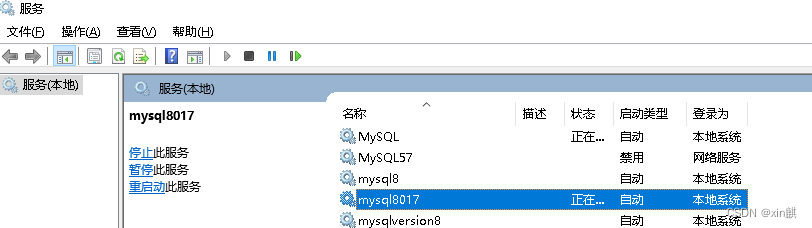
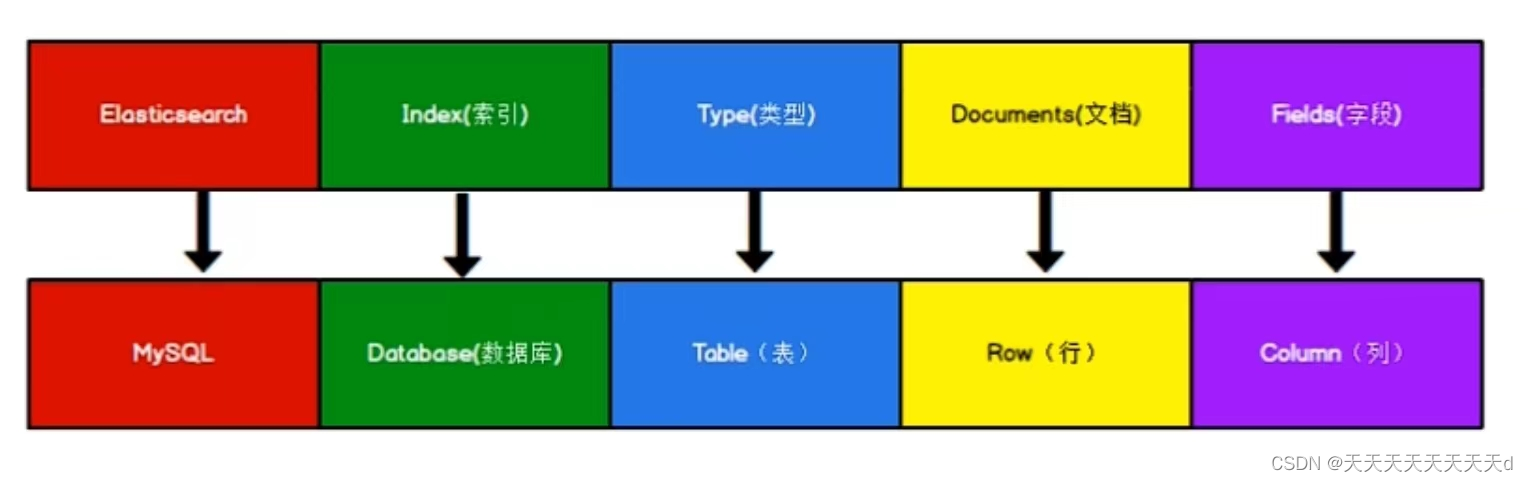
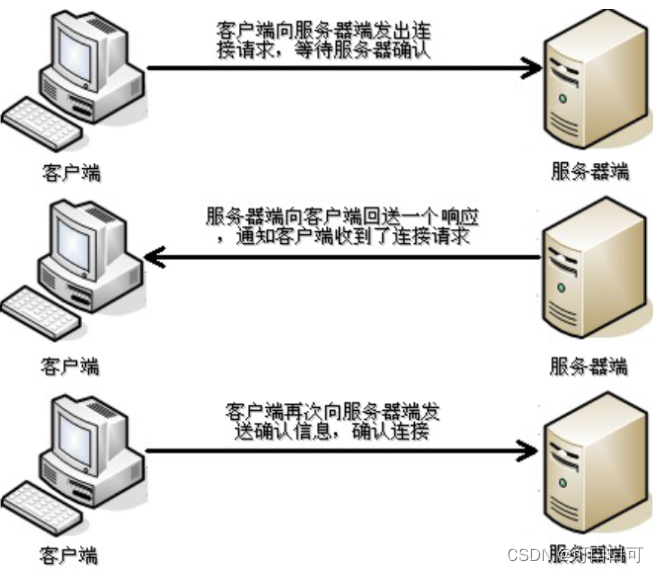
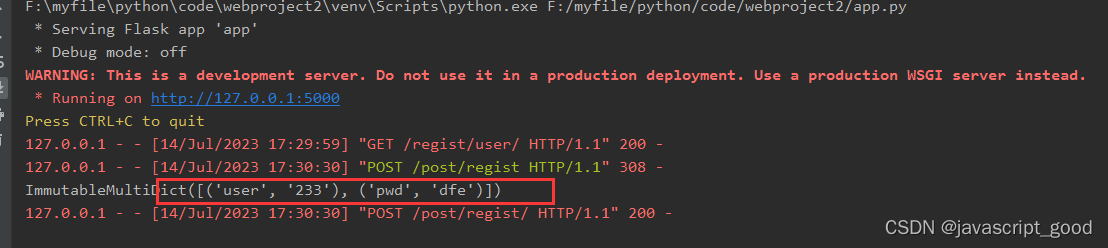
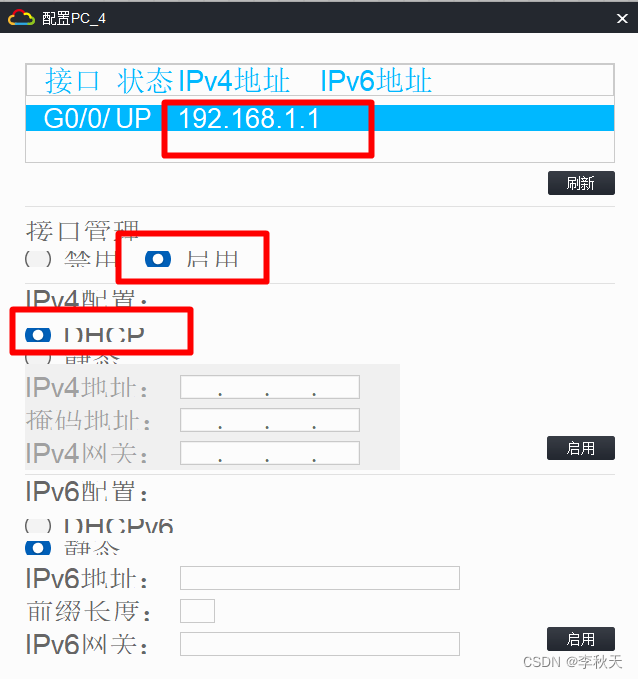
强化学习算法 TD3 论文:Addressing Function Approximation Error in Actor-Critic Methods 2018.10. ,作者本人的 TD3 代码,PyTroch 实现
与原版 DDPG 相比,TD3 的改动可以概括为:
- 使用与双 Q 学习(Double DQN)相似的思想:使用两个 Critic(估值网络 Q(s, a))对动作 - 值进行评估,训练的时候取 min ( Q θ 1 ( s , a )
强化学习算法 TD3 论文:Addressing Function Approximation Error in Actor-Critic Methods 2018.10. ,作者本人的 TD3 代码,PyTroch 实现
与原版 DDPG 相比,TD3 的改动可以概括为:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.luyixian.cn/news_show_331226.aspx
如若内容造成侵权/违法违规/事实不符,请联系dt猫网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!