目录
一、什么是归并排序?
二、归并排序
三、什么是基数排序?
四、基数排序
五、各种排序的比较
一、什么是归并排序?
归并排序是建立在归并操作上的一种有效,稳定的排序算法。是将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
二、归并排序
1 . 概述
-
归并排序,Merging Sort
-
归并排序:将两个或两个以上的有序表合并成一个新的有序表。
-
归并排序分类:
1. 二路归并排序
2. 多路归并排序
-
二路归并排序:将两个有序表合并成一个有序表的归并排序,称为二路归并排序。也就是将两个相邻的记录有序子序列归并为一个记录的有序序列。
-
二路归并排序基本思想:
1. 将待排序记录r[0]到r[n-1]看成是n个长度为1的有序子表
2. 把这些子表依次两两归并,便得到[n/2]个有序子表
3. 然后,再把这[n/2]个有序的子表进行两两归并
4. 如此重复,直到最后得到一个长度为n的有序表为止
2 .两个相邻有序序列归并:分析
假设前后两个有序序列分别存放在一维数组人的r[h..m] 和 r[m+1..t]中,同时,提供另一个有序数组order,用于存放归并后的数据
首先在两个有序序列中,分别从第1个记录开始进行对应关键字的比较,将关键字值较小的记录放入有序数据order中
然后,依次对两个有序序列中剩余记录进行相同操作,直到两个有序序列中的所有记录都加入到有序数组order中为止
最后,这个有序数组order中存放的记录序列就是归并排序后的结果。

3. 两个相邻有序序列归并:算法
-
代码
/**** @param r 待排序的数组(多个有序子序列)* @param order 已经排序号的数组* @param h 第一个子序列开始的位置* @param m 第一个子序列结束的位置,第二个子序列开始的位置为m+1* @param t 第二个子序列结束的位置*/ //【算法】两个有序序列的归并算法 //把r数组中两个相邻的有序表r[h]~r[m]和r[m+1]~r[t]归并为一个有序表order[h]~order[t] public void merge(RecordNode[] r, RecordNode[] order, int h, int m, int t) {int i = h, j = m + 1, k = h;while (i <= m && j <= t) { // 将r中两个相邻子序列归并到order中if (r[i].key.compareTo(r[j].key) <= 0) {// 较小值复制到order中order[k++] = r[i++];} else {order[k++] = r[j++];}}while (i <= m) { // 将前一个子序列剩余元素复制到order中order[k++] = r[i++];}while (j <= t) { // 将后一个子序列剩余元素复制到order中order[k++] = r[j++];} } - 测试
public class TestSeqList13_merge {public static void main(String[] args) throws Exception {int[] arr = {39,52,67,95,8,25,56,70};SeqList seqList = new SeqList(arr.length);System.out.print("序列号:");for (int i = 0; i < arr.length; i++) {System.out.print(" " + i);seqList.insert(i, new RecordNode(arr[i]));}System.out.println();System.out.print("归并前:");seqList.display();// 归并操作System.out.print("归并后:");RecordNode[] temp = new RecordNode[arr.length];// 待归并的数据 {39,52,67,95}和 {8,25,56,70}seqList.merge(seqList.r,temp,0,3, 7);// 输出归并后的数据for (int i = 0; i < temp.length; i++) {String str = temp[i].key.toString().length() == 1 ? " " : " ";System.out.print(str + temp[i].key.toString());}System.out.println();}
}
//归并操作
//序列号: 0 1 2 3 4 5 6 7
//归并前: 39 52 67 95 8 25 56 70
//归并后: 8 25 39 52 56 67 70 954. 一趟归并:分析
-
假设r为待排序的数组,n为待排序列的长度,s为待归并的有序子序列的长度,一趟归并排序的结果存放在数组order中。
-
两个相邻的有序序列,第一趟处理的长度为1,第二趟为2,第三趟为4 ... ,也就是说s的取值1/2/4/8...
-
步骤:
-
根据长度s,进行两两归并
-
归并操作时,如果最后两个序列长度不等,将剩余内容归并到有序表中
-
归并操作时,如果有未参加归并操作的内容,直接复制到order中
-
5. 一趟归并:算法
-
代码
//【算法】一趟归并算法 //把数组r[n]中每个长度为s的有序表两两归并到数组order[n]中 //s 为子序列的长度,n为排序序列的长度 public void mergepass(RecordNode[] r, RecordNode[] order, int s, int n) {System.out.print("子序列长度s=" + s + " ");int p = 0; //p为每一对待合并表的第一个元素的下标,初值为0while (p + 2 * s - 1 <= n - 1) { //两两归并长度均为s的有序表merge(r, order, p, p + s - 1, p + 2 * s - 1);p += 2 * s;}if (p + s - 1 < n - 1) { //归并最后两个长度不等的有序表merge(r, order, p, p + s - 1, n - 1);} else {for (int i = p; i <= n - 1; i++) //将剩余的有序表复制到order中{order[i] = r[i];}} }
测试:s=1
public class TestSeqList14_mergepass {public static void main(String[] args) throws Exception {int[] arr = {52,39,67,95,70,8,25,52,56};SeqList seqList = new SeqList(arr.length);System.out.print("序列号:\t\t ");for (int i = 0; i < arr.length; i++) {System.out.print(" " + i);seqList.insert(i, new RecordNode(arr[i]));}System.out.println();System.out.print("初始值:\t\t ");seqList.display();// 一趟归并算法RecordNode[] temp = new RecordNode[arr.length];int s = 1;seqList.mergepass(seqList.r, temp, s, arr.length);for (int i = 0; i < temp.length; i++) {String str = temp[i].key.toString().length() == 1 ? " " : " ";System.out.print(str + temp[i].key.toString());}System.out.println();
}
}
//一趟归并算法
//序列号: 0 1 2 3 4 5 6 7 8
//初始值: 52 39 67 95 70 8 25 52 56
//子序列长度s=1 39 52 67 95 8 70 25 52 56- 测试:s=8
public class TestSeqList14_mergepass2 {public static void main(String[] args) throws Exception {int[] arr = {8,25,39,52,52,67,70,95,56};SeqList seqList = new SeqList(arr.length);System.out.print("序列号:\t\t ");for (int i = 0; i < arr.length; i++) {System.out.print(" " + i);seqList.insert(i, new RecordNode(arr[i]));}System.out.println();System.out.print("初始值:\t\t ");seqList.display();// 一趟归并算法RecordNode[] temp = new RecordNode[arr.length];int s = 8;seqList.mergepass(seqList.r, temp, s, arr.length);for (int i = 0; i < temp.length; i++) {String str = temp[i].key.toString().length() == 1 ? " " : " ";System.out.print(str + temp[i].key.toString());}System.out.println();
}
}
//一趟归并算法
//序列号: 0 1 2 3 4 5 6 7 8
//初始值: 8 25 39 52 52 67 70 95 56
//子序列长度s=8 8 25 39 52 52 56 67 70 956 二路归并:分析
设置待排序的n个记录保存在数组r[n]中,归并过程中需要引入辅助数组temp[n],
第1趟由r归并到temp,第2趟由temp归并到r
如此反复,直到n个记录成为一个有序表为止。
在归并过程中,为了将最后的排序结果仍置于数组中,需要进行的归并趟数为偶数,
如果实际上只需奇数趟即可生成,那么最后还要进行一趟,正好此时temp中的n个有序记录,为一个长度不大于s的表,将会背直接复制r。
7. 二路归并: 算法
-
添加打印方法
public void display(RecordNode[] arr) { //输出数组元素for (int i = 0; i < arr.length; i++) {String str = arr[i].key.toString().length() == 1 ? " " : " ";System.out.print(str + arr[i].key.toString());}System.out.println(); } -
算法代码
//【算法】2-路归并排序算法 public void mergeSort() {System.out.println("归并排序");int s = 1; // s为已排序的子序列长度,初值为1int n = this.curlen;RecordNode[] temp = new RecordNode[n]; // 定义长度为n的辅助数组tempwhile (s < n) {mergepass(r, temp, s, n); // 一趟归并,将r数组中各子序列归并到temp中display(temp); // 打印temp临时数组s *= 2; // 子序列长度加倍,下一趟归并mergepass(temp, r, s, n); // 将temp数组中各子序列再归并到r中display(); // 打印r数组s *= 2;} } - 测试
public class TestSeqList15_mergeSort {public static void main(String[] args) throws Exception {int[] arr = {52,39,67,95,70,8,25,52,56};SeqList seqList = new SeqList(arr.length);System.out.print("序列号:\t\t ");for (int i = 0; i < arr.length; i++) {System.out.print(" " + i);seqList.insert(i, new RecordNode(arr[i]));}System.out.println();System.out.print("初始值:\t\t ");seqList.display();// 二路归并算法seqList.mergeSort();
}
}
//二路归并算法
//序列号: 0 1 2 3 4 5 6 7 8
//初始值: 52 39 67 95 70 8 25 52 56
//归并排序
//子序列长度s=1 39 52 67 95 8 70 25 52 56
//子序列长度s=2 39 52 67 95 8 25 52 70 56
//子序列长度s=4 8 25 39 52 52 67 70 95 56
//子序列长度s=8 8 25 39 52 52 56 67 70 958. 性能分析
-
时间复杂度:
1. 归并趟数:log2n
2. 每一趟时间复杂度:O(n)
3. 二路归并排序:O(nlog2n)
-
空间复杂度:O(n)
-
二路归并是一个==稳定==的排序算法
三、什么是基数排序?
基数排序(radix sort)属于“分配式排序”(distribution sort),又称“桶子法”(bucket sort)或bin sort。它是透过键值的部份资讯,将要排序的元素分配至某些“桶”中,藉以达到排序的作用,基数排序法是属于稳定性的排序,其时间复杂度为O (nlog(r)m),其中r为所采取的基数,而m为堆数,在某些时候,基数排序法的效率高于其它的稳定性排序法。
四、基数排序
1 概述
-
基数排序(Radix Sort):是一种借助于多关键字进行排序,也就是一种将单关键字按基数分成“多关键字”进行排序的方法。
-
基数排序分类:
-
多关键字排序
-
链式基数排序
-
2 多关键字排序
-
n个记录的序列 {R1, R2, ... , Rn}对关键字(k1, k2, ... , kd)有序。
-
就是说,对于序列中任意两个记录Ri和Rj (1≤i<j≤n) 都满足下列有序关系:
(ki1, ki2, ... , kid) < (kj1, kj2, ... , kjd)
1. K1称为最主位关键字
2. Kd称为最主位关键字
-
多关键字排序按照关键字的顺序分为两种方式:
1. 最主位优先MSD法:先对K1进行分组,同一组中记录,若关键字K1相等,再对各组按K2排序分成子组,... , 至最后对最次位关键字排序完成为止。
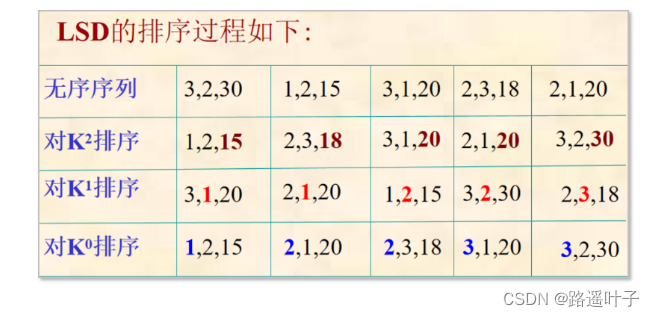
2. 最次为优先LSD法:先对Kd进行排序,然后对Kd-1进行排序,依次类推,直至对主要位关键字K1排序完成为止。(排序过程中不需要根据“前一个”关键字的排序结果,将记录序列分隔成若干个子序列)
-
例如:学生记录含三个关键字,
系别、班号和班内的序列号,其中以系别为最主位关键字。
3. 链式基数排序
-
假如多关键字的记录序列中,每个关键字的取值范围相同,则按LSD法进行排序时,可以采用“分配-收集”的方法,其好处是不需要进行关键字间的比较。
-
对于数字型或字符型的单关键字,可以看成是由多个数位或多个字符构成的多关键字,此时可以采用这种“分配-收集”的办法进行排序,称为基数排序法。
-
例如:关键字如下{209, 386, 768, 185, 247, 606, 230, 834, 539}
1. 首先按其
个位数取值分别为0,1,...9分配成10组,之后按从0至9的顺序将他们收集在一起2. 然后按其
十位数取值分别为0,1,...9分配成10组,之后再按从0至9的顺序将他们收集在一起3. 最后按其
百位数重复一遍上述操作 -
在计算机上实现基数排序时,为减少所需辅助存储空间,应采用链表作存储结构,即链式基数排序,具体操作:
1. 待排序记录以指针相链,构成一个链表
2. 分配时,按当前关键字位所取值,将记录分配到不同的链队列中,每个队列中记录的关键字位相同3. 收集时,按当前关键字位取值从小到大将各队列首尾相链成一个链表4. 对每个关键字位均 重复2)和3)两步
例如:


注意:
-
分配和收集的实际操作仅为修改链表中的指针和设置队列的头、尾指针
-
为查找使用,该链表尚需将它调整为有序表。
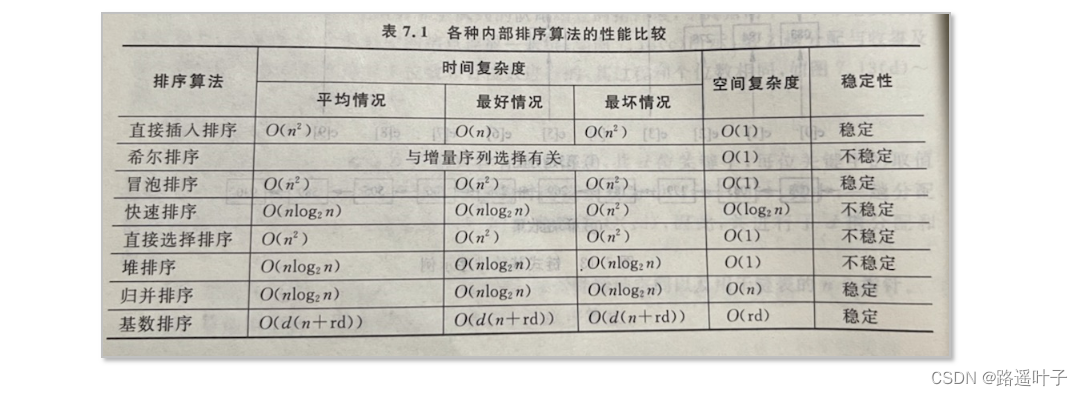
五、各种排序的比较
写到最后
四季轮换,已经数不清凋零了多少, 愿我们往后能向心而行,一路招摇胜!
🐋 你的支持认可是我创作的动力
💟 创作不易,不妨点赞💚评论❤️收藏💙一下
😘 感谢大佬们的支持,欢迎各位前来不吝赐教