在Java世界中,有两种数据审计工具:Envers和JaVers。 Envers已经存在了很长时间,它被认为是主流。 JaVers提供全新的方法和技术独立性。 如果您考虑哪种工具更适合您的项目,本文是一个很好的起点。
本文分为三个部分。首先,是高层次的比较。 在第二部分中,我将展示用于管理组织结构的简单演示应用程序 Javers和Envers进行的数据审计。 在第三部分中,我将检查这两种工具如何应对对审计数据的查询。
当与Spring Data JPA集成时Javers,Envers都内不能记录JPQL、和本机SQL语句修改的数据,所以要尽量避免使用JPQL、和本机SQL语句修改数据(只查询数据没问题);
当与Spring Data JPA集成时Javers默认就可以记录操作认证用户,Envers需要自己定制RevisionEntity、RevisionListener ;
@Data
@Entity
@RevisionEntity(UserRevisionListener.class)
public class UserRevEntity extends DefaultRevisionEntity {private String username;}
public class UserRevisionListener implements RevisionListener {@Overridepublic void newRevision(Object revisionEntity) {String username;if (SecurityContextHolder.getContext().getAuthentication() != null) {org.springframework.security.core.userdetails.User principal = (org.springframework.security.core.userdetails.User) SecurityContextHolder.getContext().getAuthentication().getPrincipal();username = Optional.of(principal.getUsername()).orElse(null);} else {username = "unauthenticated";}UserRevEntity exampleRevEntity = (UserRevEntity) revisionEntity;exampleRevEntity.setUsername(username);}目录
- 高级比较
- 演示应用程序
- 数据库配置
- 启用 Envers 审计
- 启用 JaVers 审核
- 查询竞赛
- 按类型浏览对象历史记录
- 恩弗斯方式
- 贾弗斯方式
- 比较
- 查询筛选器
- 恩弗斯方式
- 贾弗斯方式
- 比较
- 更多查询筛选器
- 重建完整的对象图
- 恩弗斯方式
- 贾弗斯方式
- 比较
- 其他查询类型
- 按类型浏览对象历史记录
- 结语
高级比较
JaVers和Envers之间有两个很大的区别:
-
Envers是Hibernate插件。 它与Hibernate有很好的集成,但你只能将它用于传统的SQL数据库。 如果您选择了 NoSQL 数据库或 SQL,但使用了其他持久性框架 (例如JOOQ) — Envers 不是一个选项。
相反,JaVers可以与任何类型的数据库和任何类型的 持久性框架。目前,JaVers附带了MongoDB和 流行的 SQL 数据库。将来可能会添加其他数据库(如Cassandra,Elastic)。
-
Envers的审计模型是面向表格的。 您可以将 Envers 视为对数据库记录进行版本控制的工具。
正如文档所说:对于每个被审计的实体,都会创建一个审计表。 缺省情况下,审计表名是通过在原始名称中添加_AUD后缀来创建的。这可能是一个优势,您可以将审计数据存储在实时数据附近。 恩弗斯的桌子看起来很熟悉。使用 SQL 查询它们很容易。JaVers的审计模型是面向对象的。这一切都与对象的快照有关。 JaVers 将它们保存到单个表(或 Mongo 中的集合) 作为具有统一结构的 JSON 文档。 优势?您可以专注于域对象并处理持久性和审核 作为基础设施方面。 由于审核数据与实时数据分离,因此您可以选择存储它们的位置。 默认情况下,JaVers 会将快照保存到应用程序的数据库中,但您可以指向另一个快照。 例如,SQL for Application 和 MongoDB for JaVers (甚至是为公司中的所有应用程序共享的集中式 JaVers 数据库)。
演示应用程序
我们的演示项目是基于Spring Boot的简单Groovy应用程序。 从https://github.com/javers/javers-vs-envers 克隆它。
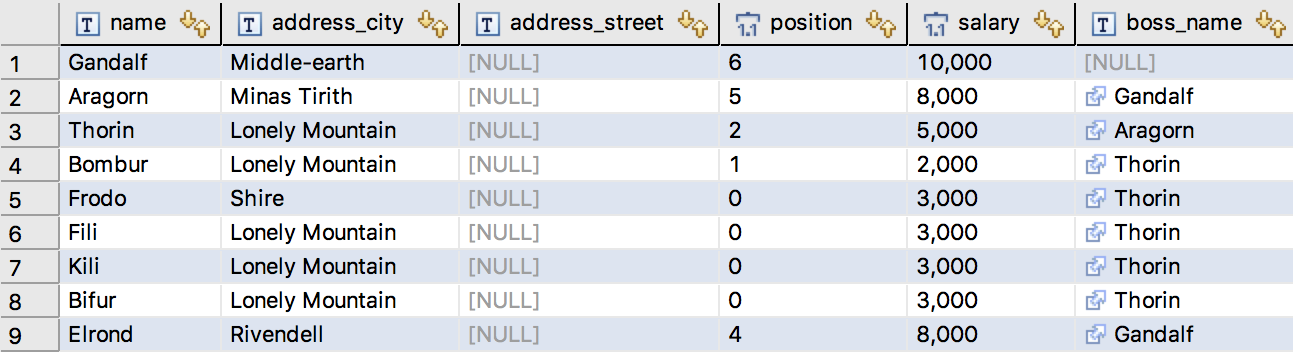
让我们从域模型开始。 只有两个类:员工和地址。员工以树状结构进行组织。
Employee.groovy
@Entity
class Employee {@IdString name@ManyToOneEmployee boss@OneToMany(cascade = CascadeType.ALL, mappedBy = "boss")Set<Employee> subordinates = new HashSet()@EmbeddedAddress addressInteger salaryPosition positionEmployee() {}...
}Address.groovy
@Embeddable
class Address {@Column(name = "address_city")String city@Column(name = "address_street")String streetAddress() {}Address(String city) {this.city = city}
}
数据库配置
该应用程序配置为与本地 PostgreSQL 一起使用。 您可以轻松更改它(不要忘记合适的 JDBC 驱动程序)。
application.properties
spring.datasource.url=jdbc:postgresql://localhost:5432/javers-vs-envers
build.gradle
compile 'postgresql:postgresql:9.1-901-1.jdbc4'
要运行应用程序并填充数据库,请执行InitHierarchyTest.groovy测试:
def "should init and persist organization structure"(){given:def boss = hierarchyService.initStructure()boss.prettyPrint()expect:boss.name == "Gandalf"
}您可以从命令行运行它:
./gradlew test --tests InitHierarchyTest
现在,您应该在表中填充了初始数据。Employee
select * from Employee
启用 Envers 审计
要启用 Envers,我们需要添加依赖项:hibernate-envers
compile 'org.hibernate:hibernate-envers:'+hibernateVersion
对我们实体的注释:@Audited
import org.hibernate.envers.Audited@Entity
@Audited
class Employee {...
}就是这样。现在,我们可以做一些审核的更改:
SimpleChangeTest.groovy
def "should persist Employee's property change"(){given:def boss = hierarchyService.initStructure()hierarchyService.giveRaise(boss, 200)expect:hierarchyService.findByName("Gandalf").salary == 10200
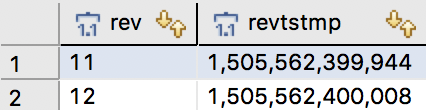
}Envers 创建两个表:和。revinfoemployee_aud
select * from revinfo
select * from employee_aud
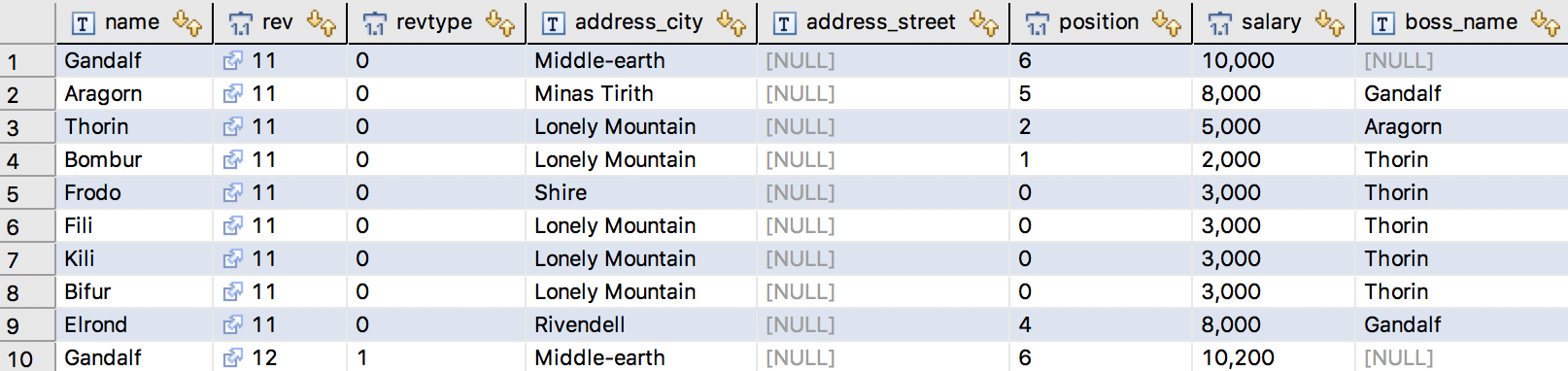
到目前为止,这并不奇怪。我们有两个修订与审计表中的记录相关联。 Revtype 0 表示插入,1 表示更新。 奇怪的是修订时间戳的类型。 为什么是长而不是日期?幸运的是,您可以使用自定义修订实体进行修复。 此外,修订实体是您可以挂钩修订元数据(如更改作者)的地方。
启用 JaVers 审核
要启用 JaVers,我们需要将此依赖项添加到 JaVers Spring Boot 启动器 for SQL 中:
compile 'org.javers:javers-spring-boot-starter-sql:6.8.0'
将JaVers与Spring应用程序
集成的最简单方法是将注释添加到Spring Data CRUD存储库中。 此注释启用自动审核方面。@JaversSpringDataAuditable
EmployeeRepository.groovy
import org.javers.spring.annotation.JaversSpringDataAuditable
import org.springframework.data.repository.CrudRepository@JaversSpringDataAuditable
interface EmployeeRepository extends CrudRepository<Employee, String> {
}就这样。现在,当您重新运行时, JaVers 将创建三个表:SimpleChangeTest
jv_commit,jv_global_id,jv_snapshot
(还有第四个表 — ,但我们的应用程序没有触及它)。jv_commit_property
JaVers'Commit 与 Envers'Revision 的概念类似 (来自 Git 和 Subversion 的灵感是显而易见的)。 每个提交都有时间戳和作者。 在这里,作者字段未知,如果您启用 Spring 安全性,它将设置为当前用户 (请参阅作者提供程序)。
select * from jv_commit

现在,让我们看看对象的快照是如何存储的。
在JaVers中,每个审核的对象都有GlobalId。 对于实体,它是类型名称和本地 ID 对。 ValueObjects(如地址)被视为实体的组件, 因此,它们由以下一对标识:拥有实体 GlobalId 和路径(通常是属性名称)。
到目前为止,我们有 18 个对象,因此存储了 18 个 GlobalId。
select * from jv_global_id
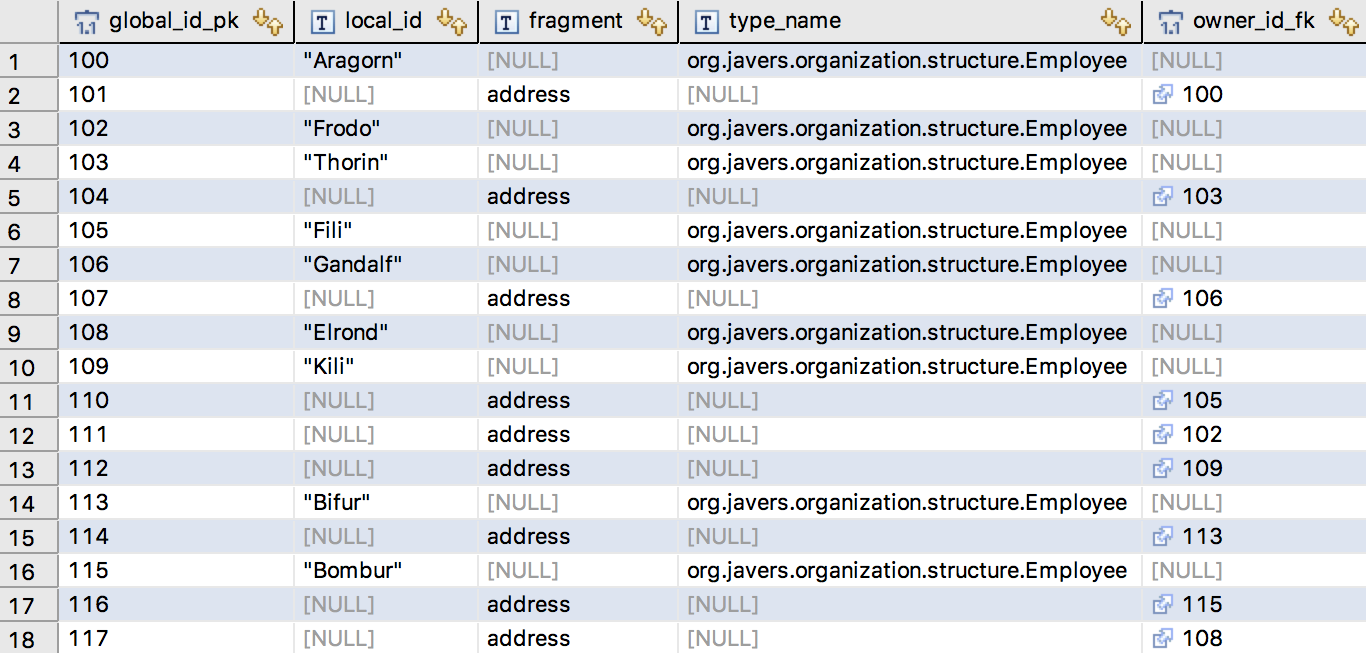
对于每个 GlobalId,JaVers 都会创建一个或多个对象的快照。 到目前为止,我们只做了一个更改(甘道夫上升了),所以我们有 18 个初始快照 以及甘道夫的一个更新快照。似乎没错。
select * from jv_snapshot

JaVers 与 Envers 的区别在于专栏,这里是实时快照本身。 它是包含 JSON 文档的文本列。 多亏了这一点,JaVers没有耦合到任何特定类型的数据库。 只要数据库支持文本或 JSON 类型,就可以了。 事实上,MongoDB对JaVers来说比SQL更自然。 因为MongoDB旨在存储JSON文档。state
快照状态文档是映射,其中键是属性名称,值是, 好吧,属性值(非常像Javascript)。 对其他对象的引用将冻结并存储为 GlobalId。
比如,这是甘道夫的现状:
{"address": {"valueObject": "org.javers.organization.structure.Address","ownerId": {"entity": "org.javers.organization.structure.Employee","cdoId": "Gandalf"},"fragment": "address"},"name": "Gandalf","position": "CEO","salary": 10200,"subordinates": [{"entity": "org.javers.organization.structure.Employee","cdoId": "Elrond"},{"entity": "org.javers.organization.structure.Employee","cdoId": "Aragorn"}]
}查询竞赛
某些应用程序仅出于以防万一而实施了数据审核。 例如,如果 IT 审计员意外和令人生畏地访问您询问问题。 在此方案中,应用程序不需要具有任何用于浏览审核数据的特殊 UI。 任何开发人员都可以直接连接到数据库,生成一些报告并让审计员满意。
在其他应用中,数据审计非常重要,以至于 它成为提供给用户的功能之一。 例如,维基百科具有页面历史记录视图,其中显示了对任何页面所做的更改。
我专注于第二种情况, 我们的演示应用程序针对审计数据运行查询,以显示奖学金的历史记录。
按类型浏览对象历史记录
让我们从基本查询开始 — 按类型查询。 我们正在为甘道夫和阿拉贡增加一个名字,我们也在改变他们的地址。 这意味着四个变化。
given:def gandalf = hierarchyService.initStructure()def aragorn = gandalf.getSubordinate('Aragorn')gandalf.prettyPrint()//changeshierarchyService.giveRaise(gandalf, 200)hierarchyService.updateCity(gandalf, 'Shire')hierarchyService.giveRaise(aragorn, 100)hierarchyService.updateCity(aragorn, 'Shire')然后我们想浏览我们在Envers和JaVers中员工的历史。
恩弗斯方式
EnversQueryTest.groovy#L27
@Transactional
def "should browse Envers history of objects by type"(){given:...when:List folks = AuditReaderFactory.get(entityManager).createQuery().forRevisionsOfEntity( Employee, false, true ).add(AuditEntity.revisionType().eq(MOD)) // without initial versions.getResultList()println 'envers history of Employees:'folks.each {println 'revision:' + it[1].id + ', entity: '+ it[0]}then:folks.size() == 4
}转换器输出:
envers history of Employees:
revision:33, entity: Employee{ Gandalf CEO, $10200, Middle-earth, subordinates:Aragorn,Elrond }
revision:34, entity: Employee{ Gandalf CEO, $10200, Shire, subordinates:Aragorn,Elrond }
revision:35, entity: Employee{ Aragorn CTO, $8100, Minas Tirith, subordinates:Thorin }
revision:36, entity: Employee{ Aragorn CTO, $8100, Shire, subordinates:Thorin }
贾弗斯方式
JaversQueryTest.groovy#L23
def "should browse JaVers history of objects by type"(){given:...when:List<Shadow<Employee>> shadows = javers.findShadows(QueryBuilder.byClass(Employee).withSnapshotTypeUpdate().build())println 'javers history of Employees:'shadows.each { shadow ->println 'commit:' + shadow.commitMetadata.id + ', entity: '+ shadow.get()}then:shadows.size() == 4shadows[0].commitMetadata.id.majorId == 5shadows[3].commitMetadata.id.majorId == 2
}贾弗斯输出:
javers history of Employees:
commit:5.0, entity: Employee{ Aragorn CTO, $8100, Shire, subordinates:Thorin }
commit:4.0, entity: Employee{ Aragorn CTO, $8100, Minas Tirith, subordinates:Thorin }
commit:3.0, entity: Employee{ Gandalf CEO, $10200, Shire, subordinates:Aragorn,Elrond }
commit:2.0, entity: Employee{ Gandalf CEO, $10200, Middle-earth, subordinates:Aragorn,Elrond }比较
这两个工具都完成了这项工作并显示了正确的历史记录。这两个工具都加载了相关实体。
艺术印象呢?有一些有趣的区别。
-
Envers 查询结果按时间顺序排序。 最早的更改位于列表的第一个。 浏览历史记录时,通常您希望先查看最新更改。 反向时间顺序更自然,这就是Javers的排序方式。 我没有在 Envers 中找到反向排序的方法(注:Envers 可以反向排序 AuditQuery query = reader.createQuery()
.forRevisionsOfEntity(User.class, false, true)
.addOrder(AuditEntity.revisionNumber().desc());
)。 -
JaVers 查询 API 似乎更优雅。它被称为JQL(JaVers Query Language)。
-
Envers的查询中真正神秘的是结果类型。 为什么返回非参数化列表?什么清单?好吧,这取决于第二个标志 传到命名。 如果为 true,它将是一个实体列表,否则是三元素数组的列表,包含:实体实例、修订实体和修订类型。 不酷。在Groovy中这不是问题,但在Java中,你必须大量投射才能获得数据。 在 JaVers 中,您可以获得类型安全的阴影列表。 简而言之,Shadow 是一对历史实体和提交元数据。
getResultList()forRevisionsOfEntity()selectEntitiesOnly -
两个工具都加载了相关实体(下属和老板), 虽然我们没有要求这个。 Envers使用众所周知的Hibernate延迟加载方法。 相反,JaVers 总是急切地加载数据 基于查询范围。 这两种方法都有优点和缺点。 延迟加载看起来很吸引人,您可以根据需要获得尽可能多的数据而不会打扰 关于基础数据库查询。 缺点是持续的威胁。 此外,Hibernate动态代理和持久集合使您的对象图混乱。
LazyInitializationException
查询筛选器
如果没有搜索过滤器,浏览对象历史记录不是很有用。
在下一个示例中,我们将展示如何实现 两种常见的搜索用例:
- 按 ID 搜索,以显示指定员工的历史记录。
- 按更改的属性搜索,以显示整个组织中的工资变化历史记录。
恩弗斯方式
EnversQueryTest.groovy#L57
@Transactional
def "should browse Envers history of objects by type with filters"(){given:def gandalf = hierarchyService.initStructure()def aragorn = gandalf.getSubordinate('Aragorn')def thorin = aragorn.getSubordinate('Thorin')//changes[gandalf, aragorn, thorin].each {hierarchyService.giveRaise(it, 100)hierarchyService.updateCity(it, 'Shire')}when: 'query with Id filter'List aragorns = AuditReaderFactory.get(entityManager).createQuery().forRevisionsOfEntity( Employee, false, true ).add(AuditEntity.id().eq( 'Aragorn' )).getResultList()then:println 'envers history of Aragorn:'aragorns.each {println 'revision:' + it[1].id + ', entity: '+ it[0]}aragorns.size() == 3when: 'query with Property filter'List folks = AuditReaderFactory.get(entityManager).createQuery().forRevisionsOfEntity( Employee, false, true ).add(AuditEntity.property('salary').hasChanged()).add(AuditEntity.revisionType().eq(MOD)).getResultList()then:println 'envers history of salary changes:'folks.each {println 'revision:' + it[1].id + ', entity: '+ it[0]}folks.size() == 3
}我们的查询没有太大变化。要按 ID 搜索,我们使用:
.add(AuditEntity.id().eq( 'Aragorn' ))
为了按更改的属性进行搜索,我们添加了:
.add(AuditEntity.property('salary').hasChanged())
看起来不错,但是运行此测试时会发生什么?哎 呦! 第二个查询引发异常:
org.hibernate.QueryException: could not resolve property: salary_MOD of: org.javers.organization.structure.Employee_AUD [select e__, r from org.javers.organization.structure.Employee_AUD e__, org.hibernate.envers.DefaultRevisionEntity r where e__.salary_MOD = :_p0 and e__.REVTYPE = :_p1 and e__.originalId.REV.id = r.id order by e__.originalId.REV.id asc]
看起来表中缺少一列。但是这个表是由Envers管理的, 为什么他在自己的表格中找不到列?salary_MODemployee_AUD
在用户指南中进行一些挖掘后, 我们可以找到答案——修改标志。 如果我们想按更改的属性进行查询,我们需要为我们的类启用它们:
@Entity
@Audited( withModifiedFlag=true )
class Employee {...然后,Envers 将布尔矩阵添加到表中:employee_AUD
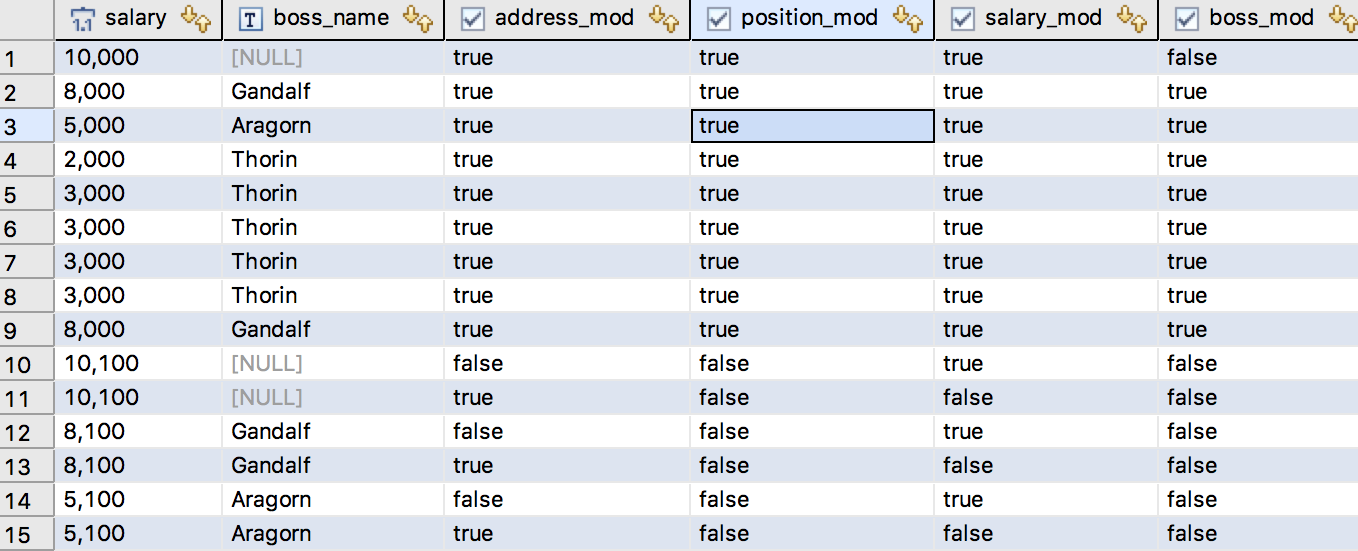
当我们看到这些标志时,它们变得很明显。 Envers 使用它们来查找对给定属性进行更改的记录。
现在,Envers 输出似乎是正确的:
envers history of Aragorn:
revision:6554, entity: Employee{ Aragorn CTO, $8000, Minas Tirith, subordinates:'Thorin' }
revision:6557, entity: Employee{ Aragorn CTO, $8100, Minas Tirith, subordinates:'Thorin' }
revision:6558, entity: Employee{ Aragorn CTO, $8100, Shire, subordinates:'Thorin' }envers history of salary changes:
revision:6555, entity: Employee{ Gandalf CEO, $10100, Middle-earth, subordinates:'Aragorn','Elrond' }
revision:6557, entity: Employee{ Aragorn CTO, $8100, Minas Tirith, subordinates:'Thorin' }
revision:6559, entity: Employee{ Thorin TEAM_LEAD, $5100, Lonely Mountain, subordinates:'Bombur','Frodo','Fili','Kili','Bifur' }相反,JaVers 查询开箱即用。
贾弗斯方式
JaversQueryTest.groovy#L52
def "should browse JaVers history of objects by type with filters"(){given:def gandalf = hierarchyService.initStructure()def aragorn = gandalf.getSubordinate('Aragorn')def thorin = aragorn.getSubordinate('Thorin')//changes[gandalf, aragorn, thorin].each {hierarchyService.giveRaise(it, 100)hierarchyService.updateCity(it, 'Shire')}when: 'query with Id filter'List<Shadow<Employee>> shadows = javers.findShadows(QueryBuilder.byInstanceId('Aragorn', Employee).build())then:println 'javers history of Aragorn:'shadows.each { shadow ->println 'commit:' + shadow.commitMetadata.id + ', entity: '+ shadow.get()}shadows.size() == 3when: 'query with Property filter'shadows = javers.findShadows(QueryBuilder.byClass(Employee).withChangedProperty('salary').withSnapshotTypeUpdate().build())then:println 'javers history of salary changes:'shadows.each { shadow ->println 'commit:' + shadow.commitMetadata.id + ', entity: '+ shadow.get()}shadows.size() == 3
}贾弗斯输出:
javers history of Aragorn:
commit:5.1, entity: Employee{ Aragorn CTO, $8100, Shire, subordinates: }
commit:4.1, entity: Employee{ Aragorn CTO, $8100, Minas Tirith, subordinates: }
commit:1.1, entity: Employee{ Aragorn CTO, $8000, Minas Tirith, subordinates: }javers history of salary changes:
commit:6.0, entity: Employee{ Thorin TEAM_LEAD, $5100, Lonely Mountain, subordinates: }
commit:4.1, entity: Employee{ Aragorn CTO, $8100, Minas Tirith, subordinates: }
commit:2.1, entity: Employee{ Gandalf CEO, $10100, Middle-earth, subordinates: }
比较
这两个工具再次完成了这项工作并显示了正确的历史记录。
-
按 ID 搜索。只是按预期工作。
-
按更改的属性搜索。 在这里,一开始,Envers 抛出了一个例外,我们不得不添加 表架构的修改标志。 我喜欢这些标志的设计,因为它很简单。 问题是默认情况下它们是禁用的。
如果您的应用程序在生产环境中运行了一段时间,该怎么办 而且您从一开始就没有启用标志?将它们添加到现有表中可能会很痛苦...
我认为Javers以更优雅的方式解决了这个问题。 默认情况下,每个快照都包含已更改属性名称 (in) 的列表。 快照结构是固定的,不再纠结于标志配置。jv_snapshot.changed_properties
更多查询筛选器
筛选的其他选项是什么?Envers 提供按属性值筛选:
query.add(AuditEntity.property("name").eq("John"));
// or
query.add(AuditEntity.relatedId("address").eq(addressId));这很有用。此外,您可以使用许多其他典型的 SQL:,,,, 等运算符。eqgelelikebetween
在 JaVers 中,没有属性值过滤器,我们有一个悬而未决的问题。 另一方面,JaVers 提供了一些基于 Commit 元数据的过滤器。 可以按提交作者、日期和属性进行查询:
QueryBuilder.byInstanceId("bob", Employee.class).byAuthor("Pam").build()
// or
QueryBuilder.byInstanceId("bob", Employee.class).withCommitProperty("tenant", "ACME")
// or
QueryBuilder.byInstanceId("bob", Employee.class).from(new LocalDate(2016,01,1)).to (new LocalDate(2018,01,1)).build()查看 JaVers 查询筛选器的完整列表。
重建完整的对象图
最后一项任务是竞争中最困难的部分。 我们想要重建给定时间点的完整对象图。 这意味着时间感知型联接很棘手。
在此用例中,我们加载一个员工的历史版本 我们检查相关员工是否以正确的版本加入。
为了使案件更难(也更现实),我们独立更新员工。 我们希望从Javers和Envers那里得到的是回忆那个特定的时间点。 当所有的人都有相同的薪水时——6000 美元。
given:def gandalf = hierarchyService.initStructure()def aragorn = gandalf.getSubordinate('Aragorn')def thorin = aragorn.getSubordinate('Thorin')def bombur = thorin.getSubordinate("Bombur")[gandalf,aragorn, bombur].each {hierarchyService.updateSalary(it, 6000)}hierarchyService.giveRaise(thorin, 1000)//this state we want to reconstruct,//when all the four guys have salary $6000gandalf.prettyPrint()[gandalf, aragorn, thorin, bombur].each {hierarchyService.giveRaise(it, 500)}让我们从Envers开始挑战。
恩弗斯方式
EnversQueryTest.groovy#L102
@Transactional
def "should reconstruct a full object graph with Envers"(){given:...when:def start = System.currentTimeMillis()List thorins = AuditReaderFactory.get(entityManager).createQuery().forRevisionsOfEntity( Employee, false, true ).add( AuditEntity.id().eq( 'Thorin' ) ).getResultList()then:def thorinShadow = thorins.collect{it[0]}.find{it.salary == 6000}[thorinShadow,thorinShadow.getBoss(),thorinShadow.getBoss().getBoss(),thorinShadow.getSubordinate("Bombur")].each{println itassert it.salary == 6000}println "Envers query executed in " + (System.currentTimeMillis() - start) + " millis"
}转换器输出:
Employee{ Thorin TEAM_LEAD, $6000, Lonely Mountain, subordinates:'Bombur','Frodo','Fili','Kili','Bifur' }
Employee{ Aragorn CTO, $6000, Minas Tirith, subordinates:'Thorin' }
Employee{ Gandalf CEO, $6000, Middle-earth, subordinates:'Aragorn','Elrond' }
Employee{ Bombur SCRUM_MASTER, $6000, Lonely Mountain, subordinates: }
Envers query executed in 47 millis
贾弗斯方式
JaversQueryTest.groovy#L90
def "should reconstruct a full object graph with JaVers"(){given:... when:def start = System.currentTimeMillis()List<Shadow<Employee>> shadows = javers.findShadows(QueryBuilder.byInstanceId('Thorin', Employee).withScopeDeepPlus().build())then:def thorinShadow = shadows.collect{it.get()}.find{it.salary == 6000}[thorinShadow,thorinShadow.getBoss(),thorinShadow.getBoss().getBoss(),thorinShadow.getSubordinate("Bombur")].each{println itassert it.salary == 6000}println "JaVers query executed in " + (System.currentTimeMillis() - start) + " millis"
}贾弗斯输出:
Employee{ Thorin TEAM_LEAD, $6000, Lonely Mountain, subordinates:'Bombur','Frodo','Fili','Kili','Bifur' }
Employee{ Aragorn CTO, $6000, Minas Tirith, subordinates:'Thorin' }
Employee{ Gandalf CEO, $6000, Middle-earth, subordinates:'Aragorn','Elrond' }
Employee{ Bombur SCRUM_MASTER, $6000, Lonely Mountain, subordinates: }
JaVers query executed in 48 millis比较
这两个工具都成功地重建了正确的对象图。 索林的版本与 正确的阿拉贡版本,与正确的
甘道夫版本相连。 信不信由你,这种重建并非微不足道 因为它是在不知道时间维度的普通 SQL 数据库之上实现的。
性能基准超出了本文的范围。 当您尝试在生产数据库上重建大型对象图时, 您可能会在 JaVers 和 Envers 中面临性能问题。
在 JaVers 中,您可以启用一个简单的探查器工具,该工具记录查询执行统计信息 到标准记录器:slf4j
<logger name="org.javers.JQL" level="DEBUG"/>
然后,可以分析 JQL 查询执行中的日志:
[main] org.javers.core.Javers : Commit(id:6.1, snapshots:1, author:unknown, changes - ValueChange:1), done in 68 millis (diff:64, persist:4)
[main] org.javers.core.Javers : Commit(id:7.1, snapshots:1, author:unknown, changes - ValueChange:1), done in 54 millis (diff:52, persist:2)
[main] org.javers.core.Javers : Commit(id:8.0, snapshots:1, author:unknown, changes - ValueChange:1), done in 66 millis (diff:64, persist:2)
[main] org.javers.core.Javers : Commit(id:9.0, snapshots:1, author:unknown, changes - ValueChange:1), done in 62 millis (diff:57, persist:5)
[main] org.javers.JQL : SHALLOW query: 4 snapshots loaded (entities: 3, valueObjects: 1)
[main] org.javers.JQL : DEEP_PLUS query for '...Employee/Aragorn' at commitId 8.0, 4 snapshot(s) loaded, gaps filled so far: 1
[main] org.javers.JQL : DEEP_PLUS query for '...Employee/Gandalf' at commitId 8.0, 4 snapshot(s) loaded, gaps filled so far: 2
[main] org.javers.JQL : DEEP_PLUS query for '...Employee/Elrond' at commitId 8.0, 2 snapshot(s) loaded, gaps filled so far: 3
[main] org.javers.JQL : DEEP_PLUS query for '...Employee/Frodo' at commitId 8.0, 2 snapshot(s) loaded, gaps filled so far: 4
[main] org.javers.JQL : DEEP_PLUS query for '...Employee/Kili' at commitId 8.0, 2 snapshot(s) loaded, gaps filled so far: 5
[main] org.javers.JQL : DEEP_PLUS query for '...Employee/Fili' at commitId 8.0, 2 snapshot(s) loaded, gaps filled so far: 6
[main] org.javers.JQL : DEEP_PLUS query for '...Employee/Bifur' at commitId 8.0, 2 snapshot(s) loaded, gaps filled so far: 7
[main] org.javers.JQL : DEEP_PLUS query for '...Employee/Bombur' at commitId 8.0, 3 snapshot(s) loaded, gaps filled so far: 8
[main] org.javers.JQL : queryForShadows executed:
JqlQuery {IdFilter{ globalId: ...Employee/Thorin }QueryParams{ aggregate: true, limit: 100 }ShadowScopeDefinition{ shadowScope: DEEP_PLUS, maxGapsToFill: 10 }Stats{ executed in millis: 36 DB queries: 9 all snapshots: 25 SHALLOW snapshots: 4 DEEP_PLUS snapshots: 21 gaps filled: 8 }
}经验法则 — 尽量保持每个 JQL 查询执行的数据库查询数 尽可能小。使用正确的影子范围(阅读有关范围的更多信息)。
其他查询类型
Envers 只有一种类型的查询结果 — 对象的历史版本,这是对象历史的最自然视图。
在JaVers中,这种查询类型称为影子查询(这就是我们在查询示例中使用的原因)。 除此之外,JaVers 还提供了另外两种查询类型:快照查询和更改查询。findShadows()
快照包含与阴影相同的数据,但它们已冻结。什么意思?
- 快照是 JaVers 类的一个实例, 而影子只是用户域类的一个实例。
CdoSnapshot - 快照是独立的,可以轻松地序列化/反序列化为 JSON 并通过网络发送。 例如,当您为前端应用程序构建 REST API 时,快照可能很有用 (请参阅我们如何在JaVers GUI 的 POC 中使用快照)。
更改是将对象历史记录呈现为统一更改日志的最佳选择。 JaVers 提供了格式化程序,它创建的文本更改日志如下所示:SimpleTextChangeLog
commit 3.0, author: hr.manager, 2015-04-16 22:16:50changed object: Employee/Boblist changed on 'subordinates' property: [(0).added:'Employee/Trainee One', (1).added:'Employee/Trainee Two']
commit 2.0, author: hr.director, 2015-04-16 22:16:50changed object: Employee/Bobvalue changed on 'position' property: 'Scrum master' -> 'Team Lead'value changed on 'salary' property: '9000' -> '11000' 实现自己的更改日志格式化程序很容易(请参阅示例)。
结语
那么哪种工具更好呢?
作为Javers的作者,我在回答这个问题时不能客观 (你可以很容易地猜到我的意见)。 事实上,本文的目的是提供Javers和Envers的公平比较。 这为您提供了足够的信息来做出有意识的决定。
![[附源码]计算机毕业设计springboot餐馆点餐管理系统](https://img-blog.csdnimg.cn/680a81d53114401cb1710cd74fd42c62.png)
![[附源码]计算机毕业设计springboot房屋租赁系统](https://img-blog.csdnimg.cn/31f1ef3b9dd947d7b8d47829bbcd6460.png)



![[附源码]计算机毕业设计springboot飞越青少儿兴趣培训机构管理系统](https://img-blog.csdnimg.cn/d191a39367534940a875fb7ec2f5c56f.png)

![[附源码]SSM计算机毕业设计校园爱心支愿管理系统JAVA](https://img-blog.csdnimg.cn/b435b25ae6234137bf8a2a18ac2b3353.png)