yu & Ballard, 2004;Yu & Siskind, 2013)。例如,Liang、Jordan和Klein(2009)将Barzilay和Lapata(2005)的工作扩展到多个领域(足球和天气),依靠弱监督技术;与此类似,Koncel-Kedziorski、Hajishirzi和Farhadi(2014)提出了一种弱监督多级方法,以处理数据中的足球事件和相关足球报道中的句子之间没有一一对应的事实。我们将在下面(第3.3节)对数据驱动方法的更广泛的讨论中回到这些方法。
2.2文本结构
在确定要传递什么信息之后,nlg系统需要决定它们向读者呈现的顺序。例如,图1b显示了三个相同类型的事件(所有心动过缓事件,即心率短暂下降),从输入信号中选择(在抽象后),并作为时间序列排序。
这个阶段通常被称为文本(或语篇或文档)结构。以足球领域为例,在描述目标之前(通常是按时间顺序),似乎应该先从一般信息开始(游戏邦注:如比赛在何时何地进行,参加比赛的人数等)。在新生儿护理领域,可以在特定事件之间施加时间顺序,如图1b所示,但更大的文本跨度可能反映基于重要性的排序,以及基于相关性的信息分组(例如,与患者呼吸有关的所有事件)(Portet et al, 2009)。当然,不同的信息之间可能存在着不同的话语关系,如对比或阐述。这一阶段的结果是一个语篇、文本或文档计划,这是一种结构化和有序的信息表示。
这些示例再次表明,应用程序域对排序首选项施加了约束。早期的方法,如McKeown(1985),通常依赖于手工制作的、与领域相关的结构化规则(McKeown将其称为schemata)。为了解释信息之间的语篇关系,研究人员还采用了修辞结构理论(首先;例如,Mann & Thompson, 1988;Scott & Sieckenius de Souza, 1990;Hovy, 1993),这通常也涉及特定领域的规则。例如,Williams和Reiter(2008)使用RST关系来确定信息之间的顺序,以最大限度地提高对低技能读者的清晰度。
许多研究人员探索了使用机器学习技术进行文档结构化的可能性(例如,Dimitromanolaki & Androutsopoulos, 2003;Althaus, Karamanis, & Koller, 2004),有时将此与内容选择相结合(Duboue & McKeown, 2003)。信息排序的一般方法(Barzilay & Lee, 2004;Lapata, 2006)已经被提出,它会自动寻找“信息承载项目”的最佳排序。这些方法可以应用于文本结构,其中要排序的项目通常是前言语信息;然而,它们也可以应用在(多文档)摘要中,要排序的项目是输入文档中的句子,这些句子被认为是有价值的摘要,足以概括(例如,Barzilay, Elhadad, & McKeown, 2002;博勒加拉,冈崎,和石祖卡,2010)。
2.3句子聚合
并不是每个信息都需要在一个单独的句子中表达出来;通过将多个信息组合成一个句子,生成的文本可能变得更加流畅和可读(例如,Dalianis, 1999;Cheng & Mellish, 2000),尽管也有一些情况认为应该避免聚合(在第5.2节中讨论)。例如,图1b中选择的三个事件被“合并”为一个前语言表示,它将被映射到一个句子。将相关信息分组到句子中的过程称为句子聚合。
再举一个例子,在足球领域,有一种(未汇总的)描述英超最快帽子戏法的方式是:
(1) Sadio Mane scored for Southampton after 12 minutes and 22 seconds.
(2) Sadio Mane scored for Southampton after 13 minutes and 46 seconds.
(3) Sadio Mane scored for Southampton after 15 minutes and 18 seconds.
-
在12分22秒后,南安普顿的萨迪奥·马内破门。
-
萨迪奥·马内在13分46秒后为南安普顿进球。
-
萨迪奥·马内在15分18秒后为南安普顿进球。
显然,这是相当冗余的,不是非常简洁或连贯的,通常读起来不愉快。因此,最好采用如下的聚合备选方案:
(4) Sadio Mane scored three times for Southampton in less than three minutes.
- 萨迪奥·马内在不到三分钟的时间里为南安普顿打进三球。
一般来说,聚合是很难定义的,并且有各种各样的解释,从消除冗余到结合语言结构。Reape和Mellish(1999)提供了一个早期的调查,区分了语义级别的聚合(如图1c所示)和语法级别的聚合(如图1-3到(4)的转换所示)。
公平地说,许多早期的聚合工作都强烈地依赖于领域。这项工作关注于领域和应用特定的规则(例如,“如果一个球员连续进了两个球,就用同一句话来描述”),这通常是手工制作的(例如,Hovy, 1988;Dalianis, 1999;肖,1998)。再一次,最近的工作逐渐转向数据驱动的方法,从语料库数据中获取聚合规则(例如,Walker, Park, Rambow, & Rogati, 2001;Cheng & Mellish, 2000)。
Barzilay和Lapata(2006)提出了一个系统,该系统通过查找条目之间的相似性,学习如何在句子和相应数据库条目的平行语料库的基础上进行聚合。就像Barzilay和Lapata(2005)的内容选择方法一样,Barzilay和Lapata(2006)从全局优化的角度看待这个问题:对数据库条目进行初始分类,根据它们的成对相似性来决定是否应该聚合它们。随后,根据传递性约束(如果<ei, ej>和<ej, ek>是链接的,那么<ei, ek>也应该是链接的)和全局约束(比如文档中应该聚合多少个句子)选择一个全局最优的链接条目集。全局优化是根据整数线性规划(一种著名的数学优化技术)进行的(例如,Nemhauser & Wolsey, 1988)。
通过语法聚合,定义与领域无关的规则来消除冗余(Harbusch & Kempen, 2009;Kempen, 2009)。例如,将(5)转换为(6):
(5) Sadio Mane scored in the 12th minute and he scored again in the 13th minute.
(6) Sadio Mane scored in the 12th minute and again in the 13th.
(5)萨迪奥·马内在第12分钟进球,在第13分钟又进球。
(6)萨迪奥·马内在第12分钟和第13分钟分别进球。
可以通过识别两个连句中的并列动词短语,而在第二个连句中省略主语和动词来实现。最近的工作探索了从语料库中自动获取这些规则的可能性。例如,Stent和Molina(2009)描述了一种从语篇树库获取句子组合规则的方法,这些规则随后被并入Walker等人(2007)描述的活跃的句子计划器中。White和Howcroft(2015)讨论了针对同一问题的更普遍的方法。
可以说,与消息级别的聚合相比,语法级别的聚合只能起到相对较小的减少作用。此外,句法聚合假设句子规划过程(包括词汇化)是完整的。
因此,虽然传统的nlg方法将聚合视为句子规划的一部分,发生在句法实现之前,但这种说法的有效性取决于正在执行的聚合的类型(另见Theune, Hielkema, & Hendriks, 2006)。
2.4 词汇化
一旦句子的内容最终确定(也可能是在消息级别聚合的结果),系统就可以开始将其转换为自然语言。在我们的例子中(图1c),聚合和词汇化的结果一起显示:在这里,三个事件被分组,并映射到一个包含动词(be)及其参数的表示,尽管参数本身仍然必须在引用表达式中呈现(见下文)。这反映了一个重要的决定,即使用哪些单词或短语来表达信息的构建模块。一个复杂的问题是,一个事件通常可以用自然语言以多种不同的方式表达。例如,足球比赛中的得分事件可以被表达为“得分”、“进球”、“把球扔进网里”等等。
这个词汇化过程的复杂性很大程度上取决于nlg系统可以接受的替代方案的数量。通常情况下,上下文约束在这里也扮演着重要的角色:如果目标是生成具有一定数量变化的文本(例如,Theune et al, 2001),系统可以决定从一组替代选项中随机选择一个词汇化选项(甚至可能是从一组文本前面没有使用的替代选项中)。
然而,文体上的限制也起了作用:例如,“to score a goal”是表达“乌龙球”的不恰当的方式。在其他应用中,词汇选择甚至可能由其他考虑因素决定,例如对所讨论事件的态度或情感立场(例如,Fleischman & Hovy, 2002,以及第5节的讨论)。nlg系统是否以输出变化为目标取决于领域。例如,足球报道的变化可能比天气报道的变化更受读者欢迎(见Reiter et al, 2005);这也可能取决于在文本中发生变化的位置。例如,与参照形式的变化相比,表达时间戳的变化可能更不受重视(Castro Ferreira, Krahmer, & Wubben, 2016)。
词汇化的一个简单的模型——图1中假设的模型——是对前言语信息进行操作,将领域概念直接转换为词汇项。这在定义良好的域中可能是可行的。通常情况下,词汇化更难,至少有两个原因(参见Bangalore & Rambow, 2000):首先,它可能涉及在语义相似、接近同义或分类相关的词汇之间进行选择(例如animal vs dog;Stede, 2000;埃德蒙兹和赫斯特,2002年)。其次,根据清晰的概念到单词的映射来建模词汇化并不总是那么简单。困难的一个来源是模糊性,例如,在表示可分级属性的术语中出现了模糊性。例如,根据实体的尺寸选择形容词“宽”或“高”需要系统推断类似物体的宽度或高度,可能使用一些比较标准(因为“高玻璃杯”比“矮个子人”短;参考Kennedy & McNally, 2005;范德姆特,2012)。在呈现数字信息(如时间戳和数量)时也注意到了类似的问题(Reiter et al, 2005;鲍尔和威廉姆斯,2012)。例如,Reiter等人(2005)讨论了天气预报生成上下文中的时间表达式,指出时间戳00:00可以表示为深夜、午夜或简单地表示为晚上(Reiter等人,2005,第143页)。毫不奇怪,人类(包括为瑞特等人的评估做出贡献的专业预测者)在词汇选择上表现出相当大的差异。
有趣的是,许多与词汇化相关的问题也在词汇获取的心理语言学文献中被讨论过(Levelt, 1989;Levelt, Roelofs, & Meyer, 1999)。其中一个问题是,说话者如何专注于正确的单词,以及在什么情况下他们容易出错,因为心理词汇是一个紧密连接的网络,其中词汇项在多个层次上(语义、语音等)相连。这也是计算建模的一个富有成效的主题(例如,Levelt等人,1999)。然而,与认知建模方法相反,nlg的研究越来越多地将词汇化视为表面实现的一部分(下文将进行讨论)(Mellish & Dale, 1998年,第351页)。Elhadad、Robin和McKeown(1997)在这方面做出了基本贡献,他们描述了一种基于统一的方法,用编码词汇和语法选择的语法规则统一概念表示(即前言语信息)。
2.5引用表达式生成
引用表达式生成(reg)被Reiter和Dale (1997, p.11)描述为“选择单词或短语以识别领域实体的任务”。这一特征表明它与词汇化非常相似,但Reiter和Dale(2000)指出,本质上的区别在于引用表达式生成是一项“辨别任务,系统需要传递足够的信息来区分一个领域实体与其他领域实体”。reg是近年来在自动文本生成领域中最受关注的任务之一(Mellish等人,2006;Siddharthan, Nenkova, & McKeown, 2011)。由于它可以相对容易地从特定的应用程序域中分离出来,并单独进行研究,因此存在针对reg问题的各种“独立”解决方案。
在我们的运行示例中,图1b所示的三个心动过缓事件稍后在be的主题参数下表示为一组三个实体,随后进行词汇化(图1c)。系统如何引用它们将取决于它们是否已经被提及(在这种情况下,一个代词或明确的描述可能有效),如果是,是否需要将它们与任何其他类似的实体区分开来(在这种情况下,它们可能需要通过一些属性来区分,例如它们发生的时间)。
因此,第一个选择与指称形式有关:例如,实体是使用代词、专有名称还是(in)确定的描述来指称的。这部分取决于这个实体在多大程度上是“焦点”或“突出的”(例如,Poesio, Stevenson, Di Eugenio, & Hitzeman, 2004),事实上,这样的概念是许多计算式的代词生成的基础(例如,McCoy & Strube, 1999;卡拉威和莱斯特,2002年;Kibble & Power, 2004)。在上下文中生成引用表达式(grec;Belz, Kow, Viethen, & Gatt, 2010),使用来自维基百科文章的数据,其中包括反身代词和专有名称等选项。许多参与这一挑战的系统根据这些众多选项中的分类来框定问题。尽管如此,公平地说,很多关于指称形式的工作都集中在何时使用代词上。专有名等形式的研究仍然不足,尽管最近各种研究人员强调了专有名生成的问题(Siddharthan et al, 2011;范德姆特,2016;Castro Ferreira, Wubben, & Krahmer, 2017)。
当所选的形式是描述时,通常需要确定参考内容。通常,在一个领域中有多个实体具有相同的参考类别或类型(例如,多个参与者或多个心动过缓)。因此,如果要让读者或听者识别该实体,则需要提及该实体的其他属性。早期的reg研究通常使用简单的视觉域,例如图2a或其对应的表格表示,取自gre3d语料库(Viethen & Dale, 2008)。在本例中,reg内容选择问题是为目标(比如d1)找到一组属性,将目标从两个干扰物(d2和d3)中分离出来。
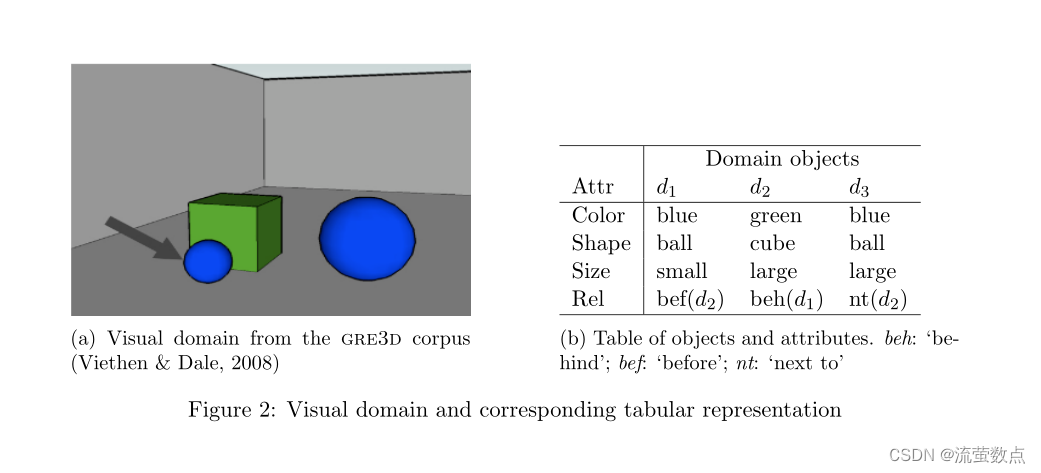
Reg内容确定算法可以被认为是通过referent的已知属性执行搜索,以找到在上下文中区分它的“正确”组合。什么构成了“正确的”组合取决于潜在的理论。描述中过多的信息(比如绿色大杯子前面的蓝色小球)可能会产生误导,甚至令人厌烦;太少(球)可能会妨碍辨认。许多关于reg的工作都诉诸于格赖斯格言,该格言指出,说话者应该确保他们的贡献对交换的目的来说是足够的信息,而不是更多(格赖斯,1975)。如何解释这一点一直是许多算法解释的主题,包括:
- 在可能的描述空间中进行详尽的搜索,并选择能够识别目标所指对象的最小属性集,这一策略包含在“完整简洁”过程中(Dale, 1989)。在我们的示例域中,这将选择大小。
- 循序渐进地选择属性,但选择每一步都能排除大部分干扰因素的属性,从而最大限度地减少包含与识别任务不直接相关的信息的可能性。这是贪婪启发式算法(Dale, 1989,1992)的基本思想,最近在基于随机效用的模型中,如Frank, Goodman和Tenenbaum(2009),它被重新启用。在我们的示例场景中,这样的算法将再次首先考虑大小。
- 逐步选择属性,但基于特定领域的偏好或认知突出性。这是增量算法(Dale & Reiter, 1995)中包含的策略,在我们的例子中,该算法预测颜色应该优先于尺寸。
虽然这些启发式只关注于明确识别指涉者的要求,但对对话中指称的研究(例如,Jordan & Walker, 2005)表明,在某些条件下,指称表达可能还包含“冗余”属性,以达到其他交际目标,如确认对话者之前的话语。类似地,White、Clark和Moore(2010)提出了一个系统,该系统可以在口头对话中生成用户定制的描述,他们认为,例如,一个经常飞行的人会比一个只偶尔飞行的学生更喜欢不同的航班描述。
这些不同的算法为目标引用计算(可能是不同的)区分描述(更准确地说:它们选择区分目标的属性集,但这些属性仍然需要用文字表示;见下文第2.6节)。各种更近期的工作可以区分(调查在Krahmer & van Deemter, 2012)。一些研究人员专注于扩展“经典”算法的表达能力,将复数(两个球)和关系(一个立方体前面的球)(例如,Horacek, 1997;石头,2000;Gardent, 2002;凯莱赫和克鲁伊夫,2006;Viethen & Dale, 2008年,以及其他许多)。其他的工作则把这个问题用概率的方式来解释;例如,FitzGerald、Artzi和Zettlemoyer(2013)将reg定义为在表示对象集合表达式的逻辑形式空间上估计对数线性分布的问题。
其他工作集中在评估不同reg算法的性能,通过收集受控的人类引用,并将其与各种算法预测的引用进行比较(例如,Belz, 2008;Gatt & Belz, 2010;Jordan & Walker, 2005年,还有很多其他的)。同样,研究人员也开始探索reg算法作为人类语言生产的心理语言学模型的相关性(例如,van Deemter, Gatt, van Gompel, & Krahmer, 2012b)。
另一种不同的工作已经脱离了内容选择和形式之间的分离,将这些任务联合起来执行。例如,Engonopoulos和Koller(2014)使用一种同步语法,直接将表面字符串与目标引用关联起来,使用图表计算给定目标的可能表达式。这项工作与我们在下面第3.2节中讨论的基于规划的方法有一定关系,后者利用语法形式主义作为规划操作符(例如Stone & Webber, 1998;Koller & Stone, 2007),同时解决实现和内容确定问题(包括作为特例的reg)。
最后,在早期的工作中,视觉信息通常被“简化”为一个表(就像我们上面做的那样),但在更复杂的场景中,reg已经取得了实质性的进展。例如,GIVE challenge(Koller, Striegnitz, Gargett, Byron, Cassell, Dale, Moore, & Oberlander, 2010)为探索虚拟环境中的对象的情境引用提供了动力(另见Stoia & Shockley, 2006;Garoufi & Koller, 2013)。最近的工作已经开始探索计算机视觉和reg之间的接口,以生成复杂的、现实的视觉场景中的物体描述,包括照片(例如,Mitchell, van Deemter, & Reiter, 2013;Kazemzadeh, Ordonez, Matten, & Berg, 2014;毛,黄,Toshev, Camburu, Yuille,和Murphy, 2016)。这是我们将在第4节讨论的视觉和语言之间关系的更广泛发展的一部分。
2.6语言实现
最后,当所有相关的单词和短语都确定后,需要将它们组合起来形成一个结构良好的句子。图1d中的简单例子显示了句子的结构,有三个连续的心动缓,降到69,语言信息对应于图1a中从原始信号中选择的部分。
这个任务通常被称为语言实现,包括对句子的组成成分进行排序,以及生成正确的形态形式(包括动词的变化和一致,在相关的语言中)。通常,实现者还需要插入虚词(如助动词和介词)和标点符号。这个阶段的一个重要问题是,输出需要包括输入中可能不存在的各种语言成分(下面3.1节讨论的“代沟”的一个例子);因此,这个生成任务可以被认为是非同构结构之间的投影(参见Ballesteros, Bohnet, Mille, & Wanner, 2015)。已经提出了许多不同的方法,我们将讨论其中的一些
- human-crafted模板;
- human-crafted基于语法的系统;
- 统计方法。
2.6.1手工编写模板
当应用程序域很小且期望变化最小时,实现是一项相对容易的任务,并且可以使用模板指定输出(例如,Reiter, Mellish, & Levine, 1995;McRoy, Channarukul, & Ali, 2003),例如如下。
(7) $player scored for $team in the $minute minute.
$球员为$球队在$分钟内得分。
这个模板有三个变量,可以用球员、球队和球员进球的时间来填充。因此,它可以生成这样的句子:
(8) Ivan Rakitic scored for Barcelona in the 4th minute.
伊万·拉基蒂奇在第4分钟为巴萨进球。
模板的一个优点是,它们允许对输出的质量进行完全控制,并避免生成不合语法的结构。基于模板的方法的现代变体包括模板中的语法信息,以及可能用于填补空白的复杂规则(Theune et al, 2001),这使得区分模板与更复杂的方法变得困难(van Deemter, Krahmer, & Theune, 2005)。
模板的缺点是,如果手工构建,它们是劳动密集型的(尽管模板最近已经从语料库数据中自动学习,参见例如,Angeli, Manning, & Jurafsky, 2012;Kondadadi et al, 2013,以及下面3.3节中的讨论)。它们也不能很好地扩展到需要大量语言变化的应用程序。
2.6.2手工编写基于语法的系统
通用的、领域独立的实现系统提供了模板的替代方案。大多数这些系统都是基于语法的,也就是说,它们根据所考虑的语言的语法做出部分或全部的选择。这种语法可以手动编写,就像许多经典的现成实现器一样,如fuf/surge (Elhadad & Robin, 1996)、mumble (Meteer, McDonald, Anderson, Forster, Gay, Iluettner, & Sibun, 1987)、kpml (Bateman, 1997)、nigel (Mann & Matthiessen, 1983)和RealPro (Lavoie & Rambow, 1997)。手工编码的基于语法的实现器往往需要非常详细的输入。例如,kpml (Bateman, 1997)是基于系统功能语法(sfg;Halliday & Matthiessen, 2004),而实现被建模为一个网络的遍历,其中的选择依赖于语法和语义-语用信息。这种级别的细节使得这些系统难以作为简单的“即插即用”或“现成”模块使用(例如,Kasper, 1989),这推动了简单实现引擎的开发,这些引擎提供语法和形态学api,但将选择留给开发人员(Gatt等人,2009;沃德里&拉帕尔姆,2013年;Bollmann, 2011;德奥利维拉和斯里帕达,2014年;Mazzei, Battaglino, & Bosco, 2016)。
基于语法的系统的一个困难是如何在相关选项中做出选择,例如下面的选项,手工制作的规则很难设计,对上下文和输入具有正确的敏感性:
(9) Ivan Rakitic scored for Barcelona in the 4th minute.
(10) For Barcelona, Ivan Rakitic scored in minute four.
(11) Barcelona player Ivan Rakitic scored after four minutes.
伊万·拉基蒂奇在第4分钟为巴萨进球。
巴塞罗那队,伊万·拉基蒂奇在第4分钟进球。
巴塞罗那球员伊万·拉基蒂奇在4分钟后进球。
2.6.3统计方法
最近的方法是寻求从大型语料库中获取概率语法,减少所需的手工劳动量,同时增加覆盖率。基本上,已经采取了两种方法在实现过程中纳入统计资料。
一种方法是由Langkilde和Knight (Langkilde- geary, 2000;Langkilde-Geary & Knight, 2002)在卤素/氮系统上的研究,依赖于一种两级方法,在这种方法中,一个小型的手工制作的语法被用来生成表示为森林的替代实现,随机重新排序器从其中选择最佳候选对象。Langkilde和Knight以n-grams的形式依赖基于语库的统计知识,而其他人则尝试了更复杂的统计模型来执行重排序(例如,Bangalore & Rambow, 2000;Ratnaparkhi, 2000;卡希尔,福斯特,和罗勒,2007)。第二种方法不依赖计算成本高的生成-筛选方法,而是直接在生成决策级别使用统计信息。这种方法的一个例子是Belz(2008)开发的pcru系统,它在给定的语料库中使用上下文无关的语法生成最可能的句子派生。在这种情况下,统计数据被用来控制生成器在寻找最优解决方案时的选择行为。
在这两种方法中,基本生成器都是手工制作的,而统计信息则用于过滤输出。一个明显的替代方案是也依赖于基本发电系统的统计信息。通过从树库中获取语法规则,已经开发出了完全基于数据驱动的语法方法。例如,Openccg框架(Espinosa, White, & Mehay, 2008;White & Rajkumar, 2009, 2012)提出了一种基于组合范畴语法(ccg;Steedman, 2000),依赖于来自Penn Treebank (Hockenmaier & Steedman, 2007)的ccg表示语料库,并使用统计语言模型进行重新排序。
基于多种语法形式,还有其他几种实现方法采用了类似的原理,包括头部驱动短语结构语法(hpsg;宫瑶和辻井,2005;Carroll & openen, 2005),《词汇-功能语法》(lfg;Cahill & Van Genabith, 2006)和树连接语法(标签;加德纳和纳拉扬,2015年)。在许多这样的系统中,基础生成器使用图表生成算法的一些变体(Kay, 1996)来迭代实现输入规范的部分,并将它们合并为一个或多个最终结构,然后可以对其进行排序(参见Rajkumar & White, 2014,进一步讨论)。具有广泛覆盖语法的随机实现器的存在促使人们更加关注微妙的选择,比如如何避免结构歧义,或者如何处理英语中显式补语插入等选择(参见例如,Rajkumar & White, 2011)。与此类似,加德纳和佩雷斯-贝特拉奇尼(Perez-Beltrachini, 2017)提出的微观规划的统计方法侧重于联合模型中表面实现、聚合和句子分割之间的相互作用。
其他实现方法也依赖于一个或多个分类器来提高产出。
例如,Filippova和Strube(2007, 2009)描述了一种使用最大熵分类器的两步方法对成分进行线性化的方法,首先确定哪个成分应该占据句子开头的位置,然后在句子的其余部分对成分进行排序。Bohnet、Wanner、Mille和Burga(2010)在基于支持向量机的框架中提出了一种实现器,使用未指定的依赖结构作为输入,其中分类器以级联方式组织。一个初始分类器将语义输入解码为相应的语法特征,而两个后续分类器首先将语法线性化,然后为组成词位呈现正确的形态实现。
使用分类器级联的建模选择不仅仅局限于实现。实际上,在某些情况下,它被作为nlg过程的整体模型,我们将在第3.3.3节中返回这个主题。nlg的这一观点的一个结果是,输入表示的性质也发生了变化:在统计生成系统中做出的决策越多,输入表示就越少语言化,越抽象,为集成的端到端随机生成系统铺平了道路,如Konstas和Lapata(2013),我们将在下一节中讨论。
2.7讨论
本节概述了在大多数nlg系统中可以找到的一些经典任务。
在每种情况下可以确定的一个共同趋势是,从早期的基于规则的手工方法,到更近期的依赖于语料库数据的随机方法,逐步向更独立于领域的方法发展。
从历史上看,这已经是个别任务的情况,如参考表达生成或实现,它们本身就成为密集研究的主题。
然而,随着越来越多的nlg任务的处理方法开始出现统计学上的转变,人们越来越强调学习技巧;特定于领域的方面是训练数据本身的一个附带属性。正如我们将在下一节中看到的,这一趋势也影响了不同nlg任务的组织方式,即从数据生成文本的系统架构。