一、问题剖析
这不是前几天面试官开局面试官就让我设计一个路由,二面过了,结果今天来个三面。
问你道简单的送分题:设计一个虚拟DOM算法?

好家伙,来吧,先进行问题剖析,谁让我们是卑微的打工人呢?
既来之,则安之。
Vue的虚拟DOM干嘛的,和diff有什么关系?
Are they friends?
我们在Vue项目实战中我们可能感受不到虚拟DOM的强大魅力,但它却是我们性能优化、响应速度背后重要的技术点,既然被问到了,那面试中我们怎么去回答比较好,我个人觉得可以从以下七个方面去回答这个面试题。
- 先说一下虚拟DOM是什么?(是什么)
- 为什么需要虚拟DOM?(为什么)
- 使用了之后,有什么好处?
- 如何实现该算法?(怎么实现)
- 在后续的diff中的作用?
- vue3中diff做了什么优化点?
- 聊到虚拟DOM,可以再聊一下,key属性的作用。
老子说过:道生一,一生二,二生三,三生万物。
个人觉得回答一个问题,如果可以引申出问题不同角度或者与其相关的知识点,那面试官可能会觉得你这个人有广度,思维不局限在当前问题下,可能对你刮目相看。
二、虚拟DOM是什么?
虚拟dom就是虚拟的dom对象,通过JavaScript 对象来模拟dom对象。
简而言之:一个JS对象,里面存放着DOM对象的数据。
三、为什么需要虚拟DOM?
首先,我们都知道在前端性能优化的一个秘诀就是尽可能少地操作DOM,不仅仅是DOM相对较慢,更因为频繁变动DOM会造成浏览器的回流或者重回,这些都是性能的杀手,因此我们需要这一层抽象。
在patch过程中尽可能地一次性将差异更新到DOM中,这样保证了DOM不会出现性能很差的情况。
Vue的虚拟DOM是借鉴snabbdom.js库实现的。
关于回流或者重回的,后期出一篇文章讲讲。

四、使用了之后,有什么好处?
通过引入vdom我们可以获得如下好处:
- 将真实元素节点抽象成 虚拟DOM,有效减少直接操作 dom 次数,从而提高程序性能方便实现跨平台。
- 操作 dom 是很耗性能的操作,频繁的dom操作容易引起页面的重绘和回流,但是通过抽象 VNode 进行中间处理,可以有效减少直接操作dom的次数,从而减少页面重绘和回流。
五、如何实现该算法?
重头戏来了。
我们分为三个步骤来实现虚拟DOM算法。
- 用JS对象模拟DOM树。
- 比较两棵虚拟DOM树的差异。
- 把差异应用到真正的DOM树上。
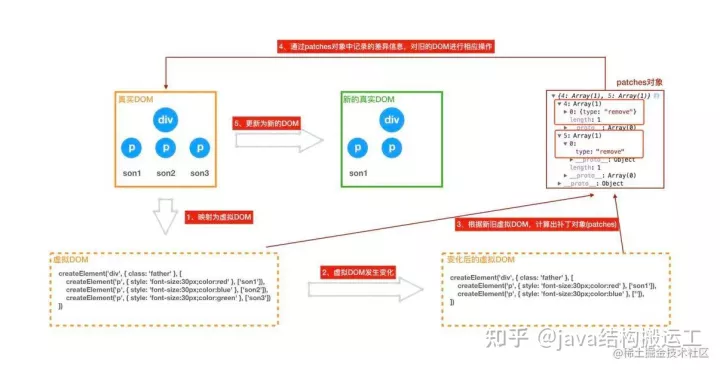
我们先来看看如果Vue没有用虚拟DOM之前的情况是怎样的?
此时状态发生了变化,就用模板引擎重新渲染整个视图,然后用新的视图更换掉旧的视图。
这样子做有什么不优雅的点呢?
最大的问题就是这样做会很慢,因为即使一个小小的状态变更都要重新构造整棵 DOM,性价比太低;
而且这样做的话,input和textarea的会失去原有的焦点。(因为你重新渲染了)
当然,这种做法对于局部小视图的更新,是没有问题的;但是对于大型视图,如全局应用状态变更的时候,需要更新页面较多局部视图的时候,这样的做法不可取。
Virtual DOM诞生
所以虚拟DOM(Virtual DOM)出来了。
核心是:维护状态,更新视图。
好处也显而易见。
相对于 DOM 对象,原生的 JavaScript 对象处理起来更快,而且更简单。DOM 树上的结构、属性信息我们都可以很容易地用 JavaScript 对象表示出来:
新渲染的对象树去和旧的树进行对比,记录这两棵树差异。记录下来的不同就是我们需要对页面真正的 DOM 操作,然后把它们应用在真正的 DOM 树上,页面就变更了。这样就可以做到:视图的结构确实是整个全新渲染了,但是最后操作DOM的时候确实只变更有不同的地方。
Virtual DOM 的几个主要步骤
- 用 JavaScript 对象结构表示 DOM 树的结构;然后用这个树构建一个真正的 DOM 树,插到文档当中。
- 当状态变更的时候,重新构造一棵新的对象树。然后用新的树和旧的树进行比较,记录两棵树差异。
- 把2所记录的差异应用到步骤1所构建的真正的DOM树上,视图就更新了。
可以这样理解:
Virtual DOM 本质上就是在 JS 和 DOM 之间做了一个缓存。
可以类比 CPU 和硬盘,既然硬盘这么慢,我们就在它们之间加个缓存:
既然 DOM 这么慢,我们就在它们 JS 和 DOM 之间加个缓存。
CPU(JS)只操作内存(Virtual DOM),最后的时候再把变更写入硬盘(DOM)。
算法实现
5.1 用JS对象模拟DOM树
用 JavaScript 来表示一个 DOM 节点是很简单的事情,你只需要记录它的节点类型、属性,还有子节点:
创建元素对象:
element.js
function Element (tagName, props, children) {this.tagName = tagNamethis.props = propsthis.children = children
}module.exports = function (tagName, props, children) {return new Element(tagName, props, children)
}
复制代码使用示范:
var el = require('./element')var ul = el('ul', {id: 'list'}, [ el('li', {class: 'item'}, ['Item 1']),el('li', {class: 'item'}, ['Item 2']),el('li', {class: 'item'}, ['Item 3'])]
)
复制代码现在ul只是一个 JavaScript 对象表示的 DOM 结构,页面上并没有这个结构。我们可以根据这个ul构建真正的<ul>:
为Element添加渲染函数render。
Element.prototype.render = function () {var el = document.createElement(this.tagName) // 根据tagName构建var props = this.propsfor (var propName in props) { // 设置节点的DOM属性var propValue = props[propName]el.setAttribute(propName, propValue)}var children = this.children || []children.forEach(function (child) {var childEl = (child instanceof Element)? child.render() // 如果子节点也是虚拟DOM,递归构建DOM节点: document.createTextNode(child) // 如果字符串,只构建文本节点el.appendChild(childEl)})return el
}
复制代码render方法会根据tagName构建一个真正的DOM节点,然后设置这个节点的属性,最后递归地把自己的子节点也构建起来。所以只需要:
var ulRoot = ul.render()
document.body.appendChild(ulRoot)
复制代码到这里,我们已经可以将真实的DOM,用JS对象模拟出来。

5.2 比较两棵虚拟DOM树的差异
两个树的完全的 diff 算法是一个时间复杂度为 O(n^3) 的问题。但是在前端当中,你很少会跨越层级地移动DOM元素。所以 Virtual DOM 只会对同一个层级的元素进行对比:
这是虚拟DOM的关键:只对同一层级元素做对比。
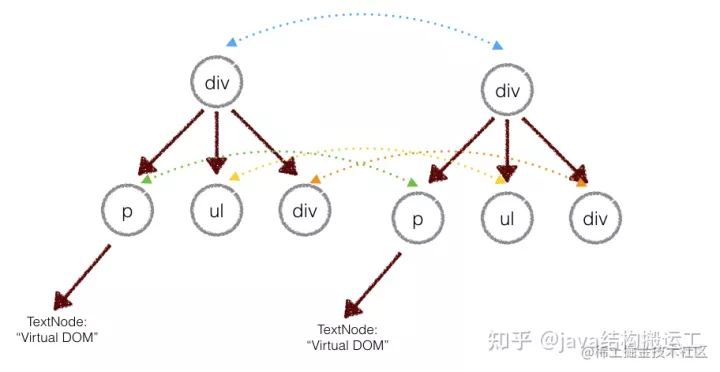
上面的div只会和同一层级的div对比,第二层级的只会跟第二层级对比。这样算法复杂度就可以达到 O(n)。
我们比较两棵虚拟DOM树的差异,分为两小步实现:
- 记录差异性。
- 有哪些类型的差异?
深度优先遍历,记录差异
我们会对新旧两棵树进行一个深度优先的遍历,这样每个节点都会有一个唯一的标记:
在深度优先遍历的时候,每遍历到一个节点就把该节点和新的的树进行对比。如果有差异的话就记录到一个对象patches里面。
// diff 函数,对比两棵树
function diff (oldTree, newTree) {var index = 0 // 当前节点的标志var patches = {} // 用来记录每个节点差异的对象dfsWalk(oldTree, newTree, index, patches)return patches
}// 对两棵树进行深度优先遍历
function dfsWalk (oldNode, newNode, index, patches) {// 对比oldNode和newNode的不同,记录下来patches[index] = [...]diffChildren(oldNode.children, newNode.children, index, patches)
}// 遍历子节点
function diffChildren (oldChildren, newChildren, index, patches) {var leftNode = nullvar currentNodeIndex = indexoldChildren.forEach(function (child, i) {var newChild = newChildren[i]currentNodeIndex = (leftNode && leftNode.count) // 计算节点的标识? currentNodeIndex + leftNode.count + 1: currentNodeIndex + 1dfsWalk(child, newChild, currentNodeIndex, patches) // 深度遍历子节点leftNode = child})
}
复制代码例如,上面的div和新的div有差异,当前的标记是0,那么:
patches[0] = [{difference}, {difference}, ...] // 用数组存储新旧节点的不同
复制代码同理p是patches[1],ul是patches[3],类推。
如图所示:

差异类型
接着看第二小步:有哪些差异类型?
上面说的节点的差异指的是什么呢?对 DOM 操作可能会:
- 替换掉原来的节点,例如把上面的div换成了section
- 移动、删除、新增子节点,例如上面div的子节点,把p和ul顺序互换
- 修改了节点的属性
- 对于文本节点,文本内容可能会改变。例如修改上面的文本节点2内容为帅气的呱哥。
所以我们定义了几种差异类型:
var REPLACE = 0
var REORDER = 1
var PROPS = 2
var TEXT = 3
复制代码对于节点替换,很简单。判断新旧节点的tagName和是不是一样的,如果不一样的说明需要替换掉。如div换成section,就记录下:
var REPLACE = 0; // 这是我们上面定义的类型
patches[0] = [{type: REPALCE,node: newNode // el('section', props, children)
}]
复制代码如果给div新增了属性id为container,就记录下:
var REPLACE = 0;var PROPS = 2
patches[0] = [{type: REPALCE,node: newNode // el('section', props, children)
}, {type: PROPS,props: {id: "container"}
}]
复制代码如果是文本节点,如上面的文本节点2,就记录下:
var TEXT = 3
patches[2] = [{type: TEXT,content: "帅气的呱哥"
}]
复制代码那如果把我div的子节点重新排序呢?
例如p, ul, div的顺序换成了div, p, ul。这个该怎么对比?
如果按照同层级进行顺序对比的话,它们都会被替换掉。如p和div的tagName不同,p会被div所替代。最终,三个节点都会被替换,这样DOM开销就非常大。而实际上是不需要替换节点,而只需要经过节点移动就可以达到,我们只需知道怎么进行移动。
以上的顺序变化:可采用乾坤大挪移。
通过动态规划求解,时间复杂度为 O(M * N)。但是我们并不需要真的达到最小的操作,我们只需要优化一些比较常见的移动情况,牺牲一定DOM操作,让算法时间复杂度达到线性的(O(max(M, N))。具体算法细节比较多
牺牲DOM,换取时间。
RED红发剧场版黄猿说过:不牺牲一些东西,哪来的和平。

5.3 把差异应用到真正的DOM树上
因为步骤一【5.1 用JS对象模拟DOM树】所构建的 JavaScript 对象树和render出来真正的DOM树的信息、结构是一样的。所以我们可以对那棵DOM树也进行深度优先的遍历,遍历的时候从步骤二生成的patches对象中找出当前遍历的节点差异,然后进行 DOM 操作。
那么vdom又如何成为dom呢?
我们经过【5.1用JS对象模拟DOM树】得知,vdom经过element函数变成vdom,用JS对象模拟DOM树。
他是在什么时候触发的?
♂️实际上,在vue中我们常常会为组件编写模板 - template, 这个模板会被编译器 - compiler编译为渲染函数,在接下来的挂载(mount)过程中会调用render函数,返回的对象就是虚拟dom。
但它们还不是真正的dom,所以会在后续的patch过程中进一步转化为dom。

小总结
Virtual DOM 算法主要是实现上面步骤的三个函数:element,diff,patch。然后就可以实际的进行使用:
// 1. 构建虚拟DOM
var tree = el('div', {'id': 'container'}, [el('h1', {style: 'color: blue'}, ['simple virtal dom']),el('p', ['Hello, virtual-dom']),el('ul', [el('li')])
])// 2. 通过虚拟DOM构建真正的DOM
var root = tree.render()
document.body.appendChild(root)// 3. 生成新的虚拟DOM
var newTree = el('div', {'id': 'container'}, [el('h1', {style: 'color: red'}, ['simple virtal dom']),el('p', ['Hello, virtual-dom']),el('ul', [el('li'), el('li')])
])// 4. 比较两棵虚拟DOM树的不同
var patches = diff(tree, newTree)// 5. 在真正的DOM元素上应用变更
patch(root, patches)
复制代码当然实际中还需要处理事件监听等;生成虚拟 DOM 的时候也可以加入 JSX 语法。
看到这里的靓仔,你很优秀了。
快End了,再坚持坚持。
六、在后续的diff中的作用?
关于diff算法,我个人觉得可以从以下四个方面去回答。
- 虚拟DOM和diff是什么关系?
- 为什么要用diff?
- 那它啥时候执行?
- 怎么执行?
虚拟DOM和diff是什么关系?
实际上,在vue中我们常常会为组件编写模板 - template, 这个模板会被编译器 - compiler编译为渲染函数,在接下来的挂载(mount)过程中会调用render函数,返回的对象就是虚拟dom。
挂载过程结束后,vue程序进入更新流程。如果某些响应式数据发生变化,将会引起组件重新render,此时就会生成新的vdom,和上一次的渲染结果diff就能得到变化的地方,从而转换为最小量的dom操作,高效更新视图。
简而言之:Diff算法就是一种对比算法,主要是对比旧的虚拟DOM和新的虚拟DOM,找出发生更改的节点,并只更新这些更改点,而不更新未发生变化的节点,从而准确的更新DOM,减少操作真实DOM的次数,提高性能。
我们在【5.3 把差异应用到真正的DOM树上】提到的,虚拟DOM在后续的patch过程中进一步转化为dom。主要是来提升性能。
这里的patch其实也叫Diff算法。
它的必要性
那我们已经知道虚拟DOM转成真正的DOM,需要Diff算法在转换过程中,提升性能。
其实在Vue1.x视图中每个依赖均有更新函数对应,可以做到精准更新,因此并不需要虚拟DOM和patching算法支持,但是这样粒度过细导致Vue1.x无法承载较大应用;Vue 2.x中为了降低Watcher粒度,每个组件只有一个Watcher与之对应,此时就需要引入patching算法才能精确找到发生变化的地方并高效更新。
简而言之:vue1之前是有变化,就全部变化;
vue2引入diff可以做到有变化,只需要找到那个变化的watcher去更新即可。
diff啥时候执行?
vue中diff执行的时刻是组件内响应式数据变更触发实例执行其更新函数时,更新函数会再次执行render函数获得最新的虚拟DOM,然后执行patch函数,并传入新旧两次虚拟DOM,通过比对两者找到变化的地方,最后将其转化为对应的DOM操作。
怎么执行?
这个是核心。圈起来,要考的。
其实我们在【5.2 比较两棵虚拟DOM树的差异】中有大概说过。
现在我们重点讲解一下。
滚动条警告⚠️⚠️⚠️
patch过程是一个递归过程,遵循深度优先、同层比较的策略;
- 首先判断两个节点是否为相同同类节点,不同则删除重新创建
- 如果双方都是文本则更新文本内容
- 如果双方都是元素节点则递归更新子元素,同时更新元素属性 更新子节点时又分了几种情况:(diff算法核心:新节点孩子 VS 旧节点孩子) 新的子节点是文本,老的子节点是数组则清空,并设置文本; 新的子节点是文本,老的子节点是文本则直接更新文本; 新的子节点是数组,老的子节点是文本则清空文本,并创建新子节点数组中的子元素; 新的子节点是数组,老的子节点也是数组,那么比较两组子节点
只能同级比较,不能跨层比较。
diff算法在比较过程中,是通过指针进行比较的。
vue2新老节点替换的规则:
- 旧前 和 新前;匹配:旧前的指针++、新前的指针++
- 旧后 和 新后;匹配:旧后的指针--、新后的指针--
- 旧前 和 新后;匹配:旧前的指针++、新后的指针--
- 旧后 和 新前;匹配:旧后的指针--、新前的指针++
- 以上都不满足条件 ===》 查找;匹配:新的指针++,新的添加到页面上并且新在旧的中有,要给旧的赋值为undefined
- 创建或者删除
可能突然对这个规则会有点难以理解,没关系,结合图理解一下:
其实很好理解的,建议把图拖到另外一个窗口,再结合以上规则试着理解一遍。

不要慌,跟着我的分析一步一步往下走理解。
分析过程:
这是diff比较复杂的过程:
- 旧前a、新前b
- 不匹配,下一个规则,旧后d,新后m
- 不匹配,下一个规则,旧前a,新后m
- 不匹配,下一个规则,旧后d,新前b
- 不匹配,下一个规则(第五种)
- 把新前b,创建到页面中,同时去找旧里面这个b的节点
- 找到了设置为undefined,即旧的数组是【a, undefined, c, d】
- (这里为什么设置为undefined,请看上面的规则,OK,Go on~)
- 新的指针++,变为1(到这里,我们终于把第一个给走完)
- 接着上面的四个步骤,还是不匹配,又走第五种
- 把新前c,创建到页面中,同时去找旧里面这个c的节点
- 找到了设置为undefined,即【a, undefined, undefined, d】
- 新的指针++,变为2
- 接着旧前a,新前也是a
- 匹配,旧指针++为1,新指针++为3
- OK,继续走,旧前指针是1,到了b这个位置,已经设置为undefined
- undefined在新的肯定找不到,判断如果为undefined,旧的指针++
- 新的指针不动,即旧指针变为2,新的还是3
- 来到c的位置,也是undefined,旧指针,变为3
- 旧前d,新前d,匹配
- 最后发现新的只剩下m了
- 创建,也就是第六种情况
理解后,就能明白diff的双端算法,头头比较、尾尾比较的意思了。
为什么说一定要加key?
因为如果不加的话,整个DOM不能复用,需要删除重新建立。
所以,如果要提升性能,一定要加上key,key是唯一标识,在更改前后,确认是不是同一个节点。
七、vue3中diff做了什么优化点?
这里是对vue2的diff的一个优化。
我们知道,diff算法大概有这四个过程:
- 同级比较,再比较子节点
- 先判断一方有子节点一方没有子节点的情况(如果新的children没有子节点,将旧的子节点移除)
- 比较都有子节点的情况(核心diff)
- 递归比较子节点
正常Diff两个树的时间复杂度是O(n^3),但实际情况下我们很少会进行跨层级的移动DOM,所以Vue将Diff进行了优化,从O(n^3) -> O(n),只有当新旧children都为多个子节点时才需要用核心的Diff算法进行同层级比较。
Vue2的核心Diff算法采用了双端比较的算法,同时从新旧children的两端开始进行比较,借助key值找到可复用的节点,再进行相关操作。相比React的Diff算法,同样情况下可以减少移动节点次数,减少不必要的性能损耗,更加的优雅。
那vue3的做了哪些优化?
Vue3.x借鉴了 ivi算法和 inferno算法
在创建VNode时就确定其类型,以及在mount/patch的过程中采用位运算来判断一个VNode的类型,在这个基础之上再配合核心的Diff算法,使得性能上较Vue2.x有了提升。(实际的实现可以结合Vue3.x源码看。)
该算法中还运用了动态规划的思想求解最长递归子序列。
vue3中引入的更新策略:编译期优化patchFlags、block等
聊到diff算法,曾经面试被问到vue和react的区别?
React的diff和Vue的diff算法的不同之处?
vue和react的diff算法都是进行同层次的比较,主要有以下两点不同:
- vue对比节点,如果节点元素类型相同,但是className不同,认为是不同类型的元素,会进行删除重建,但是react则会认为是同类型的节点,只会修改节点属性。
- vue的列表比对采用的是首尾指针法,而react采用的是从左到右依次比对的方式,当一个集合只是把最后一个节点移动到了第一个,react会把前面的节点依次移动,而vue只会把最后一个节点移动到最后一个,从这点上来说vue的对比方式更加高效。
最怕面试官突如其来的灵魂拷问。
更怕空气突然安静~

八、说一下虚拟Dom以及key属性的作用?
由于在浏览器中操作DOM是很昂贵的。频繁的操作DOM,会产生一定的性能问题。这就是虚拟Dom的产生原因。
VirtualDOM映射到真实DOM要经历VNode的create、diff、patch等阶段。
那key的作用是啥?
♂️ 「key的作用是尽可能的复用 DOM 元素。」
新旧 children 中的节点只有顺序是不同的时候,最佳的操作应该是通过移动元素的位置来达到更新的目的。
需要在新旧 children 的节点中保存映射关系,以便能够在旧 children 的节点中找到可复用的节点。key也就是children中节点的唯一标识。
面试官摸了摸胡子,顺便摸了摸我那八块腹肌,明天来报道。
哦,再说吧,我回家做饭了。

后记
如何设计一个虚拟DOM算法?
看似问得很浅,其实要回答的知识点很多,很深。
我们再来总结一下回答:
♂️我个人主要从五个方面回答
- 虚拟dom就是虚拟的dom对象,通过JavaScript 对象来模拟dom对象。(是什么)
- 因为在前端性能优化的一个秘诀就是尽可能少地操作DOM,不仅仅是DOM相对较慢,更因为频繁变动DOM会造成浏览器的回流或者重回,我们利用Diff算法尽可能地一次性将差异更新到DOM中,这样保证了DOM不会出现性能很差的情况。(为什么用)
- 给我设计的话,我会从三方面去考虑: 用 JavaScript 对象结构表示 DOM 树的结构;然后用这个树构建一个真正的 DOM 树,插到文档当中。 当状态变更的时候,重新构造一棵新的对象树。然后用新的树和旧的树进行比较,记录两棵树差异。 把2所记录的差异应用到步骤1所构建的真正的DOM树上,视图就更新了。此阶段会利用到Diff算法。因为挂载过程结束后,vue程序进入更新流程。如果某些响应式数据发生变化,将会引起组件重新render,此时就会生成新的vdom,和上一次的渲染结果diff就能得到变化的地方,从而转换为最小量的dom操作,高效更新视图。
- 我们刚刚说了,期间转换为真实的DOM会利用到Diff算法。
- Diff算法就是一种对比算法,主要是对比旧的虚拟DOM和新的虚拟DOM,找出发生更改的节点,并只更新这些更改点,而不更新未发生变化的节点,从而准确的更新DOM,减少操作真实DOM的次数,提高性能。
- Diff过程是一个递归过程,遵循深度优先、同层比较的策略
- 首先判断两个节点是否为相同同类节点,不同则删除重新创建
- 如果双方都是文本则更新文本内容
- 如果双方都是元素节点则递归更新子元素,同时更新元素属性 更新子节点时又分了几种情况:(diff算法核心:新节点孩子 VS 旧节点孩子) 新的子节点是文本,老的子节点是数组则清空,并设置文本; 新的子节点是文本,老的子节点是文本则直接更新文本; 新的子节点是数组,老的子节点是文本则清空文本,并创建新子节点数组中的子元素; 新的子节点是数组,老的子节点也是数组,那么比较两组子节点。
- 在vue3中diff也有做了一些优化点。 Vue2的核心Diff算法采用了双端比较的算法,同时从新旧children的两端开始进行比较,借助key值找到可复用的节点,再进行相关操作。相比React的Diff算法,同样情况下可以减少移动节点次数,减少不必要的性能损耗,更加的优雅。 Vue3.x借鉴了 ivi算法和 inferno算法 在创建VNode时就确定其类型,以及在mount/patch的过程中采用位运算来判断一个VNode的类型,在这个基础之上再配合核心的Diff算法,使得性能上较Vue2.x有了提升。
层层递进。由浅入深。
如果仔细看下来,其实发现虚拟DOM也不是很难理解,一些羞涩难懂的技术点,只要花点时间去理解,相信很快能攻破,也能明白在实际开发过程中,模板渲染成虚拟DOM后,通过diff算法去提升性能,背后的知识点懂了之后,开发过程中也会如翼添虎。






![[附源码]Python计算机毕业设计Django校园订餐系统](https://img-blog.csdnimg.cn/fb183291893647f988f0ab9c95bef7be.png)

![Matplotlib入门[04]——处理图像](https://img-blog.csdnimg.cn/1f9d779af5574b1897f69defdf703b97.png)
