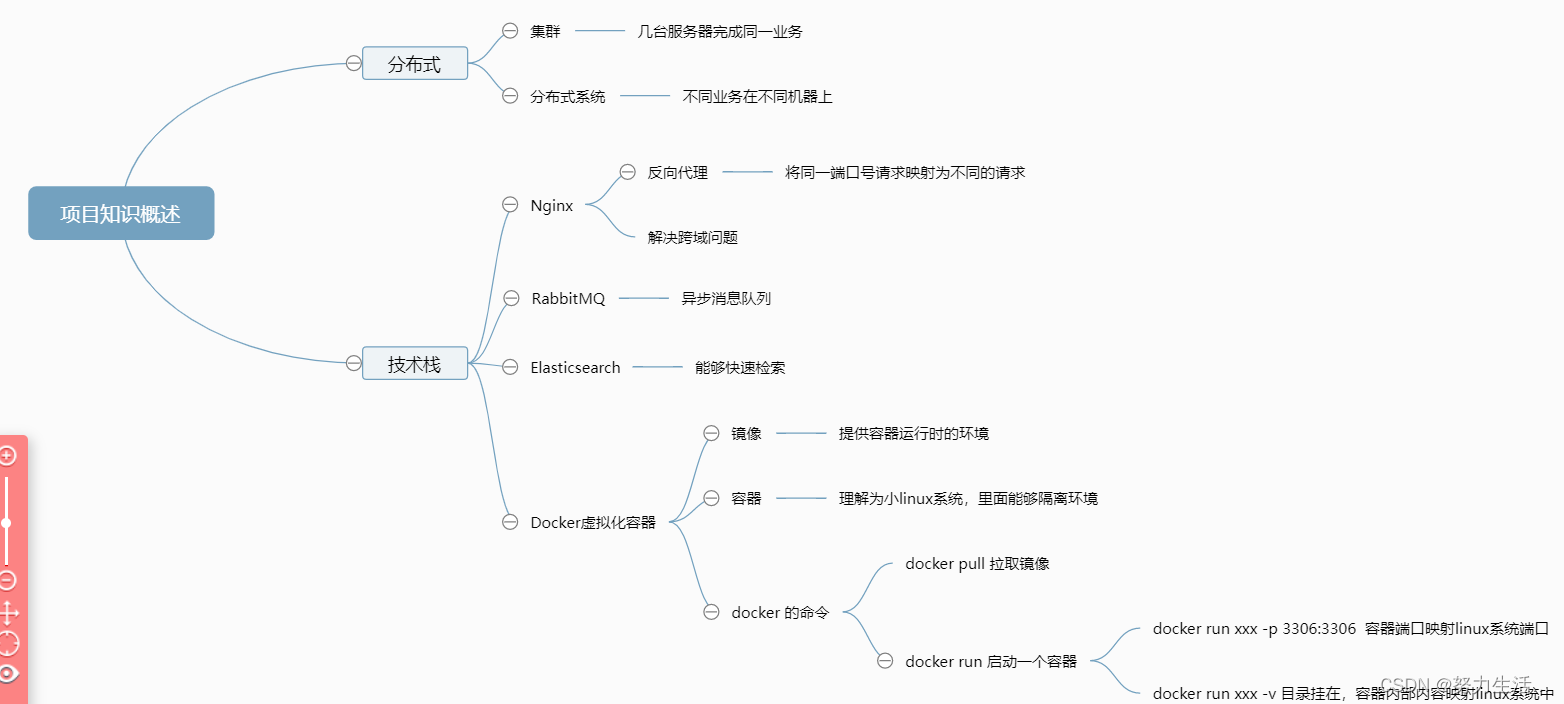
音乐按文件名拼音进行排序
- 参考网站
- ATJ2157&ATJ2127 排序是按照内码(汉字为GBK即GBK936)排序的
- 按拼音排序
- unicode与拼音的对比表(U2P.DAT),需要打包到固件中
- U2P.DAT数据结构
- U2P.DAT生成代码是使用DEV-C++生成
- 其他说明
- U2P.DAT与ATJ2127平台代码
参考网站
各种字符对应表:http://www.kanji.zinbun.kyoto-u.ac.jp/~yasuoka/CJK.html
方法思路:https://blog.csdn.net/firehood_/article/details/7648625
ATJ2157&ATJ2127 排序是按照内码(汉字为GBK即GBK936)排序的
GBK936是对GB2312编码的扩充,对汉字采用双字节编码。GBK字符集共收录21003个汉字,包含国家标准GB13000-1中的全部中日韩汉字,和BIG5编码中的所有汉字GB2312标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个同时,
GB2312收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符
GB2312中对所收汉字进行了“分区”处理,每区含有94个汉字/符号。这种表示方式也称为区位码。
• 01-09区为特殊符号。
• 16-55区为一级汉字,按拼音排序。
• 56-87区为二级汉字,按部首/笔画排序。
• 10-15区及88-94区则未有编码
按拼音排序
要达到这个要求,必须要获取相应的拼音进行对比,或者排好序的对应关系。
为了达到编码了统一性,首先把内码转换为unicode码,然后根据unicode码获取拼音,然后比较。这就要求有一个unicode与拼音的对比表(U2P.DAT)
unicode与拼音的对比表(U2P.DAT),需要打包到固件中
U2P.DAT是根据Uni2Pinyin.Z生成的
在这个http://www.kanji.zinbun.kyoto-u.ac.jp/~yasuoka/CJK.html网站上可以找到Uni2Pinyin.Z
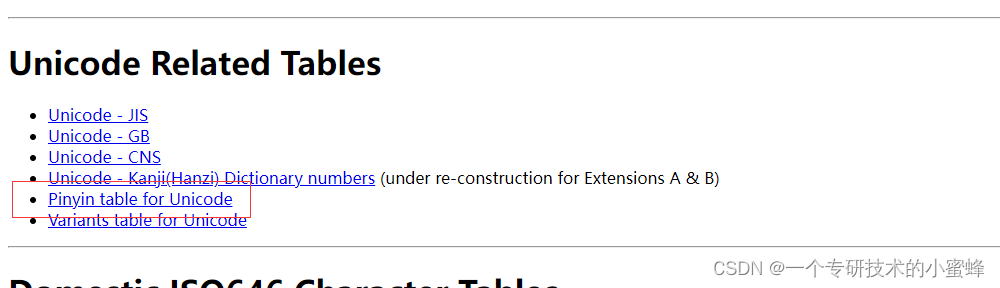
U2P.DAT数据结构
每一个unicode占32个字符,汉字编码为A对应在文件中的位置为(A-0x4e00)*32

U2P.DAT生成代码是使用DEV-C++生成
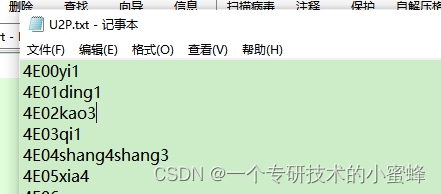
程序的输入文件是U2P.txt
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
/* run this program using the console pauser or add your own getch, system("pause") or input loop */int char_to_number(unsigned char *buffer)
{int data;
// printf("buffer[3] = %X\n",buffer[3]);if ((buffer[0] >= 0x30) && (buffer[0] <= 0x39)){data = (buffer[0] - 0x30 ) * 0x1000;}else {data = (buffer[0] - 0x37 ) * 0x1000;}
//
// printf("data = %X\n",data);
//
// printf("buffer[4] = %X\n",buffer[4]);if ((buffer[1] >= 0x30) && (buffer[1] <= 0x39)){data |= (buffer[1] - 0x30 ) * 0x100;}else {data |= (buffer[1] - 0x37 ) * 0x100;}// printf("data = %X\n",data);
//
// printf("buffer[5] = %X\n",buffer[5]);if ((buffer[2] >= 0x30) && (buffer[2] <= 0x39)){data |= (buffer[2] - 0x30 ) * 0x10;}else {data |= (buffer[2] - 0x37 ) * 0x10;}// printf("data = %X\n",data);
// // printf("buffer[6] = %X\n",buffer[6]);if ((buffer[3] >= 0x30) && (buffer[3] <= 0x39)){data |= (buffer[3] - 0x30 ) * 0x1;}else {data |= (buffer[3] - 0x37 ) * 0x1;// printf("abc = %X\n",(buffer[6] - 0x57 ) * 0x1);}// printf("data = %X\n",data);return data;
}int main(int argc, char *argv[]) {unsigned char buffer[32 + 4];int i, j = 0 ;int rdata, wdata = 0;printf("argc = %d\n", argc);/*�ļ���ʽ [0x0616] = 0x0000[0x483f] = 0x0001[0x074a] = 0x0002*/FILE *fp = fopen(argv[1],"r");printf("file name = %s\n",argv[1]);if (NULL == fp){printf("open file error\n");}FILE *fpb = fopen("dec.bin","wb+");i = 0;do{memset(buffer,0,32 + 4);fgets(buffer,32 + 4,fp) ;printf("txt = %s\n",buffer);// return ;
// for (j = 0; j < 32; j++)
// {
//
// printf("buffer[%d] = %X\n",j,buffer[j]);
//
// } rdata = char_to_number(buffer);//wdata = char_to_number(buffer + 10);rdata -= 0x4e00;i++;printf("%x = 0x%04x\n",i,rdata);// return ;//printf("%x = 0x%04x\n",i,wdata);if (rdata < 0){continue;}if (0 != fseek(fpb, rdata * 32 , SEEK_SET)){printf("bin file seek error\n");return ;}wdata = strlen(buffer) - 5;if (0 == fwrite(buffer + 4,wdata,1,fpb)){printf("bin file write fail\n");}} while (i < 0x51AF);fclose(fp);fclose(fpb);printf("size of data = %d\n",sizeof(wdata));return 0;
}其他说明
这个只是针对汉字拼音排序的,当然还有其他的排序方法
如UCA+CLDR排序标准,这个比较全面,就unicode的排序标准,其中就包括汉字拼音的。暂时未研究。
U2P.DAT与ATJ2127平台代码
联系作者获取



![[附源码]计算机毕业设计springboot基于Java的日用品在线电商平台](https://img-blog.csdnimg.cn/0b3e0de816594f41befe507d7aecd354.png)

![[附源码]Python计算机毕业设计Django大学生创新项目管理系统](https://img-blog.csdnimg.cn/7e4d74cc0c1a44c88eaf46e1f9c1dbd7.png)