本章论文:
YOLOv3论文(YOLOv3: An Incremental Improvement)(原文+解读/总结+翻译)
系列论文:
YOLOv1论文解读/总结_yolo论文原文_耿鬼喝椰汁的博客-CSDN博客
YOLOv2论文解读/总结_耿鬼喝椰汁的博客-CSDN博客
目录
前言
YOLOv3:
YOLOv3保留的东西:
YOLOv3的改进:
v3最主要的改进之处为以下三点:
一、网络的改进
二、多尺度预测
三、单标签分类改进为多标签分类
一些失败的尝试
前言
目标检测长期发展以来two-stage算法(RCNN系列)占据地位,直至YOLO和SSD等one-stage算法的出现。
从R-CNN到Faster R-CNN一直采用的思路是proposal+分类 (proposal 提供位置信息, 分类提供类别信息)精度已经很高,但由于two-stage(proposal耗费时间过多)处理速度不行达不到real-time效果。
YOLOv1和YOLOv2给目标检测带来了曙光,但也存在很多问题:
(1)定位不准确
(2)和基于region proposal的方法相比召回率较低。
不论是YOLOv1,还是YOLOv2,都有一个共同的致命缺陷:只使用了最后一个经过32倍降采样的特征图(简称C5特征图)。尽管YOLOv2使用了passthrough技术将16倍降采样的特征图(即C4特征图)融合到了C5特征图中,但最终的检测仍是在C5尺度的特征图上进行的,最终结果便是导致了模型的小目标的检测性能较差。
为了解决这一问题,YOLO作者做了第三次改进,不仅仅是使用了更好的主干网络:DarkNet-53,更重要的是使用了FPN技术与多级检测方法,相较于YOLO的前两代,YOLOv3的小目标的检测能力提升显著。
那么,在本文章,就让我们一起来领略一下YOLOv3的强大风采吧。
YOLOv3:
YOLOv3正如作者所说,这仅仅是他们近一年的一个工作报告(TECH REPORT),不算是一个完整的paper,因为他们实际上是把其它论文的一些工作在YOLO上尝试了一下。
YOLOv3除了网络结构,其余变动不多,大部分思想延续前两代YOLO的思想:YOLOv3在YOLOv2的基础上改良了网络的主干,利用多尺度特征图进行检测,改进了多个独立的Logistic regression分类器来取代softmax来预测类别分类。
YOLOv3保留的东西:
YOLOv3保留v1和v2中的特性如下:
- 从YOLOv1开始,yolo算法就是通过划分单元格grid cell来做检测,只是划分的数量不一样。
- 采用"leaky ReLU"作为激活函数。
- 端到端进行训练,统一为回归问题。一个loss function搞定训练,只需关注输入端和输出端。
- 从yolo_v2开始,yolo就用batch normalization作为正则化、加速收敛和避免过拟合的方法,把BN层和leaky relu层接到每一层卷积层之后。
- 多尺度训练。想速度快点,可以牺牲准确率;想准确率高点,可以牺牲一点速度。
- 沿用了v2中边框预测的方法
YOLOv3的改进:
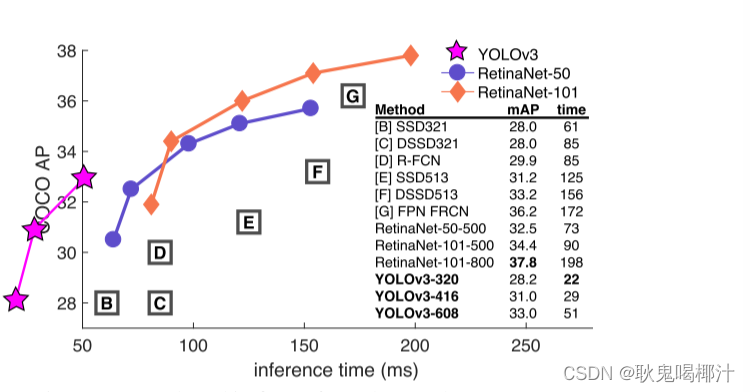
yolo每一代的提升很大一部分决定于backbone网络的提升,从v2的darknet-19到v3的darknet-53。yolo_v3还提供为了速度而生的轻量级主干网络backbone——tiny darknet。速度改进如下:
v3最主要的改进之处为以下三点:
- 1. 更好的backbone(骨干网络)(从v2的darknet-19到v3的darknet-53,类似于ResNet引入残差结构)
- 2. 多尺度预测(引入FPN)
- 3. 考虑到检测物体的重叠情况,用多标签的方式替代了之前softmax单标签方式,分类器不再使用softmax(darknet-19中使用),损失函数中采用binary cross-entropy loss(二分类交叉损失熵)
一、网络的改进
YOLOv3的第一处改进便是换上了更好的backbone网络(骨干网络提取出图像中好的特征来实现我们所需的目标):DarkNet53。相较于YOLOv2中所使用的DarkNet19,新的网络使用了更多的卷积——53层卷积,同时,添加了残差网络中的残差连结结构,以提升网络的性能。
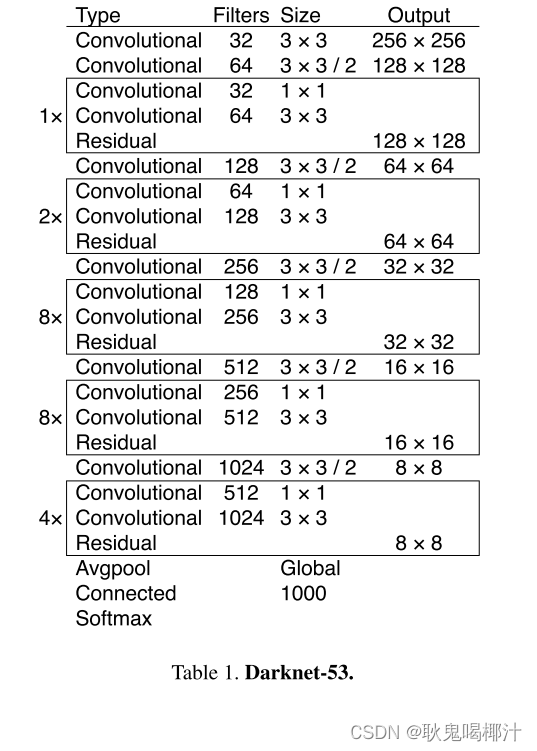
这个网络主要是由一系列的1x1和3x3的卷积层组成(每个卷积层后都会跟一个BN层和一个LeakyReLU)层,作者说因为网络中有53个convolutional layers,所以叫做Darknet-53(2 + 1x2 + 1 + 2x2 + 1 + 8x2 + 1 + 8x2 + 1 + 4x2 + 1 = 53 按照顺序数,最后的Connected是全连接层也算卷积层,一共53个)。
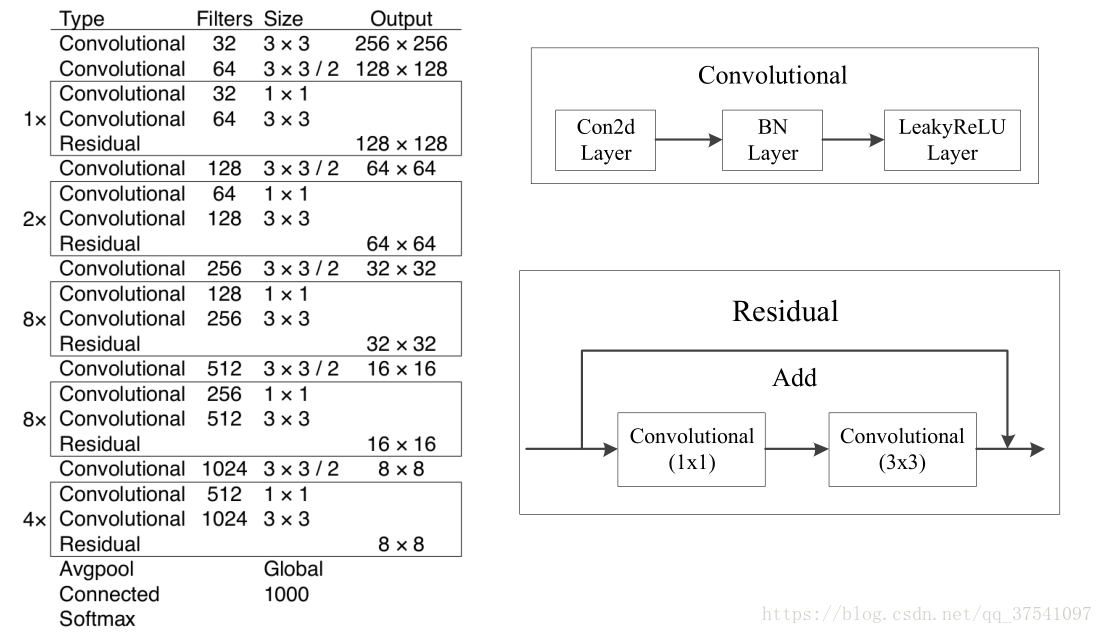
注意,DarkNet53网络中的降采样操作没有使用Maxpooling层,而是由stride=2的卷积来实现。卷积层仍旧是线性卷积、BN层以及LeakyReLU激活函数的串联组合。
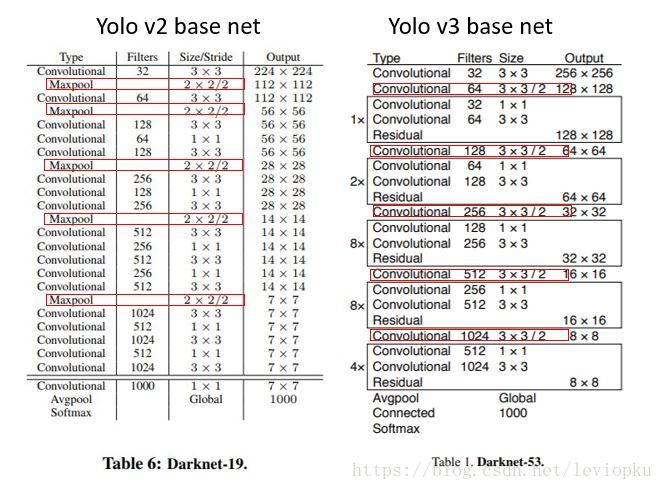
YOLOv2中对于向前传播中张量尺寸变换,都是通过最大池化来进行,一共有5次。而v3是通过卷积核增大步长来进行,也是5次。(darknet-53最后面有一个全局平均池化,在yolo-v3里面没有这一层,所以张量维度变化只考虑前面那5次)
v3和v2一样,backbone都会将输出特征图缩小到输入的1/32。所以,通常都要求输入图片是32的倍数。可以对比v2和v3的backbone看看:(DarkNet-19 与 DarkNet-53)从下图可以看出,darknet-19是不存在残差结构(resblock,从resnet上借鉴过来)的,和VGG是同类型的backbone(属于上一代CNN结构)
二、多尺度预测
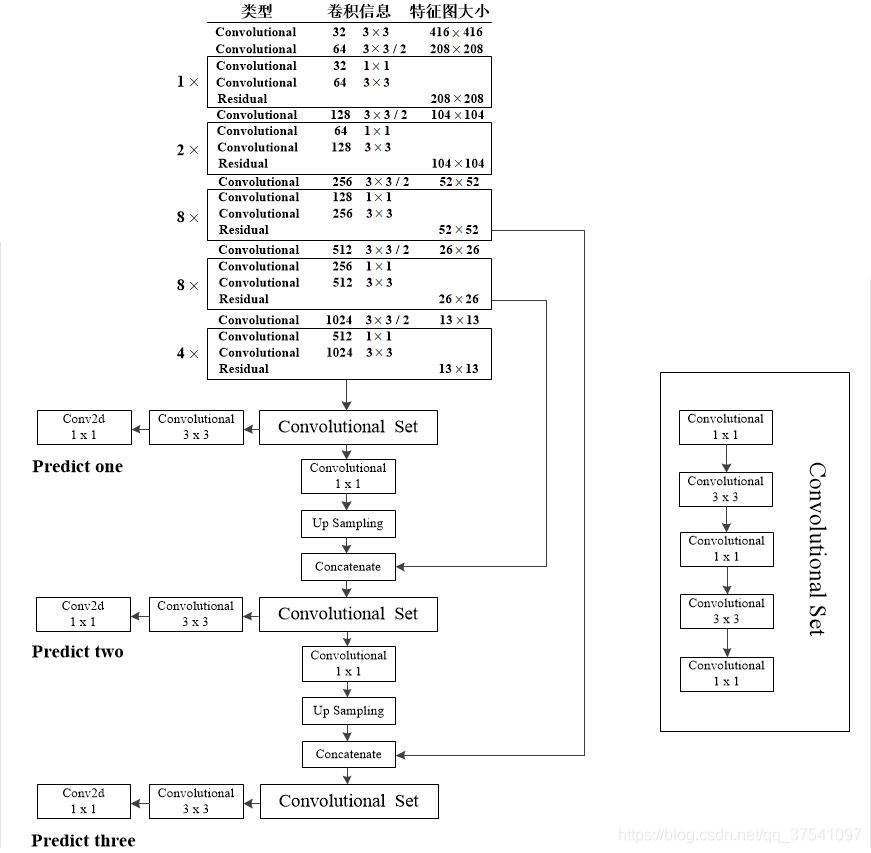
YOLOv3借鉴了FPN的方法,采用多尺度的特征图对不同大小的物体进行检测,以提升小物体的预测能力。
YOLOv3的第二个改进是多尺度训练,是真正的多尺度,一共有3种尺度,分别是13*13,26*26,52*52三种分辨率,分别负责预测大,中,小的物体边框,这种改进对小物体检测更加友好。
YOLOv3通过下采样32倍、16倍和8倍得到3个不同尺度的特征图。例如输入416X416的图像,则会得到13X13 (416/32),26X26(416/16) 以及52X52(416/8)这3个尺度的特征图。
每种尺度预测3个box, anchor的设计方式仍然使用聚类,得到9个聚类中心,将其按照大小均分给3个尺度.
- 尺度1: 在基础网络之后添加一些卷积层再输出box信息.
- 尺度2: 从尺度1中的倒数第二层的卷积层上采样(x2)再与最后一个16x16大小的特征图相加,再次通过多个卷积后输出box信息.相比尺度1变大两倍.
- 尺度3: 与尺度2类似,使用了32x32大小的特征图.
作者在论文中提到利用三个特征层进行边框的预测,将这部分更加详细的分析展示在下图中。(图源:CSDN太阳花的小绿豆)
三、单标签分类改进为多标签分类
不管是在检测任务的标注数据集,还是在日常场景中,物体之间的相互覆盖都是不能避免的。因此一个锚点的感受野肯定会有包含两个甚至更多个不同物体的可能,在之前的方法中是选择和锚点IoU最大的Ground Truth作为匹配类别,用softmax作为激活函数。
YOLOv3多标签模型的提出,对于解决覆盖率高的图像的检测问题效果是十分显著的,YOLOv3的效果好很多,不仅检测的更精确,最重要的是被覆盖很多的物体也能很好的在YOLOv3中检测出来。
1、YOLOv3 使用的是logistic 分类器,而不是之前使用的softmax。
2、在YOLOv3 的训练中,便使用了Binary Cross Entropy ( BCE, 二元交叉熵) 来进行类别预测。
原因:
(1)softmax只适用于单目标多分类(甚至类别是互斥的假设),但目标检测任务中可能一个物体有多个标签。(属于多个类并且类别之间有相互关系),比如Person和Women。
(2)logistic激活函数来完成,这样就能预测每一个类别是or不是。
一些失败的尝试
作者在最后还提到了他们做了哪些尝试,但是发现并没有起到太大的作用:
- Anchor box坐标的偏移预测:尝试捕捉位移 (x,y) 和检测框边长 (w,ℎ) 的线性关系,这时方式得到的效果并不好且模型不稳定;
- 使用线性激活函数代替sigmoid激活函数预测位移 (x,y) ,该方法导致模型的mAP下降;
- 使用focal loss:作者还尝试使用focal loss,但它使mAP降低了2点。
这篇论文的学习和总结到这里就结束啦,如果有什么问题可以在评论区留言呀~
如果帮助到大家,可以一键三连支持下~
参考文章:
(3条消息) YOLO v3网络结构分析_yolov3网络结构_太阳花的小绿豆的博客-CSDN博客
(3条消息) yolo系列之yolo v3【深度解析】_yolov3_木盏的博客-CSDN博客
YOLO算法最全综述:从YOLOv1到YOLOv5 - 知乎 (zhihu.com)