一、开源项目简介
- 知道学习平台是一个基于 Java 开发的分布式在线教育系统
- 项目采用前后端分离的企业级微服务架构
- 引入组件化的思想实现高内聚低耦合,项目代码简洁注释丰富上手容易
- 注重代码规范,严格控制包依赖
- 可以帮助个人、企业或机构快速搭建一个在线学习平台,满足企业的在线教学、在线培训、企业内训等需求
二、开源协议
作者暂未使用国际主流开源许可协议
三、界面展示
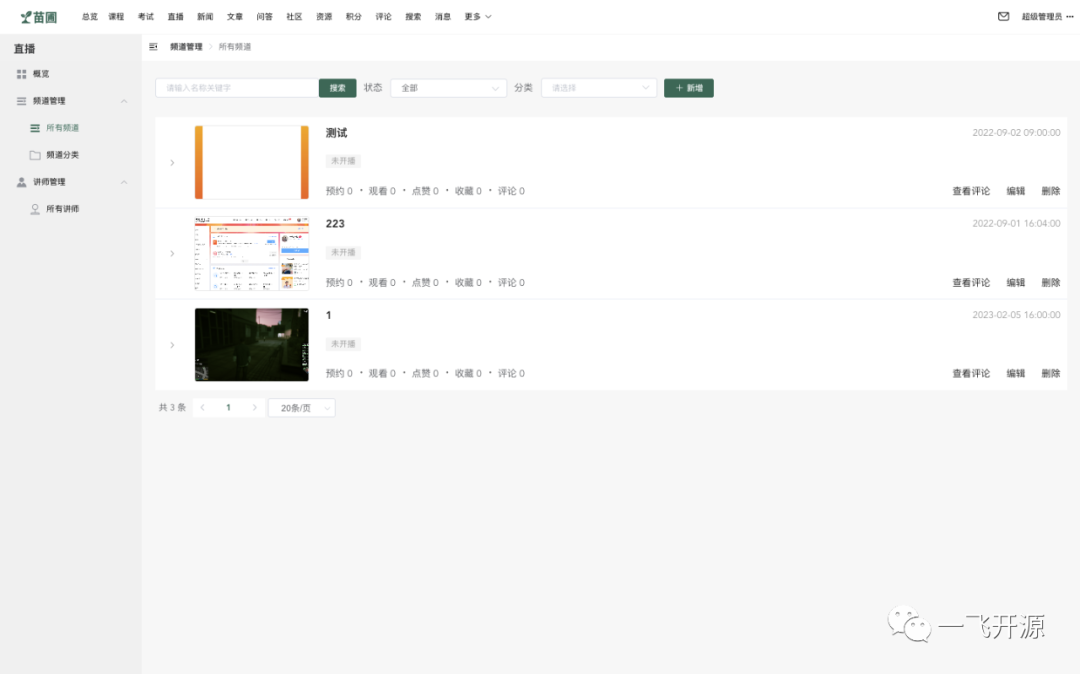
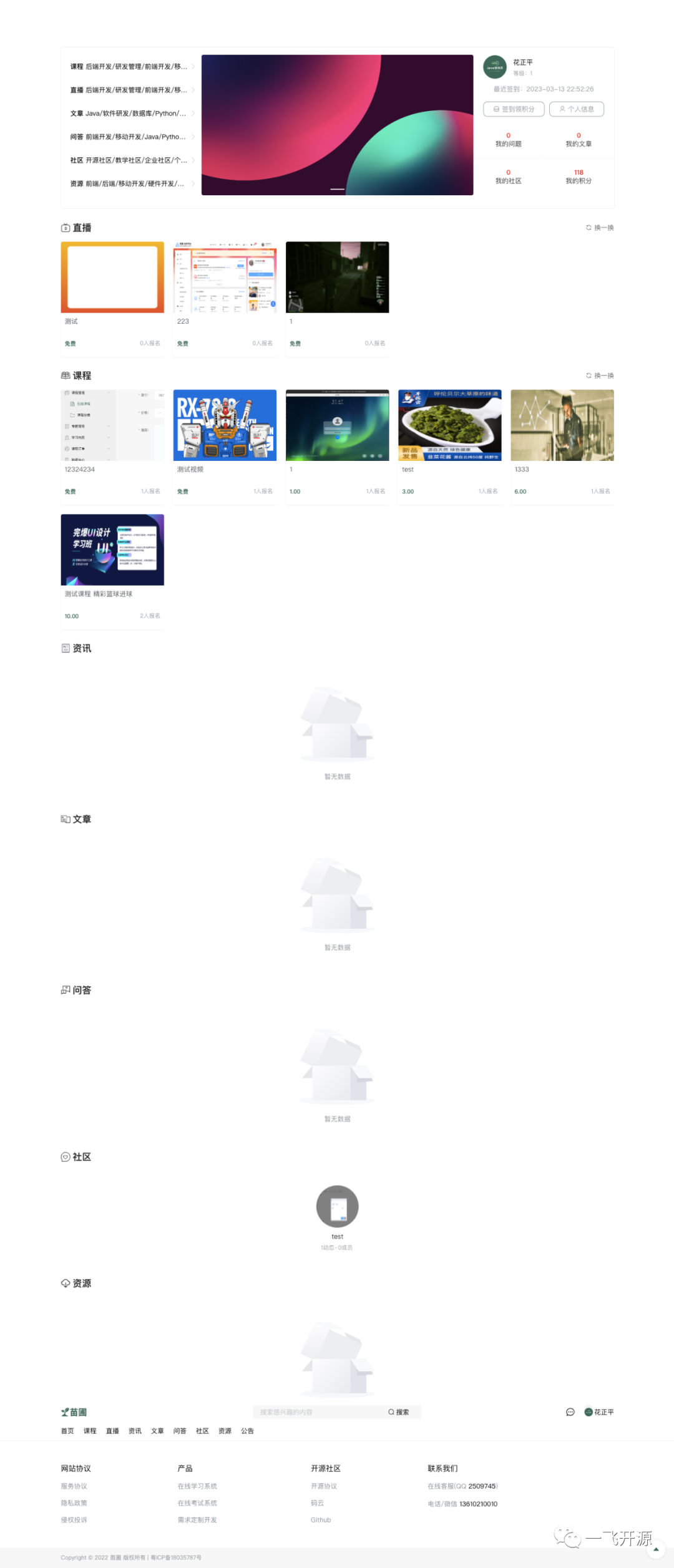
四、功能概述
方案一
企业培训管理平台
构建企业培训全周期服务闭环,为企业发展赋能,满足多样化的培训需求。
- 互动直播、在线点播
- 知识库学习、在线问答
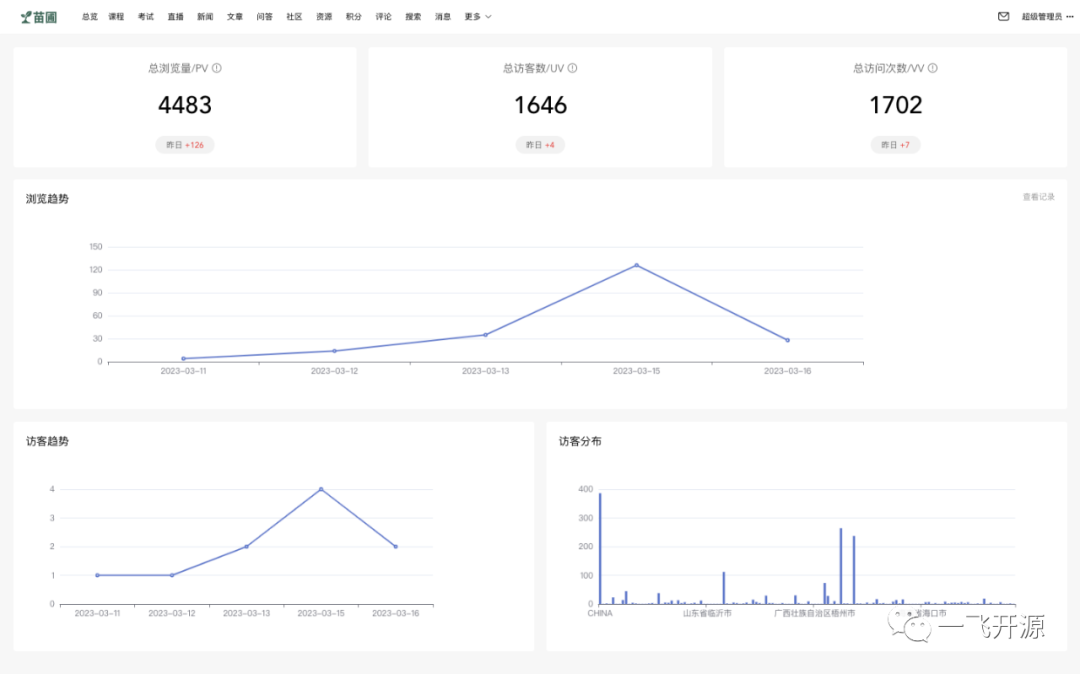
- 岗位培训、数据统计
- 公告、新闻资讯、社区博客

方案二
网络在线教育平台
网络在线教育系统是一套通用的教育培训平台,可应用于不同的行业进行教学培训。
- 互动直播、在线点播
- 智能评卷、在线考试、文库资源
- 新闻资讯、社区博客、在线问答
- 报表统计、学习分析

五、技术选型
技术框架
核心框架:SpringCloud 持久层框架:Mybatis-plus 日志管理:Log4j 项目管理框架: Maven API 接口框架: Swagger2 前端框架:Vue3
模块说明
cloud-learning-cecloud-learning-auth-service --权限认证服务 cloud-learning-behavior-service --行为服务 cloud-learning-gateway-service --网关服务 cloud-learning-learn-service --学习服务 cloud-learning-member-service --会员服务 cloud-learning-message-service --消息服务 cloud-learning-oss-service --对象存储服务 cloud-learning-setting-service --系统设置服务 cloud-learning-usercenter-service --用户中心服务
六、源码地址
https://download.csdn.net/download/weixin_37576193/87731374