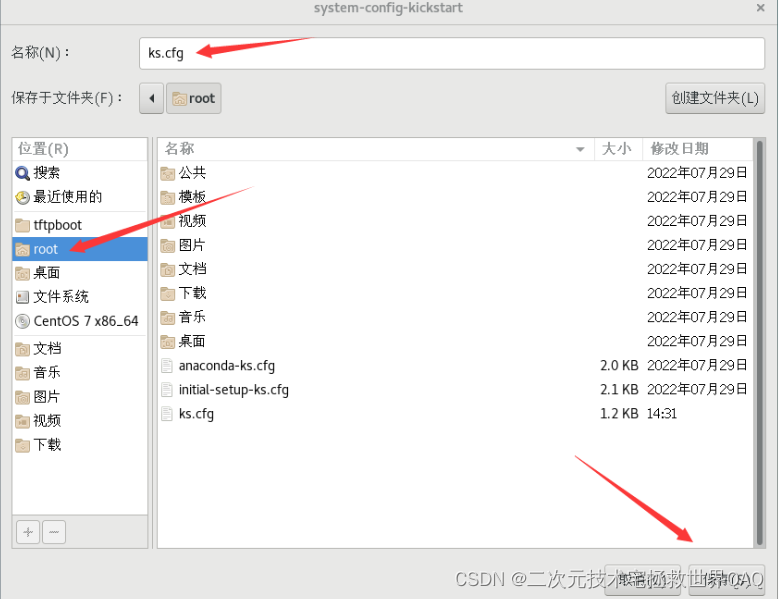
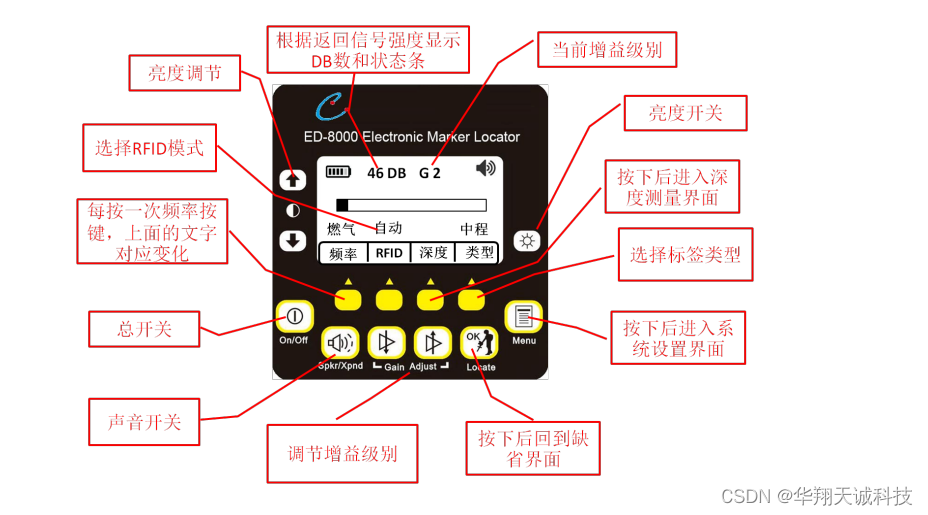
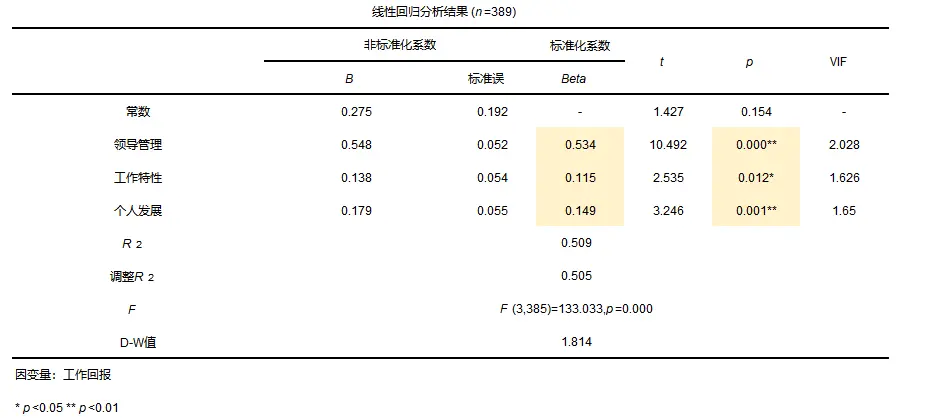
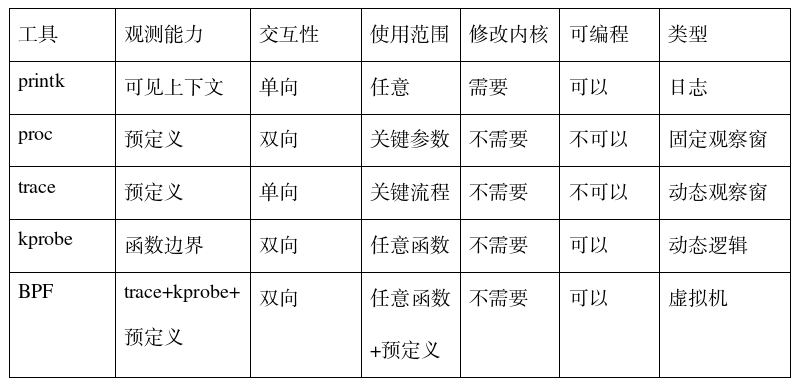
海龟库:
海龟绘图
“小海龟”turtle是Python语言中一个很流行的绘制图像的函数库,想象一个小乌龟,在一个横轴为x、纵轴为y的坐标系原点,(0,0)位置开始,它根据一组函数指令的控制,在这个平面坐标系中移动,从而在它爬行的路径上绘制了图形。
海龟绘图(Turtle Graphics)是python2.6版本中后引入的一个简单的绘图工具,出现在1966年的Logo计算机语言。
海龟绘图(turtle库)是python的内部模块,使用前导入即可 import turtle
知识教学:
请想象绘图区有一只机器海龟,起始位置在 x-y 平面的 (0, 0) 点。先执行 import turtle,再执行 turtle.forward(15),它将(在屏幕上)朝所面对的 x 轴正方向前进 15 像素,随着它的移动画出一条线段。再执行 turtle.right(25),它将原地右转 25 度。
程序代码:
效果演示: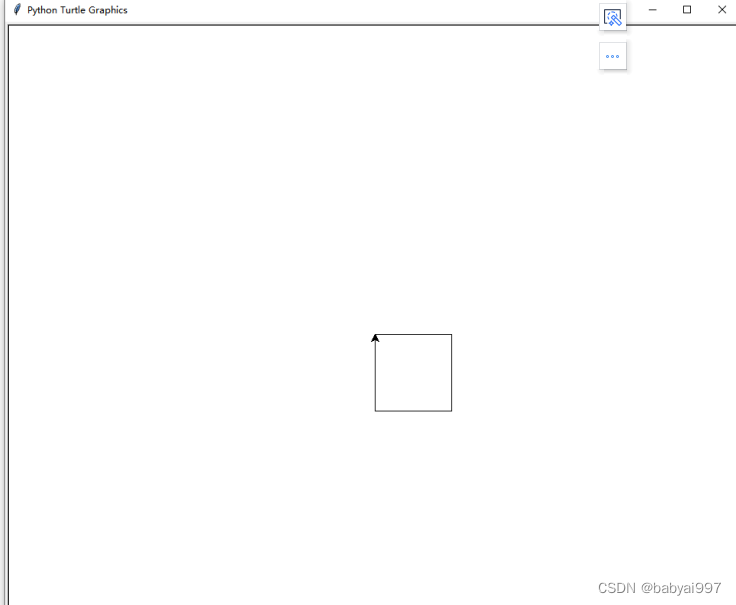
程序代码:

效果演示:
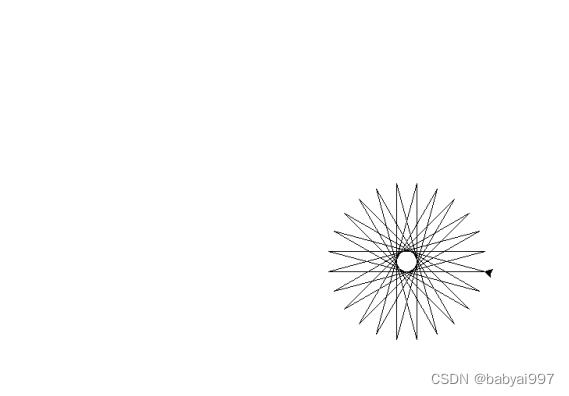
| 方法 | 参数 | 说明 |
|
| 画笔落下 | |
|
| 画笔抬起 | |
| turtle.forward(distance) | 前进:海龟前进 distance 指定的距离,方向为海龟的朝向 | |
| turtle.right(angle) | 右转:海龟右转 angle 个单位。 | |
| turtle.left(angle) | 左转:海龟左转 angle 个单位。 | |
| turtle.home() | 返回原点:海龟移至初始坐标 (0,0),并设置朝向为初始方向 。 |
要求:画出你的名字。