目录
1 问题背景
2 批量梯度下降 (Batch Gradient Descent)
3 鞍点(Saddle Point)
3 随机梯度下降 (Stochastic Gradient Descent)
4 小批量梯度下降 (Mini-batch Gradient Descent)
1 问题背景
在Lecture2中,介绍了使用穷举法来确定最优值,然而当遇到
范围较大,或者数量过多等情况时,穷举法的时间复杂度过大。因此,我们需要优化该算法。
2 批量梯度下降 (Batch Gradient Descent)
在这次课中,介绍了一种寻找最优值的算法——批量梯度下降 (Batch Gradient Descent, BGD)
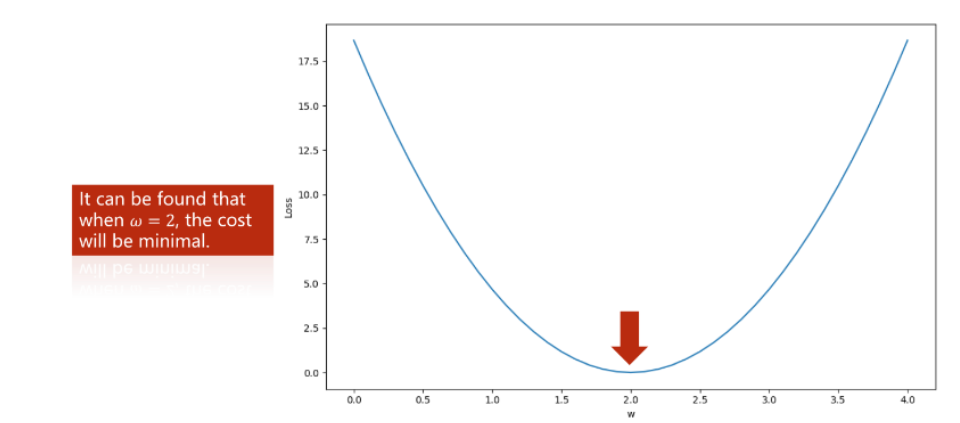
简单介绍下该算法。首先对于下图:
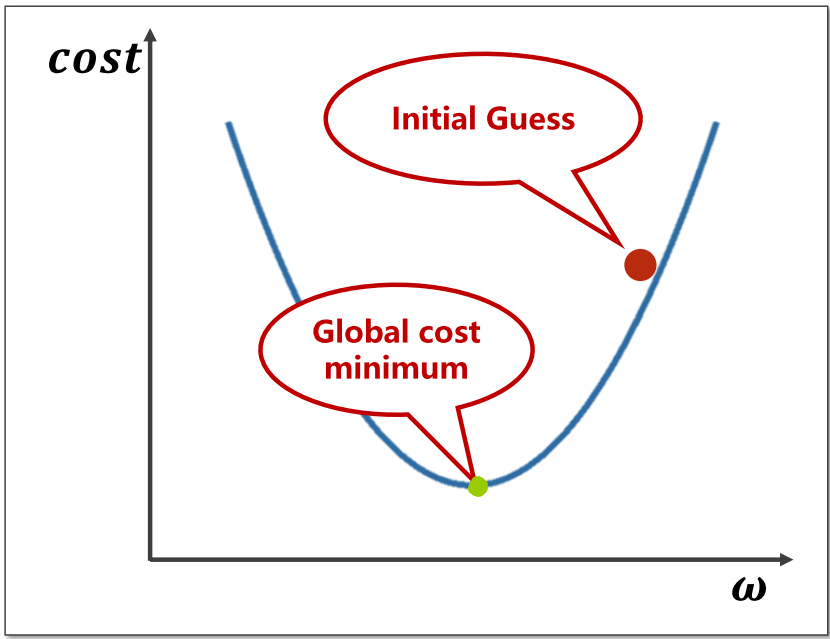
假设我们目前的起始位于上图红色点,为了找到最优
点(位于绿点),那么我们需要向左边移动,这样才能到达最优
点。
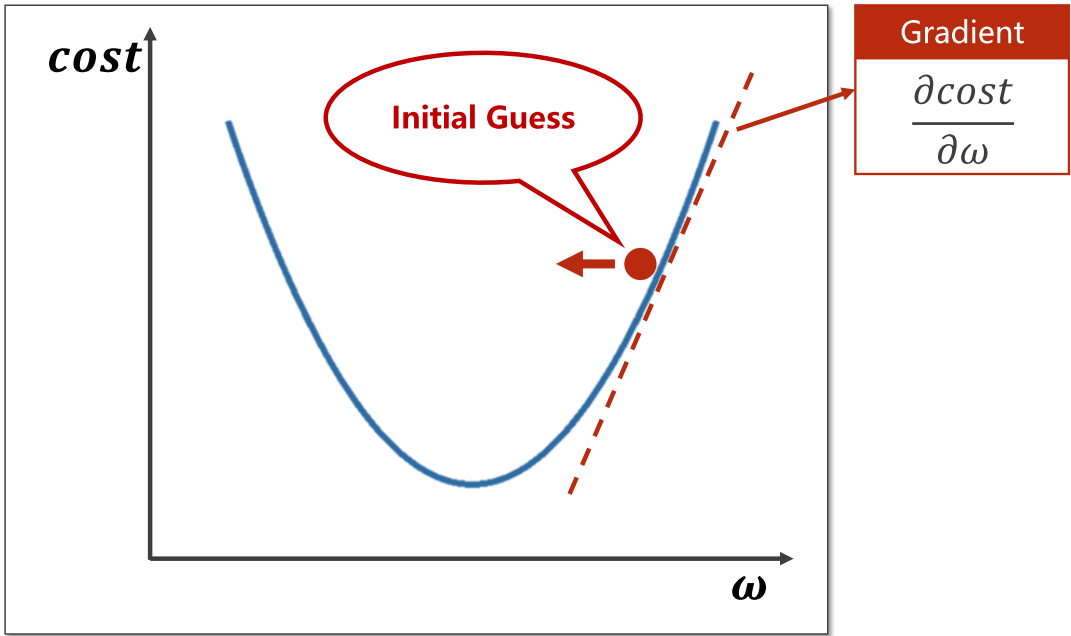
如何让权值点向左还是向右移动呢?此时我们需要计算当前点的梯度(Gradient),也就是用成本函数对权重进行求导,如果梯度<0,则向函数值递减方向移动;梯度>0,则向函数值递增方向移动。
因为要移动起来,所以我们每移动一步,就要更新一下值。更新函数如下图Update处:
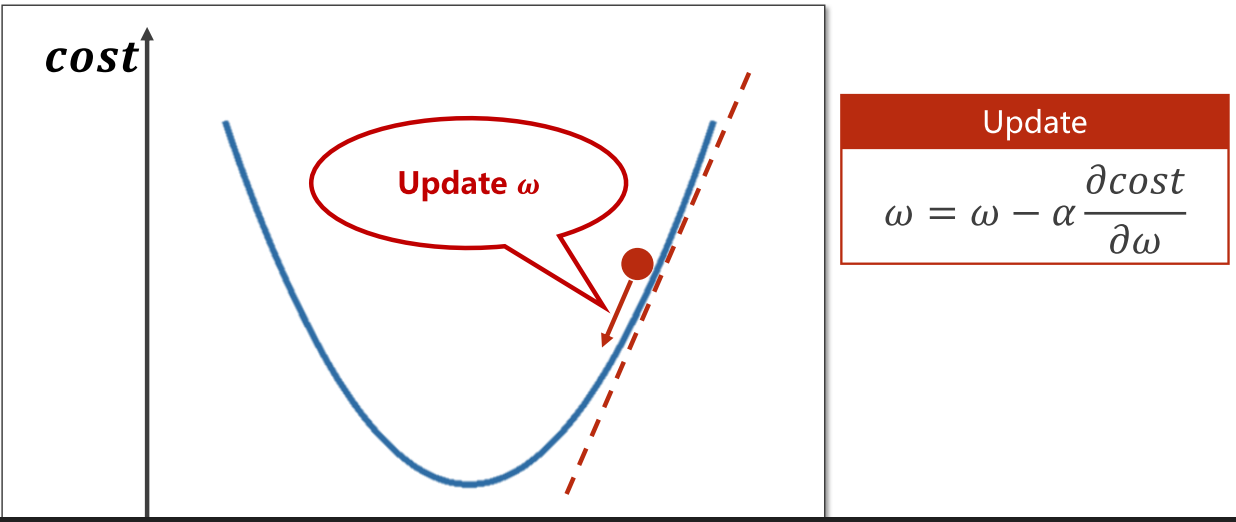
在这个更新函数中, α代表学习率(Learning Rate),学习率是机器学习中常用的一个超参数,它定义了每次更新参数时步长的大小,即每次更新参数时参数值变化的幅度。如果学习率设置得过大,所求结果可能会在最优解的附近来回震荡,而无法找到全局最优解。如果学习率设置得过小,那么模型的训练将会非常缓慢,甚至找不到最优解。
这个式子中,梯度前面用了减号,是为了朝函数值递减方向,也就是往最优所在的点移动,所以在梯度前面加负号。 就这样持续一步步地更新
,直到找到最优
。
下面我们来具体讲讲如何去计算更新函数中的 :

计算过程中,需要用到上节课总结的两个公式:
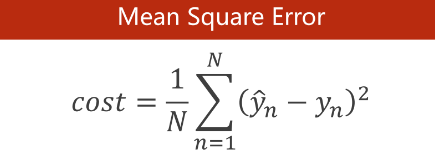

接着把上述两个公式代入原式:

蓝色处,因为cost=MSE,所以直接代入上一节课的MSE公式,然后对求导。
绿色处,由有理运算法则,和的导数等于导数的和,所以这里可以把移入求和式子中,对里面先进行求导后,再求和相加。
黄色处,根据复合导数的链式求导法进行求导。
代码实现
from matplotlib import pyplot as pltx_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = 1.0 # 初始权重,由这个权重开始迭代'''线性模型,算出预测值y_hat'''
def forward(x):return x * w'''均方误差MSE'''
def cost(xs, ys):cost = 0for x, y in zip(xs, ys):y_pred = forward(x) # 算出y_hatcost += (y_pred - y) ** 2 # (y_hat - y)²return cost / len(xs) # 除以样本总数求均值'''梯度下降公式'''
def gradient(xs, ys):grad = 0for x, y in zip(xs, ys):grad += 2 * x * (x * w - y)return grad / len(xs)print('Predict (before training)', 4, forward(4)) # 训练前,模型对输入的4的最终预测结果cost_list = [] # 保存每轮迭代后的cost值
epoch_list = [] # 保存每轮的迭代后的epoch值
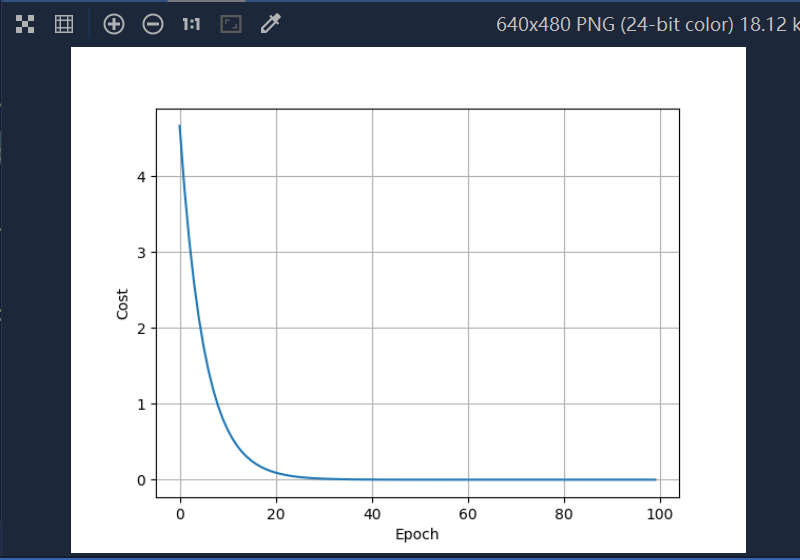
for epoch in range(100): # 进行100轮训练cost_val = cost(x_data, y_data)grad_val = gradient(x_data, y_data)w -= 0.01 * grad_val # 使用梯度下降法更新权重,0.01表示学习率print('Epoch:', epoch, 'w=%.2f' % w, 'loss=%.2f' % cost_val)cost_list.append(cost_val)epoch_list.append(epoch)
print('Predict (after training)', 4, forward(4)) # 训练后,模型对输入的4的最终预测结果'''绘图'''
plt.plot(epoch_list, cost_list)
plt.ylabel('Cost')
plt.xlabel('Epoch')
plt.grid()
plt.show()
将MSE公式和Linear Model公式代入整合,的最终更新函数:

补充
训练后的结果一般来说,cost会趋于收敛情况

如果发生如下情况,说明训练失败,原因有很多,其中之一可能是学习率取得太大:
这就是批量梯度下降算法,本质上是一个贪心算法(Greedy Algorithm)。不过该算法有局限性,比如当前的预测值正好位于下图绿线处,因为再往右移动会梯度会发生变化,使得程序直接终止,于是误将红的点作为最优
值,而忽略了处于蓝色点的最优
值:
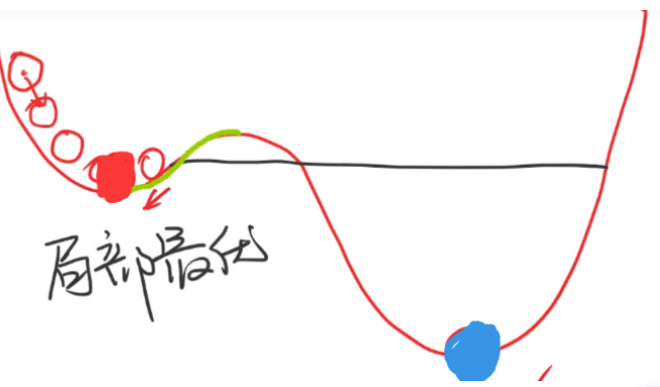
我们把上图中的红点称为局部最优点(Local Optimum),蓝色点称为全局最优点(Global Optimum)。因此对于该梯度下降算法,很可能会找到局部最优点,而忽略了全局最优点。不过这种现象不必担心,因为在实际训练中,往往很难陷入局部最优点。
3 鞍点(Saddle Point)
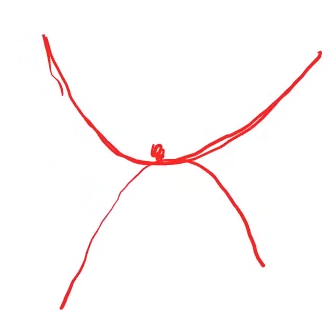
在实际训练中,往往很难陷入局部最优点,而最需要解决的问题是鞍点(Saddle Point),鞍点是机器学习和数学中的一个概念,它指的是一个特殊的局部极小值,在某些方向上是极小值,但在其他方向上是极大值。在一元函数中,梯度=0的点就是鞍点。比如下图中,红色小球所处的位置就在鞍点,此时梯度为零,会导致更新函数无法更新(因为梯度=0,=
-α*0相当于没有发生更新):

从多维角度来分析,比如下图红球处于马鞍面(Saddle Surface),从一个切面看可以处于最小值,从另一个切面看又处于最大值:
在优化问题中,鞍点是一种特殊的局部最优解,是一个难以优化的点,因为优化算法可能很难从鞍点附近找到全局最优解。这是因为,如果优化算法在鞍点附近搜索,它可能会被误导到其他附近的局部最优解,而不是真正的全局最优解。所以在深度学习中,需要克服的最大问题就是鞍点而非局部最优问题。
3 随机梯度下降 (Stochastic Gradient Descent)
随机梯度下降 (Stochastic Gradient Descent, SGD)在深度学习中很常用,和BGD算法的区别是,BGD使用所有的样本的均值的平均损失来作为的更新依据,而SGD是从所有样本中随机选择单个样本的损失值来对
进行更新。
随机梯度下降的优点是,每次仅使用一个数据点的梯度,因此在每次迭代时都有可能沿着非0梯度的方向更新参数,这样就避免陷入到鞍点导致无法更新参数。

代码实现
import randomx_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = 1.0def forward(x):return x * wdef loss(x, y):y_pred = forward(x)return (y_pred - y) ** 2def gradient(x, y):return 2 * x * (x * w - y)print('Predict (before training)', 4, forward(4))
for epoch in range(100):t = random.randrange(0, 3) # 随机得到一个样本x = x_data[t]y = y_data[t]grad = gradient(x, y)w = w - 0.01 * gradprint("\tgrad: ", x, y, '%.2f' % grad)l = loss(x, y)print("progress:", epoch, "w=%.2f" % w, "loss=%.2f" % l)
print('Predict (after training)', 4, forward(4))
部分输出结果
Predict (before training) 4 4.0
grad: 3.0 6.0 -18.00
progress: 0 w=1.18 loss=6.05
grad: 2.0 4.0 -6.56
progress: 1 w=1.25 loss=2.28
grad: 3.0 6.0 -13.58
progress: 2 w=1.38 loss=3.44
grad: 1.0 2.0 -1.24
progress: 3 w=1.39 loss=0.37
grad: 2.0 4.0 -4.85
progress: 4 w=1.44 loss=1.24···
grad: 1.0 2.0 -0.00
progress: 97 w=2.00 loss=0.00
grad: 1.0 2.0 -0.00
progress: 98 w=2.00 loss=0.00
grad: 2.0 4.0 -0.00
progress: 99 w=2.00 loss=0.00
Predict (after training) 4 7.999910864525451
4 小批量梯度下降 (Mini-batch Gradient Descent)
SGD算法虽然可以在一定程度上避免陷入局部最优以及鞍点问题,但是运算所需时间复杂度过高,每次仅使用一个数据点的梯度,因此它的收敛速度通常比较慢。
因此有一个折中的办法,就是使用小批量梯度下降 (Mini-batch Gradient Descent) 算法。简单来说,小批量梯度下降是一种介于批量梯度下降和随机梯度下降之间的优化算法。结合了这两种方法,通过使用小的随机选择的训练数据子集(称为mini-batch)计算损失函数关于参数的梯度的平均值来更新模型参数。
总之,小批量梯度下降算法实现了BGD的高计算效率和SGD的良好收敛性之间的平衡。