【摘要】本文分析了Linux设备的内存映射的相关概念和理论,使用例子对mmap及nopage的驱动编写方法进行了解释,最后对3种不同的内核虚拟空间分配方法下,mmap驱动编写方法进行了细致的分析和调试。
1、mmap概念
如下图所示,mmap是操作外设(字符设备、块设备、网络设备等)一种方法,所谓操作设备(比如IO端口(点亮一个LED)、LCD控制器、磁盘控制器)实际上就是往设备的存储空间(物理地址)读写数据。
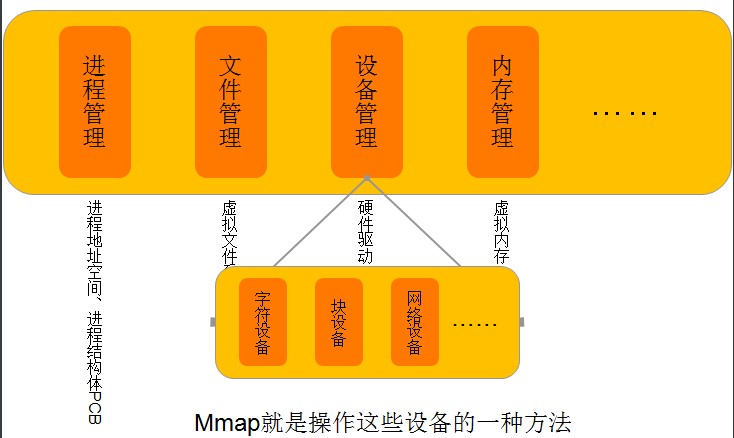
但是,由于应用程序不能直接操作设备硬件地址,所以操作系统提供了这样的一种机制——内存映射,把设备地址映射到进程虚拟地址,mmap就是实现内存映射的一种方法。
操作设备还有很多方法,如read、write、ioctl、ioremap。但mmap的好处是,mmap把设备内存映射到虚拟内存,则用户操作虚拟内存相当于直接操作设备了,省去了其它方法那样(ioctl、ioremap)需要从用户空间到内核空间再到设备的复制过程,所以相对IO操作来说,增加了数据的吞吐量。
既然mmap是实现内存映射的接口,那么内存映射是什么呢?看下图
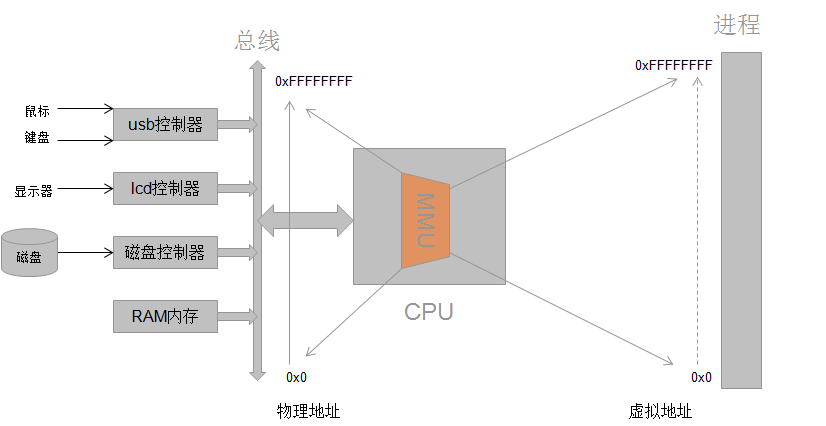
每个进程都有独立的进程地址空间,通过页表和MMU,可将虚拟地址转换为物理地址,每个进程都有独立的页表数据,这可解释为什么两个不同进程相同的虚拟地址,却对应不同的物理地址。
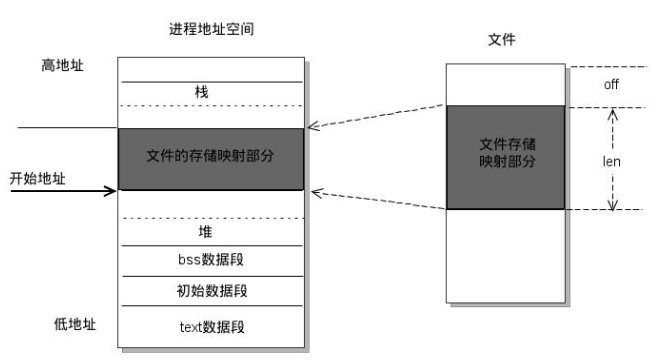
现在已经知道了内存映射是把设备地址映射到进程空间地址(注意:并不是所有内存映射都是映射到进程地址空间的,ioremap是映射到内核虚拟空间的,mmap是映射到进程虚拟地址的),实质上是分配了一个vm_area_struct结构体加入到进程的地址空间,也就是说,把设备地址映射到这个结构体,映射过程就是驱动程序要做的事了。
linux内核使用vm_area_struct结构来表示一个独立的虚拟内存区域,由于每个不同质的虚拟内存区域功能和内部机制都不同,因此一个进程使用多个vm_area_struct结构来分别表示不同类型的虚拟内存区域。各个vm_area_struct结构使用链表或者树形结构链接,方便进程快速访问,如下图所示:
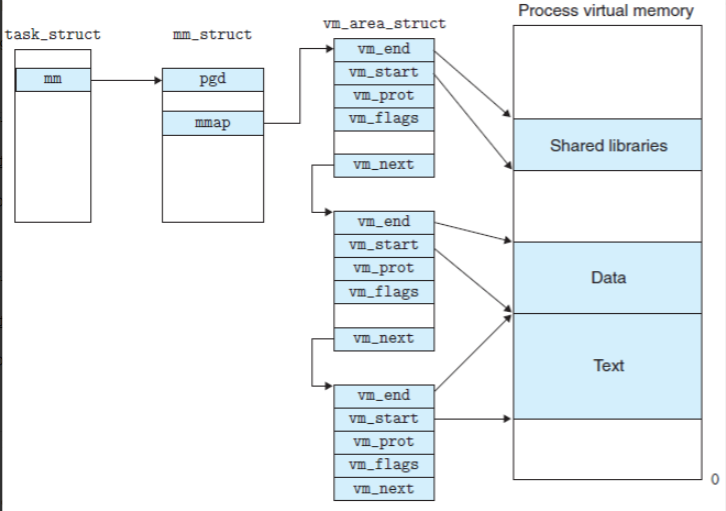
vm_area_struct结构中包含区域起始和终止地址以及其他相关信息,同时也包含一个vm_ops指针,其内部可引出所有针对这个区域可以使用的系统调用函数。这样,进程对某一虚拟内存区域的任何操作需要用要的信息,都可以从vm_area_struct中获得。mmap函数就是要创建一个新的vm_area_struct结构,并将其与文件的物理磁盘地址相连。
/* 在<linux/mm.h>中定义 */struct vm_area_struct {struct mm_struct * vm_mm; /* The address space we belong to. */unsigned long vm_start; /* Our start address within vm_mm. */unsigned long vm_end; /* The first byte after our end addresswithin vm_mm. *//* linked list of VM areas per task, sorted by address */struct vm_area_struct *vm_next;pgprot_t vm_page_prot; /* Access permissions of this VMA. */unsigned long vm_flags; /* Flags, listed below. */struct rb_node vm_rb;/** For areas with an address space and backing store,* linkage into the address_space->i_mmap prio tree, or* linkage to the list of like vmas hanging off its node, or* linkage of vma in the address_space->i_mmap_nonlinear list.*/union {struct {struct list_head list;void *parent; /* aligns with prio_tree_node parent */struct vm_area_struct *head;} vm_set;struct raw_prio_tree_node prio_tree_node;} shared;/** A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma* list, after a COW of one of the file pages. A MAP_SHARED vma* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack* or brk vma (with NULL file) can only be in an anon_vma list.*/struct list_head anon_vma_node; /* Serialized by anon_vma->lock */struct anon_vma *anon_vma; /* Serialized by page_table_lock *//* Function pointers to deal with this struct. */struct vm_operations_struct * vm_ops;/* Information about our backing store: */unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZEunits, *not* PAGE_CACHE_SIZE */struct file * vm_file; /* File we map to (can be NULL). */void * vm_private_data; /* was vm_pte (shared mem) */unsigned long vm_truncate_count;/* truncate_count or restart_addr */#ifndef CONFIG_MMUatomic_t vm_usage; /* refcount (VMAs shared if !MMU) */
#endif
#ifdef CONFIG_NUMAstruct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endif
};/** These are the virtual MM functions - opening of an area, closing and* unmapping it (needed to keep files on disk up-to-date etc), pointer* to the functions called when a no-page or a wp-page exception occurs. */
struct vm_operations_struct {void (*open)(struct vm_area_struct * area);void (*close)(struct vm_area_struct * area);struct page * (*nopage)(struct vm_area_struct * area, unsigned long address, int *type);unsigned long (*nopfn)(struct vm_area_struct * area, unsigned long address);int (*populate)(struct vm_area_struct * area, unsigned long address, unsigned long len, pgprot_t prot, unsigned long pgoff, int nonblock);/* notification that a previously read-only page is about to become* writable, if an error is returned it will cause a SIGBUS */int (*page_mkwrite)(struct vm_area_struct *vma, struct page *page);
#ifdef CONFIG_NUMAint (*set_policy)(struct vm_area_struct *vma, struct mempolicy *new);struct mempolicy *(*get_policy)(struct vm_area_struct *vma, unsigned long addr);int (*migrate)(struct vm_area_struct *vma, const nodemask_t *from, const nodemask_t *to, unsigned long flags);
#endif
};
1. mmap的优势、使用范围和细节
-
区别于常规文件操作的优势
- 常规文件操作:常规文件操作为了提高读写效率和保护磁盘,使用了页缓存机制。这样造成读文件时需要先将文件页从磁盘拷贝到页缓存中,由于页缓存处在内核空间,不能被用户进程直接寻址,所以还需要将页缓存中数据页再次拷贝到内存对应的用户空间中。这样,通过了两次数据拷贝过程,才能完成进程对文件内容的获取任务。写操作也是一样,待写入的buffer在内核空间不能直接访问,必须要先拷贝至内核空间对应的主存,再写回磁盘中(延迟写回),也是需要两次数据拷贝。
- mmap操作:使用mmap操作文件中,创建新的虚拟内存区域和建立文件磁盘地址和虚拟内存区域映射这两步,没有任何文件拷贝操作。而之后访问数据时发现内存中并无数据而发起的缺页异常过程,可以通过已经建立好的映射关系,只使用一次数据拷贝,就从磁盘中将数据传入内存的用户空间中,供进程使用。
- 比对结果:常规文件操作需要从磁盘到页缓存再到用户主存的两次数据拷贝。而mmap操控文件,只需要从磁盘到用户主存的一次数据拷贝过程,提高了文件读取效率。
- 可用于实现高效的大规模数据传输。解决内存空间不足,往往是借助硬盘空间协助操作。但是由于会造成大量的文件I/O操作,极大影响效率。这个问题可以通过mmap映射很好的解决。换句话说,但凡是需要用磁盘空间代替内存的时候,mmap都可以发挥其功效。
- 提供进程间共享内存及相互通信的方式。不管是父子进程还是无亲缘关系的进程,都可以将自身用户空间映射到同一个文件或匿名映射到同一片区域。从而通过各自对映射区域的改动,达到进程间通信和进程间共享的目的。
-
使用范围:
- 不是每个设备都适合 mmap 抽象, 例如对串口或其他面向流的设备采用mmap就没有意义。
- mmap的映射粒度是一页(PAGE_SIZE),即被映射区大小必须是 PAGE_SIZE 的整数倍并且开始地址必须 是PAGE_SIZE 对齐的。
- 大部分 PCI 外设通过mmap映射它们的控制寄存器到一个内存地址, 并且一个高性能应用程序可能首选对寄存器的直接存取来代替反复地调用 ioctl 来完成它的工作。
-
细节:
- mmap映射区域大小必须是物理页大小(PAGE_SIZE)的整倍数(32位系统中通常是4k字节)。因为内存映射的最小粒度是页。
- 例如,一个文件的大小是5000字节,mmap函数从文件的起始开始,映射5000字节到虚拟内存中,但是对应到进程虚拟地址区域的大小需要满足整页大小,因此mmap函数执行后,实际映射到虚拟内存区域8192个 字节,50008191的字节部分用零填充,且写50008191时,进程不会报错,但读/写8192以外的磁盘部分,会返回一个SIGSECV错误。
- 但若文件大小是5000,却映射了15000字节到虚拟内存,那么对前2页(0-8191)的访问是正常的,但对8192至14999的访问会报SIGBUS错误,因为对应的区域没有合法的物理页(文件内容),除非在访问前将文件扩充到了该范围。对15000之后的访问,会报SIGSEGV错误,因为访问了映射外的内容。
- 若某文件被映射到内存,一旦映射建立,之后即使文件关闭或文件大小调整,映射依然存在,任然可以对其进行存取。
- mmap映射区域大小必须是物理页大小(PAGE_SIZE)的整倍数(32位系统中通常是4k字节)。因为内存映射的最小粒度是页。
2.mmap的函数原型
mmap 方法是 file_operation 结构的一部分, 当发出 mmap 系统调用时被引用。在调用实际的方法之前内核进行大量工作,因此, mmap的原型非常不同于系统调用的原型。
-
用户空间下的mmap原型:
mmap (void *addr, size_t len, int prot, int flags, int fd, off_t offset);- 参数:
- addr:映射区的开始地址
- len:映射区的长度
- prot:内存保护标志,不能与文件的打开模式冲突。是以下的某个或某几个值得组合。
- 1 EACCES:访问出错
- 2 EAGAIN:文件已被锁定,或者太多的内存已被锁定
- 3 EBADF:fd不是有效的文件描述词
- 4 EINVAL:一个或者多个参数无效
- 5 ENFILE:已达到系统对打开文件的限制
- 6 ENODEV:指定文件所在的文件系统不支持内存映射
- 7 ENOMEM:内存不足,或者进程已超出最大内存映射数量
- 8 EPERM:权能不足,操作不允许
- 9 ETXTBSY:已写的方式打开文件,同时指定MAP_DENYWRITE标志
- 10 SIGSEGV:试着向只读区写入
- 11 SIGBUS:试着访问不属于进程的内存区
- flags:指定映射对象的类型,映射选项和映射页是否可以共享。是以下的某个或某几个值得组合
-
1 MAP_FIXED :使用指定的映射起始地址,如果由start和len参数指定的内存区重叠于现存的映射空间,重叠部分将会被丢弃。如果指定的起始地址不可用,操作将会失败。并且起始地址必须落在页的边界上。
-
2 MAP_SHARED :与其它所有映射这个对象的进程共享映射空间。对共享区的写入,相当于输出到文件。直到msync()或者munmap()被调用,文件实际上不会被更新。
-
3 MAP_PRIVATE :建立一个写入时拷贝的私有映射。内存区域的写入不会影响到原文件。这个标志和以上标志是互斥的,只能使用其中一个。
-
4 MAP_DENYWRITE :这个标志被忽略。
-
5 MAP_EXECUTABLE :同上
-
6 MAP_NORESERVE :不要为这个映射保留交换空间。当交换空间被保留,对映射区修改的可能会得到保证。当交换空间不被保留,同时内存不足,对映射区的修改会引起段违例信号。
-
7 MAP_LOCKED :锁定映射区的页面,从而防止页面被交换出内存。
-
8 MAP_GROWSDOWN :用于堆栈,告诉内核VM系统,映射区可以向下扩展。
-
9 MAP_ANONYMOUS :匿名映射,映射区不与任何文件关联。
-
10 MAP_ANON :MAP_ANONYMOUS的别称,不再被使用。
-
11 MAP_FILE :兼容标志,被忽略。
-
12 MAP_32BIT :将映射区放在进程地址空间的低2GB,MAP_FIXED指定时会被忽略。当前这个标志只在x86-64平台上得到支持。
-
13 MAP_POPULATE :为文件映射通过预读的方式准备好页表。随后对映射区的访问不会被页违例阻塞。
-
14 MAP_NONBLOCK :仅和MAP_POPULATE一起使用时才有意义。不执行预读,只为已存在于内存中的页面建立页表入口。
-
- fd:有效的文件描述词。如果MAP_ANONYMOUS被设定,为了兼容问题,其值应为-1
- offset:被映射对象内容的起点
- 返回值:成功返回被映射区的指针。失败时返回MAP_FAILED(其值为-1), error被设为以下的某个值:
- 1 EACCES:访问出错
- 2 EAGAIN:文件已被锁定,或者太多的内存已被锁定
- 3 EBADF:fd不是有效的文件描述词
- 4 EINVAL:一个或者多个参数无效
- 5 ENFILE:已达到系统对打开文件的限制
- 6 ENODEV:指定文件所在的文件系统不支持内存映射
- 7 ENOMEM:内存不足,或者进程已超出最大内存映射数量
- 8 EPERM:权能不足,操作不允许
- 9 ETXTBSY:已写的方式打开文件,同时指定MAP_DENYWRITE标志
- 10 SIGSEGV:试着向只读区写入
- 11 SIGBUS:试着访问不属于进程的内存区
- 参数:
与mmap相关的函数还包括:
int munmap( void * addr, size_t len ):在进程地址空间中解除一个映射关系,addr是调用mmap()时返回的地址,len是映射区的大小。
int msync( void *addr, size_t len, int flags ):将内存区缓存的内容即刻写回真实物理设备。一般说来,进程在映射空间的对共享内容的改变并不直接写回到磁盘文件中,往往在调用munmap()后才执行该操作。
-
内核驱动下的mmap原型:
int (*mmap) (struct file *filp, struct vm_area_struct *vma);- 为实现 mmap, 驱动只要建立合适的页表给这个地址范围, 并且如果需要,可以用新的操作集合替换
vma->vm_ops。
- 为实现 mmap, 驱动只要建立合适的页表给这个地址范围, 并且如果需要,可以用新的操作集合替换
3.mmap内存映射原理(流程)
-
进程启动映射过程,并在虚拟地址空间中为映射创建虚拟映射区域
- 进程在用户空间调用库函数mmap
- 在当前进程的虚拟地址空间中,寻找一段空闲的满足要求的连续的虚拟地址
- 为此虚拟区分配一个vm_area_struct结构,接着对这个结构的各个域进行初始化
- 将新建的虚拟区结构(vm_area_struct)插入进程的虚拟地址区域链表或树中
-
调用驱动实现的mmap函数,实现文件物理地址和进程虚拟地址的一一映射关系
5. 为映射分配了新的虚拟地址区域后,通过待映射的文件指针,在文件描述符表中找到对应的文件描述符,通过文件描述符,链接到内核“已打开文件集”中该文件的文件结构体(struct file),每个文件结构体维护着和这个已打开文件相关各项信息。
6. 通过该文件的文件结构体,链接到file_operations模块,调用内核函数mmap(不同于用户空间mmap库函数)。
7. 内核mmap函数通过虚拟文件系统inode模块定位到文件磁盘物理地址。
8. 通过remap_pfn_range函数建立页表,即实现了文件地址和虚拟地址区域的映射关系。但此时,这片虚拟地址并没有任何数据关联到主存中。 -
进程发起对这片映射空间的访问,引发缺页异常,实现文件内容到物理内存(主存)的拷贝
9. 进程的读或写操作访问虚拟地址空间这一段映射地址,通过查询页表,发现这一段地址并不在物理页面上。因为目前只建立了地址映射,真正的硬盘数据还没有拷贝到内存中,因此引发缺页异常。
10. 缺页异常进行一系列判断,确定无非法操作后,内核发起请求调页过程。
11. 调页过程先在交换缓存空间(swap cache)中寻找需要访问的内存页,如果没有则调用nopage函数把所缺的页从磁盘装入到主存中。
12. 之后进程即可对这片主存进行读或者写的操作,如果写操作改变了其内容,一定时间后系统会自动回写脏页面到对应磁盘地址,也即完成了写入到文件的过程。也可以调用msync()来强制同步, 这样所写的内容就能立即保存到文件里了。
有 2 个建立页表的方法:调用 remap_pfn_range 一次完成全部, 或者通过 nopage一次一页的完成。每个方法有它的优点和限制,下文将分别介绍。
2、使用 remap_pfn_range实现mmap
建立新页来映射物理地址的工作可以由 remap_pfn_range 和 io_remap_page_range来处理。前者用在 pfn 指向实际的系统 RAM 的情况下,后者用在 phys_addr 指向 I/O 内存时。它们的原型:
int remap_pfn_range(struct vm_area_struct *vma, unsigned long virt_addr,unsigned long pfn, unsigned long size, pgprot_t prot);int io_remap_page_range(struct vm_area_struct *vma, unsigned long virt_addr, unsigned long phys_addr, unsigned long size, pgprot_t prot);
- 参数解析:
- vma:页被映射到的虚拟内存区范围。
- virt_addr:函数为设备映射到的从 virt_addr 开始的 virt_addr_size大小的虚拟地址范围。
- pfn:页帧号, 对应虚拟地址应当被映射的物理地址。页帧号简单地说就是物理地址右移 PAGE_SHIFT 位。对大部分情况来说, VMA 结构的 vm_paoff 成员正好就等于该值。即,上面虚拟地址范围所映射的从 (pfn<<PAGE_SHIFT)到 (pfn<<PAGE_SHIFT)+size的物理地址范围。
- size:被映射的区的大小,以字节。
- prot:驱动为vma->vm_page_prot 设置的值。
注意:为了内容的一致性,映射设备内存不应当被处理器缓存。所以,除了通常系统的BIOS会为此做了正确的配置,我们也可以通过设置保护字段来关闭特定 VMA 的缓存,但它是高度处理器依赖的,更进一步了解请参考drivers/char/mem.c 的 pgprot_noncached 函数 。
下面以为某simple设备的线性内存映射为例, 解释使用remap_pfn_range接口实现的mmap驱动代码:
void simple_vma_open(struct vm_area_struct *vma)
{printk(KERN_NOTICE "Simple VMA open, virt %lx, phys %lx\n",vma->vm_start, vma->vm_pgoff << PAGE_SHIFT);
}void simple_vma_close(struct vm_area_struct *vma)
{printk(KERN_NOTICE "Simple VMA close.\n");
}static struct vm_operations_struct simple_remap_vm_ops = {.open = simple_vma_open,.close = simple_vma_close,
};static int simple_remap_mmap(struct file *filp, struct vm_area_struct *vma)
{if (remap_pfn_range(vma, vma->vm_start, vm->vm_pgoff,vma->vm_end - vma->vm_start,vma->vm_page_prot))return -EAGAIN;vma->vm_ops = &simple_remap_vm_ops;simple_vma_open(vma);return 0;
}
注意:
- 无论何时,一个进程打开或关闭 VMA 时,相应的open或close函数将被调用。对于驱动来说,在open或close函数中,不需要完成任何特殊的工作,因为内核已经给你做好了。所以,即便你不提供自定义的open和close函数(无需对vma->vm_ops赋值也可),mmap也可以正常使用。但如果你添加了自定义的open函数,则必须在驱动的最后添加
simple_vma_open(vma);语句,因为在初始化mmap时,系统默认不会调用open方法。在后面的“mmap的驱动代码实现”小节中提供了不使用自定义 vma->vm_ops的代码。 - remap_pfn_range 只存取保留页和在物理内存顶之上的物理地址。在 Linux, 一个物理地址页若被标志为"保留的",则代表在内存映射中来指示它对内存管理是不可用的。保留页被锁定在内存,并且是唯一可被安全映射到用户空间的。
3、使用 nopage实现mmap
尽管上一节中说的 remap_pfn_range 对许多情况下已经足够了,但在遇到应用程序需要改变一个现有映射区的大小时,即调整某现有VMA的大小,则使用nopage却是更加方便的。
-
nopage函数原型
struct page *(*nopage)(struct vm_area_struct *vma, unsigned long address, int *type); 参数解析:address——导致缺页的虚拟地址,需要向下取整到页地址type——当不为NULL时,存储引起nopage调用的缺页类型,一般设为VM_FAULT_MINOR 返 回 值:用户需要的页指针,同时增加此页的应用计数。 -
调用时机:当用户使用(存取)到VMA中的某页时,此页若不在当前内存中,则会发生缺页异常,进而调用nopage。
-
驱动代码实现:
/* 找到正确的struct page 给出错地址并且递增它的引用计数 */ struct page *simple_vma_nopage(struct vm_area_struct *vma, unsigned long address, int *type) {struct page *pageptr;unsigned long offset = vma->vm_pgoff << PAGE_SHIFT;unsigned long physaddr = address - vma->vm_start + offset; //计算需要的物理地址unsigned long pageframe = physaddr >> PAGE_SHIFT; //得到新的页帧号if (!pfn_valid(pageframe)) //确保一个有效的页帧号(即请求的地址未超出驱动的内存区)return NOPAGE_SIGBUS; //也可以返回NOPAGE_OOM 来指示资源限制导致的失败pageptr = pfn_to_page(pageframe);get_page(pageptr); //递增页的引用计数if (type)*type = VM_FAULT_MINOR;return pageptr; }static struct vm_operations_struct simple_remap_vm_ops = {.nopage = simple_vma_nopage, };static int simple_nopage_mmap(struct file *filp, struct vm_area_struct *vma) {unsigned long offset = vma->vm_pgoff << PAGE_SHIFT;if (offset >= __pa(high_memory) || (filp->f_flags & O_SYNC)){vma->vm_flags |= VM_IO;vma->vm_flags |= VM_RESERVED;}vma->vm_ops = &simple_nopage_vm_ops; //用自己的操作来替换缺省的(NULL)vm_opssimple_vma_open(vma);return 0; }-
限制条件:
- 这个实现只对 ISA 内存区起作用。但是对那些在 PCI 总线上的设备是不行的,因为PCI内存是被映射在最高的系统内存之上的,导致在系统内存中没有这些地址的条目,所以返回不了需要的页指针。所以PCI设备的mmap实现只能使用前一节的remap_pfn_range ,且对 PCI 映射的扩展是不可能的。
- 如果 nopage 方法被留置为 NULL, 处理页出错的内核代码映射零页(零页是一个写时拷贝的页,任何引用零页的进程都看到一个填满 0 的页 )到出错的虚拟地址。因此, 如果一个进程通过调用mremap扩展一个映射的页,并且驱动还没有实现nopage,则进程以零填充的内存代替一个段错误而结束。
-
小技巧
-
最简单的阻止某映射扩展的方法是实现一个简单的 nopage 方法, 它会产生一个总线信号发送给出错进程
struct page *simple_nopage(struct vm_area_struct *vma, unsigned long address, int *type) { return NOPAGE_SIGBUS; /* send a SIGBUS */ }- 当进程解引用一个位于已知的 VMA 中,但是当前还没有有效的页表条目给这个 VMA 的地址时,才会触发调用nopage。如果已使用remap_pfn_range 来映射全部设备区,这里展示的 nopage 方法只被调用来引用那个区外部的地址,因此,我们能通过是否返回 NOPAGE_SIGBUS 来判断一个错误。
-
-
4、mmap的驱动代码实现
以字符设备驱动为例,一般对字符设备的操作如下图所示:
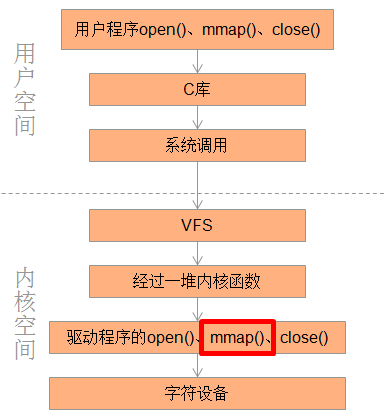
而内存映射的主要任务就是实现内核空间中的mmap()函数。
1. 字符设备驱动程序的框架
static int device_open(struct inode *inode, struct file *filp)
{printk(KERN_NOTICE"Device opened!\n");return 0;
}static int device_close(struct inode *inode, struct file *filp)
{printk(KERN_NOTICE"Device closed!\n");return 0;
}static int device_mmap(struct file *filp, struct vm_area_struct *vma)
{printk(KERN_NOTICE"Device mmap!\n");return 0;
}static struct file_operations device_fops =
{.owner = THIS_MODULE,.open = device_open,.release = device_close,.mmap = device_mmap,
};static int __init char_device_init(void)
{return 0;
}static void __exit char_device_exit(void)
{}module_init(char_device_init);
module_exit(char_device_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("liangzc1124@163.com");
【前提知识】:
关于这个过程,涉及一些术语:
-
设备文件:linux中将硬件虚拟成设备文件,对普通文件的各种操作均适用于设备文件。
-
索引节点:linux使用索引节点来记录文件信息(如文件长度、创建修改时间),它存储在磁盘中,读入内存后就是一个inode结构体,文件系统维护了一个索引节点的数组,每个索引节点都对应一个文件或者目录(目录也是文件)。
-
主设备号:如上面的990,表示设备的类型,比如该设备是lcd还是usb等。
-
次设备号:表示该类设备上的不同设备。
-
文件(普通文件或设备文件)的三个主要数据结构:
- 文件操作:struct file_operations
- 文件对象:struct file
- 文件索引节点:struct inode
关于驱动程序中内存映射的实现,先了解一下open和close的流程
2. open接口的流程
- 应用程序调用
open("/dev/mmap_driver", O_RDWR); - open就会通过VFS找到该设备的索引节点(inode),mknod的时候会根据设备号把驱动程序的file_operations结构填充到索引节点中(关于mknod /dev/mmap_driver c 990 0,这条指令创建了设备文件,在安装驱动(insmod)的时候,会运行驱动程序的初始化程序(module_init),在初始化程序中,会注册它的主设备号到系统中(cdev_add),如果mknod时的主设备号990在系统中不存在,即和注册的主设备号不同,则上面的指令会执行失败,就创建不了设备文件)
- 然后,根据设备文件的索引节点中的file_operations中的open指针,就调用驱动的open方法了。
- 生成一个文件对象files_struct结构,系统维护一个files_struct的链表,表示系统中所有打开的文件。
- 返回文件描述符fd,把fd加入到进程的文件描述符表中。
3. close接口的流程
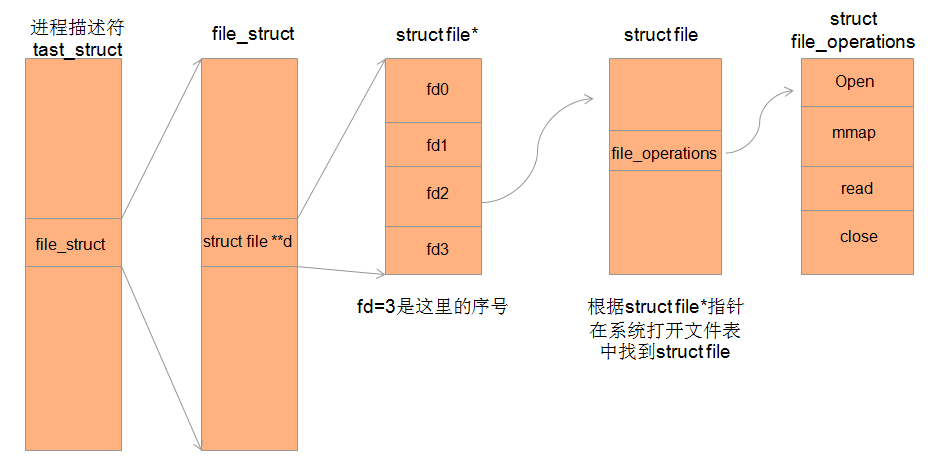
- 设备驱动close流程
应用程序调用close(fd),最终调用到驱动的close,为什么根据一个简单的int型fd就可以找到驱动的close函数?这就和上面说的三个结构(struct file_operations、struct file、struct inode)息息相关了,假如fd = 3
4. mmap接口的流程
由open和close得知,应用程序调用mmap最终也会调用到驱动程序中mmap方法
-
调用应用程序中的mmap函数
void * mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);- addr:映射后虚拟地址的起始地址,通常为NULL,由内核自动分配
- length:映射区的大小
- prot:页面访问权限(PROT_READ、PROT_WRITE、PROT_EXEC、PROT_NONE)
- flags:参考网络资料
- fd:文件描述符
- offset:文件映射开始偏移量
-
驱动程序中的简单mmap函数的示例
static int device_mmap(struct file *file, struct vm_area_struct *vma) { vma->vm_flags |= VM_IO; //表示对设备IO空间的映射 vma->vm_flags |= VM_RESERVED; //标志该内存区不能被换出,在设备驱动中虚拟页和物理页的关系应该是长期的,应该保留起来,不能随便被别的虚拟页换出 if(remap_pfn_range( vma, //虚拟内存区域,即设备地址将要映射到这里 vma->vm_start, //虚拟空间的起始地址 virt_to_phys(buf)>>PAGE_SHIFT, //与物理内存对应的页帧号,物理地址右移12位 vma->vm_end - vma->vm_start, //映射区域大小,一般是页大小的整数倍 vma->vm_page_prot)) //保护属性, { return -EAGAIN; } return 0; }
上面说了,mmap的主要工作是把设备地址映射到进程虚拟地址,也即创建和添加一个vm_area_struct的结构体,这里说的映射在程序中的表现是页表。映射就是要建立页表。进程地址空间就可以通过页表(软件)和MMU(硬件)映射到设备地址上了

- 注意:
- 在本程序中,virt_to_phys(buf),buf是在open时申请的用户空间虚拟地址,这里使用virt_to_phys把buf转换成物理地址,是模拟了一个硬件设备,即把虚拟设备映射到虚拟地址,在实际中可以直接使用外设的物理地址。
- 2.并不是所有设备驱动都可以使用mmap来映射,比如像串口和其他面向流的设备,并且必须按照页大小进行映射。
5. 重映射内核虚拟地址
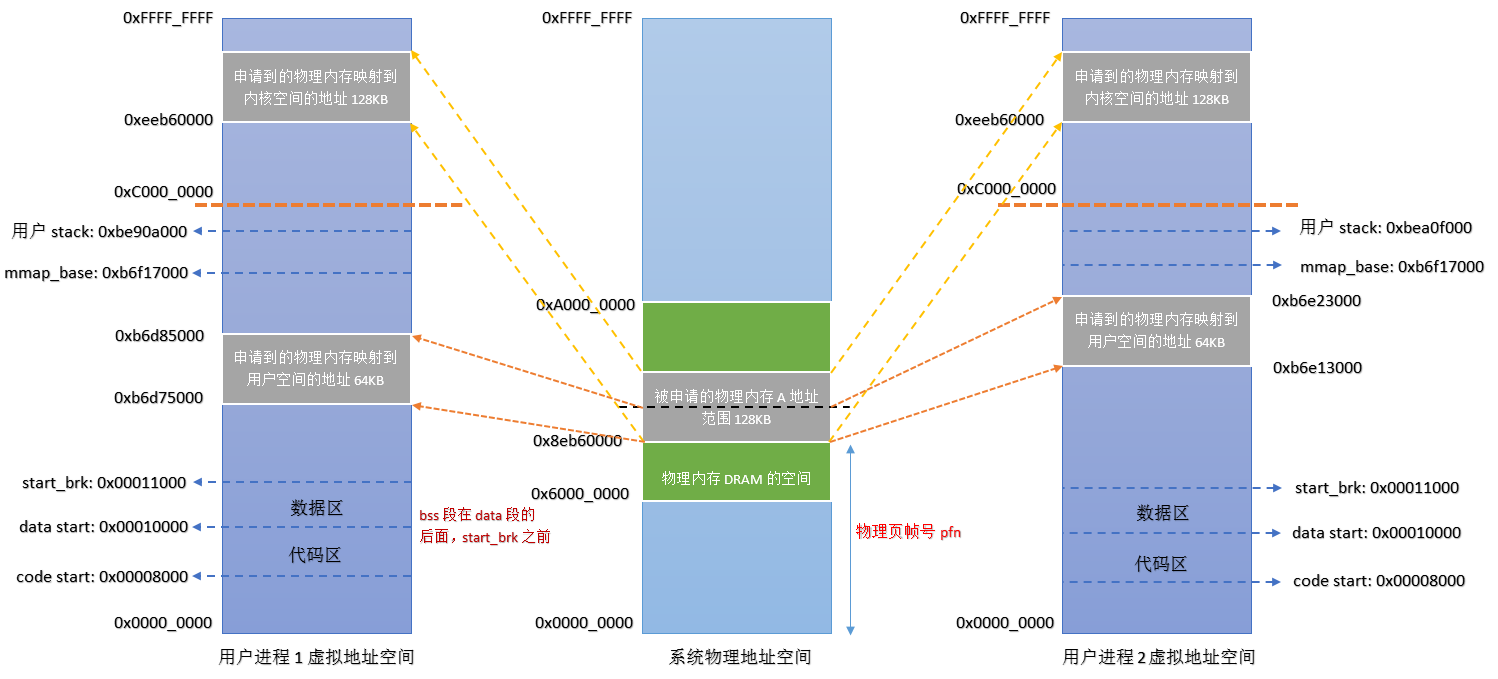
在驱动中申请一个32个Page的缓冲区,这里的PAGE_SIZE是4KB,所以内核中的缓冲区大小是128KB。user_1和user_2将前64KB映射到自己的用户空间,其中user_1向缓冲区中写入字符串,user_2去读取。user_3将全部128KB映射到自己的用户空间,并对其清零。
在驱动中申请缓冲区的方式有多种,可以用kzalloc、也可以用alloc_pages,当然也可用vmalloc,下面会分别针对这三个接口实现驱动。
5.1 利用kzalloc实现
先以kzalloc申请缓冲区的方式为例介绍,调用kmalloc申请32个页,我们知道kzalloc返回的虚拟地址的特点是对应的物理地址也是连续的,所以在调用remap_pfn_range的时候很方便。所以在驱动初始化的时候申请128KB的缓冲区。
- 驱动文件——remap_pfn_kmalloc.c
/* remap_pfn_kmalloc.c */
//所有的驱动模块代码都包含下面两个头文件
#include <linux/init.h>
#include <linux/module.h>#include <linux/miscdevice.h> //定义misc设备相关的数据结构和接口
#include <linux/mm.h> //定义内存管理的接口,如remap_pfn_range接口
#include <linux/uaccess.h>
#include <linux/fs.h> //定义文件系统相关的接口
#include <linux/slab.h> //定义内存申请类的接口,如kmalloc接口
#include <asm/io.h> //定义体系相关的IO接口,如virt_to_phys接口 #define BUF_SIZE (32*PAGE_SIZE)static void *kbuff;/* 没有做什么实际的工作,只是打印一些log,比如将进程的内存布局信息输出 */
static int remap_pfn_open(struct inode *inode, struct file *file)
{struct mm_struct *mm = current->mm;printk("client: %s (%d)\n", current->comm, current->pid); //将进程的名字以及pid打印出来printk("code section: [0x%lx 0x%lx]\n", mm->start_code, mm->end_code); //进程的代码段的范围printk("data section: [0x%lx 0x%lx]\n", mm->start_data, mm->end_data); //进程的数据段的范围printk("brk section: s: 0x%lx, c: 0x%lx\n", mm->start_brk, mm->brk); //进程堆区的起始地址和当前堆顶地址printk("mmap section: s: 0x%lx\n", mm->mmap_base); //进程的mmap区的基地址,mmap区是向下增长的printk("stack section: s: 0x%lx\n", mm->start_stack); //进程的用户栈的起始地址,向下增长printk("arg section: [0x%lx 0x%lx]\n", mm->arg_start, mm->arg_end);printk("env section: [0x%lx 0x%lx]\n", mm->env_start, mm->env_end);return 0;
}static int remap_pfn_mmap(struct file *file, struct vm_area_struct *vma)
{/**offset表示该vma表示的区间在kbuffer缓冲区中的偏移地址,单位是页。*这个值是用户调用mmap时传入的最后一个参数,不过用户空间的offset的单位是字节*/unsigned long offset = vma->vm_pgoff << PAGE_SHIFT; //pfn_start表示在内核缓冲区中,将被映射到用户空间的地址对应的物理页帧号;//virt_to_phys接受的虚拟地址必须在低端内存范围内,用于将虚拟地址转换为物理地址unsigned long pfn_start = (virt_to_phys(kbuff) >> PAGE_SHIFT) + vma->vm_pgoff;//virt_start表示内核缓冲区中将被映射到用户空间的地址对应的虚拟地址unsigned long virt_start = (unsigned long)kbuff + offset;//size表示该vma表示的内存区间的大小unsigned long size = vma->vm_end - vma->vm_start;int ret = 0;printk("phy: 0x%lx, offset: 0x%lx, size: 0x%lx\n", pfn_start << PAGE_SHIFT, offset, size);/**将物理页帧号pfn_start对应的物理内存映射到用户空间的vm->vm_start处,映射长度为该虚拟内存区的长度。*由于这里的内核缓冲区是用kzalloc分配的,保证了物理地址的连续性,所以会将物理页帧号从pfn_start开始*的(size >> PAGE_SHIFT)个连续的物理页帧依次按序映射到用户空间。 */ret = remap_pfn_range(vma, vma->vm_start, pfn_start, size, vma->vm_page_prot);if (ret)printk("%s: remap_pfn_range failed at [0x%lx 0x%lx]\n",__func__, vma->vm_start, vma->vm_end);elseprintk("%s: map 0x%lx to 0x%lx, size: 0x%lx\n", __func__, virt_start,vma->vm_start, size);return ret;
}static const struct file_operations remap_pfn_fops = {.owner = THIS_MODULE,.open = remap_pfn_open,.mmap = remap_pfn_mmap,
};static struct miscdevice remap_pfn_misc = {.minor = MISC_DYNAMIC_MINOR,.name = "remap_pfn",.fops = &remap_pfn_fops,
};static int __init remap_pfn_init(void)
{int ret = 0;kbuff = kzalloc(BUF_SIZE, GFP_KERNEL); // 这里的BUF_SIZE是128KBif (!kbuff) {ret = -ENOMEM;goto err;}// 注册一个misc设备,加载驱动后会在/dev下生成一个名为remap_pfn的节点,用户程序可以通过这个节点跟驱动通信ret = misc_register(&remap_pfn_misc); if (unlikely(ret)) {pr_err("failed to register misc device!\n");goto err;}return 0;err:return ret;
}static void __exit remap_pfn_exit(void)
{misc_deregister(&remap_pfn_misc);kfree(kbuff);
}module_init(remap_pfn_init);
module_exit(remap_pfn_exit);
MODULE_LICENSE("GPL");-
测试文件
-
user_1.c
#include <stdio.h> #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> #include <sys/mman.h> #include <unistd.h> #include <stdlib.h>#define PAGE_SIZE (4*1024) #define BUF_SIZE (16*PAGE_SIZE) #define OFFSET (0)int main(int argc, const char *argv[]) {int fd;char *addr = NULL;fd = open("/dev/remap_pfn", O_RDWR); //打开设备节点if (fd < 0) {perror("open failed\n");exit(-1);}/**从内核空间映射64KB的内存到用户空间,首地址存放在addr中,由于后面既要写入也要共享,所以设置了对应的flags。*这里指定的offset是0,即映射前64KB。*/addr = mmap(NULL, BUF_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_LOCKED, fd, OFFSET);if (!addr) {perror("mmap failed\n");exit(-1);}sprintf(addr, "I am %s\n", argv[0]); //输出字符串到addr指向的虚拟地址空间while(1)sleep(1);return 0; } -
user_2.c
#include <stdio.h> #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> #include <sys/mman.h> #include <unistd.h> #include <stdlib.h>#define PAGE_SIZE (4*1024) #define BUF_SIZE (16*PAGE_SIZE) #define OFFSET (0)int main(int argc, const char *argv[]) {int fd;char *addr = NULL;fd = open("/dev/remap_pfn", O_RDWR);if (fd < 0) {perror("open failed\n");exit(-1);}addr = mmap(NULL, BUF_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_LOCKED, fd, OFFSET);if (!addr) {perror("mmap failed\n");exit(-1);}printf("%s", addr); //将addr指向的虚拟地址空间的内容打印出来while(1)sleep(1);return 0; } -
user_6.c
#include <stdio.h> #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> #include <sys/mman.h> #include <unistd.h> #include <stdlib.h> #include <string.h>#define PAGE_SIZE (4*1024) #define BUF_SIZE (32*PAGE_SIZE) #define OFFSET (0)extern void *func2(void);void func(num) {char buffer[PAGE_SIZE];printf("%d\n", num);while (1)func(--num); }int global_bss[PAGE_SIZE]; int global_data[PAGE_SIZE] = {5};int main(int argc, const char *argv[]) {int fd;char *addr = NULL;int *brk;char buffer[1024*1024];char *addr2;printf("global_bss: 0x%p, global_data: 0x%p\n", &global_bss, &global_data);memset(global_bss, 0x55, PAGE_SIZE*4);memset(global_data, 0x55, PAGE_SIZE*4);fd = open("/dev/remap_pfn", O_RDWR);if (fd < 0) {perror("open failed\n");exit(-1);}addr = mmap(NULL, BUF_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_LOCKED, fd, 0);if (!addr) {perror("mmap failed\n");exit(-1);}memset(addr, 0x0, BUF_SIZE);printf("Clear Finished\n");/*brk = malloc(1024*PAGE_SIZE);*//*memset(brk, 0x0, 1024*PAGE_SIZE);*/addr2 = func2();//func(0);while(1) {sleep(1);}return 0; } -
测试结果
-
内核虚拟空间的布局(在内核的启动log里可以看到内核空间的虚拟内存布局信息)
1 [ 0.000000] Virtual kernel memory layout:2 [ 0.000000] vector : 0xffff0000 - 0xffff1000 ( 4 kB)3 [ 0.000000] fixmap : 0xffc00000 - 0xfff00000 (3072 kB)4 [ 0.000000] vmalloc : 0xf0800000 - 0xff800000 ( 240 MB) #vmalloc分配的内存位于此范围5 [ 0.000000] lowmem : 0xc0000000 - 0xf0000000 ( 768 MB) #kzalloc分配的内存位于此范围6 [ 0.000000] pkmap : 0xbfe00000 - 0xc0000000 ( 2 MB)7 [ 0.000000] modules : 0xbf000000 - 0xbfe00000 ( 14 MB)8 [ 0.000000] .text : 0xc0008000 - 0xc0800000 (8160 kB)9 [ 0.000000] .init : 0xc0b00000 - 0xc0c00000 (1024 kB) 10 [ 0.000000] .data : 0xc0c00000 - 0xc0c7696c ( 475 kB) 11 [ 0.000000] .bss : 0xc0c78000 - 0xc0cc9b8c ( 327 kB) -
用户的虚拟内存布局大致信息
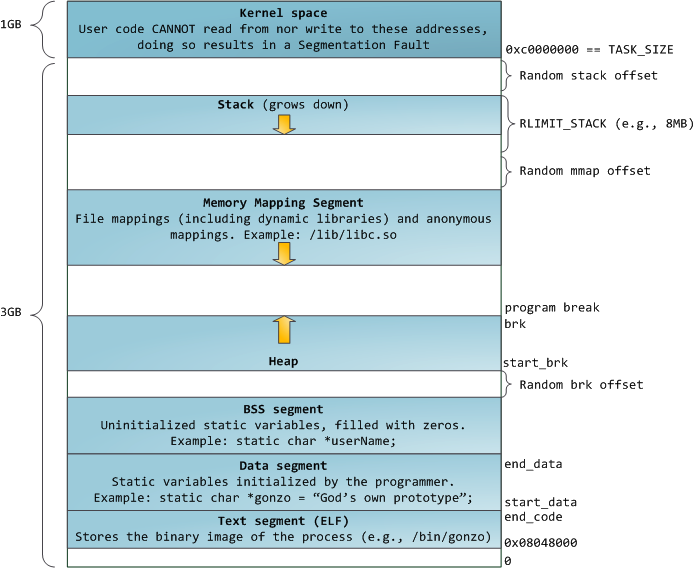
- 调用malloc分配内存的时候,如果传给malloc的参数小于128KB时,系统会在heap区分配内存,分配的方式是向高地址调整brk指针的位置。
- 当传给malloc的参数大于128KB时,系统会在mmap区分配,即分配一块新的vma,其中可能会涉及到vma的合并扩展等操作。参考:Linux进程分配内存的两种方式–brk() 和mmap()
-
加载驱动后,前台运行user_1,通过ps命令获得user_1进程号为870。而后查看一下该进程的地址空间的map信息:
# ./user_1& # cat /proc/870/maps 00008000-00009000 r-xp 00000000 00:12 1179664 /mnt/user_1 00010000-00011000 rw-p 00000000 00:12 1179664 /mnt/user_1 b6d75000-b6d85000 rw-s 00000000 00:10 8765 /dev/remap_pfn b6d85000-b6eb8000 r-xp 00000000 b3:01 143 /lib/libc-2.18.so b6eb8000-b6ebf000 ---p 00133000 b3:01 143 /lib/libc-2.18.so b6ebf000-b6ec1000 r--p 00132000 b3:01 143 /lib/libc-2.18.so b6ec1000-b6ec2000 rw-p 00134000 b3:01 143 /lib/libc-2.18.so b6ec2000-b6ec5000 rw-p 00000000 00:00 0 b6ec5000-b6ee6000 r-xp 00000000 b3:01 188 /lib/libgcc_s.so.1 b6ee6000-b6eed000 ---p 00021000 b3:01 188 /lib/libgcc_s.so.1 b6eed000-b6eee000 rw-p 00020000 b3:01 188 /lib/libgcc_s.so.1 b6eee000-b6f0e000 r-xp 00000000 b3:01 165 /lib/ld-2.18.so b6f13000-b6f15000 rw-p 00000000 00:00 0 b6f15000-b6f16000 r--p 0001f000 b3:01 165 /lib/ld-2.18.so b6f16000-b6f17000 rw-p 00020000 b3:01 165 /lib/ld-2.18.so be8e9000-be90a000 rw-p 00000000 00:00 0 [stack] bed1c000-bed1d000 r-xp 00000000 00:00 0 [sigpage] bed1d000-bed1e000 r--p 00000000 00:00 0 [vvar] bed1e000-bed1f000 r-xp 00000000 00:00 0 [vdso] ffff0000-ffff1000 r-xp 00000000 00:00 0 [vectors]- 取第3行
b6d75000-b6d85000 rw-s 00000000 00:10 8765 /dev/remap_pfn进行分析- “b6d75000”:vma->vm_start的值,"b6d85000"是vma->vm_end的值,b6d85000减b6d75000是64KB,即给vma表示的虚拟内存区域的大小。
- “rw-s”:表示的是vma->vm_flags,其中’s’表示share,'p’表示private
- “00000000”:表示偏移量,也就是vma->vm_pgoff的值
- “00:10”:表示该设备节点的主次设备号
- “8765”:表示该设备节点的inode值
- “/dev/remap_pfn”:表示设备节点的名字。
- 取第3行
-
运行user_2,可以看到user_1写入的信息被打印
# ./user_2 I am ./user_1# cat /proc/873/maps 00008000-00009000 r-xp 00000000 00:12 1179665 /mnt/user_2 00010000-00011000 rw-p 00000000 00:12 1179665 /mnt/user_2 b6e13000-b6e23000 rw-s 00000000 00:10 8765 /dev/remap_pfn b6e23000-b6f56000 r-xp 00000000 b3:01 143 /lib/libc-2.18.so b6f56000-b6f5d000 ---p 00133000 b3:01 143 /lib/libc-2.18.so b6f5d000-b6f5f000 r--p 00132000 b3:01 143 /lib/libc-2.18.so b6f5f000-b6f60000 rw-p 00134000 b3:01 143 /lib/libc-2.18.so b6f60000-b6f63000 rw-p 00000000 00:00 0 b6f63000-b6f84000 r-xp 00000000 b3:01 188 /lib/libgcc_s.so.1 b6f84000-b6f8b000 ---p 00021000 b3:01 188 /lib/libgcc_s.so.1 b6f8b000-b6f8c000 rw-p 00020000 b3:01 188 /lib/libgcc_s.so.1 b6f8c000-b6fac000 r-xp 00000000 b3:01 165 /lib/ld-2.18.so b6fb0000-b6fb3000 rw-p 00000000 00:00 0 b6fb3000-b6fb4000 r--p 0001f000 b3:01 165 /lib/ld-2.18.so b6fb4000-b6fb5000 rw-p 00020000 b3:01 165 /lib/ld-2.18.so be9ee000-bea0f000 rw-p 00000000 00:00 0 [stack] beedf000-beee0000 r-xp 00000000 00:00 0 [sigpage] beee0000-beee1000 r--p 00000000 00:00 0 [vvar] beee1000-beee2000 r-xp 00000000 00:00 0 [vdso] ffff0000-ffff1000 r-xp 00000000 00:00 0 [vectors] -
根据上面的信息,可以得到如下结构图
-
-
5.2 利用alloc_pages实现
-
alloc_pages的函数原型
#define alloc_pages(gfp_mask, order) \alloc_pages_node(numa_node_id(), gfp_mask, order)static inline struct page *alloc_pages_node(int nid, gfp_t gfp_mask,unsigned int order) {if (nid == NUMA_NO_NODE)nid = numa_mem_id();return __alloc_pages_node(nid, gfp_mask, order); }- 这个函数可以保证分配到的物理内存是连续的。需要注意的是,如果是从低端内存分配出来的内存,在内核空间可以利用page_address()很容易的获取其对应的虚拟地址,但是如果是从高端内存区分配的内存,如果要在内核空间访问的话,需要先用kmap这样的函数将其映射到kmap区,然后才能访问。
- 但是对于remap_pfn_range来说就不用担心,只要保证要映射的size大小的空间对应物理地址是连续的就可以,alloc_pages可以满足。
- 为了简便,在调用alloc_pages的时候可以将gfp_mask设置为GFP_KERNEL,这样可以保证从低端内存区分配连续的物理页帧。
-
驱动文件代码——remap_pfn_alloc_pages.c
//省略了与5.1节所示代码不变的部分 #define BUF_SIZE (32*PAGE_SIZE) static struct page *start_page;static int remap_pfn_mmap(struct file *file, struct vm_area_struct *vma) {unsigned long offset = vma->vm_pgoff << PAGE_SHIFT;//page_to_pfn将start_page指向的struct page结构体转换为对应的物理页帧号unsigned long pfn_start = page_to_pfn(start_page) + vma->vm_pgoff; /**page_address利用start_page指向的struct page结构体得到其在内核空间的虚拟地址,*因为是从低端内存分配的,所以可以返回正确的虚拟地址。如果使用高端内存分配的,*并且没有用kmap这样的函数映射到内核空间的话,page_address返回NULL*/unsigned long virt_start = (unsigned long)page_address(start_page);unsigned long size = vma->vm_end - vma->vm_start;int ret = 0;printk("phy: 0x%lx, offset: 0x%lx, size: 0x%lx\n", pfn_start << PAGE_SHIFT, offset, size);//调用remap_pfn_range将物理内存映射到用户空间ret = remap_pfn_range(vma, vma->vm_start, pfn_start, size, vma->vm_page_prot);if (ret)printk("%s: remap_pfn_range failed at [0x%lx 0x%lx]\n",__func__, vma->vm_start, vma->vm_end);elseprintk("%s: map 0x%lx to 0x%lx, size: 0x%lx\n", __func__, virt_start,vma->vm_start, size);return ret; }static int __init remap_pfn_init(void) {int ret = 0;//分配32个页(128KB),函数get_order计算可以存放下BUF_SIZE的最小阶数start_page = alloc_pages(GFP_KERNEL, get_order(BUF_SIZE));if (!start_page) {ret = -ENOMEM;goto err;}ret = misc_register(&remap_pfn_misc);if (unlikely(ret)) {pr_err("failed to register misc device!\n");goto err;}return 0;err:return ret; }static void __exit remap_pfn_exit(void) {misc_deregister(&remap_pfn_misc);__free_pages(start_page, get_order(BUF_SIZE)); //释放内核申请的32个页 }
5.3 利用vmalloc实现
vmalloc比较特殊,它分配的内存虚拟地址是连续的,但是不保证物理页帧也连续,这里不保证的意思是也可能是连续的。因为vmalloc在分配内存时是调用alloc_page一页一页的分配,就是每次从伙伴系统只分配一页,然后将分配得到的单页物理页帧映射到内核的vmalloc区连续的虚拟地址上。比如:我想用vmalloc分配128KB的内存,vmalloc计算发现需要分配32个page,然后会调用32次alloc_page(),每次从伙伴系统分配1个page,每分配一个page就将该page映射到准备好的连续的虚拟地址上,当然也就无法保证这些page之间对应的物理页帧的连续性。所以,在调用remap_pfn_range的时候就需要注意,必须一页一页地映射。
-
驱动文件代码——remap_pfn_vmalloc.c
//省略了与5.1节所示代码不变的部分#define BUF_SIZE (32*PAGE_SIZE) static void *kbuff;static int remap_pfn_mmap(struct file *file, struct vm_area_struct *vma) {unsigned long offset = vma->vm_pgoff << PAGE_SHIFT;//计算内核缓冲区中将要被映射到用户空间的位置的虚拟起始地址virt_startunsigned long virt_start = (unsigned long)kbuff + (unsigned long)(vma->vm_pgoff << PAGE_SHIFT);//调用vmalloc_to_pfn将由vmalloc分配的虚拟地址转换为对应的物理页帧号unsigned long pfn_start = (unsigned long)vmalloc_to_pfn((void *)virt_start);unsigned long size = vma->vm_end - vma->vm_start;int ret = 0;unsigned long vmstart = vma->vm_start;int i = 0;printk("phy: 0x%lx, offset: 0x%lx, size: 0x%lx\n", pfn_start << PAGE_SHIFT, offset, size);//循环调用remap_pfn_range,每次映射PAGE_SIZE,即4KB,每映射完一页,都要计算下一个虚拟地址对应的物理页帧号。while (size > 0) {ret = remap_pfn_range(vma, vmstart, pfn_start, PAGE_SIZE, vma->vm_page_prot);if (ret) {printk("%s: remap_pfn_range failed at [0x%lx 0x%lx]\n",__func__, vmstart, vmstart + PAGE_SIZE);ret = -ENOMEM;goto err;} elseprintk("%s: map 0x%lx (0x%lx) to 0x%lx , size: 0x%lx, number: %d\n", __func__, virt_start,pfn_start << PAGE_SHIFT, vmstart, PAGE_SIZE, ++i);if (size <= PAGE_SIZE)size = 0;else {size -= PAGE_SIZE;vmstart += PAGE_SIZE;virt_start += PAGE_SIZE;pfn_start = vmalloc_to_pfn((void *)virt_start);}}return 0; err:return ret; }static int __init remap_pfn_init(void) {int ret = 0;kbuff = vmalloc(BUF_SIZE); //分配128KB的空间if (!kbuff) {ret = -ENOMEM;goto err;}ret = misc_register(&remap_pfn_misc);if (unlikely(ret)) {pr_err("failed to register misc device!\n");goto err;}return 0; err:return ret; }static void __exit remap_pfn_exit(void) {misc_deregister(&remap_pfn_misc);vfree(kbuff); }-
测试文件——user_3.c
#include <stdio.h> #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> #include <sys/mman.h> #include <unistd.h> #include <stdlib.h> #include <string.h>#define PAGE_SIZE (4*1024) #define BUF_SIZE (32*PAGE_SIZE) #define OFFSET (0)int main(int argc, const char *argv[]) {int fd;char *addr = NULL;int *brk;fd = open("/dev/remap_pfn", O_RDWR);if (fd < 0) {perror("open failed\n");exit(-1);}addr = mmap(NULL, BUF_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_LOCKED, fd, 0);if (!addr) {perror("mmap failed\n");exit(-1);}memset(addr, 0x0, BUF_SIZE);printf("Clear Finished\n");while(1)sleep(1);return 0; } -
运行结果
# 运行user_3,可以得到如下的内核log#./user_3& #kmesg [11712.435630] client: user_3 (874) [11712.435741] code section: [0x8000 0x8828] [11712.435839] data section: [0x10828 0x10964] [11712.435936] brk section: s: 0x11000, c: 0x11000 [11712.436042] mmap section: s: 0xb6f1b000 [11712.436131] stack section: s: 0xbefc6e20 [11712.436256] arg section: [0xbefc6f23 0xbefc6f2c] [11712.436378] env section: [0xbefc6f2c 0xbefc6ff3] [11712.436603] phy: 0x9fdf8000, offset: 0x0, size: 0x20000 [11712.436767] remap_pfn_mmap: map 0xf1443000 (0x9fdf8000) to 0xb6d69000 , size: 0x1000, number: 1 [11712.436991] remap_pfn_mmap: map 0xf1444000 (0x9fdf7000) to 0xb6d6a000 , size: 0x1000, number: 2 [11712.437210] remap_pfn_mmap: map 0xf1445000 (0x9fdf6000) to 0xb6d6b000 , size: 0x1000, number: 3 [11712.437429] remap_pfn_mmap: map 0xf1446000 (0x9fdf5000) to 0xb6d6c000 , size: 0x1000, number: 4 [11712.437647] remap_pfn_mmap: map 0xf1447000 (0x9fdf4000) to 0xb6d6d000 , size: 0x1000, number: 5 [11712.437862] remap_pfn_mmap: map 0xf1448000 (0x9fdf3000) to 0xb6d6e000 , size: 0x1000, number: 6 [11712.438086] remap_pfn_mmap: map 0xf1449000 (0x9fdf2000) to 0xb6d6f000 , size: 0x1000, number: 7 [11712.438305] remap_pfn_mmap: map 0xf144a000 (0x9fdf1000) to 0xb6d70000 , size: 0x1000, number: 8 [11712.438535] remap_pfn_mmap: map 0xf144b000 (0x9fdf0000) to 0xb6d71000 , size: 0x1000, number: 9 [11712.438752] remap_pfn_mmap: map 0xf144c000 (0x9fdef000) to 0xb6d72000 , size: 0x1000, number: 10 [11712.438966] remap_pfn_mmap: map 0xf144d000 (0x9fdee000) to 0xb6d73000 , size: 0x1000, number: 11 [11712.439198] remap_pfn_mmap: map 0xf144e000 (0x9fded000) to 0xb6d74000 , size: 0x1000, number: 12 [11712.439404] remap_pfn_mmap: map 0xf144f000 (0x9fdec000) to 0xb6d75000 , size: 0x1000, number: 13 [11712.440003] remap_pfn_mmap: map 0xf1450000 (0x9fdeb000) to 0xb6d76000 , size: 0x1000, number: 14 [11712.440145] remap_pfn_mmap: map 0xf1451000 (0x9fdea000) to 0xb6d77000 , size: 0x1000, number: 15 [11712.440319] remap_pfn_mmap: map 0xf1452000 (0x9fde9000) to 0xb6d78000 , size: 0x1000, number: 16 [11712.440499] remap_pfn_mmap: map 0xf1453000 (0x9fde8000) to 0xb6d79000 , size: 0x1000, number: 17 [11712.440680] remap_pfn_mmap: map 0xf1454000 (0x9fde7000) to 0xb6d7a000 , size: 0x1000, number: 18 [11712.440862] remap_pfn_mmap: map 0xf1455000 (0x9fde6000) to 0xb6d7b000 , size: 0x1000, number: 19 [11712.441065] remap_pfn_mmap: map 0xf1456000 (0x9fde5000) to 0xb6d7c000 , size: 0x1000, number: 20 [11712.441520] remap_pfn_mmap: map 0xf1457000 (0x9fde4000) to 0xb6d7d000 , size: 0x1000, number: 21 [11712.441819] remap_pfn_mmap: map 0xf1458000 (0x9fde3000) to 0xb6d7e000 , size: 0x1000, number: 22 [11712.442001] remap_pfn_mmap: map 0xf1459000 (0x9fde2000) to 0xb6d7f000 , size: 0x1000, number: 23 [11712.442182] remap_pfn_mmap: map 0xf145a000 (0x9fde1000) to 0xb6d80000 , size: 0x1000, number: 24 [11712.442370] remap_pfn_mmap: map 0xf145b000 (0x9fde0000) to 0xb6d81000 , size: 0x1000, number: 25 [11712.442558] remap_pfn_mmap: map 0xf145c000 (0x9fc0c000) to 0xb6d82000 , size: 0x1000, number: 26 [11712.442749] remap_pfn_mmap: map 0xf145d000 (0x9fc0d000) to 0xb6d83000 , size: 0x1000, number: 27 [11712.442944] remap_pfn_mmap: map 0xf145e000 (0x9fdc5000) to 0xb6d84000 , size: 0x1000, number: 28 [11712.443171] remap_pfn_mmap: map 0xf145f000 (0x9fdf9000) to 0xb6d85000 , size: 0x1000, number: 29 [11712.443355] remap_pfn_mmap: map 0xf1460000 (0x9fdfa000) to 0xb6d86000 , size: 0x1000, number: 30 [11712.443534] remap_pfn_mmap: map 0xf1461000 (0x9fdfb000) to 0xb6d87000 , size: 0x1000, number: 31 [11712.443711] remap_pfn_mmap: map 0xf1462000 (0x9fdfc000) to 0xb6d88000 , size: 0x1000, number: 32- 可以看到,remap_pfn_mma被循环调用了32次,每次映射4KB。
- 也可以看到每次映射的物理页帧之间有可能是连续的,也有可能不是连续的,具体跟当前系统中内存的碎片化程度有关,碎片化程度越高,上面的物理页帧之间的连续性也就越差。
- 可以看到,vmalloc分配的内存的地址都落在了高端内存区的vmalloc区,而且虚拟地址都是连续的,用户的vma的虚拟内存区域地址也是连续的,只有物理内存不一定连续。比如下面几行
-
5、remap_pfn_range的实现分析
-
代码位于<mm/memory.c>
int remap_pfn_range(struct vm_area_struct *vma, unsigned long addr,unsigned long pfn, unsigned long size, pgprot_t prot) {pgd_t *pgd;unsigned long next;unsigned long end = addr + PAGE_ALIGN(size); //计算本次映射的结尾虚拟地址struct mm_struct *mm = vma->vm_mm;int err;/** Physically remapped pages are special. Tell the rest of the world about it:* VM_IO tells people not to look at these pages (accesses can have side effects).* VM_RESERVED is specified all over the place, because in 2.4 it kept swapout's vma scan off this vma; * but in 2.6 the LRU scan won't even find its pages, so this flag means no more than count its pages in reserved_vm,* and omit it from core dump, even when VM_IO turned off.* VM_PFNMAP tells the core MM that the base pages are just raw PFN mappings, * and do not have a "struct page" associated with them.** There's a horrible special case to handle copy-on-write behaviour that some programs depend on.* We mark the "original" un-COW'ed pages by matching them up with "vma->vm_pgoff".*/if (is_cow_mapping(vma->vm_flags)) {if (addr != vma->vm_start || end != vma->vm_end)return -EINVAL;vma->vm_pgoff = pfn;}vma->vm_flags |= VM_IO | VM_RESERVED | VM_PFNMAP;BUG_ON(addr >= end);pfn -= addr >> PAGE_SHIFT;pgd = pgd_offset(mm, addr); //计算addr在第1级页表中对应的页表项的地址,pgd_offset宏展开为mm->pgd + (addr >>21)flush_cache_range(vma, addr, end); //刷新cachedo {next = pgd_addr_end(addr, end); //计算下一个被映射的虚拟地址,如果addr到end可被一个pgd映射的话,则返回end的值err = remap_pud_range(mm, pgd, addr, next, pfn + (addr >> PAGE_SHIFT), prot); //函数定义如下if (err)break;} while (pgd++, addr = next, addr != end);return err; }||\/ static inline int remap_pud_range(struct mm_struct *mm, pgd_t *pgd,unsigned long addr, unsigned long end,unsigned long pfn, pgprot_t prot) {pud_t *pud;unsigned long next;pfn -= addr >> PAGE_SHIFT;pud = pud_alloc(mm, pgd, addr); //对于2级页表,pud_alloc(mm, pgd, addr)返回的是pgd的值if (!pud)return -ENOMEM;do {next = pud_addr_end(addr, end); //对于2级页表,pud_addr_end(addr, end)返回end的值if (remap_pmd_range(mm, pud, addr, next, //函数定义如下pfn + (addr >> PAGE_SHIFT), prot))return -ENOMEM;} while (pud++, addr = next, addr != end);return 0; }||\/ static inline int remap_pmd_range(struct mm_struct *mm, pud_t *pud,unsigned long addr, unsigned long end,unsigned long pfn, pgprot_t prot) {pmd_t *pmd;unsigned long next;pfn -= addr >> PAGE_SHIFT;pmd = pmd_alloc(mm, pud, addr); //对于2级页表,pmd_alloc(mm, pud, addr)返回的是pud的值,其实也就是pgd的值if (!pmd)return -ENOMEM;VM_BUG_ON(pmd_trans_huge(*pmd));do {next = pmd_addr_end(addr, end); //对于2级页表,pmd_addr_end(addr, end)返回end的值if (remap_pte_range(mm, pmd, addr, next, //函数remap_pte_range定义如下pfn + (addr >> PAGE_SHIFT), prot))return -ENOMEM;} while (pmd++, addr = next, addr != end);return 0; }||\/ static int remap_pte_range(struct mm_struct *mm, pmd_t *pmd,unsigned long addr, unsigned long end,unsigned long pfn, pgprot_t prot) {pte_t *pte;spinlock_t *ptl;pte = pte_alloc_map_lock(mm, pmd, addr, &ptl); //pte_alloc_map_lock的定义如下if (!pte)return -ENOMEM;arch_enter_lazy_mmu_mode();do {BUG_ON(!pte_none(*pte));//调用pte_mkspecial构造第2级页表项的内容,函数set_pte_at用于将表项内容设置到pte指向的第2级页表项中set_pte_at(mm, addr, pte, pte_mkspecial(pfn_pte(pfn, prot)));pfn++; //计算下一个将要被映射的物理页帧号} while (pte++, addr += PAGE_SIZE, addr != end); //计算第2级页表项中下一个将要被填充的表项的地址arch_leave_lazy_mmu_mode();pte_unmap_unlock(pte - 1, ptl);return 0; }||\/ /** pte_alloc首先检查*pmd是否为空,如果为空的话,表示第2级页表还尚未分配,那么调用__pte_alloc分配一个页*(其实是调用alloc_pages分配了一个page,也就是4KB),并将起始地址存放的*pmd中,其实就是*pgd。* 如果不出意外的话,pte_alloc返回0,这样pte_offset_map_lock就会被调用,返回address在第2级页表中的表项的地址*/ #define pte_alloc_map_lock(mm, pmd, address, ptlp) \(pte_alloc(mm, pmd, address) ? \NULL : pte_offset_map_lock(mm, pmd, address, ptlp)) -
【参考文章列表】:
- LDD3
- Linux驱动mmap内存映射
- 内存映射函数remap_pfn_range学习









![[Unity] 获取UI组件的屏幕坐标(打包手机端使用前置摄像头)](https://img-blog.csdnimg.cn/223afd5653bc43bbaffaf45e7d715532.png)