概述
OVERVIEW
- 概述
- C++11新特性:
- C++14新特性:
- C++17新特性:
- C++20新特性:
- C++程序编译过程
- C++内存模型
- C++STL
- 1.Queue&Stack
- 2.String
- 3.Map
| C语言 | C++语言 | |
|---|---|---|
| 面向过程编程 | ✅ | ✅ |
| 面向对象编程(类和对象) | ❌ | ✅ |
| 泛型编程、元编程(模板) | ❌ | ✅ |
| 函数式编程(Lambda) | ❌ | ✅ |
| STL(function、bind、thread、智能指针) | ||
| 其他(左值与右值、深拷贝、移动构造、返回值优化) | ||
| 异常处理 | ||
| 设计模式(创建型模式4种、结构型模式7种、行为型模式7种) |

C++11新特性:
- auto关键字
- decltype关键字
- nullptr字面值
- constexpr关键字
- for (declaration : expression)
- Lambda表达式
- initializer_list(初始化列表)
- 标准库bind函数
- 智能指针shared_ptr, unique_ptr
- 右值引用&&(C++性能得到非常大的提升)
- STL容器std::array, std::forward_list, std::unordered_map, std::unordered_set
C++14新特性:
- 扩展了lambda表达式,增加泛型:支持auto
- 扩展了类型推导至任意函数:C11只支持lambda返回类型的auto
- 弃用关键字deprecated
C++17新特性:
- 扩展了constexpr至switch if等:C++11的constexpr函数只能包含一个表达式
- typename嵌套
- inline内联变量
- 模板参数推导
- 元组类std::tuple\std::pair实现两个元素的组合
- 类模板std::variant表示一个类型安全的联合体
- 引用包装器std::reference_wrapper
- 边长参数模板
- 结构化绑定(函数多值返回时用{}合成struct)
- 非类型模板参数可传入类的静态成员
- 在if和switch中可进行初始化
- 初始化(如struct)对象时可用花括号对其成员进行赋值
- 简化多层命名空间的写法
- lambda表达式可捕获*this的值,但this及其成员为只读
- 十六进制的单精度浮点数
- 继承与改写构造函数
- usingB1::B1;//表示继承B1的构造函数
- 当模板参数为非类型时,可用auto自动推导类型
- 判断有没有包含某文件
__has_include
C++20新特性:
-
concept用于声明具有特定约束条件的模板类型
template<typename T> concept number = std::is_arithmetic<T>::value; //声明一个数值类型的concept
-
范围库Ranges Library
-
协程Coroutines
-
模块Modules
C++程序编译过程

-
预处理Preprocessing:将.cpp文件转化为.i文件,
cpp -o test.i test.cpp、gcc -E test.c -o test.i预处理器把所有include的文件包括递归包含的文件内容,都展开到输出文件,并展开了所有的宏定义。
-
编译Compilation:将.cpp/.h文件转换成.s文件,
cc test.i -o test.s、gcc -S test.i -o test.x编译的过程将预处理的文件进行一系列的词法分析、语法分析、语义分析及优化成相应的汇编代码。这一步中一般会进行优化,比如去除没有用到的类的声明、循环语句的优化等。
-
汇编Assemble:将.s文件转化为.o文件,
as -o test.o test.s、gcc -c test.s -o test.oas汇编器会将汇编代码转换为机器指令,并以特定的二进制格式输出保存在目标文件中
-
链接Linking:将.o文件转换为可执行程序,
ld test.o -o test、gcc test.cld链接器将程序的相关目标文件组合链接在一起,生成程序的可执行映像文件。要解决的问题是:可能调用了库函数、或者一个目标文件中调用了另外一个文件中的库函数,需要通过链接器建立对应的关系,使程序能够正常的执行。
补充:静态链接与动态链接
- 静态链接:将源代码从静态链接库中拷贝到最终的可执行程序中,这样可能会导致最终的目标文件很大。
- 动态链接:需要调用的库函数以动态链接库的形式存在,多个进程之间共享。而链接的时候只需要知道要调用的函数的位置即可。在程序执行时当需要调用某个动态链接库中的函数式,操作系统首先会查找所有正在运行的程序,看内存中是否已经有该库函数的拷贝了,如果有则多进程之间可以共享该拷贝,否则才会将其载入到该进行的虚拟内存中。
C++内存模型
C++程序内存分为5个区:堆、栈、静态全局区、常量区、代码区

- 堆:new/malloc创建的内存,堆在内存中位于bss区和栈区之间,用于动态内存分配,一般由程序员分配和释放。
- 栈:函数中的临时变量(局部变量)、函数的参数值,由编译器自动分配释放,
- 全局区:声明变量既不在函数中也不再类中,分为未初始化和已初始化全局变量,存放静态数据、常量,程序结束后由系统释放。
- 只读常量区:存放常量字符串,程序结束后由系统释放
- 代码区:函数的定义、类定义、相关的程序逻辑(函数体的二进制代码)
补充:静态分配与动态分配
- 静态分配:指发生在程序编译和链接的阶段
- 动态分配:发生在程序的运行阶段
C++STL
如果对SLT不够熟练,在企业开发当中将会导致开发效率十分低,
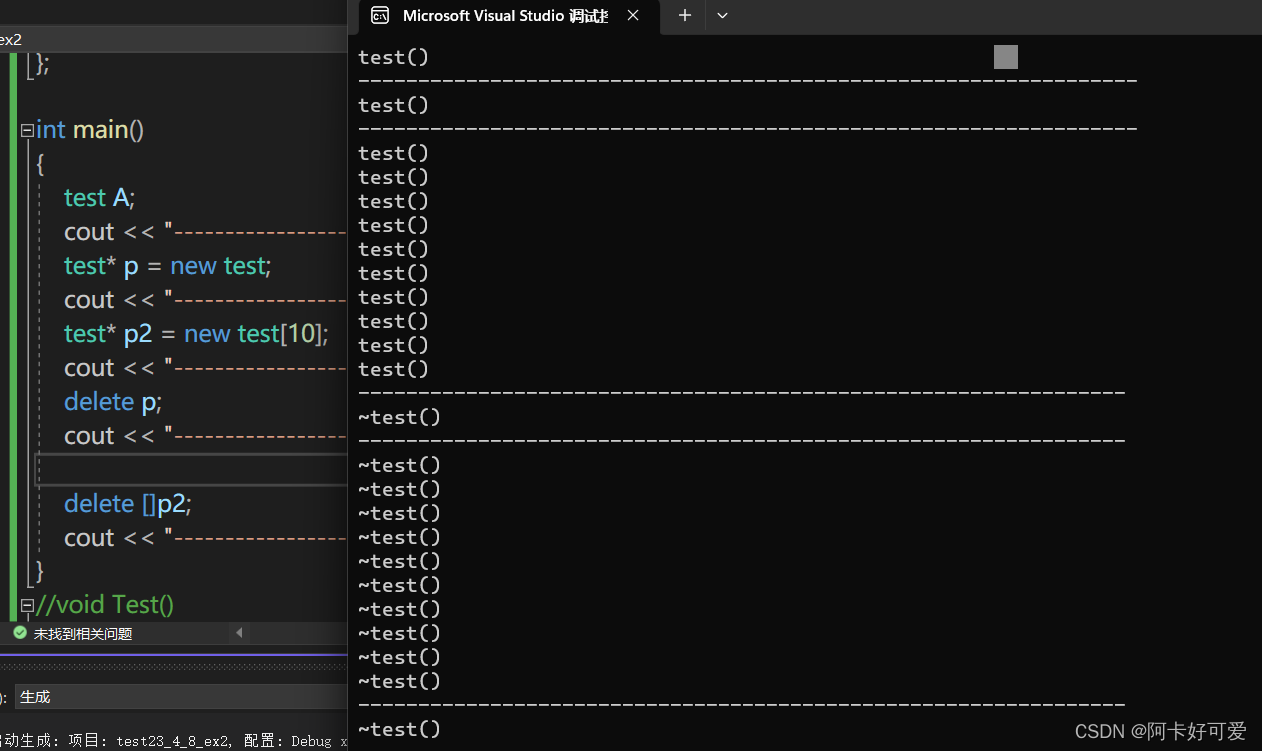
1.Queue&Stack
#include<iostream>
#include<queue>
using namespace std;int main() {queue<int> q;q.push(1);q.push(2);q.push(3);cout << "front = " << q.front() << " back = " << q.back() << " size = " << q.size() << endl;q.pop();cout << "front = " << q.front() << " back = " << q.back() << " size = " << q.size() << endl;q.pop();cout << "front = " << q.front() << " back = " << q.back() << " size = " << q.size() << endl;q.pop();cout << "front = " << q.front() << " back = " << q.back() << " size = " << q.size() << endl;q.pop();return 0;
}

可以看到虽然队列中只push了3次元素,但是使用queue进行第4次pop时程序也没有报错提醒,并且back的值居然得到了结果。
#include<iostream>
#include<stack>
using namespace std;int main() {stack<int> s;s.push(1);s.push(2);s.push(3);cout << "top = " << s.top() << " size = " << s.size() << endl;s.pop();cout << "top = " << s.top() << " size = " << s.size() << endl;s.pop();cout << "top = " << s.top() << " size = " << s.size() << endl;s.pop();cout << "top = " << s.top() << " size = " << s.size() << endl;s.pop();return 0;
}

栈中只push了3次元素,使用stack进行第4次pop时程序直接给出了segmentfault错误。
- 总结:在使用queue和stack等容器时,一定要做有效性的校验,否则拿到的数据可能会出错,或者直接导致segmentfault.
if (!q.empty()) cout << "front = " << q.front() << " back = " << q.back() << " size = " << q.size() << endl;
else cout << "queue is empty!" << endl;
if (!s.empty()) cout << "top = " << s.top() << " size = " << s.size() << endl;
else cout << "stack is empty!" << endl;
2.String
-
str1 == str2调用的是str1的方法还是str2的方法?(运算符重载)
答:理解为调用的是类对象str1的函数,而str2作为参数传入函数中,str1是一个this指针(this对象是str1)
-
str1=“abcdefg”; str1[7]=‘K’;不报错,而str1[20]=‘K’;报错segmentation fault的原因?
答:string对象会进行自动扩容1.5~2倍(编译器决定)
#include<iostream> #include<string> using namespace std;int main() {string str1 = "helloworld";cout << "str1 = " << str1 << " size = " << str1.size() << endl;cout << "str1[0] = " << str1[0] << endl;cout << "str1[9] = " << str1[9] << endl;cout << "str1[10] = " << str1[10] << endl;cout << "str1[11] = " << str1[11] << endl;cout << "str1[12] = " << str1[12] << endl;cout << "str1[13] = " << str1[13] << endl;cout << "str1[20] = " << str1[20] << endl;cout << "str1[50] = " << str1[50] << endl;cout << "str1[120] = " << str1[120] << endl;int n = 1000;while (n--) str1 += "T";cout << "str1 = " << str1 << " size = " << str1.size() << endl;return 0; }
-
str1.length()与strlen(str1)的区别?
答:strlen的时间复杂度为O(n),而string.length的时间复杂度为O(1),string类中存储着length的大小,strlen为遍历方式
#include<iostream> #include<string> #include<cstring> using namespace std;int main() {int n = 100000000;string s1;while (n--) s1 += 'T';long start = clock();int size = s1.size();cout << "c++ size = " << size << " time = " << clock() - start << endl;start = clock();size = strlen(s1.c_str());cout << "c size = " << size << " time = " << clock() - start << endl;return 0; }
很明显的计算时间的差异
-
cout对字符串的输出结束判定是通过str.size()的,而不是像C语言一样通过字符串末尾的
\0。 -
直接使用
str[11] = T等赋值操作无法像+=操作一样新增string字符串内容并触发string.size的修改。
3.Map
| Map | 头文件 | 命名空间 |
|---|---|---|
| hash_map | <hash_map>/<ext/hash_map> | __gnu_cxx; |
| unordered_map | <unordered_map> | std |
-
映射过程是根据哈希函数进行映射的,结果是乱序的,hash_map底层是利用数组实现的,在数组上再挂在链表。
-
使用map时需要预先进行find查找,以免访问未分配空间造成size增加!
#include<iostream> #include<unordered_map> using namespace std;int main() {unordered_map<string, int> hashmap;hashmap["abc"] = 1;hashmap["abcd"] = 2;hashmap["abcde"] = 3;hashmap.insert(pair<string, int>("adcdef", 4));cout << "size = " << hashmap.size() << endl;cout << "hashmap[\"hello\"] = " << hashmap["hello"] << endl;//访问非法空间则自动生成一个默认的类型cout << "size = " << hashmap.size() << endl;return 0; }
auto it = hashmap.find("hello"); if (it != hashmap.end()) cout << "hashmap[\"hello\"] = " << hashmap["hello"] << endl; else cout << "hashmap[\"hello\"] is not exist!" << endl; -
当map集合非常大时,使用swap方法比直接使用运算符重载的=进行赋值更快!
swap方法将两个数据集进行对换,对换的过程中没有出现内存的拷贝,速度比使用重载的赋值运算符更快。
#include<iostream> #include<map> using namespace std;int main() {map<int, int> mymap1;int n = 10000;while (n--) mymap1[n] = 2;//map集合的数据集非常大10000条数据unsigned long tick = clock();map<int, int> mymap2 = mymap1;cout << "time(operator) = " << clock() - tick << endl;//直接使用运算符重载时消耗的时间tick = clock();map<int, int> mymap3;mymap3.swap(mymap1);cout << "time(switch) = " << clock() - tick << endl;//使用switch方法对换数据消耗的时间return 0; }
-
遍历hashmap
int main() {unordered_map<string, int> hashmap;hashmap["abc"] = 1;hashmap["abcd"] = 2;hashmap["abcde"] = 3;hashmap.insert(pair<string, int>("adcdef", 4));cout << "size = " << hashmap.size() << endl;auto it = hashmap.find("hello");if (it != hashmap.end()) cout << "hashmap[\"hello\"] = " << hashmap["hello"] << endl;else cout << "hashmap[\"hello\"] is not exist!" << endl;for (auto it = hashmap.begin(); it != hashmap.end(); ++it) {cout << "key = " << it->first << "\tvalue = " << it->second << endl;}for (auto it : hashmap) {cout << "key = " << it.first << "\tvalue = " << it.second << endl;}return 0; }







![[JavaEE]----Spring03](https://img-blog.csdnimg.cn/abd888e6246e43fcb6a199e363d2300d.png)