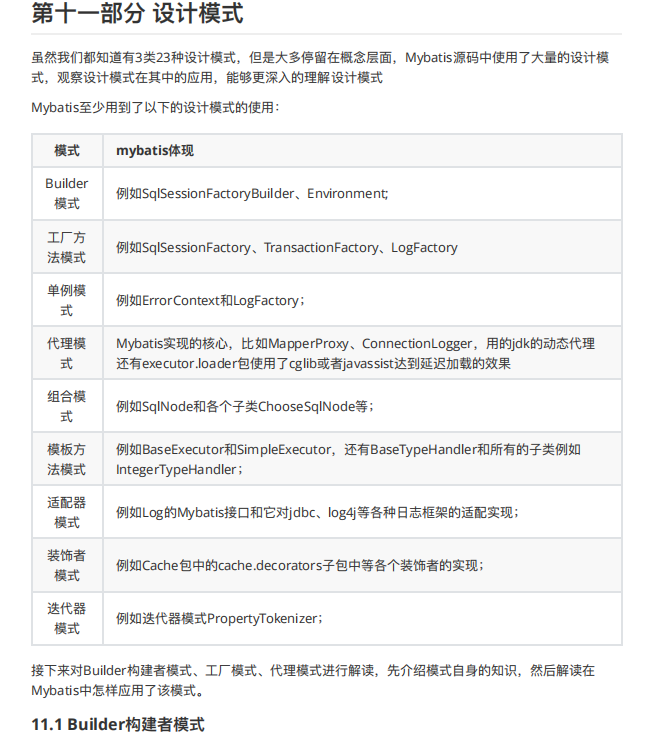
本文由清华大学与腾讯科技有限公司和香港中文大学合作,并 在腾讯公司落地应用 。 说话风格建模对于表现力语音合成具有重要作用。 现有基于参考音频提取风格表征的方法通常利用文本的语义相似度进行参考音频选择,忽略了语义信息和说话风格的差异性。 本文考虑利用天然成对的文本和语音数据互相作为监督,设计了一种 基于 对比学习 的根据文本选取多个参考音频的 风格建模方法CALM , 从文本中捕捉到真正与说话风格相关的特征 。 与基线方法相比, 在中文情感数据集上,所提方法预测的 风格嵌入相似度提升25.3% ,主观意见得分从2.804提升至3.812, 偏好率提升56.7% ; 在英文有声书数据集上,所提方法预测的 风格嵌入相似度提升11.5% ,主观意见得分从3.160提升至3.625, 偏好率提升13.3% 。
扫码阅读论文
https://www.isca-speech.org/archive/interspeech_2022/meng22c_interspeech.html
合成样例试听
https://thuhcsi.github.io/interspeech2022-CALM-tts/
01 背景动机
为了进一步提升语音合成的风格表现力,目前的语音合成系统通常会利用文本预测或者参考音频的方式来建模说话风格。 然而,由于说话风格是由很多声学成分耦合在一起形成的表征,仅从文本信息预测比较困难,导致预测准确度较低; 并且对于同一句文本,可能存在多种合适的说话风格,因此也可能面临一对多的问题,导致预测的说话风格过平滑。
现有的从参考音频提取说话风格的方法,或使用说话人平均的参考音频,或使用语义信息检索参考音频等方法。 固定参考音频或者使用说话人平均的参考音频,都会忽略不同文本所需要的表达方式不同的需求。 利用语义信息检索参考音频时,忽略了语义信息和说话风格的差异性: 语义信息中包含有很多和说话风格无关的信息,例如文本内容的主题等。 同时,由于使用参考音频的方法在训练阶段通常会使用真实(ground-truth)的语音作为参考音频,而推理阶段使用其他参考音频,也会面临训练推理不匹配的问题,导致合成语音中较低的内容质量。
02 贡献
本文设计了一种通过选取多个参考音频对语音合成中的说话风格进行建模的方法,其核心是从文本内容获得合适的文本嵌入表征用于检索参考音频。
本文提出的 基于对比学习的声学-语言学模块 ( CALM ),利用对比学习联合训练两个编码器: 风格编码器(Style Encoder)和语言编码器(Linguistic Encoder),对提取出的文本表征和风格表征进行跨模态的优化,可以更好的对来自文本信息的说话风格进行建模,以及提取出更加和风格相关的文本表征。
在两个数据集上的客观和主观评价指标都表明,本文提出方法能够提升合成的语音说话风格与输入文本的匹配度。 最后,我们分析了参考音频个数对于说话风格的影响,并综合考虑性能与计算复杂度选择了合适的参考音频个数。
03 解决方案
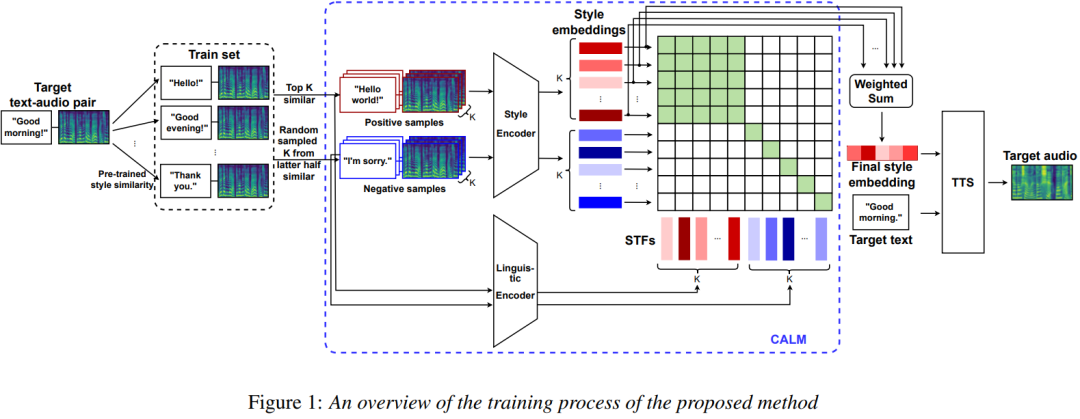
本文提出方法的训练过程如上图1所示,图中蓝色框包围的为 基于对比学习的声学-语言学模块 CALM ,主要包含两个编码器: 风格编码器 (Style Encoder)和 语言编码器 (Linguistic Encoder)。 语音合成模型整体基于Fastspeech 2 框架 ,CALM模块负责进行风格建模。
基于对比学习的声学-语言学模块
(CALM)
我们利用CALM中的语言编码器从文本中提取与风格相关的文本特征,利用风格编码器从语音中提取说话风格嵌入。 CALM将说话风格和文本内容映射到同一嵌入空间中,并且利用对比学习来学习它们的表征。 具体地,CALM会强制那些具有相似风格表征的文本具有更相近的文本表征; 相反,不同说话风格的文本表征则尽可能分散在嵌入空间中。
正负样本的选择
为了进行对比学习的训练,首先需要进行正样本和负样本的选择。 我们先在训练集中训练一个风格编码器,然后利用训练后的风格编码器对每个训练数据集中的语音进行风格嵌入提取,这个风格嵌入将被用于衡量不同样本之间的风格相似度。 如图1左侧所示,对于训练数据集中的每一对(语音,文本),我们将训练集中的所有其他(语音,文本)按照与当前语音的风格嵌入余弦相似度降序排序。 最靠前的K对样本作为当前样本的正样本,随机选择K对排在后1/2的样本作为当前样本的负样本。
CALM训练
如图1中蓝框包围的部分所示,给出2K对(语音,文本)作为输入,CALM会预测一个 2K × 2K 的矩阵 M' ,其中第(i,j)个元素表示第i个文本嵌入与第j条语音的风格嵌入的余弦相似度。 Ground-truth矩阵M则只包含1或-1两个值: 当文本嵌入和风格嵌入都来源于正样本,或来源于同一对负样本时,矩阵值为1; 其他情况则为-1。 通过最小化预测矩阵M'和真实矩阵M之间的均方误差(MSE)来对模型进行优化。
通过这些设置,CALM可以通过联合训练一个风格编码器和一个语言编码器来学习一个多模态嵌入空间,最大化正样本之间嵌入的余弦相似度,最小化负样本之间嵌入的余弦相似度,使得语言编码器能够从文本中提取出与说话风格 最 相关的表征。
04 实验验证
实验数据
本文使用了两个数据集来验证本文提出方法的有效性。 第一个是单说话人的中文情感数据集,包含六种情感(喜、怒、悲、厌、惊、惧)每种1500句,共9000句。 第二个是英文的Blizzard-2013有声书数据集中的四个故事,共9741句。
基线模型
我们复现了Gong等人提出的Multiple Reference TTS (MRTTS)作为基线方法。 MRTTS在训练和推理阶段都使用语义相似度来检索多个参考音频以得到风格表征。
对比实验
为验证本文所提出方法的有效性,我们分别通过客观评测和主观评测对各个模型进行比较。 其中,客观评测在中文情感数据集上以被选择的参考音频的情感类别准确率作为评测标准,在中英两个数据集上都以预测的风格嵌入与真实风格嵌入余弦相似度作为评测标准。 主观评测对合成语音的说话风格和输入文本的匹配程度采用ABX测试和MOS打分。 表1展示了客观实验结果。 表2和表3展示了主观实验结果。
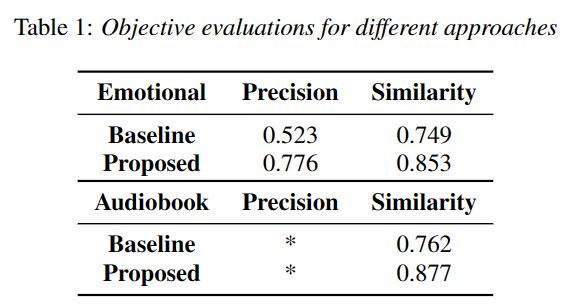
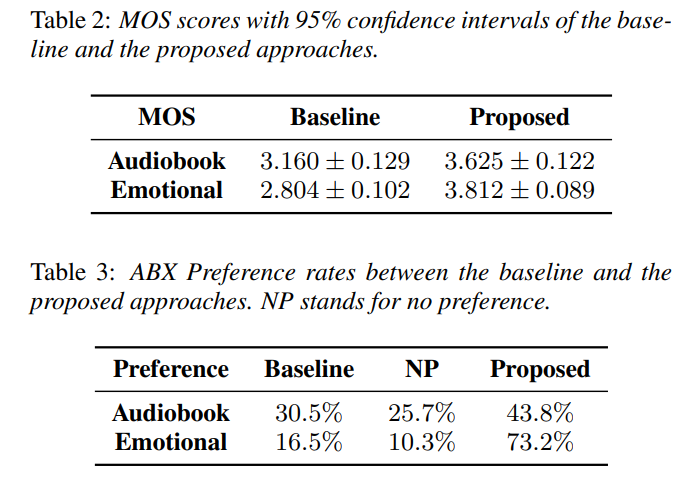
客观评价指标和主观评价指标都表明,我们的模型可以生成比基线更适合输入文本的风格的音频。
参考音频个数N的实验
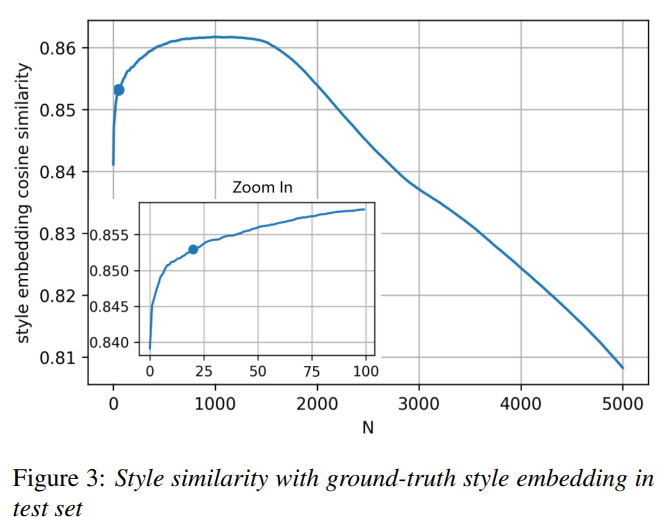
我们在中文情感数据集上观察了参考音频个数N对模型推理时性能的影响。 如图3所示,随着N的增大,预测的风格嵌入与真实风格嵌入的余弦相似度先增大后减小。 转折点出现在N = 1500左右。 在训练集中,每种情感都有1450句。 因此,CALM中的语言编码器提取了与说话风格更相关的文本特征。 说话风格的余弦相似度随着N增加而提高,但同时计算复杂度也随着N增加而提高。 综合考虑到性能和计算复杂度之间的权衡,我们选择N为20,此时相似度的提高开始放缓。
05 结语
本文设计了一种选取多个参考音频对语音合成中的说话风格进行建模的方法,基于对比学习,联合训练两个编码器: 风格编码器和语言编码器,以生成跨模态的表征。 这个跨模态表征在推理阶段会用于检索到风格适合当前输入文本的多个参考音频,多个参考音频的风格嵌入的加权和会作为最终的风格表征。 客观实验表明,在中英两个数据集上,相比基线方法,本文所提出的方法可以提升所预测的风格嵌入与真实风格嵌入之间的余弦相似度。 主观实验表明,在中英两个数据集上,相比基线方法,基于本文所提方法合成的语音说话风格与输入文本更加匹配。