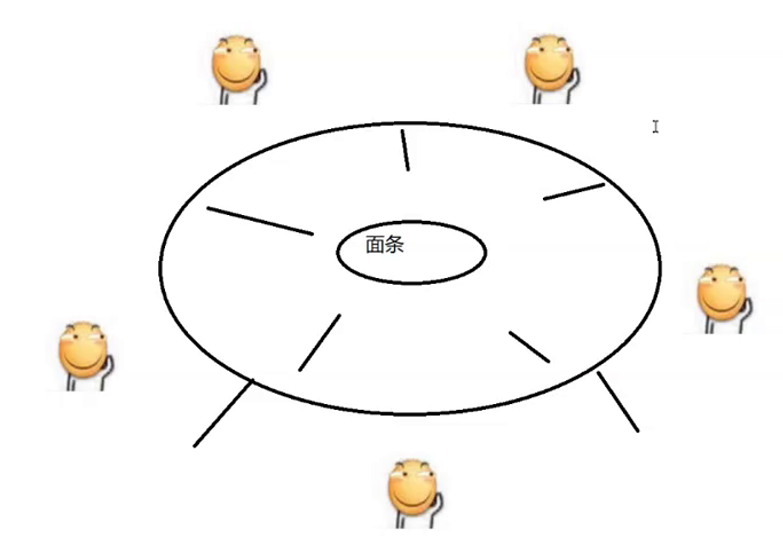
一致性 hash 算法由麻省理工学院的 Karger 及其合作者于1997年提供出的,算法提出之初是用于大规模缓存系统的负载均衡。它的工作过程是这样的,首先根据 ip 获取其他的信息为缓存节点生成一个 hash,并将这个 hash 投射到 [0, 232 – 1] 的圆环上。当有查询或写入请求时,则为缓存项的 key 生成一个 hash 值。然后查找第一个大于或等于该 hash 值的缓存节点,并到这个节点中查询或写入缓存项。如果当前节点挂了,则在下一次查询或写入缓存时,为缓存项查找另一个大于其 hash 值的缓存节点即可。大致效果如下,每个缓存节点在圆环上占据一个位置。如果缓存项的 key 的 hash 值小于缓存节点 hash 值,则到该缓存节点中存储或读取缓存项。比如下面绿色点对应的缓存项存储到 cache-2 节点中。由于 cache-3 挂了,原本应该存到该节点中的缓存想最终会存储到 cache-4 节点中。
关于一致性 hash 算法,我这里只做扫盲。具体的细节不讨论,大家请自行补充相关的背景知识。下面来看看一致性 hash 在 Dubbo 中的应用。我们把上图的缓存节点替换成 Dubbo 的服务提供者,于是得到了下图:
这里相同颜色的节点均属于同一个服务提供者,比如 Invoker1-1,Invoker1-2,……, Invoker1-160。这样做的目的是通过引入虚拟节点,让 Invoker 在圆环上分散开来,避免数据倾斜问题。所谓数据倾斜是指,由于节点不够分散,导致大量请求落到了同一个节点上,而其他节点只会接收到了少量的请求。比如:
如上,由于 Invoker-1 和 Invoker-2 在圆环上分布不均,导致系统中75%的请求都会落到 Invoker-1 上,只有 25% 的请求会落到 Invoker-2 上。解决这个问题办法是引入虚拟节点,通过虚拟节点均衡各个节点的请求量。
到这里背景知识就普及完了,接下来开始分析源码。我们先从 ConsistentHashLoadBalance 的 doSelect 方法开始看起,如下:
public class ConsistentHashLoadBalance extends AbstractLoadBalance {private final ConcurrentMap<String, ConsistentHashSelector<?>> selectors = new ConcurrentHashMap<String, ConsistentHashSelector<?>>();@Overrideprotected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {String methodName = RpcUtils.getMethodName(invocation);String key = invokers.get(0).getUrl().getServiceKey() + "." + methodName;// 获取 invokers 原始的 hashcodeint identityHashCode = System.identityHashCode(invokers);ConsistentHashSelector<T> selector = (ConsistentHashSelector<T>) selectors.get(key);// 如果 invokers 是一个新的 List 对象,意味着服务提供者数量发生了变化,可能新增也可能减少了。// 此时 selector.identityHashCode != identityHashCode 条件成立if (selector == null || selector.identityHashCode != identityHashCode) {// 创建新的 ConsistentHashSelectorselectors.put(key, new ConsistentHashSelector<T>(invokers, methodName, identityHashCode));selector = (ConsistentHashSelector<T>) selectors.get(key);}// 调用 ConsistentHashSelector 的 select 方法选择 Invokerreturn selector.select(invocation);}private static final class ConsistentHashSelector<T> {...}
}如上,doSelect 方法主要做了一些前置工作,比如检测 invokers 列表是不是变动过,以及创建 ConsistentHashSelector。这些工作做完后,接下来开始调用 select 方法执行负载均衡逻辑。在分析 select 方法之前,我们先来看一下一致性 hash 选择器 ConsistentHashSelector 的初始化过程,如下:
private static final class ConsistentHashSelector<T> {// 使用 TreeMap 存储 Invoker 虚拟节点private final TreeMap<Long, Invoker<T>> virtualInvokers;private final int replicaNumber;private final int identityHashCode;private final int[] argumentIndex;ConsistentHashSelector(List<Invoker<T>> invokers, String methodName, int identityHashCode) {this.virtualInvokers = new TreeMap<Long, Invoker<T>>();this.identityHashCode = identityHashCode;URL url = invokers.get(0).getUrl();// 获取虚拟节点数,默认为160this.replicaNumber = url.getMethodParameter(methodName, "hash.nodes", 160);// 获取参与 hash 计算的参数下标值,默认对第一个参数进行 hash 运算String[] index = Constants.COMMA_SPLIT_PATTERN.split(url.getMethodParameter(methodName, "hash.arguments", "0"));argumentIndex = new int[index.length];for (int i = 0; i < index.length; i++) {argumentIndex[i] = Integer.parseInt(index[i]);}for (Invoker<T> invoker : invokers) {String address = invoker.getUrl().getAddress();for (int i = 0; i < replicaNumber / 4; i++) {// 对 address + i 进行 md5 运算,得到一个长度为16的字节数组byte[] digest = md5(address + i);// 对 digest 部分字节进行4次 hash 运算,得到四个不同的 long 型正整数for (int h = 0; h < 4; h++) {// h = 0 时,取 digest 中下标为 0 ~ 3 的4个字节进行位运算// h = 1 时,取 digest 中下标为 4 ~ 7 的4个字节进行位运算// h = 2, h = 3 时过程同上long m = hash(digest, h);// 将 hash 到 invoker 的映射关系存储到 virtualInvokers 中,// virtualInvokers 中的元素要有序,因此选用 TreeMap 作为存储结构virtualInvokers.put(m, invoker);}}}}
}ConsistentHashSelector 的构造方法执行了一系列的初始化逻辑,比如从配置中获取虚拟节点数以及参与 hash 计算的参数下标,默认情况下只使用第一个参数进行 hash。需要特别说明的是,ConsistentHashLoadBalance 的负载均衡逻辑只受参数值影响,具有相同参数值的请求将会被分配给同一个服务提供者。ConsistentHashLoadBalance 不 care 权重,因此使用时需要注意一下。
在获取虚拟节点数和参数下标配置后,接下来要做的事情是计算虚拟节点 hash 值,并将虚拟节点存储到 TreeMap 中。到此,ConsistentHashSelector 初始化工作就完成了。接下来,我们再来看看 select 方法的逻辑。
public Invoker<T> select(Invocation invocation) {// 将参数转为 keyString key = toKey(invocation.getArguments());// 对参数 key 进行 md5 运算byte[] digest = md5(key);// 取 digest 数组的前四个字节进行 hash 运算,再将 hash 值传给 selectForKey 方法,// 寻找合适的 Invokerreturn selectForKey(hash(digest, 0));
}private Invoker<T> selectForKey(long hash) {// 到 TreeMap 中查找第一个节点值大于或等于当前 hash 的 InvokerMap.Entry<Long, Invoker<T>> entry = virtualInvokers.tailMap(hash, true).firstEntry();// 如果 hash 大于 Invoker 在圆环上最大的位置,此时 entry = null,// 需要将 TreeMap 的头结点赋值给 entryif (entry == null) {entry = virtualInvokers.firstEntry();}// 返回 Invokerreturn entry.getValue();
}如上,选择的过程比较简单了。首先是对参数进行 md5 以及 hash 运算,得到一个 hash 值。然后再拿这个值到 TreeMap 中查找目标 Invoker 即可。
到此关于 ConsistentHashLoadBalance 就分析完了。在阅读 ConsistentHashLoadBalance 之前,大家一定要先补充背景知识。否者即使这里只有一百多行代码,也很难看懂。好了,本节先分析到这。
2.4 RoundRobinLoadBalance
本节,我们来看一下 Dubbo 中的加权轮询负载均衡的实现 RoundRobinLoadBalance。在详细分析源码前,我们还是先来了解一下什么是加权轮询。这里从最简单的轮询开始讲起,所谓轮询就是将请求轮流分配给一组服务器。举个例子,我们有三台服务器 A、B、C。我们将第一个请求分配给服务器 A,第二个请求分配给服务器 B,第三个请求分配给服务器 C,第四个请求再次分配给服务器 A。这个过程就叫做轮询。轮询是一种无状态负载均衡算法,实现简单,适用于每台服务器性能相近的场景下。显然,现实情况下,我们并不能保证每台服务器性能均相近。如果我们将等量的请求分配给性能较差的服务器,这显然是不合理的。因此,这个时候我们需要加权轮询算法,对轮询过程进行干预,使得性能好的服务器可以得到更多的请求,性能差的得到的少一些。每台服务器能够得到的请求数比例,接近或等于他们的权重比。比如服务器 A、B、C 权重比为 5:2:1。那么在8次请求中,服务器 A 将获取到其中的5次请求,服务器 B 获取到其中的2次请求,服务器 C 则获取到其中的1次请求。
以上就是加权轮询的算法思想,搞懂了这个思想,接下来我们就可以分析源码了。我们先来看一下 2.6.4 版本的 RoundRobinLoadBalance。
public class RoundRobinLoadBalance extends AbstractLoadBalance {public static final String NAME = "roundrobin";private final ConcurrentMap<String, AtomicPositiveInteger> sequences = new ConcurrentHashMap<String, AtomicPositiveInteger>();@Overrideprotected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {// key = 全限定类名 + "." + 方法名,比如 com.xxx.DemoService.sayHelloString key = invokers.get(0).getUrl().getServiceKey() + "." + invocation.getMethodName();int length = invokers.size();// 最大权重int maxWeight = 0;// 最小权重int minWeight = Integer.MAX_VALUE;final LinkedHashMap<Invoker<T>, IntegerWrapper> invokerToWeightMap = new LinkedHashMap<Invoker<T>, IntegerWrapper>();// 权重总和int weightSum = 0;// 下面这个循环主要用于查找最大和最小权重,计算权重总和等for (int i = 0; i < length; i++) {int weight = getWeight(invokers.get(i), invocation);// 获取最大和最小权重maxWeight = Math.max(maxWeight, weight);minWeight = Math.min(minWeight, weight);if (weight > 0) {// 将 weight 封装到 IntegerWrapper 中invokerToWeightMap.put(invokers.get(i), new IntegerWrapper(weight));// 累加权重weightSum += weight;}}// 查找 key 对应的对应 AtomicPositiveInteger 实例,为空则创建。// 这里可以把 AtomicPositiveInteger 看成一个黑盒,大家只要知道// AtomicPositiveInteger 用于记录服务的调用编号即可。至于细节,// 大家如果感兴趣,可以自行分析AtomicPositiveInteger sequence = sequences.get(key);if (sequence == null) {sequences.putIfAbsent(key, new AtomicPositiveInteger());sequence = sequences.get(key);}// 获取当前的调用编号int currentSequence = sequence.getAndIncrement();// 如果 最小权重 < 最大权重,表明服务提供者之间的权重是不相等的if (maxWeight > 0 && minWeight < maxWeight) {// 使用调用编号对权重总和进行取余操作int mod = currentSequence % weightSum;// 进行 maxWeight 次遍历for (int i = 0; i < maxWeight; i++) {// 遍历 invokerToWeightMapfor (Map.Entry<Invoker<T>, IntegerWrapper> each : invokerToWeightMap.entrySet()) {// 获取 Invokerfinal Invoker<T> k = each.getKey();// 获取权重包装类 IntegerWrapperfinal IntegerWrapper v = each.getValue();// 如果 mod = 0,且权重大于0,此时返回相应的 Invokerif (mod == 0 && v.getValue() > 0) {return k;}// mod != 0,且权重大于0,此时对权重和 mod 分别进行自减操作if (v.getValue() > 0) {v.decrement();mod--;}}}}// 服务提供者之间的权重相等,此时通过轮询选择 Invokerreturn invokers.get(currentSequence % length);}// IntegerWrapper 是一个 int 包装类,主要包含了一个自减方法。// 与 Integer 不同,Integer 是不可变类,而 IntegerWrapper 是可变类private static final class IntegerWrapper {private int value;public void decrement() {this.value--;}// 省略部分代码}
}如上,RoundRobinLoadBalance 的每行代码都不是很难理解,但是将它们组合到一起之后,好像就看不懂了。这里对上面代码的主要逻辑进行总结,如下:
- 找到最大权重值,并计算出权重和
- 使用调用编号对权重总和进行取余操作,得到 mod
- 检测 mod 的值是否等于0,且 Invoker 权重是否大于0,如果两个条件均满足,则返回该 Invoker
- 如果上面条件不满足,且 Invoker 权重大于0,此时对 mod 和权重进行递减
- 再次循环,重复步骤3、4
以上过程对应的原理不太好解释,所以下面直接举例说明把。假设我们有三台服务器 servers = [A, B, C],对应的权重为 weights = [2, 5, 1]。接下来对上面的逻辑进行简单的模拟。
mod = 0:满足条件,此时直接返回服务器 A
mod = 1:需要进行一次递减操作才能满足条件,此时返回服务器 B
mod = 2:需要进行两次递减操作才能满足条件,此时返回服务器 C
mod = 3:需要进行三次递减操作才能满足条件,经过递减后,服务器权重为 [1, 4, 0],此时返回服务器 A
mod = 4:需要进行四次递减操作才能满足条件,经过递减后,服务器权重为 [0, 4, 0],此时返回服务器 B
mod = 5:需要进行五次递减操作才能满足条件,经过递减后,服务器权重为 [0, 3, 0],此时返回服务器 B
mod = 6:需要进行六次递减操作才能满足条件,经过递减后,服务器权重为 [0, 2, 0],此时返回服务器 B
mod = 7:需要进行七次递减操作才能满足条件,经过递减后,服务器权重为 [0, 1, 0],此时返回服务器 B
经过8次调用后,我们得到的负载均衡结果为 [A, B, C, A, B, B, B, B],次数比 A:B:C = 2:5:1,等于权重比。当 sequence = 8 时,mod = 0,此时重头再来。从上面的模拟过程可以看出,当 mod >= 3 后,服务器 C 就不会被选中了,因为它的权重被减为0了。当 mod >= 4 后,服务器 A 的权重被减为0,此后 A 就不会再被选中。
以上是 2.6.4 版本的 RoundRobinLoadBalance 分析过程,大家如果看不懂,自己可以定义一些权重组合进行模拟。也可以写点测试用例,进行调试分析,总之不要死看。
2.6.4 版本的 RoundRobinLoadBalance 存在着比较严重的性能问题,该问题最初是在 issue #2578 中被反馈出来。问题出在了 Invoker 的返回时机上,RoundRobinLoadBalance 需要在mod == 0 && v.getValue() > 0 条件成立的情况下才会被返回相应的 Invoker。假如 mod 很大,比如 10000,50000,甚至更大时,doSelect 方法需要进行很多次计算才能将 mod 减为0。由此可知,doSelect 的效率与 mod 有关,时间复杂度为 O(mod)。mod 又受最大权重 maxWeight 的影响,因此当某个服务提供者配置了非常大的权重,此时 RoundRobinLoadBalance 会产生比较严重的性能问题。这个问题被反馈后,社区很快做了回应。并对 RoundRobinLoadBalance 的代码进行了重构,将时间复杂度优化至了常量级别。这个优化可以说很好了,下面我们来学习一下优化后的代码。
public class RoundRobinLoadBalance extends AbstractLoadBalance {public static final String NAME = "roundrobin";private final ConcurrentMap<String, AtomicPositiveInteger> sequences = new ConcurrentHashMap<String, AtomicPositiveInteger>();private final ConcurrentMap<String, AtomicPositiveInteger> indexSeqs = new ConcurrentHashMap<String, AtomicPositiveInteger>();@Overrideprotected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {String key = invokers.get(0).getUrl().getServiceKey() + "." + invocation.getMethodName();int length = invokers.size();int maxWeight = 0;int minWeight = Integer.MAX_VALUE;final List<Invoker<T>> invokerToWeightList = new ArrayList<>();// 查找最大和最小权重for (int i = 0; i < length; i++) {int weight = getWeight(invokers.get(i), invocation);maxWeight = Math.max(maxWeight, weight);minWeight = Math.min(minWeight, weight);if (weight > 0) {invokerToWeightList.add(invokers.get(i));}}// 获取当前服务对应的调用序列对象 AtomicPositiveIntegerAtomicPositiveInteger sequence = sequences.get(key);if (sequence == null) {// 创建 AtomicPositiveInteger,默认值为0sequences.putIfAbsent(key, new AtomicPositiveInteger());sequence = sequences.get(key);}// 获取下标序列对象 AtomicPositiveIntegerAtomicPositiveInteger indexSeq = indexSeqs.get(key);if (indexSeq == null) {// 创建 AtomicPositiveInteger,默认值为 -1indexSeqs.putIfAbsent(key, new AtomicPositiveInteger(-1));indexSeq = indexSeqs.get(key);}if (maxWeight > 0 && minWeight < maxWeight) {length = invokerToWeightList.size();while (true) {int index = indexSeq.incrementAndGet() % length;int currentWeight = sequence.get() % maxWeight;// 每循环一轮(index = 0),重新计算 currentWeightif (index == 0) {currentWeight = sequence.incrementAndGet() % maxWeight;}// 检测 Invoker 的权重是否大于 currentWeight,大于则返回if (getWeight(invokerToWeightList.get(index), invocation) > currentWeight) {return invokerToWeightList.get(index);}}}// 所有 Invoker 权重相等,此时进行普通的轮询即可return invokers.get(sequence.incrementAndGet() % length);}
}上面代码的逻辑是这样的,每进行一轮循环,重新计算 currentWeight。如果当前 Invoker 权重大于 currentWeight,则返回该 Invoker。还是举例说明吧,假设服务器 [A, B, C] 对应权重 [5, 2, 1]。
第一轮循环,currentWeight = 1,可返回 A 和 B
第二轮循环,currentWeight = 2,返回 A
第三轮循环,currentWeight = 3,返回 A
第四轮循环,currentWeight = 4,返回 A
第五轮循环,currentWeight = 0,返回 A, B, C
如上,这里的一轮循环是指 index 再次变为0所经历过的循环,这里可以把 index = 0 看做是一轮循环的开始。每一轮循环的次数与 Invoker 的数量有关,Invoker 数量通常不会太多,所以我们可以认为上面代码的时间复杂度为常数级。
重构后的 RoundRobinLoadBalance 看起来已经很不错了,但是在代码更新不久后,很有又被重构了。这次重构原因是新的 RoundRobinLoadBalance 在某些情况下选出的服务器序列不够均匀。比如,服务器 [A, B, C] 对应权重 [5, 1, 1]。现在进行7次负载均衡,选择出来的序列为 [A, A, A, A, A, B, C]。前5个请求全部都落在了服务器 A上,分布不够均匀。这将会使服务器 A 短时间内接收大量的请求,压力陡增。而 B 和 C 无请求,处于空闲状态。我们期望的结果是这样的 [A, A, B, A, C, A, A],不同服务器可以穿插获取请求。为了增加负载均衡结果的平滑性,社区再次对 RoundRobinLoadBalance 的实现进行了重构。这次重构参考自 Nginx 的平滑加权轮询负载均衡,实现原理是这样的。每个服务器对应两个权重,分别为 weight 和 currentWeight。其中 weight 是固定的,currentWeight 是会动态调整,初始值为0。当有新的请求进来时,遍历服务器列表,让它的 currentWeight 加上自身权重。遍历完成后,找到最大的 currentWeight,并将其减去权重总和,然后返回相应的服务器即可。
上面描述不是很好理解,下面还是举例说明吧。仍然使用服务器 [A, B, C] 对应权重 [5, 1, 1] 的例子进行说明,现在有7个请求依次进入负载均衡逻辑,选择过程如下:
| 请求编号 | currentWeight 数组 | 选择结果 | 减去权重总和后的 currentWeight 数组 |
|---|---|---|---|
| 1 | [5, 1, 1] | A | [-2, 1, 1] |
| 2 | [3, 2, 2] | A | [-4, 2, 2] |
| 3 | [1, 3, 3] | B | [1, -4, 3] |
| 4 | [6, -3, 4] | A | [-1, -3, 4] |
| 5 | [4, -2, 5] | C | [4, -2, -2] |
| 6 | [9, -1, -1] | A | [2, -1, -1] |
| 7 | [7, 0, 0] | A | [0, 0, 0] |
如上,经过平滑性处理后,得到的服务器序列为 [A, A, B, A, C, A, A],相比之前的序列 [A, A, A, A, A, B, C],分布性要好一些。初始情况下 currentWeight = [0, 0, 0],第7个请求处理完后,currentWeight 再次变为 [0, 0, 0],是不是很神奇。这个结果也不难理解,在7次计算过程中,每个服务器的 currentWeight 都增加了自身权重 weight * 7,得到 currentWeight = [35, 7, 7],A 被选中5次,要被减去 5 * 7。B 和 C 被选中1次,要被减去 1 * 7。于是 currentWeight = [35, 7, 7] – [35, 7, 7] = [0, 0, 0]。
以上就是平滑加权轮询的计算过程,现在大家应该对平滑加权轮询算法了有了一些了解。接下来,我们来看看 Dubbo-2.6.5 是如何实现上面的计算过程的。
public class RoundRobinLoadBalance extends AbstractLoadBalance {public static final String NAME = "roundrobin";private static int RECYCLE_PERIOD = 60000;protected static class WeightedRoundRobin {// 服务提供者权重private int weight;// 当前权重private AtomicLong current = new AtomicLong(0);// 最后一次更新时间private long lastUpdate;public void setWeight(int weight) {this.weight = weight;// 初始情况下,current = 0current.set(0);}public long increaseCurrent() {// current = current + weight;return current.addAndGet(weight);}public void sel(int total) {// current = current - total;current.addAndGet(-1 * total);}}// 嵌套 Map 结构,存储的数据结构示例如下:// {// "UserService.query": {// "url1": WeightedRoundRobin@123, // "url2": WeightedRoundRobin@456, // },// "UserService.update": {// "url1": WeightedRoundRobin@123, // "url2": WeightedRoundRobin@456,// }// }// 最外层为服务类名 + 方法名,第二层为 url 到 WeightedRoundRobin 的映射关系。// 这里我们可以将 url 看成是服务提供者的 idprivate ConcurrentMap<String, ConcurrentMap<String, WeightedRoundRobin>> methodWeightMap = new ConcurrentHashMap<String, ConcurrentMap<String, WeightedRoundRobin>>();// 原子更新锁private AtomicBoolean updateLock = new AtomicBoolean();@Overrideprotected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {String key = invokers.get(0).getUrl().getServiceKey() + "." + invocation.getMethodName();// 获取 url 到 WeightedRoundRobin 映射表,如果为空,则创建一个新的ConcurrentMap<String, WeightedRoundRobin> map = methodWeightMap.get(key);if (map == null) {methodWeightMap.putIfAbsent(key, new ConcurrentHashMap<String, WeightedRoundRobin>());map = methodWeightMap.get(key);}int totalWeight = 0;long maxCurrent = Long.MIN_VALUE;// 获取当前时间long now = System.currentTimeMillis();Invoker<T> selectedInvoker = null;WeightedRoundRobin selectedWRR = null;// 下面这个循环主要做了这样几件事情:// 1. 遍历 Invoker 列表,检测当前 Invoker 是否有// 对应的 WeightedRoundRobin,没有则创建// 2. 检测 Invoker 权重是否发生了变化,若变化了,// 则更新 WeightedRoundRobin 的 weight 字段// 3. 让 current 字段加上自身权重,等价于 current += weight// 4. 设置 lastUpdate 字段,即 lastUpdate = now// 5. 寻找具有最大 current 的 Invoker 以及 WeightedRoundRobin,// 暂存起来,留作后用// 6. 计算权重总和for (Invoker<T> invoker : invokers) {String identifyString = invoker.getUrl().toIdentityString();WeightedRoundRobin weightedRoundRobin = map.get(identifyString);int weight = getWeight(invoker, invocation);if (weight < 0) {weight = 0;}// 检测当前 Invoker 是否有对应的 WeightedRoundRobin,没有则创建if (weightedRoundRobin == null) {weightedRoundRobin = new WeightedRoundRobin();// 设置 Invoker 权重weightedRoundRobin.setWeight(weight);// 存储 url 唯一标识 identifyString 到 weightedRoundRobin 的映射关系map.putIfAbsent(identifyString, weightedRoundRobin);weightedRoundRobin = map.get(identifyString);}// Invoker 权重不等于 WeightedRoundRobin 中保存的权重,说明权重变化了,此时进行更新if (weight != weightedRoundRobin.getWeight()) {weightedRoundRobin.setWeight(weight);}// 让 current 加上自身权重,等价于 current += weightlong cur = weightedRoundRobin.increaseCurrent();// 设置 lastUpdate,表示近期更新过weightedRoundRobin.setLastUpdate(now);// 找出最大的 current if (cur > maxCurrent) {maxCurrent = cur;// 将具有最大 current 权重的 Invoker 赋值给 selectedInvokerselectedInvoker = invoker;// 将 Invoker 对应的 weightedRoundRobin 赋值给 selectedWRR,留作后用selectedWRR = weightedRoundRobin;}// 计算权重总和totalWeight += weight;}// 对 <identifyString, WeightedRoundRobin> 进行检查,过滤掉长时间未被更新的节点。// 该节点可能挂了,invokers 中不包含该节点,所以该节点的 lastUpdate 长时间无法被更新。// 若未更新时长超过阈值后,就会被移除掉,默认阈值为60秒。if (!updateLock.get() && invokers.size() != map.size()) {if (updateLock.compareAndSet(false, true)) {try {ConcurrentMap<String, WeightedRoundRobin> newMap = new ConcurrentHashMap<String, WeightedRoundRobin>();// 拷贝newMap.putAll(map);// 遍历修改,也就是移除过期记录Iterator<Entry<String, WeightedRoundRobin>> it = newMap.entrySet().iterator();while (it.hasNext()) {Entry<String, WeightedRoundRobin> item = it.next();if (now - item.getValue().getLastUpdate() > RECYCLE_PERIOD) {it.remove();}}// 更新引用methodWeightMap.put(key, newMap);} finally {updateLock.set(false);}}}if (selectedInvoker != null) {// 让 current 减去权重总和,等价于 current -= totalWeightselectedWRR.sel(totalWeight);// 返回具有最大 current 的 Invokerreturn selectedInvoker;}// should not happen herereturn invokers.get(0);}
}以上就是 Dubbo-2.6.5 版本的 RoundRobinLoadBalance,大家如果能够理解平滑加权轮询算法的计算过程,再配合我写的注释,理解上面的代码应该不难。
以上就是关于 RoundRobinLoadBalance 全部的分析,内容有点多,大家慢慢消化吧。好了,本节先到这。