文章目录
- 一 JDBC的PreparedStatement
- 二 prepareStatement的准备阶段
- 2.1 获取Connection
- 2.1.1 **UnpooledDataSource**
- 2.1.2 PooledDataSource
- 2.2 Sql的预编译PreparedStatementHandler
- 2.3 为Statement设置参数
- 2.4 执行具体的语句过程
- 官网:mybatis – MyBatis 3 | 简介
- 参考书籍:《通用源码阅读指导书:MyBatis源码详解》 易哥
- 参考文章:Mybatis源码解析
- CSDN:Mybatis源码分析_长安不及十里的博客-CSDN博客
- 掘金:稀土掘金
- 语雀文档地址:Mybatis 源码分析
- 个人博客地址:mybatis – 疯狂的程序员
上一篇文章我们分析了,Select的语句的执行过程,但是在与数据库打交道的那一块,我们没有详细介绍,下面我们来看看Mybatis中是如何与数据库打交道的?
SimpleExecutor
@Overridepublic <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {Statement stmt = null;try {Configuration configuration = ms.getConfiguration();// 创建处理器 StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);// 预编译参数 stmt = prepareStatement(handler, ms.getStatementLog());return handler.query(stmt, resultHandler);} finally {closeStatement(stmt);}}
一 JDBC的PreparedStatement
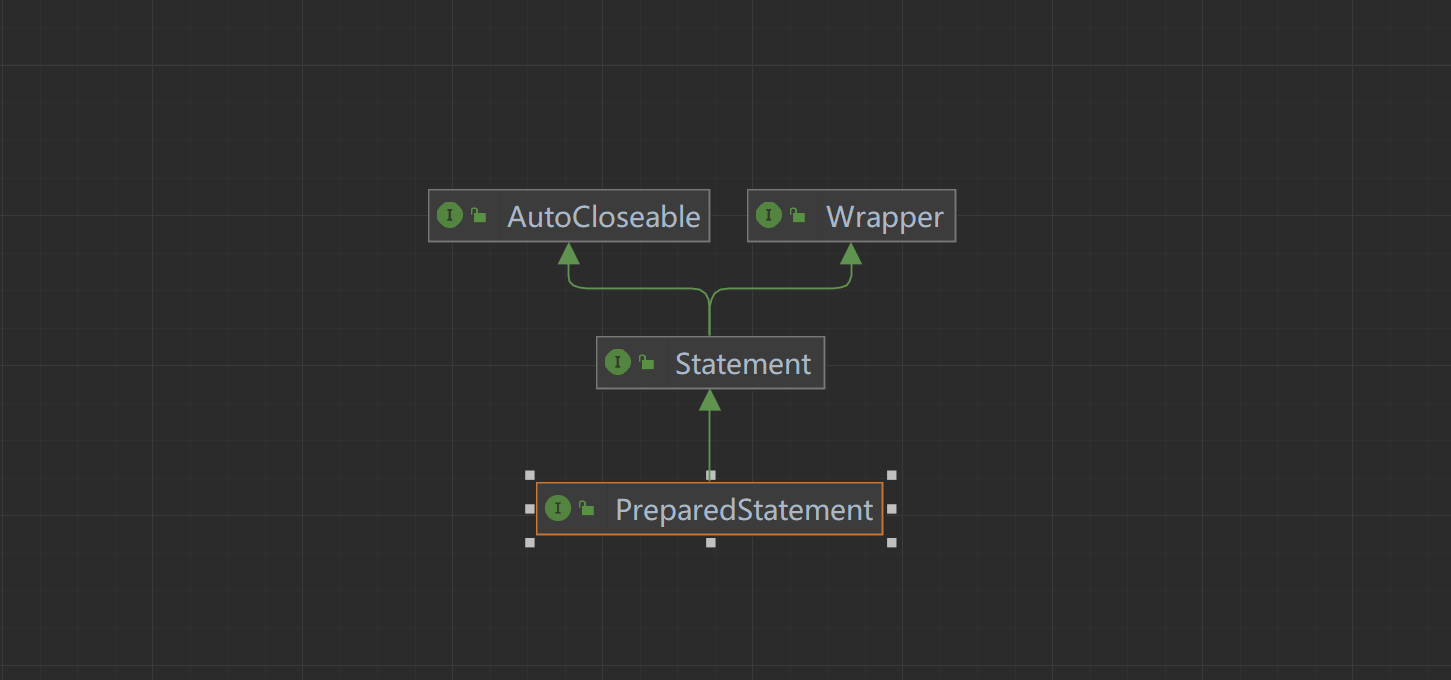
文档说明:
表示预编译SQL语句的对象。 SQL语句被预编译并存储在PreparedStatement对象中。然后,可以使用该对象多次有效地执行此语句。 注意:用于设置IN形参值的setter方法(setShort、setString等)必须指定与输入形参定义的SQL类型兼容的类型。例如,如果IN参数的SQL类型为INTEGER,则应该使用方法setInt。 如果需要任意参数类型转换,则应该将方法setObject与目标SQL类型一起使用。 在下面的参数设置示例中,con表示活动连接:
PreparedStatement pstmt = con.prepareStatement("UPDATE EMPLOYEES . 设定工资= ?Where id = ?");
pstmt.setBigDecimal (153833.00)
pstmt.setInt (110592)
JDBC中java.sql.PreparedStatement是java.sql.Statement的子接口,它主要提供了无参数执行方法如executeQuery和executeUpdate等,以及大量形如set{Type}(int, {Type})形式的方法用于设置参数。
PreparedStatement
public interface PreparedStatement extends Statement {// 执行PreparedStatement对象中的SQL查询,并返回由该查询生成的ResultSet对象。ResultSet executeQuery() throws SQLException;// 执行PreparedStatement对象中的SQL语句,该语句必须是SQL数据操作语言(DML)语句,如INSERT、UPDATE或DELETE;或不返回任何结果的SQL语句,如DDL语句。int executeUpdate() throws SQLException;// 其他省略
}
这里我们可以看到executeQuery与executeUpdate方法前者主要是处理Select语句后者处理INSERT、UPDATE或DELETE语句,这里他的子类太多了我们介绍与Mybatis相关的CallableStatement与JdbcPreparedStatement

- CallableStatement:用于执行SQL存储过程的接口。JDBC API提供了一种存储过程SQL转义语法,允许以标准方式对所有rdbms调用存储过程。此转义语法有一种形式包含结果形参,另一种形式不包含结果形参。如果使用,结果参数必须注册为OUT参数。其他参数可用于输入、输出或同时用于输入和输出。参数按数字顺序引用,第一个参数为1。 {?= call [( , ,…)]} {call [( , ,…)]}
- JdbcPreparedStatement:表示预编译SQL语句的对象。 SQL语句被预编译并存储在PreparedStatement对象中。
下面:我们来看看在JDBC中使用PreparedStatement
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;public class PreparedStatementTest {public static void main(String[] args) throws Throwable {Class.forName("com.mysql.jdbc.Driver");String url = "jdbc:mysql://localhost/test";// 获取连接try (Connection con = DriverManager.getConnection(url, "root", null)) {String sql = "insert into t select ?,?";// 预编译SqlPreparedStatement statement = con.prepareStatement(sql);// 设置参数statement.setInt(1, 123456);statement.setString(2, "abc");// 执行statement.executeUpdate();// 关闭statement.close();}}
}通常我们的一条sql在db接收到最终执行完毕返回可以分为下面三个过程:
- 词法和语义解析
- 优化sql语句,制定执行计划
- 执行并返回结果
我们把这种普通语句称作Immediate Statements。
二 prepareStatement的准备阶段
让我们回到之前的准备工作?
ReuseExecutor
@Overridepublic int doUpdate(MappedStatement ms, Object parameter) throws SQLException {// 获取好的解析文件 Configuration configuration = ms.getConfiguration();// 参数与处理器 StatementHandler handler = configuration.newStatementHandler(this, ms, parameter, RowBounds.DEFAULT, null, null);Statement stmt = prepareStatement(handler, ms.getStatementLog());return handler.update(stmt);}
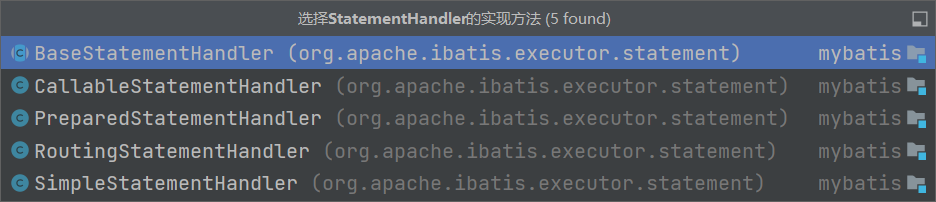
- SimpleStatementHandler,这个很简单了,就是对应我们JDBC中常用的Statement接口,用于简单SQL的处理;
- PreparedStatementHandler,这个对应JDBC中的PreparedStatement,预编译SQL的接口;
- CallableStatementHandler,这个对应JDBC中CallableStatement,用于执行存储过程相关的接口;
- RoutingStatementHandler,这个接口是以上三个接口的路由,没有实际操作,只是负责上面三个StatementHandler的创建及调用。
- 首先获取Connection
- SQL预编译
- 设置参数
- 执行Sql,返回结果
- 关闭
2.1 获取Connection
首先我们来看看获取Connection,是如何获取的?
ReuseExecutor
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {Statement stmt;BoundSql boundSql = handler.getBoundSql();String sql = boundSql.getSql();if (hasStatementFor(sql)) {stmt = getStatement(sql);applyTransactionTimeout(stmt);} else {Connection connection = getConnection(statementLog);stmt = handler.prepare(connection, transaction.getTimeout());putStatement(sql, stmt);}handler.parameterize(stmt);return stmt;}
BaseExecutor
/*** 获取一个Connection对象* @param statementLog 日志对象* @return Connection对象* @throws SQLException*/protected Connection getConnection(Log statementLog) throws SQLException {Connection connection = transaction.getConnection();if (statementLog.isDebugEnabled()) { // 启用调试日志// 生成Connection对象的具有日志记录功能的代理对象ConnectionLogger对象return ConnectionLogger.newInstance(connection, statementLog, queryStack);} else {// 返回原始的Connection对象return connection;}}transaction事务工厂,在DefaultSqlSessionFactory#openSession()创建,在我们的配置中JdbcTransactionFactory
DefaultSqlSessionFactory
/*** 从数据源中获取SqlSession对象* @param execType 执行器类型* @param level 事务隔离级别* @param autoCommit 是否自动提交事务* @return SqlSession对象*/private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {Transaction tx = null;try {// 找出要使用的指定环境final Environment environment = configuration.getEnvironment();// 从环境中获取事务工厂final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);// 从事务工厂中生产事务tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);// 创建执行器final Executor executor = configuration.newExecutor(tx, execType);// 创建DefaultSqlSession对象return new DefaultSqlSession(configuration, executor, autoCommit);} catch (Exception e) {closeTransaction(tx); // may have fetched a connection so lets call close()throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);} finally {ErrorContext.instance().reset();}}private TransactionFactory getTransactionFactoryFromEnvironment(Environment environment) {if (environment == null || environment.getTransactionFactory() == null) {return new ManagedTransactionFactory();}return environment.getTransactionFactory();}
让我们来看看Transaction类的接口信息,他的实现类:JdbcTransaction与ManagedTransaction
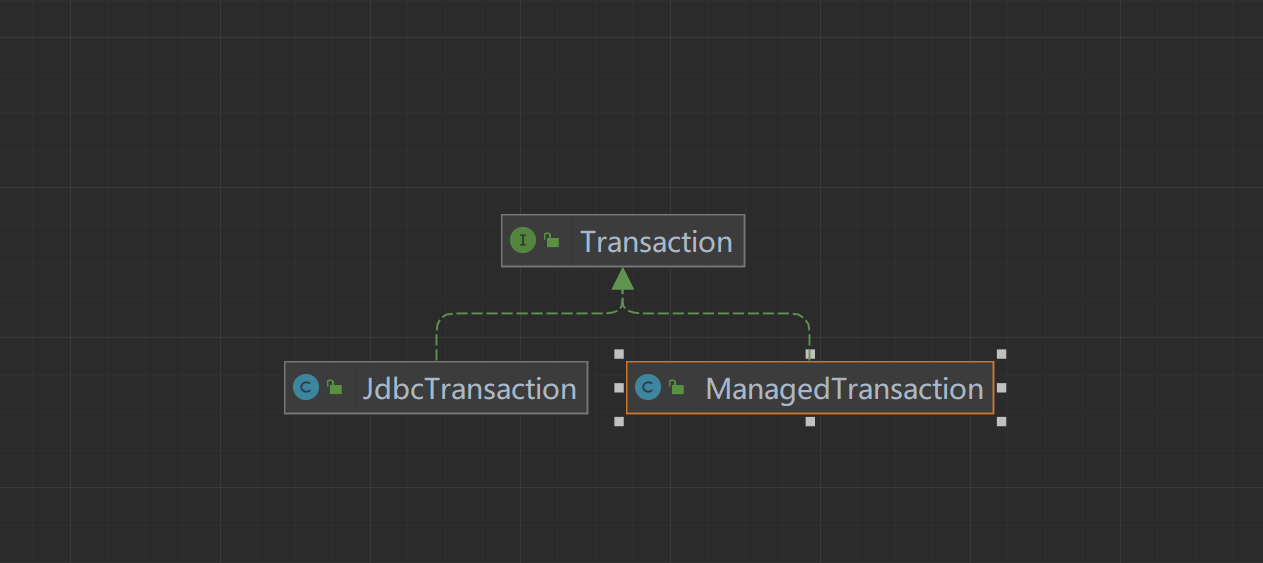
Transaction
public interface Transaction {/*** 获取该事务对应的数据库连接* @return 数据库连接* @throws SQLException*/Connection getConnection() throws SQLException;/*** 提交事务* @throws SQLException*/void commit() throws SQLException;/*** 回滚事务* @throws SQLException*/void rollback() throws SQLException;/*** 关闭对应的数据连接* @throws SQLException*/void close() throws SQLException;/*** 读取设置的事务超时时间* @return 事务超时时间* @throws SQLException*/Integer getTimeout() throws SQLException;}Transaction接口只是定义了基本的方法,关键在于他的实现,我们来看看JdbcTransaction
public class JdbcTransaction implements Transaction {private static final Log log = LogFactory.getLog(JdbcTransaction.class);// 数据库连接protected Connection connection;// 数据源protected DataSource dataSource;// 事务隔离级别protected TransactionIsolationLevel level;// 是否自动提交事务protected boolean autoCommit;public JdbcTransaction(DataSource ds, TransactionIsolationLevel desiredLevel, boolean desiredAutoCommit) {dataSource = ds;level = desiredLevel;autoCommit = desiredAutoCommit;}public JdbcTransaction(Connection connection) {this.connection = connection;}@Overridepublic Connection getConnection() throws SQLException {if (connection == null) {openConnection();}return connection;}/*** 提交事务* @throws SQLException*/@Overridepublic void commit() throws SQLException {// 连接存在且不会自动提交事务if (connection != null && !connection.getAutoCommit()) {if (log.isDebugEnabled()) {log.debug("Committing JDBC Connection [" + connection + "]");}// 调用connection对象的方法提交事务connection.commit();}}/*** 回滚事务* @throws SQLException*/@Overridepublic void rollback() throws SQLException {if (connection != null && !connection.getAutoCommit()) {if (log.isDebugEnabled()) {log.debug("Rolling back JDBC Connection [" + connection + "]");}connection.rollback();}}// 关闭@Overridepublic void close() throws SQLException {if (connection != null) {resetAutoCommit();if (log.isDebugEnabled()) {log.debug("Closing JDBC Connection [" + connection + "]");}connection.close();}}protected void openConnection() throws SQLException {if (log.isDebugEnabled()) {log.debug("Opening JDBC Connection");}//通过dataSource来获取connection,并设置到transaction的connection属性中connection = dataSource.getConnection();if (level != null) {//通过connection设置事务的隔离级别connection.setTransactionIsolation(level.getLevel());}//设置事务是否自动提交setDesiredAutoCommit(autoCommmit);}// 其他方法省略
}
我们看到JdbcTransaction中有一个**Connection属性和dataSource属性,使用connection来进行提交、回滚、关闭等操作,也就是说JdbcTransaction其实只是在jdbc的connection上面封装了一下,实际使用的其实还是jdbc的事务。**我们看看getConnection()方法。
@Overridepublic Connection getConnection() throws SQLException {if (connection == null) {openConnection();}return connection;}protected void openConnection() throws SQLException {if (log.isDebugEnabled()) {log.debug("Opening JDBC Connection");}// 从数据源中获取connection这与上面的案例是一致的connection = dataSource.getConnection();if (level != null) {connection.setTransactionIsolation(level.getLevel());}setDesiredAutoCommit(autoCommit);}
- 我们再来看看dataSource.getConnection()这个方法获取connection
这里先看看官方文档对dataSource的配置信息吧:虽然数据源配置是可选的,但如果要启用延迟加载特性,就必须配置数据源,有三种内建的数据源类型(也就是 type=“[UNPOOLED|POOLED|JNDI]”):

对数据源元素的解析,请参考前面的文章对environments元素进行解析,下面贴关键代码
XMLConfigBuilder
/*** 解析配置信息,获取数据源工厂* 被解析的配置信息示例如下:* <dataSource type="POOLED">* <property name="driver" value="{dataSource.driver}"/>* <property name="url" value="{dataSource.url}"/>* <property name="username" value="${dataSource.username}"/>* <property name="password" value="${dataSource.password}"/>* </dataSource>** @param context 被解析的节点* @return 数据源工厂* @throws Exception*/private DataSourceFactory dataSourceElement(XNode context) throws Exception {if (context != null) {// 通过这里的类型判断数据源类型,例如POOLED、UNPOOLED、JNDIString type = context.getStringAttribute("type");// 获取dataSource节点下配置的propertyProperties props = context.getChildrenAsProperties();// 根据dataSource的type值获取相应的DataSourceFactory对象DataSourceFactory factory = (DataSourceFactory) resolveClass(type).newInstance();// 设置DataSourceFactory对象的属性factory.setProperties(props);return factory;}throw new BuilderException("Environment declaration requires a DataSourceFactory.");}
扩展问题:DefaultSqlSession线程安全吗?:Mybatis(二)SqlSession之线程安全
下面我们仔细来介绍下数据源的创建?首先我们看看DataSource接口信息
DataSource
public interface DataSource extends CommonDataSource, Wrapper {Connection getConnection() throws SQLException;Connection getConnection(String username, String password)throws SQLException;
}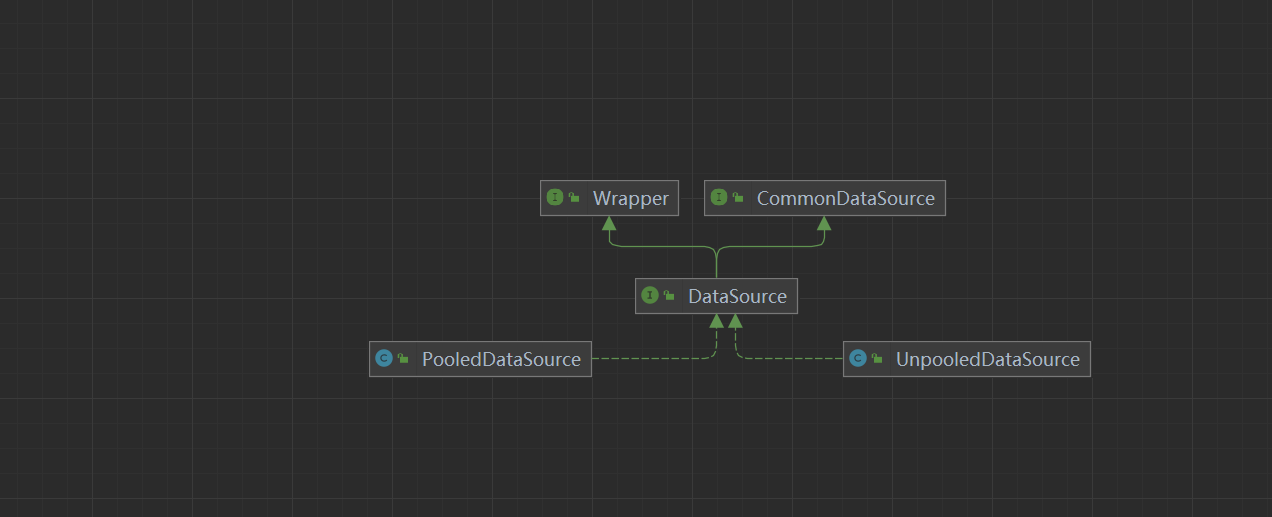
我们再来看看他的实现类PooledDataSource与UnpooledDataSource,池化与非池化,首先看看UnpooledDataSource的成员变量,他的步骤如下
- initializeDriver - 初始化数据库驱动
- doGetConnection - 获取数据连接
- configureConnection - 配置数据库连接
2.1.1 UnpooledDataSource
UnpooledDataSource
public class UnpooledDataSource implements DataSource {// 驱动加载器private ClassLoader driverClassLoader;// 驱动配置信息private Properties driverProperties;// 已经注册的所有驱动private static Map<String, Driver> registeredDrivers = new ConcurrentHashMap<>();// 数据库驱动private String driver;// 数据源地址private String url;// 数据源用户名private String username;// 数据源密码private String password;// 是否自动提交private Boolean autoCommit;// 默认事务隔离级别private Integer defaultTransactionIsolationLevel;// 最长等待时间。发出请求后,最长等待该时间后如果数据库还没有回应,则认为失败private Integer defaultNetworkTimeout;static {// 首先将java.sql.DriverManager中的驱动都加载进来Enumeration<Driver> drivers = DriverManager.getDrivers();while (drivers.hasMoreElements()) {Driver driver = drivers.nextElement();registeredDrivers.put(driver.getClass().getName(), driver);}}
}
UnpooledDataSource
// 传入用户密码
@Overridepublic Connection getConnection() throws SQLException {return doGetConnection(username, password);}private Connection doGetConnection(String username, String password) throws SQLException {Properties props = new Properties();if (driverProperties != null) {props.putAll(driverProperties);}if (username != null) {props.setProperty("user", username);}if (password != null) {props.setProperty("password", password);}return doGetConnection(props);}/*** 建立数据库连接* @param properties 里面包含建立连接的"user"、"password"、驱动配置信息* @return 数据库连接对象* @throws SQLException*/private Connection doGetConnection(Properties properties) throws SQLException {// 初始化驱动initializeDriver();// 通过DriverManager获取连接Connection connection = DriverManager.getConnection(url, properties);// 配置连接,要设置的属性有defaultNetworkTimeout、autoCommit、defaultTransactionIsolationLevelconfigureConnection(connection);return connection;}
- 我们来看看他初始化数据库驱动方法initializeDriver()来初始化数据库驱动
UnpooledDataSource
/*** 初始化数据库驱动* @throws SQLException*/private synchronized void initializeDriver() throws SQLException {if (!registeredDrivers.containsKey(driver)) { // 如果所需的驱动尚未被注册到registeredDriversClass<?> driverType;try {if (driverClassLoader != null) { // 如果存在驱动类加载器// 优先使用驱动类加载器加载驱动类driverType = Class.forName(driver, true, driverClassLoader);} else {// 使用Resources中的所有加载器加载驱动类driverType = Resources.classForName(driver);}// 实例化驱动Driver driverInstance = (Driver)driverType.newInstance();// 向DriverManager注册该驱动的代理DriverManager.registerDriver(new DriverProxy(driverInstance));// 注册到registeredDrivers,表明该驱动已经加载registeredDrivers.put(driver, driverInstance);} catch (Exception e) {throw new SQLException("Error setting driver on UnpooledDataSource. Cause: " + e);}}}
通过反射机制加载驱动Driver,并将其注册到DriverManager中的一个常量集合中,供后面获取连接时使用,为什么这里是一个List呢?我们实际开发中有可能使用到了多种数据库类型,如Mysql、Oracle等,其驱动都是不同的,不同的数据源获取连接时使用的是不同的驱动。
- 我们仔细从驱动管理器中来看看他说如何获取理数据库连接的
Connection connection = DriverManager.getConnection(url, properties)
DriverManager
// Worker method called by the public getConnection() methods.private static Connection getConnection(String url, java.util.Properties info, Class<?> caller) throws SQLException {// 当callerCl为空时,我们应该检查应用程序的(间接调用该类的)类加载器,以便可以从这里加载rt.jar外部的JDBC驱动程序类。ClassLoader callerCL = caller != null ? caller.getClassLoader() : null;synchronized(DriverManager.class) {// synchronize loading of the correct classloader.if (callerCL == null) {callerCL = Thread.currentThread().getContextClassLoader();}}if(url == null) {throw new SQLException("The url cannot be null", "08001");}println("DriverManager.getConnection(\"" + url + "\")");// 遍历已加载的registeredDrivers,试图建立连接。// 记住第一个被引发的异常,这样我们就可以重新引发它。SQLException reason = null;// 遍历已经注册是使用驱动for(DriverInfo aDriver : registeredDrivers) {// 如果调用者没有加载驱动程序的权限,那么跳过它。if(isDriverAllowed(aDriver.driver, callerCL)) {try {println(" trying " + aDriver.driver.getClass().getName());Connection con = aDriver.driver.connect(url, info);if (con != null) {// Success!println("getConnection returning " + aDriver.driver.getClass().getName());return (con);}} catch (SQLException ex) {if (reason == null) {reason = ex;}}} else {println(" skipping: " + aDriver.getClass().getName());}}// if we got here nobody could connect.if (reason != null) {println("getConnection failed: " + reason);throw reason;}println("getConnection: no suitable driver found for "+ url);throw new SQLException("No suitable driver found for "+ url, "08001");}
- 从配置文件中来配置连接比如:超时,自动提交,事务隔离级别
configureConnection(connection)
UnpooledDataSource
private void configureConnection(Connection conn) throws SQLException {if (defaultNetworkTimeout != null) {conn.setNetworkTimeout(Executors.newSingleThreadExecutor(), defaultNetworkTimeout);}if (autoCommit != null && autoCommit != conn.getAutoCommit()) {conn.setAutoCommit(autoCommit);}if (defaultTransactionIsolationLevel != null) {conn.setTransactionIsolation(defaultTransactionIsolationLevel);}}
到最后返回数据库连接对象Connection,从源码可以看到最后返回来JDBCConnection
2.1.2 PooledDataSource
PooledDataSource 内部实现了连接池功能,用于复用数据库连接。因此,从效率上来说,PooledDataSource 要高于 UnpooledDataSource,但是最终获取Connection还是通过UnpooledDataSource,只不过PooledDataSource 提供一个存储Connection的功能。
public class PooledDataSource implements DataSource {private static final Log log = LogFactory.getLog(PooledDataSource.class);// 池化状态private final PoolState state = new PoolState(this);// 持有一个UnpooledDataSource对象private final UnpooledDataSource dataSource;// 和连接池设置有关的配置项protected int poolMaximumActiveConnections = 10;protected int poolMaximumIdleConnections = 5;protected int poolMaximumCheckoutTime = 20000;protected int poolTimeToWait = 20000;protected int poolMaximumLocalBadConnectionTolerance = 3;protected String poolPingQuery = "NO PING QUERY SET";protected boolean poolPingEnabled;protected int poolPingConnectionsNotUsedFor;// 存储池子中的连接的编码,编码用("" + url + username + password).hashCode()算出来// 因此,整个池子中的所有连接的编码必须是一致的,里面的连接是等价的private int expectedConnectionTypeCode;}
PoolState 用于记录连接池运行时的状态,比如连接获取次数,无效连接数量等。同时 PoolState 内部定义了两个 PooledConnection 集合,用于存储空闲连接和活跃连接。
PoolState
public class PoolState {// 池化数据源protected PooledDataSource dataSource;// 空闲的连接protected final List<PooledConnection> idleConnections = new ArrayList<>();// 活动的连接protected final List<PooledConnection> activeConnections = new ArrayList<>();// 连接被取出的次数protected long requestCount = 0;// 取出请求花费时间的累计值。从准备取出请求到取出结束的时间为取出请求花费的时间protected long accumulatedRequestTime = 0;// 累积被检出的时间protected long accumulatedCheckoutTime = 0;// 声明的过期连接数protected long claimedOverdueConnectionCount = 0;// 过期的连接数的总检出时长protected long accumulatedCheckoutTimeOfOverdueConnections = 0;// 总等待时间protected long accumulatedWaitTime = 0;// 等待的轮次protected long hadToWaitCount = 0;// 坏连接的数目protected long badConnectionCount = 0;public PoolState(PooledDataSource dataSource) {this.dataSource = dataSource;}
}
PooledConnection 内部定义了一个 Connection 类型的变量,用于指向真实的数据库连接。以及一个 Connection 的代理类,用于对部分方法调用进行拦截,至于为什么要拦截,随后将进行分析。除此之外,PooledConnection 内部也定义了一些字段,用于记录数据库连接的一些运行时状态。
PooledConnection
class PooledConnection implements InvocationHandler {private static final String CLOSE = "close";private static final Class<?>[] IFACES = new Class<?>[] { Connection.class };// 该连接的哈希值private final int hashCode;// 该连接所属的连接池private final PooledDataSource dataSource;// 真正的Connectionprivate final Connection realConnection;// 代理Connectionprivate final Connection proxyConnection;// 从连接池中取出的时间private long checkoutTimestamp;// 创建时间private long createdTimestamp;// 上次使用时间private long lastUsedTimestamp;// 标志所在连接池的连接类型编码private int connectionTypeCode;// 连接是否可用private boolean valid;public PooledConnection(Connection connection, PooledDataSource dataSource) {this.hashCode = connection.hashCode();this.realConnection = connection;this.dataSource = dataSource;this.createdTimestamp = System.currentTimeMillis();this.lastUsedTimestamp = System.currentTimeMillis();this.valid = true;// 参数依次是:被代理对象的类加载器 被代理对象的接口 包含代理对象的类(实现InvocationHandler接口的类)this.proxyConnection = (Connection) Proxy.newProxyInstance(Connection.class.getClassLoader(), IFACES, this);}}
获取连接调用了PooledDataSource#popConnection方法
/*** 从池化数据源中给出一个连接* @param username 用户名* @param password 密码* @return 池化的数据库连接* @throws SQLException*/private PooledConnection popConnection(String username, String password) throws SQLException {boolean countedWait = false;PooledConnection conn = null;// 用于统计取出连接花费的时长的时间起点long t = System.currentTimeMillis();int localBadConnectionCount = 0;while (conn == null) {// 给state加同步锁synchronized (state) {if (!state.idleConnections.isEmpty()) { // 池中存在空闲连接// 左移操作,取出第一个连接conn = state.idleConnections.remove(0);if (log.isDebugEnabled()) {log.debug("Checked out connection " + conn.getRealHashCode() + " from pool.");}} else { // 池中没有空余连接if (state.activeConnections.size() < poolMaximumActiveConnections) { // 池中还有空余位置// 可以创建新连接,也是通过DriverManager.getConnection拿到的连接conn = new PooledConnection(dataSource.getConnection(), this);if (log.isDebugEnabled()) {log.debug("Created connection " + conn.getRealHashCode() + ".");}} else { // 连接池已满,不能创建新连接// 找到借出去最久的连接PooledConnection oldestActiveConnection = state.activeConnections.get(0);// 查看借出去最久的连接已经被借了多久long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();if (longestCheckoutTime > poolMaximumCheckoutTime) { // 借出时间超过设定的借出时长// 声明该连接超期不还state.claimedOverdueConnectionCount++;state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;state.accumulatedCheckoutTime += longestCheckoutTime;// 因超期不还而从池中除名state.activeConnections.remove(oldestActiveConnection);if (!oldestActiveConnection.getRealConnection().getAutoCommit()) { // 如果超期不还的连接没有设置自动提交事务// 尝试替它提交回滚事务try {oldestActiveConnection.getRealConnection().rollback();} catch (SQLException e) {// 即使替它回滚事务的操作失败,也不抛出异常,仅仅做一下记录log.debug("Bad connection. Could not roll back");}}// 新建一个连接替代超期不还连接的位置conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this);conn.setCreatedTimestamp(oldestActiveConnection.getCreatedTimestamp());conn.setLastUsedTimestamp(oldestActiveConnection.getLastUsedTimestamp());oldestActiveConnection.invalidate();if (log.isDebugEnabled()) {log.debug("Claimed overdue connection " + conn.getRealHashCode() + ".");}} else { // 借出去最久的连接,并未超期// 继续等待,等待有连接归还到连接池try {if (!countedWait) {// 记录发生等待的次数。某次请求等待多轮也只能算作发生了一次等待state.hadToWaitCount++;countedWait = true;}if (log.isDebugEnabled()) {log.debug("Waiting as long as " + poolTimeToWait + " milliseconds for connection.");}long wt = System.currentTimeMillis();// 沉睡一段时间再试,防止一直占有计算资源state.wait(poolTimeToWait);state.accumulatedWaitTime += System.currentTimeMillis() - wt;} catch (InterruptedException e) {break;}}}}if (conn != null) { // 取到了连接// 判断连接是否可用if (conn.isValid()) { // 如果连接可用if (!conn.getRealConnection().getAutoCommit()) { // 该连接没有设置自动提交// 回滚未提交的操作conn.getRealConnection().rollback();}// 每个借出去的连接都到打上数据源的连接类型编码,以便在归还时确保正确conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));// 数据记录操作conn.setCheckoutTimestamp(System.currentTimeMillis());conn.setLastUsedTimestamp(System.currentTimeMillis());state.activeConnections.add(conn);state.requestCount++;state.accumulatedRequestTime += System.currentTimeMillis() - t;} else { // 连接不可用if (log.isDebugEnabled()) {log.debug("A bad connection (" + conn.getRealHashCode() + ") was returned from the pool, getting another connection.");}state.badConnectionCount++;localBadConnectionCount++;// 直接删除连接conn = null;// 如果没有一个连接能用,说明连不上数据库if (localBadConnectionCount > (poolMaximumIdleConnections + poolMaximumLocalBadConnectionTolerance)) {if (log.isDebugEnabled()) {log.debug("PooledDataSource: Could not get a good connection to the database.");}throw new SQLException("PooledDataSource: Could not get a good connection to the database.");}}}}// 如果到这里还没拿到连接,则会循环此过程,继续尝试取连接}if (conn == null) {if (log.isDebugEnabled()) {log.debug("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");}throw new SQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");}return conn;}
从连接池中获取连接首先会遇到两种情况:
- 连接池中有空闲连接
- 连接池中无空闲连接
对于第一种情况,把连接取出返回即可。对于第二种情况,则要进行细分,会有如下的情况。
- 活跃连接数没有超出最大活跃连接数
- 活跃连接数超出最大活跃连接数
对于上面两种情况,第一种情况比较好处理,直接创建新的连接即可。至于第二种情况,需要再次进行细分。
- 活跃连接的运行时间超出限制,即超时了
- 活跃连接未超时
对于第一种情况,我们直接将超时连接强行中断,并进行回滚,然后复用部分字段重新创建 PooledConnection 即可。对于第二种情况,目前没有更好的处理方式了,只能等待了。
- 回收连接相比于获取连接,回收连接的逻辑要简单的多。回收连接成功与否只取决于空闲连接集合的状态,所需处理情况很少,因此比较简单。
PooledConnection
/*** 代理方法* @param proxy 代理对象,未用* @param method 当前执行的方法* @param args 当前执行的方法的参数* @return 方法的返回值* @throws Throwable*/@Overridepublic Object invoke(Object proxy, Method method, Object[] args) throws Throwable {// 获取方法名String methodName = method.getName();if (CLOSE.hashCode() == methodName.hashCode() && CLOSE.equals(methodName)) { // 如果调用了关闭方法// 那么把Connection返回给连接池,而不是真正的关闭dataSource.pushConnection(this);return null;}try {// 校验连接是否可用if (!Object.class.equals(method.getDeclaringClass())) {checkConnection();}// 用真正的连接去执行操作return method.invoke(realConnection, args);} catch (Throwable t) {throw ExceptionUtil.unwrapThrowable(t);}}
我们来看看pushConnection方法,回收一个连接
/*** 收回一个连接* @param conn 连接* @throws SQLException*/protected void pushConnection(PooledConnection conn) throws SQLException {synchronized (state) {// 将该连接从活跃连接中删除state.activeConnections.remove(conn);if (conn.isValid()) { // 当前连接是可用的// 判断连接池未满 + 该连接确实属于该连接池if (state.idleConnections.size() < poolMaximumIdleConnections && conn.getConnectionTypeCode() == expectedConnectionTypeCode) {state.accumulatedCheckoutTime += conn.getCheckoutTime();if (!conn.getRealConnection().getAutoCommit()) { // 如果连接没有设置自动提交// 将未完成的操作回滚conn.getRealConnection().rollback();}// 重新整理连接PooledConnection newConn = new PooledConnection(conn.getRealConnection(), this);// 将连接放入空闲连接池state.idleConnections.add(newConn);newConn.setCreatedTimestamp(conn.getCreatedTimestamp());newConn.setLastUsedTimestamp(conn.getLastUsedTimestamp());// 设置连接为未校验,以便取出时重新校验conn.invalidate();if (log.isDebugEnabled()) {log.debug("Returned connection " + newConn.getRealHashCode() + " to pool.");}state.notifyAll();} else { // 连接池已满或者该连接不属于该连接池state.accumulatedCheckoutTime += conn.getCheckoutTime();if (!conn.getRealConnection().getAutoCommit()) {conn.getRealConnection().rollback();}// 直接关闭连接,而不是将其放入连接池中conn.getRealConnection().close();if (log.isDebugEnabled()) {log.debug("Closed connection " + conn.getRealHashCode() + ".");}conn.invalidate();}} else { // 当前连接不可用if (log.isDebugEnabled()) {log.debug("A bad connection (" + conn.getRealHashCode() + ") attempted to return to the pool, discarding connection.");}state.badConnectionCount++;}}}
先将连接从活跃连接集合中移除,如果空闲集合未满,此时复用原连接的字段信息创建新的连接,并将其放入空闲集合中即可;若空闲集合已满,此时无需回收连接,直接关闭即可。
好了,我们已经获取到了数据库连接,接下来要创建PrepareStatement了,我们上面JDBC的例子是怎么获取的? psmt = conn.prepareStatement(sql);,直接通过Connection来获取,并且把sql传进去了,我们看看Mybaits中是怎么创建PrepareStatement的
2.2 Sql的预编译PreparedStatementHandler
让我们回到之前的步骤,我们已经获取数据库连接,接下来来看看Sql的预编译,从Connection中创建一个Statement
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {Statement stmt;BoundSql boundSql = handler.getBoundSql();String sql = boundSql.getSql();if (hasStatementFor(sql)) {stmt = getStatement(sql);applyTransactionTimeout(stmt);} else {Connection connection = getConnection(statementLog);stmt = handler.prepare(connection, transaction.getTimeout());putStatement(sql, stmt);}handler.parameterize(stmt);return stmt;}
BaseStatementHandler
// 从连接中获取一个Statement,并设置事务超时时间
@Overridepublic Statement prepare(Connection connection, Integer transactionTimeout) throws SQLException {ErrorContext.instance().sql(boundSql.getSql());Statement statement = null;try {// 获取一个Statement对象statement = instantiateStatement(connection);// 设置设置查询超时时间setStatementTimeout(statement, transactionTimeout);// 获取数据大小限制setFetchSize(statement);return statement;} catch (SQLException e) {closeStatement(statement);throw e;} catch (Exception e) {closeStatement(statement);throw new ExecutorException("Error preparing statement. Cause: " + e, e);}
}
我们接着来看看instantiateStatemen接口,根据上面的的信息,我们这的默认实现是PreparedStatementHandler
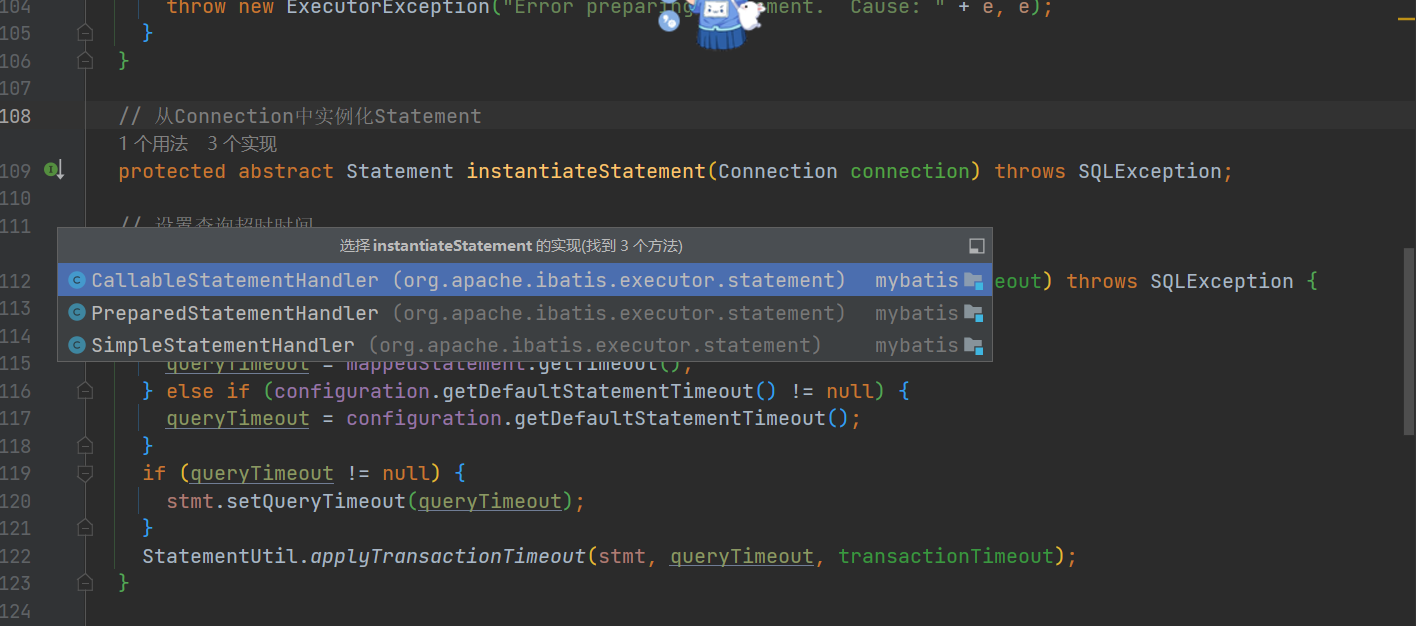
PreparedStatementHandler
@Overrideprotected Statement instantiateStatement(Connection connection) throws SQLException {// //获取sql字符串,比如"select * from user where id= ?"String sql = boundSql.getSql();// / 根据条件调用不同的 prepareStatement 方法创建 PreparedStatement if (mappedStatement.getKeyGenerator() instanceof Jdbc3KeyGenerator) {String[] keyColumnNames = mappedStatement.getKeyColumns();if (keyColumnNames == null) {//通过connection获取Statement,将sql语句传进去return connection.prepareStatement(sql, PreparedStatement.RETURN_GENERATED_KEYS);} else {return connection.prepareStatement(sql, keyColumnNames);}} else if (mappedStatement.getResultSetType() == ResultSetType.DEFAULT) {return connection.prepareStatement(sql);} else {return connection.prepareStatement(sql, mappedStatement.getResultSetType().getValue(), ResultSet.CONCUR_READ_ONLY);}}
我们接着上面connection.prepareStatement来看看他到底是如何创建的
JDBCConnection
// 创建一个默认的PreparedStatement对象,该对象具有检索自动生成的键的功能。
public synchronized PreparedStatement prepareStatement(String sql,int autoGeneratedKeys) throws SQLException {// 检测内部是否关闭checkClosed();try {if (autoGeneratedKeys != ResultConstants.RETURN_GENERATED_KEYS&& autoGeneratedKeys!= ResultConstants.RETURN_NO_GENERATED_KEYS) {throw JDBCUtil.invalidArgument("autoGeneratedKeys");}// 构造生成所请求类型结果的语句。 预处理语句必须是一条SQL语句。return new JDBCPreparedStatement(this, sql,JDBCResultSet.TYPE_FORWARD_ONLY,JDBCResultSet.CONCUR_READ_ONLY, rsHoldability,autoGeneratedKeys, null, null);} catch (HsqlException e) {throw JDBCUtil.sqlException(e);}}
到这我们就返回一个Statement对象,下面我们来看看设置参数
2.3 为Statement设置参数
SimpleExecutor
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {Statement stmt;Connection connection = getConnection(statementLog);stmt = handler.prepare(connection, transaction.getTimeout());handler.parameterize(stmt);return stmt;}
我们这里StatementHandler在前面我们已经看到了是PreparedStatementHandler,我们来看看他是如何处理的
PreparedStatementHandler
@Overridepublic void parameterize(Statement statement) throws SQLException {parameterHandler.setParameters((PreparedStatement) statement);}
/*** 为语句设置参数* @param ps 语句*/@Overridepublic void setParameters(PreparedStatement ps) {ErrorContext.instance().activity("setting parameters").object(mappedStatement.getParameterMap().getId());// 取出参数列表List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();if (parameterMappings != null) {for (int i = 0; i < parameterMappings.size(); i++) {ParameterMapping parameterMapping = parameterMappings.get(i);// ParameterMode.OUT是CallableStatement的输出参数,已经单独注册。故忽略if (parameterMapping.getMode() != ParameterMode.OUT) {Object value;// 取出属性名称String propertyName = parameterMapping.getProperty();if (boundSql.hasAdditionalParameter(propertyName)) {// 从附加参数中读取属性值value = boundSql.getAdditionalParameter(propertyName);} else if (parameterObject == null) {value = null;} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {// 参数对象是基本类型,则参数对象即为参数值value = parameterObject;} else {// 参数对象是复杂类型,取出参数对象的该属性值MetaObject metaObject = configuration.newMetaObject(parameterObject);value = metaObject.getValue(propertyName);}// 确定该参数的处理器TypeHandler typeHandler = parameterMapping.getTypeHandler();JdbcType jdbcType = parameterMapping.getJdbcType();if (value == null && jdbcType == null) {jdbcType = configuration.getJdbcTypeForNull();}try {// 此方法最终根据参数类型,调用java.sql.PreparedStatement类中的参数赋值方法,对SQL语句中的参数赋值typeHandler.setParameter(ps, i + 1, value, jdbcType);} catch (TypeException | SQLException e) {throw new TypeException("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + e, e);}}}}}
可以看到调用不同的参数处理器来设置参数类型,我们先看看TypeHandler这个接口信息
TypeHandler
public interface TypeHandler<T> {/*** 设置参数* @param ps* @param i* @param parameter* @param jdbcType* @throws SQLException*/void setParameter(PreparedStatement ps, int i, T parameter, JdbcType jdbcType) throws SQLException;/*** 获取结果* @param rs* @param columnName* @return* @throws SQLException*/T getResult(ResultSet rs, String columnName) throws SQLException;T getResult(ResultSet rs, int columnIndex) throws SQLException;T getResult(CallableStatement cs, int columnIndex) throws SQLException;
}调用不同的参数处理器,来设置不同的参数这里的类型调用来设置参数
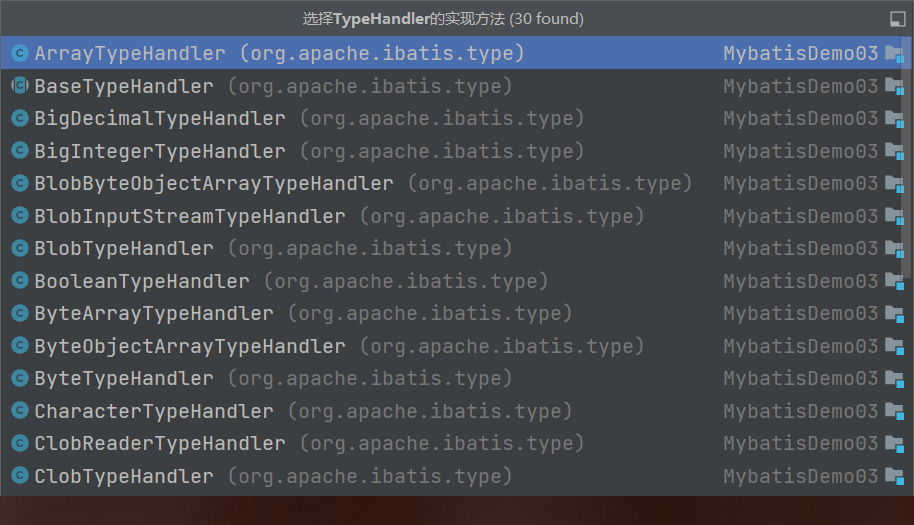
BaseTypeHandler来处理的设置参数类型,而许多类型的处理器继承BaseTypeHandler
最后根据参数类型,调用java.sql.PreparedStatement类中的参数赋值方法,对SQL语句中的参数赋值
DefaultParameterHandler
typeHandler.setParameter(ps, i + 1, value, jdbcType);
参数也设置好了,下面我们来看看执行具体的查询语句吧
2.4 执行具体的语句过程
回到刚开始的地方
SimpleExecutor
@Overridepublic int doUpdate(MappedStatement ms, Object parameter) throws SQLException {Statement stmt = null;try {Configuration configuration = ms.getConfiguration();// 获取不同的StatementHandler处理器StatementHandler handler = configuration.newStatementHandler(this, ms, parameter, RowBounds.DEFAULT, null, null);// 获取到不同的 Statement并完成参数绑定stmt = prepareStatement(handler, ms.getStatementLog());// 交给具体的StatementHandler实现执行return handler.update(stmt);} finally {closeStatement(stmt);}}
我们以默认为例:PreparedStatementHandler
PreparedStatementHandler
@Overridepublic int update(Statement statement) throws SQLException {//ClientPreparedStatement对象PreparedStatement ps = (PreparedStatement) statement;ps.execute();// 返回影响条数int rows = ps.getUpdateCount();// 参数对象Object parameterObject = boundSql.getParameterObject();// 主键自增器KeyGenerator keyGenerator = mappedStatement.getKeyGenerator();// 后置执行主键自增keyGenerator.processAfter(executor, mappedStatement, ps, parameterObject);return rows;}
从前面的数据库连接开始,我们就可以知道PreparedStatement返回的对象是ClientPreparedStatement,因此我们来看看他的execute方法
ClientPreparedStatement
@Overridepublic boolean execute() throws SQLException {// 其他代码省略rs = executeInternal(this.maxRows, sendPacket, createStreamingResultSet(),(((PreparedQuery<?>) this.query).getParseInfo().getFirstStmtChar() == 'S'), cachedMetadata, false);// 其他代码省略}关键在于调用executeInternal方法,感兴趣的朋友可以自己通过Debug去查看
到最后我们可以拿到ResultSetImpl中拿到执行的结果
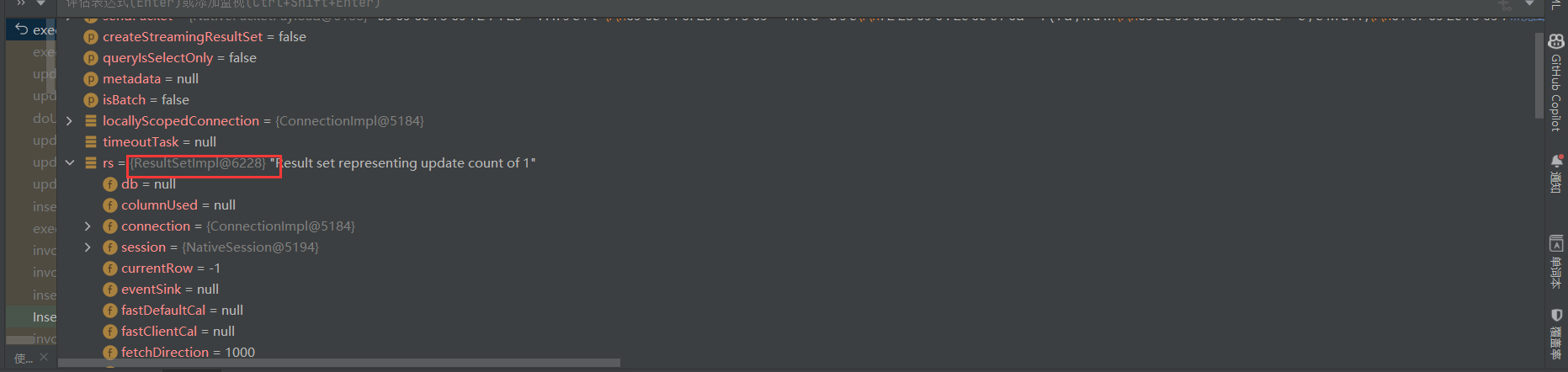
PreparedStatementHandler
int rows = ps.getUpdateCount();
ClientPreparedStatement
@Overridepublic int getUpdateCount() throws SQLException {// 调用父类的方法int count = super.getUpdateCount();if (containsOnDuplicateKeyUpdateInSQL() && this.compensateForOnDuplicateKeyUpdate) {if (count == 2 || count == 0) {count = 1;}}return count;}
详细的过程,请参考mysql驱动包的源码部分