目录
0. 相关文章链接
1. 概述
2. socket source
3. file source
3.1. 读取普通文件夹内的文件
3.2. 读取自动分区的文件夹内的文件
4. kafka source
4.1. 导入依赖
4.2. 以 Streaming 模式创建 Kafka 工作流
4.3. 通过 Batch 模式创建 Kafka 工作流
5. Rate Source
0. 相关文章链接
Spark文章汇总
1. 概述
使用 Structured Streaming 最重要的就是对 Streaming DataFrame 和 Streaming DataSet 进行各种操作。从 Spark2。0 开始, DataFrame 和 DataSet 可以表示静态有界的表, 也可以表示流式无界表。与静态 Datasets/DataFrames 类似,我们可以使用公共入口点 SparkSession 从流数据源创建流式 Datasets/DataFrames,并对它们应用与静态 Datasets/DataFrames 相同的操作。通过spark.readStream()得到一个DataStreamReader对象, 然后通过这个对象加载流式数据源, 就得到一个流式的 DataFrame。
// 1. 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSession
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()
import spark.implicits._// 2. 从数据源(socket)中加载数据.
val lines: DataFrame = spark.readStream.format("socket") // 设置数据源.option("host", "localhost").option("port", 9999).loadspark 内置了几个流式数据源, 基本可以满足我们的所有需求:
- File source 读取文件夹中的文件作为流式数据。 支持的文件格式: text, csv, josn, orc, parquet。 注意, 文件必须放置的给定的目录中, 在大多数文件系统中, 可以通过移动操作来完成。
- kafka source 从 kafka 读取数据。 目前兼容 kafka 0。10。0+ 版本
- socket source 用于测试。 可以从 socket 连接中读取 UTF8 的文本数据。 侦听的 socket 位于驱动中。 注意, 这个数据源仅仅用于测试。
- rate source 用于测试。 以每秒指定的行数生成数据,每个输出行包含一个 timestamp 和 value。其中 timestamp 是一个 Timestamp类型(信息产生的时间),并且 value 是 Long 包含消息的数量。 用于测试和基准测试。
| Source | Options | Fault-tolerant | Notes |
| File source | path: path to the input directory, and common to all file formats. maxFilesPerTrigger: maximum number of new files to be considered in every trigger (default: no max) latestFirst: whether to process the latest new files first, useful when there is a large backlog of files (default: false) fileNameOnly: whether to check new files based on only the filename instead of on the full path (default: false). With this set to true, the following files would be considered as the same file, because their filenames, “dataset.txt”, are the same: “file:///dataset.txt” “s3://a/dataset.txt” “s3n://a/b/dataset.txt” “s3a://a/b/c/dataset.txt” For file-format-specific options, see the related methods in DataStreamReader(Scala/Java/Python/R). E.g. for “parquet” format options see DataStreamReader.parquet(). In addition, there are session configurations that affect certain file-formats. See the SQL Programming Guide for more details. E.g., for “parquet”, see Parquet configuration section. | Yes | Supports glob paths, but does not support multiple comma-separated paths/globs. |
| Socket Source | host: host to connect to, must be specified port: port to connect to, must be specified | No | |
| Rate Source | rowsPerSecond (e.g. 100, default: 1): How many rows should be generated per second. rampUpTime (e.g. 5s, default: 0s): How long to ramp up before the generating speed becomes rowsPerSecond. Using finer granularities than seconds will be truncated to integer seconds. numPartitions (e.g. 10, default: Spark’s default parallelism): The partition number for the generated rows. The source will try its best to reach rowsPerSecond, but the query may be resource constrained, and numPartitions can be tweaked to help reach the desired speed. | Yes | |
| Kafka Source | See the Kafka Integration Guide. | Yes |
2. socket source
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
import org.apache.spark.sql.streaming.StreamingQueryobject StreamTest {def main(args: Array[String]): Unit = {// 1. 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSessionval spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()import spark.implicits._// 2. 从数据源(socket)中加载数据.val lines: DataFrame = spark.readStream.format("socket") // 设置数据源.option("host", "localhost").option("port", 9999).load// 3. 把每行数据切割成单词val words: Dataset[String] = lines.as[String].flatMap((_: String).split("\\W"))// 4. 计算 word countval wordCounts: DataFrame = words.groupBy("value").count()// 5. 启动查询, 把结果打印到控制台val query: StreamingQuery = wordCounts.writeStream.outputMode("complete").format("console").startquery.awaitTermination()spark.stop()}
}
3. file source
3.1. 读取普通文件夹内的文件
代码示例:
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
import org.apache.spark.sql.streaming.{StreamingQuery, Trigger}
import org.apache.spark.sql.types.{LongType, StringType, StructType}object StreamTest {def main(args: Array[String]): Unit = {// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSessionval spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()import spark.implicits._// 定义 Schema, 用于指定列名以及列中的数据类型val userSchema: StructType = new StructType().add("name", StringType).add("job", StringType).add("age", LongType)// 使用SparkSession通过readStream方法读取文件(必须是目录, 不能是文件名)val user: DataFrame = spark.readStream.format("csv").schema(userSchema).load("/Project/Data/csv")// DataStreamReader中还有csv、json、text等方法,可以直接读取对应的文件val userCopy: DataFrame = spark.readStream.schema(userSchema).csv("/Project/Data/csv")// 将对应的数据输出(trigger表示触发器:数字表示毫秒值. 0 表示立即处理)val query: StreamingQuery = user.writeStream.outputMode("append").trigger(Trigger.ProcessingTime(0)).format("console").start()// 启动执行器query.awaitTermination()spark.stop()}
}
模板数据:
lisi,male,18
zhiling,female,28
结果输出:

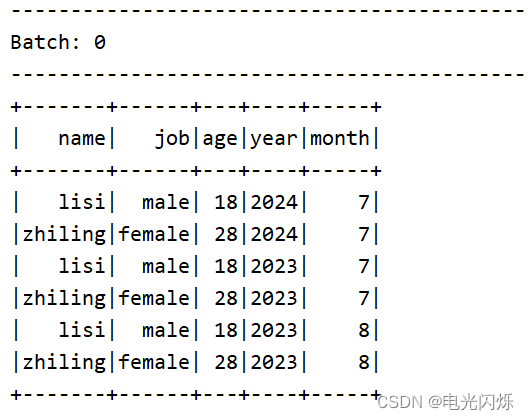
3.2. 读取自动分区的文件夹内的文件
当文件夹被命名为 “key=value” 形式时, Structured Streaming 会自动递归遍历当前文件夹下的所有子文件夹, 并根据文件名实现自动分区。如果文件夹的命名规则不是“key=value”形式, 则不会触发自动分区。 另外, 同级目录下的文件夹的命名规则必须一致。
步骤一:创建如下目录结构
year=2023month=07month=08
year=2024month=07
步骤二:写入文件数据
lisi,male,18
zhiling,female,28步骤三:编写代码(如上 读取普通文件夹内的文件 代码完全一致)
步骤四:启动运行打印日志
4. kafka source
4.1. 导入依赖
在其余Spark依赖的情况下,还需要导入如下SparkSQL的kafka依赖,参考文档: Structured Streaming + Kafka Integration Guide (Kafka broker version 0.10.0 or higher) - Spark 3.4.1 Documentation
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql-kafka-0-10_2.12</artifactId><version>2.4.3</version>
</dependency>
4.2. 以 Streaming 模式创建 Kafka 工作流
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}object StreamTest {def main(args: Array[String]): Unit = {// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSessionval spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()import spark.implicits._// 使用spark通过readStream方法可以以流的方式读取kafka里面的数据// 通过format设置 kafka 数据源// 通过 kafka.bootstrap.servers 设置kafka的参数// 通过 subscribe 设置订阅的主题,也可以订阅多个主题: "topic1,topic2"// load后会返回一个DataFrame类型, 其schema是固定的: key,value,topic,partition,offset,timestamp,timestampTypeval df: DataFrame = spark.readStream.format("kafka").option("kafka.bootstrap.servers", "bigdata1:9092,bigdata2:9092,bigdata3:9092").option("subscribe", "topic1").load// 通过 selectExpr 只获取其中的value字段// 通过as转换成 Datasetval lines: Dataset[String] = df.selectExpr("CAST(value AS string)").as[String]// 可以对 Dataset 进行各种操作val query: DataFrame = lines.flatMap((_: String).split("\\W+")).groupBy("value").count()// 进行输出,并且可以通过checkpointLocation来设置checkpoint// 下次启动的时候, 可以从上次的位置开始读取query.writeStream.outputMode("complete").format("console").option("checkpointLocation", "./ck1") .start.awaitTermination()// 关闭执行环境spark.stop()}
}4.3. 通过 Batch 模式创建 Kafka 工作流
这种模式一般需要设置消费的其实偏移量和结束偏移量, 如果不设置 checkpoint 的情况下, 默认起始偏移量 earliest, 结束偏移量为 latest。该模式为一次性作业(批处理), 而非持续性的处理数据。
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}object StreamTest {def main(args: Array[String]): Unit = {// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSessionval spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()import spark.implicits._// 使用 read 方法,而不是 readStream 方法val lines: Dataset[String] = spark.read.format("kafka").option("kafka.bootstrap.servers", "bigdata1:9092,bigdata2:9092,bigdata3:9092").option("subscribe", "topic1").option("startingOffsets", "earliest").option("endingOffsets", "latest").load.selectExpr("CAST(value AS STRING)").as[String]// 同样对 Dataset[String] 进行各种操作val query: DataFrame = lines.flatMap(_.split("\\W+")).groupBy("value").count()// 使用 write 而不是 writeStreamquery.write.format("console").save()// 关闭执行环境spark.stop()}
}5. Rate Source
以固定的速率生成固定格式的数据, 用来测试 Structured Streaming 的性能
import org.apache.spark.sql.streaming.Trigger
import org.apache.spark.sql.{DataFrame, SparkSession}object StreamTest {def main(args: Array[String]): Unit = {// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSessionval spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()import spark.implicits._val rows: DataFrame = spark.readStream.format("rate") // 设置数据源为 rate.option("rowsPerSecond", 10) // 设置每秒产生的数据的条数, 默认是 1.option("rampUpTime", 1) // 设置多少秒到达指定速率 默认为 0.option("numPartitions", 2) /// 设置分区数 默认是 spark 的默认并行度.loadrows.writeStream.outputMode("append").trigger(Trigger.Continuous(1000)).format("console").start().awaitTermination()// 关闭执行环境spark.stop()}
}注:其他Spark相关系列文章链接由此进 -> Spark文章汇总