目录
Abstract
1. Introduction
2. MEthod
2.1 Model architecture
2.2 Focal self-attention
2.2.1 Window-wise attention
2.2.2 Complexity analysis
2.3 Model configuration
3. Related work
4. Experiments
4.1 Image classification on ImageNet-1K
4.2 Object detection and instance segmentation
Abstract
最近,Vision Transformer 及其变体在各种计算机视觉任务中表现出了巨大的潜力。通过自注意力捕捉短程和长程视觉依赖的能力是成功的关键。但由于二次方计算开销,它也带来了挑战,特别是对于高分辨率视觉任务(例如,对象检测)。最近的许多工作都试图通过应用粗粒度的全局注意力或细粒度的局部注意力来降低计算和内存成本并提高性能。然而,这两种方法都削弱了多层 Transformer 原始自注意力机制的建模能力,从而导致次优解决方案。在本文中,我们提出了 focal self-attention,这是一种结合了细粒度局部交互和粗粒度全局交互的新机制。在这种新机制中,每个标记以细粒度参与其最近的周围标记,以粗粒度参与远离它的标记,因此 可以有效地捕获短程和长程视觉依赖性。借助焦点自注意力,我们提出了一种新的 Vision Transformer 模型变体,称为 Focal Transformer,它在一系列公共图像分类和对象检测基准上实现了优于最先进 (SoTA) 视觉 Transformer 的性能。特别是,我们的 Focal Transformer 模型具有 51.1M 的中等尺寸和 89.8M 的较大尺寸,分别在 224 × 224 的 ImageNet 分类上达到 83.5% 和 83.8% 的 Top-1 准确率。当用作主干时,Focal Transformers在 6 种不同的物体检测方法中,对当前的 SoTA Swin Transformers [44] 进行了一致且实质性的改进。我们最大的 Focal Transformer 在 COCO mini-val/test-dev 上产生 58.7/58.9 box mAPs 和 50.9/51.3 mask mAPs,在 ADE20K 上产生 55.4 mIoU 用于语义分割,在三个最具挑战性的计算机视觉任务上创建新的 SoTA。
1. Introduction
如今,Transformer [60] 已成为自然语言处理 (NLP) [22, 6] 中流行的模型架构。鉴于其在 NLP 中的成功,人们越来越努力将其应用于计算机视觉 (CV) [48, 51]。自从它的承诺首次在 Vision Transformer (ViT) [23] 中展示以来,我们见证了用于图像分类 [57、63、67、44、80、59]、对象检测 [9、91、84] 的全 Transformer 模型的蓬勃发展, 20] 和语义分割 [61, 65]。除了这些静态图像任务,它还被应用于各种时间理解任务,例如动作识别 [41、83、11]、对象跟踪 [15、62]、场景流估计 [39]。
在 Transformers 中,self-attention 是关键组成部分,使其与广泛使用的卷积神经网络 (CNN) [38] 不同。在每个 Transformer 层,它支持不同图像区域之间的全局内容相关交互,以对短程和长程依赖进行建模。通过完全自注意力 1 的可视化,我们确实观察到它学会了同时关注局部环境(如 CNN)和全局上下文(参见图 1 的左侧)。然而,当涉及到用于对象检测或分割等密集预测的高分辨率图像时,由于特征图中网格数量的二次计算成本,全局和细粒度的自注意力变得非常重要。最近的工作交替地利用粗粒度的全局自我注意 [63、67] 或细粒度的局部自我注意 [44、80、59] 来减少计算负担。然而,这两种方法都削弱了原始全局自注意力的能力,即同时模拟短程和长程视觉依赖性的能力,如图 1 左侧所示。
在本文中,我们提出了一种新的自我注意机制来捕获 Transformer 层中的局部和全局交互以获取高分辨率输入。考虑到附近区域之间的视觉依赖性通常比远处区域更强,我们只在局部区域进行细粒度的自注意力,而在全局区域进行粗粒度的注意。如图 1 右侧所示,特征图中的 query token 以最精细的粒度关注其最近的环境。然而,当它到达更远的区域时,它会关注汇总的 token 以捕获粗粒度的视觉依赖性。区域离 query 越远,粒度越粗因此,它可以有效地覆盖整个高分辨率特征图,同时在自我注意计算中引入的tokrn数量比完全自我关注中少得多。注意力机制。因此,它能够有效的捕获短程和长程视觉依赖性。我们称这种新机制为焦点自注意力,因为每个token都以焦点方式关注其他token。基于所提出的 focal self-attention,开发了一系列 Focal Transformer 模型,方法是 1) 利用多尺度架构为高分辨率图像保持合理的计算成本 [63、67、44、80],以及 2 ) 将特征图拆分为多个窗口,其中token共享相同的环境,而不是对每个token执行聚焦自注意力 [59、80、44]。
我们通过对图像分类、对象检测和分割的综合实证研究验证了所提出的焦点自我注意的有效性。结果表明,我们具有相似模型大小和复杂性的 Focal Transformers 在各种设置中始终优于 SoTA Vision Transformer 模型。值得注意的是,我们具有 51.1M 参数的小型 Focal Transformer 模型可以在 ImageNet-1K 上实现 83.5% 的 top-1 精度,而具有 89.8M 参数的基础模型获得 83.8% 的 top-1 精度。当转移到物体检测时,我们的 Focal Transformers 对于六种不同的物体检测方法始终优于 SoTA Swin Transformers [44]。我们最大的 Focal Transformer 模型在 COCO test-dev 上分别实现了 58.9 box mAP 和 51.3 mask mAP 用于对象检测和实例分割,在 ADE20K 上实现了 55.4 mIoU 用于语义分割。这些结果表明,focal self-attention 在建模局部-全局交互方面非常有效。

2. MEthod
2.1 Model architecture
为了适应高分辨率视觉任务,我们的模型架构与 [63、80、44] 共享类似的多尺度设计,这使我们能够在早期阶段获得高分辨率特征图。如图 2 所示,图像
首先被分成大小为 4×4 的块,得到
。然后,我们使用一个 PatchEmbedding 层,其中由一个卷积层组成,核大小和步幅都等于 4,将这些补丁投影到维度为 d 的隐藏特征中.给定这个空间特征图,然后我们将它传递给四个阶段的焦点 Transformer 块。在每个阶段
,Focal Transformer 块由
个 focal Transformer 层组成。在每个阶段之后,我们使用另一个 PatchEmbedding 层将特征图的空间大小减少 2 倍,同时特征维度增加 2。对于图像分类任务,我们取上一阶段输出的平均值并将其发送到一个分类层。对于物体检测,根据我们使用的特定检测方法,来自最后 3 个或所有 4 个阶段的特征图被馈送到检测器头。可以通过改变输入特征维度 d 和每个阶段的焦点 Transformer 层数来定制模型容量
。
标准的自注意力可以捕获细粒度的短距离和长距离交互,但是当它在高分辨率特征图上执行注意力时,它会受到高计算成本的影响,如 [80] 中提到的。以图2中的stage 1为例。对于大小为
的特征图,自注意力的复杂度为
,考虑到 min(H, W) 为 800 或什至更大,导致时间和内存成本爆炸式增长物体检测。接下来,我们将描述我们如何通过提出的焦点自注意力来解决这个问题。
2.2 Focal self-attention
在本文中,我们提出了 focal self-attention 以使 Transformer 层可扩展到高分辨率输入。我们提出只在局部注意细粒度token,在全局进行汇总,而不是计算所有细粒度token。因此,它可以覆盖与标准自注意力一样多的区域,但成本要低得多。在图 3 中,当我们逐渐添加更多参与标记时,我们显示了标准自注意力和 focal self-attention的感受野区域。对于 query 位置,当我们对其较远的环境使用逐渐粗粒度时,focal self-attention 可以具有明显更大的感受野,但代价是要注意与基线相同数量的 token 。
我们的 focal mechanism 能够以更少的时间和内存成本实现长程自注意力,因为它关注的周围(汇总的)token 数量要少得多。然而,在实践中,为每个 query 位置提取周围的 tokens 会耗费大量时间和内存,因为我们需要为所有可以访问它的 queries 复制每个token。这个实际问题已被许多先前的作品 [59, 80, 44] 注意到,常见的解决方案是将输入特征映射划分为窗口。受他们的启发,我们采取在窗口级别执行 focal self-attention。
给定
的空间大小为 M × N 的特征图,我们首先将其划分为大小为
的窗口网格。然后,我们找到每个窗口的周围环境而不是单个 token 。在下文中,我们详细阐述了 window-wise focus self-attention。


2.2.1 Window-wise attention
图 4 显示了所提出的基于窗口的 focal self-attention 的图示。为了清楚起见,我们首先定义了三个术语:
- Focal levels L - 我们为焦点自注意力提取标记的粒度级别数。例如,在图 1 中,我们总共显示了 3 个焦点级别。
- Focal window size
– 我们在级别 l ∈ { 1, ..., L } 获得汇总标记的子窗口的大小,对于图 1 中的三个级别分别为 1、2 和 4。
- Focal region size
– l 层关注区域水平和垂直方向的子窗口数量,图1中从1层到3层分别为3、4和4。
通过以上三个术语 { L,
Sub-window pooling. 假设输入特征图
,我们首先将输入特征图 x 分成大小为
的子窗口网格。然后我们使用一个简单的线性层
通过以下方式在空间上池化子窗口:
不同level
提供了丰富的细粒度和粗粒度信息。由于我们将
Attention computation. 一旦我们获得了在所有 L levels 的 pooled 特征图
计算第一层的 query 和所有层的 key 和 value :
为了执行 focal self-attention,我们需要首先为特征图中的每个 query token 提取周围的 tokens 。正如我们之前提到的,窗口分区
内的 tokens 共享同一组环境。对于第 i 个窗口
内的 queries,我们从 query 所在窗口周围的
和
中提取
的 keys 和 values,然后收集 keys 和 values 从所有 L 的值得到
和
,其中 s 是来自所有 levels 的focal ragion 的总和,即
。请注意,图 1 之后的 focal self-attention 的严格版本需要排除不同级别的重叠区域。在我们的模型中,我们有意保留它们以捕获重叠区域的金字塔信息。最后,我们按照 [44] 包括相对位置偏差并通过以下方式计算
的 focal self-attention :
其中
是可学习的相对位置偏差。它由 L 个 L focal levels 的子集组成。类似于[44],对于第一层,我们将其参数化为
,考虑到水平和垂直位置范围都在
。对于其他 focal levels,考虑到它们对 queries 具有不同的粒度,我们平等对待窗口内的所有 queries,并使用
来表示 query 窗口与每个池化的
之间的相对位置偏差 tokens。由于每个窗口的 focal self-attention 独立于其他窗口,我们可以并行计算atten。一旦我们为整个输入特征图完成它,我们将它发送到 MLP 块以像往常一样进行计算。
2.2.2 Complexity analysis
我们分析了上述两个主要步骤的计算复杂度。对于输入特征图
,我们在focal level 1 有
个子窗口。对于每个子窗口,池化操作的复杂度为
。聚合所有子窗口给我们带来了
。然后对于所有focal levels,我们总共有
的复杂性,它与每个 focal levels 的子窗口大小无关。关于注意力计算,对于
,而整个输入特征图的计算成本为
。综上所述,我们的 focal self-attention 的总体计算成本变为
。在极端情况下,可以设置
以确保该level 中所有queries(包括角落部分和中间部分)的全局接受域。
2.3 Model configuration

Focal Transformer 考虑了三种不同的网络配置。在这里,我们简单地遵循之前作品 [63、67、44] 建议的设计策略,尽管我们认为应该有更好的配置专门针对我们的 focal Transformers。具体来说,我们使用与 Swin Transformer [44] 中的 Tiny、Small 和 Base 模型类似的设计,如表 1 所示。我们的模型将 224 × 224 图像作为输入,窗口分区大小也设置为 7 以使我们的模型堪比 swin 。对于 focal self-attention 层,我们引入了两个 levels,一个用于细粒度局部注意力,一个用于粗粒度全局注意力。除了最后一个 stage,focal ragion 大小始终设置为 13,窗口分区大小为 7,这意味着我们为每个窗口分区扩展 3 个 token 。对于最后一个 stage ,由于整个特征图为 7×7,因此第 0 级的 focal ragion 大小设置为 7,足以覆盖整个特征图。对于粗粒度全局注意力,我们将其 focal window大小设置为窗口分区大小 7,但逐渐减小 focal ragion 大小以获得四个 stage 的 {7, 5, 3, 1}。对于patch embedding层,四个阶段的空间缩减率均为{4,2,2,2},而Focal-Base相比Focal-Tiny和Focal-Small具有更高的隐藏维度。
3. Related work
Vision Transformers. Vision Transformer (ViT) 首次在 [23] 中引入。它应用最初为 NLP [60] 开发的标准 Transformer 编码器,通过类似地分割图像转换成一系列视觉 token来编码图像。当使用足够的数据 [23] 和仔细的数据增强和正则化 [57] 进行训练时,它在多个图像分类基准上证明了优于 ResNet [34] 等卷积神经网络 (CNN) 的性能。这些进步进一步激发了 transformer 在图像分类以外的各种视觉任务中的应用,例如自监督学习 [16、10、40]、目标检测 [9、91、84、20] 和语义分割 [61、65、86] ].除了下游任务,另一条工作重点是从不同角度改进原始 ViT,例如数据高效训练[57]、改进的补丁嵌入/编码[18、75、32],将卷积投影集成到转换器中[ 67, 74],用于高分辨率视觉任务的多尺度架构和高效自注意力机制 [63, 67, 44, 80, 17]。我们建议读者参考 [37, 31, 37] 进行综合调查。本文重点是通过提出的 focal self-attention 机制提高视觉转换器的一般性能。在下文中,我们特别讨论了与注意力机制最相关的工作。
Efficient global and local self-attention. Transformer 模型通常需要处理大量的 token,例如 NLP 中的长文档和 CV 中的高分辨率图像。最近,提出了各种有效的自注意机制来克服普通自我注意中的二次计算和内存成本。一方面,NLP 和 CV 中的许多工作通过参与下采样/汇总的标记来求助于粗粒度的全局自注意力,同时保留长程交互 [50、47、63、67、32]。尽管这种方法可以提高效率,但它丢失了 query token 周围的详细上下文。另一方面,局部细粒度注意力,即在恒定窗口大小内关注相邻标记,是语言 [3, 78, 1] 和视觉 [59, 44, 80] 的另一种解决方案。在本文中,我们认为两种类型的注意力都很重要,全注意力 ViT 模型确实已经学习了这两种类型,如图 1 左所示。 这也得到了最近先进的 CNN 模型 [36、66、64、71、2、8、52] 的支持,这表明全局注意力或交互可以有效地提高性能。我们提出的 focal self-attention 是第一个在单个 transformer 层中协调全局和局部 self-attention 的方法。它可以捕获局部和全局交互作为普通的全注意力,但以更有效和有效的方式,特别是对于高分辨率输入。
4. Experiments
4.1 Image classification on ImageNet-1K
我们比较了 ImageNet-1K [21] 上的不同方法。为了公平比较,我们遵循 [57、63] 中的训练方法。所有模型都训练了 300 个周期,批量大小为 1024。初始学习率设置为 10 -3,从 10 -5 开始进行 20 个线性预热周期。为了优化,我们使用 AdamW [45] 作为带有余弦学习率调度器的优化器。权重衰减设置为 0.05,最大梯度范数被限制为 5.0。在排除随机擦除 [87]、重复增强 [4, 35] 和指数移动平均线 (EMA) [49]。对于我们的微型模型、小型模型和基本模型,随机深度下降率分别设置为 0.2、0.2 和 0.3。在训练期间,我们将图像随机裁剪为 224 × 224,而在验证集评估期间使用中心裁剪。
在表 2 中,我们总结了基线模型和图像分类任务的当前最先进模型的结果。我们可以发现我们的 Focal Transformers 始终优于具有相似模型大小 (#Params.) 和计算复杂度 (GFLOPs) 的其他方法。具体来说,Focal-Tiny 比 Transformer 基线 DeiT-Small/16 提高了 2.0%。同时,使用相同的模型配置 (2-2-6-2) 和一些额外的参数和计算,我们的 Focal-Tiny 比 Swin-Tiny 提高了 1.0 个百分点 (81.2% → 82.2%)。当我们将窗口大小从 7 增加到 14 以匹配 ViL-Small [80] 中的设置时,性能可以进一步提高到 82.5%。对于小型和基本型号,我们的 Focal Transformers 的性能仍然比其他的略好。值得注意的是,我们的 51.1M 参数的 Focal-Small 可以达到 83.5%,这比所有使用更少参数的对应小型和基础模型都要好。当进一步增加模型尺寸时,我们的 Focal-Base 模型达到了 83.8%,超过了使用可比参数和 FLOPs 的所有其他模型。我们建议读者参阅我们的附录以进行更详细的比较。

4.2 Object detection and instance segmentation
我们使用 COCO 2017 [43] 对我们的对象检测模型进行基准测试。预训练模型用作视觉主干,然后插入两个代表性管道,RetinaNet [42] 和 Mask R-CNN [33]。所有模型都在 118k 训练图像上训练,结果在 5K 验证集上报告。我们按照标准使用两个训练时间表,1× schedule with 12 epochs 和 3× schedule with 36 epochs。对于 1× schedule,我们将图像的短边调整为 800,同时保持其长边不超过 1333。对于 3× schedule,我们使用多尺度训练策略,通过随机将其短边调整到 [480, 800] 的范围。考虑到这种更高的输入分辨率,我们自适应地将四个阶段的焦点大小增加到(15、13、9、7),以确保焦点注意力覆盖超过一半的图像区域(前两个阶段)到整个图像(最后一个两个阶段)。随着焦点尺寸的增加,相对位置偏差相应地使用双线性上采样到相应的尺寸 插值。在训练期间,我们使用 AdamW [45] 进行优化,初始学习率为 10 -4,权重衰减为 0.05。同样,我们分别使用 0.2、0.2 和 0.3 的随机深度下降率来规范我们的微型、小型和基础模型的训练。由于 Swin Transformer 不报告 RetinaNet 上的数字,我们使用他们的官方代码使用与我们的 Focal Transformers 相同的超参数自行训练它。
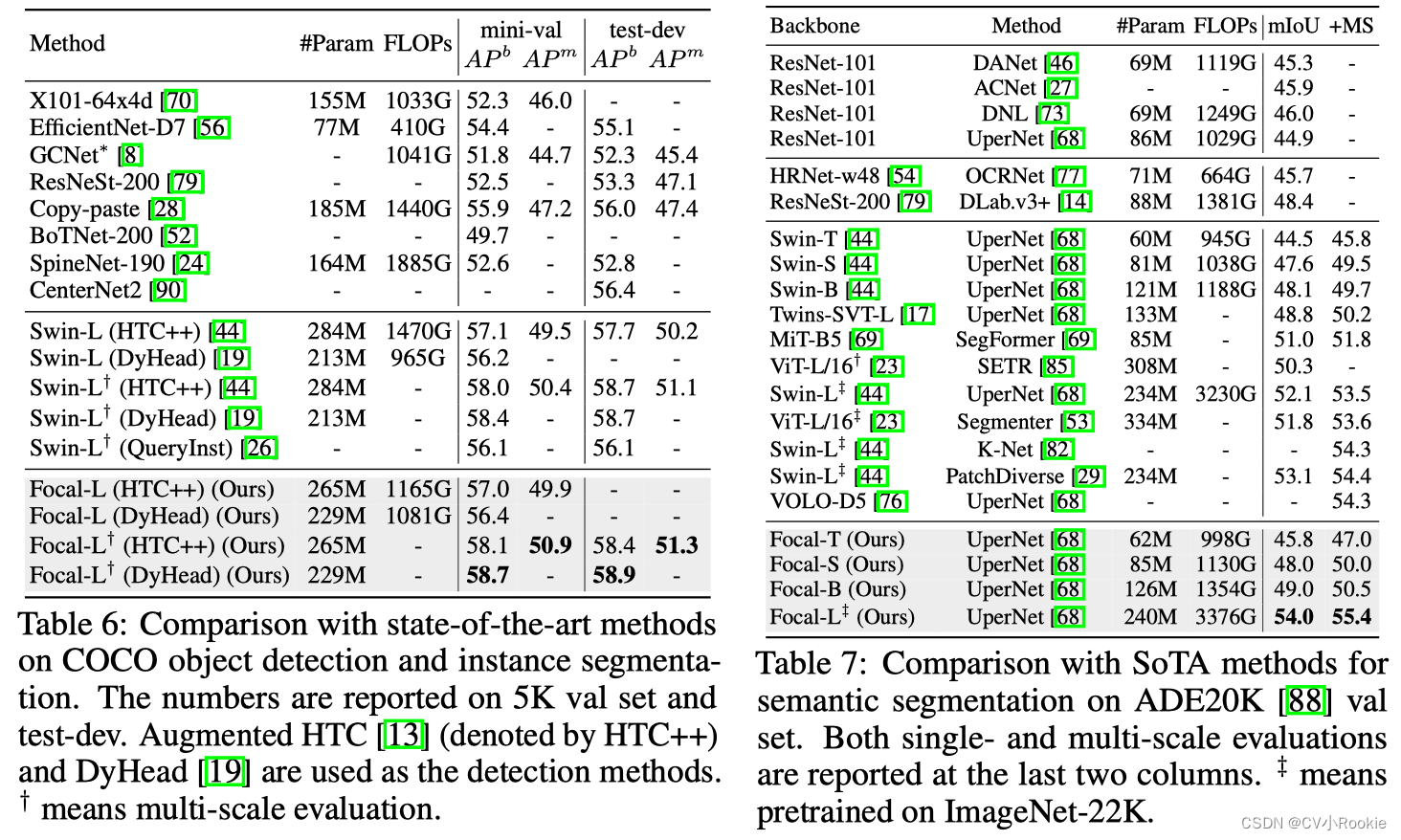
在表 3 中,我们展示了基于 CNN 的模型和当前基于 Transformer 的最先进方法的性能。报告了 bbox mAP (AP b ) 和 mask mAP (AP m )。我们的 Focal Transformers 始终优于基于 CNN 的模型,差距为 4.8-7.1 点。与同样使用多尺度 Transformer 架构的其他方法相比,我们仍然观察到在所有设置和指标上都有可观的收益。特别是,在可比较的设置下,我们的 Focal Transformers 相对于当前最佳方法 Swin Transformer [44] 带来了 0.7-1.7 点的 mAP。与其他多尺度 Transformer 模型不同,我们的方法可以同时为每个视觉标记启用短程细粒度和远程粗粒度交互,从而在每一层捕获更丰富的视觉上下文以实现更好的密集预测。为了进行更全面的比较,我们进一步用 3× schedule 训练它们,并在表 4 中显示了 RetinaNet 和 Mask R-CNN 的详细数字。为了便于理解, 我们还列出了每个模型的参数数量和相关的计算成本。正如我们所看到的,即使是 3× schedule,我们的模型仍然可以在可比较的设置下比最好的 Swin Transformer 模型获得 0.3-1.1 的增益。
为了进一步验证我们提出的 Focal Transformer 的有效性,我们按照 [44] 训练四种不同的物体检测器,包括 Cascade R-CNN [7]、ATSS [81]、RepPoints [72] 和 Sparse R-CNN [55]。我们使用 Focal-Tiny 作为主干并使用 3× 时间表训练所有四个模型。表 5 报告了 COCO 验证集上的框 mAP。正如我们所见,我们的 Focal-Tiny 在所有方法上都超过 SwinTiny 1.0-2.3 点。除了 RetinaNet 和 Mask RCNN 之外,这些对不同检测方法的显着且一致的改进表明我们的 Focal Transformer 可以用作各种对象检测方法的通用主干。
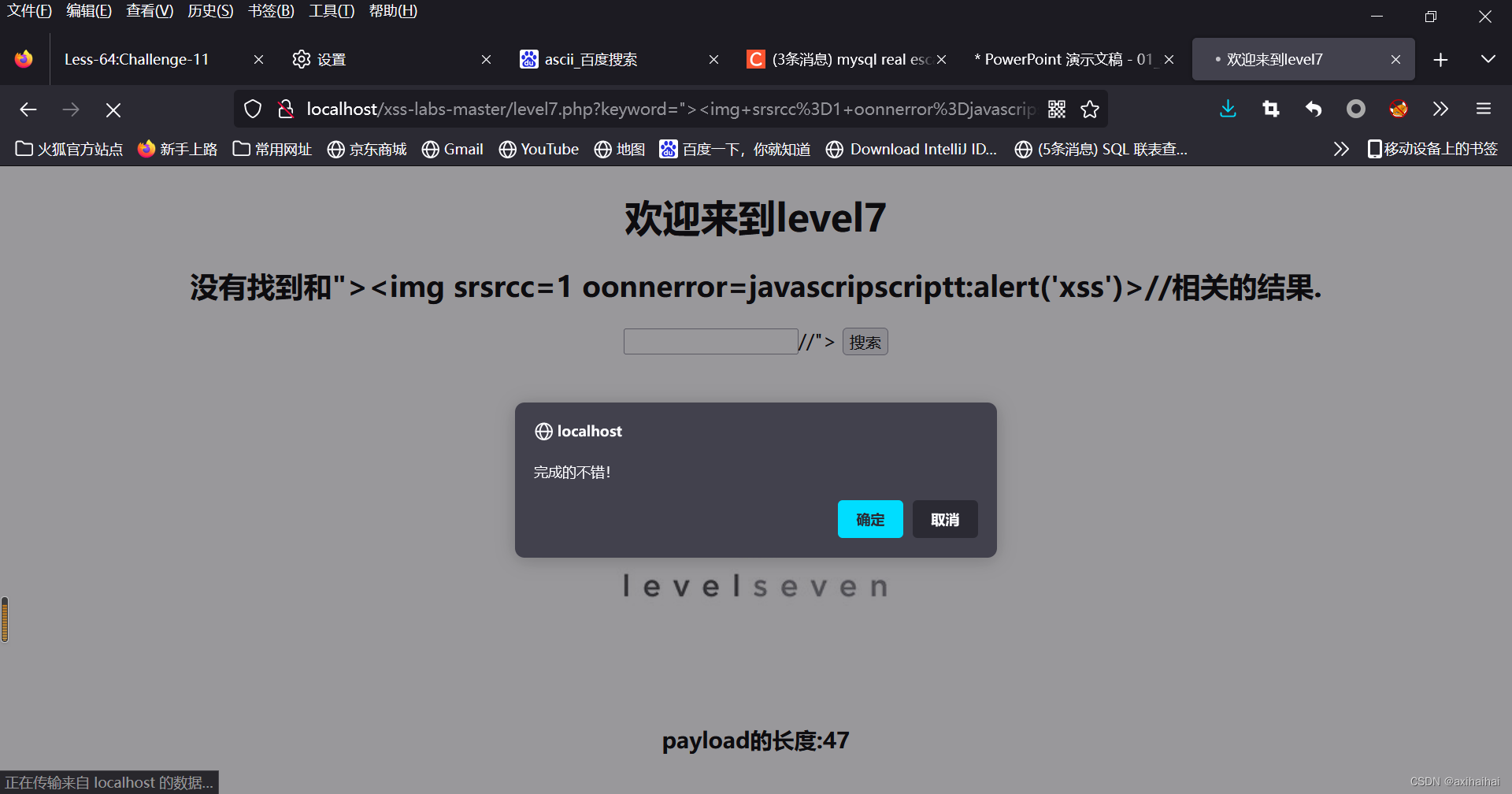
除了上面的实例分割结果,我们还进一步评估了我们的语义分割模型,这是一项通常需要高分辨率输入和远程交互的任务。我们在 ADE20K [88] 上对我们的方法进行了基准测试。具体来说,我们使用 UperNet [68] 作为分割方法,我们的 Focal Transformers 作为主干。我们分别使用 Focal-Tiny、Focal-Small、Focal-Base 训练三种模型。对于所有模型,我们通过将输入大小设置为 512 × 512 来使用标准配方,并训练模型进行 160k 次迭代,批量大小为 16。在表 7 中,我们显示了与之前作品的比较。正如我们所见,我们的微型、小型和基础模型在单尺度和多尺度 mIoU 上始终优于具有相似尺寸的 Swin Transformers。





![[附源码]计算机毕业设计springboot餐馆点餐管理系统](https://img-blog.csdnimg.cn/680a81d53114401cb1710cd74fd42c62.png)
![[附源码]计算机毕业设计springboot房屋租赁系统](https://img-blog.csdnimg.cn/31f1ef3b9dd947d7b8d47829bbcd6460.png)



![[附源码]计算机毕业设计springboot飞越青少儿兴趣培训机构管理系统](https://img-blog.csdnimg.cn/d191a39367534940a875fb7ec2f5c56f.png)