源于
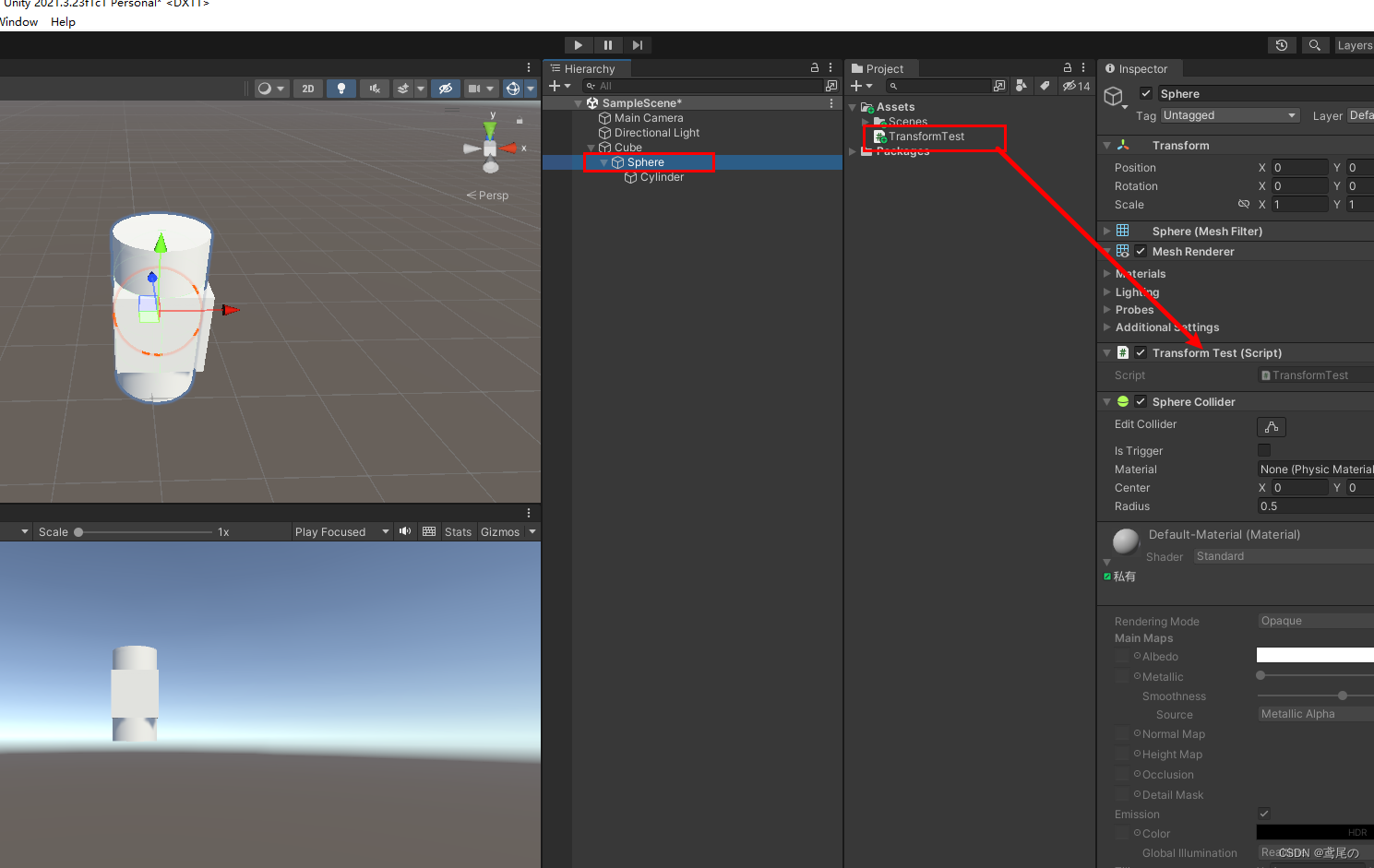
1.桨叶的平面形状和主要参数
由于其设计制造比较简单,早期直升机大多采用矩形桨叶,缺点是在高速气流中,无法抑制桨尖涡,会消耗向下的诱导速度,降低旋翼的拉力。现代多采用梯形桨叶。

桨尖后掠能够降低桨尖涡

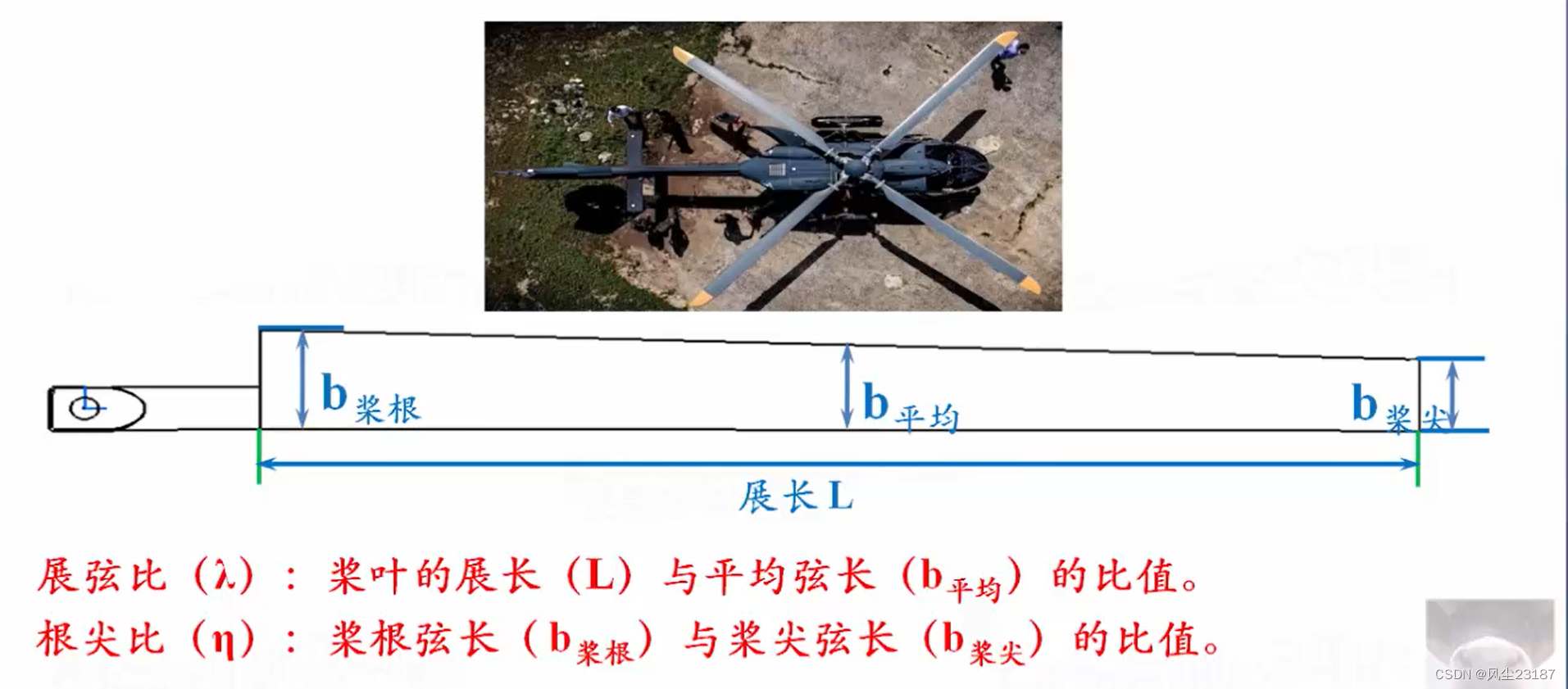
图片上方称之为前缘,下方称为后缘。
展弦比:
λ = L b a v g \lambda = \frac{L}{b_{avg}} λ=bavgL
根尖比:
η = b r o o t b m i n \eta = \frac{b_{root}}{b_{min}} η=bminbroot
2. 桨叶的截面形状和主要参数
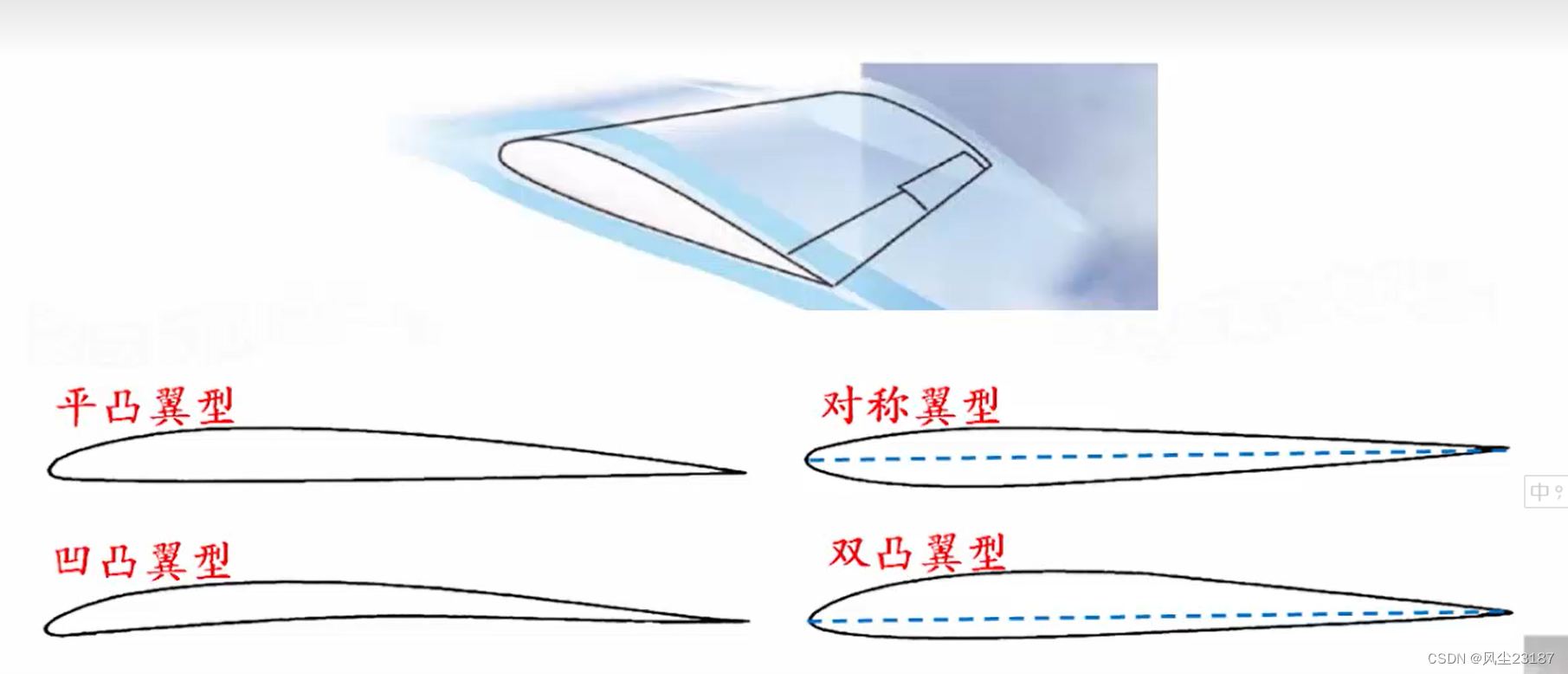
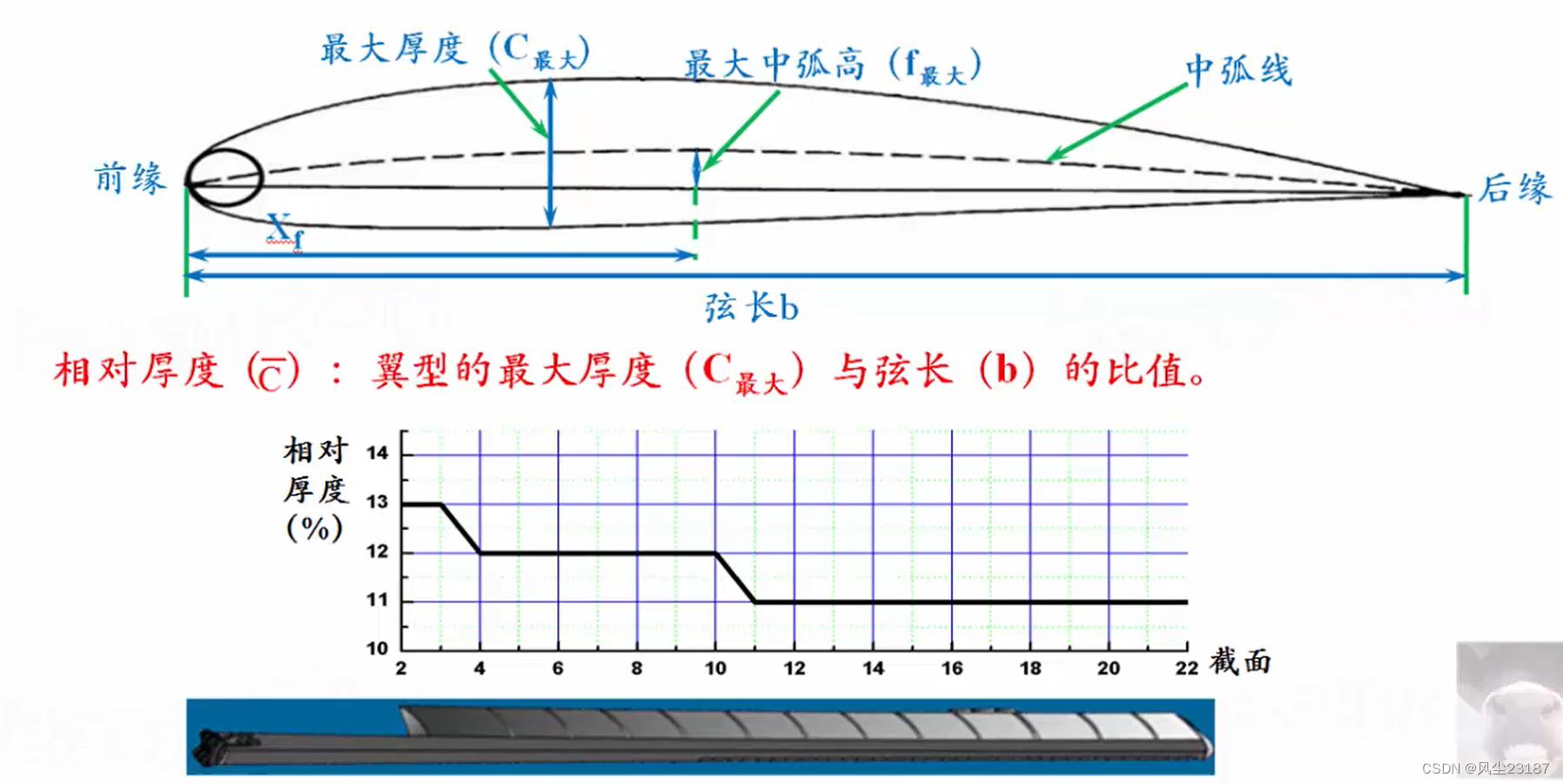
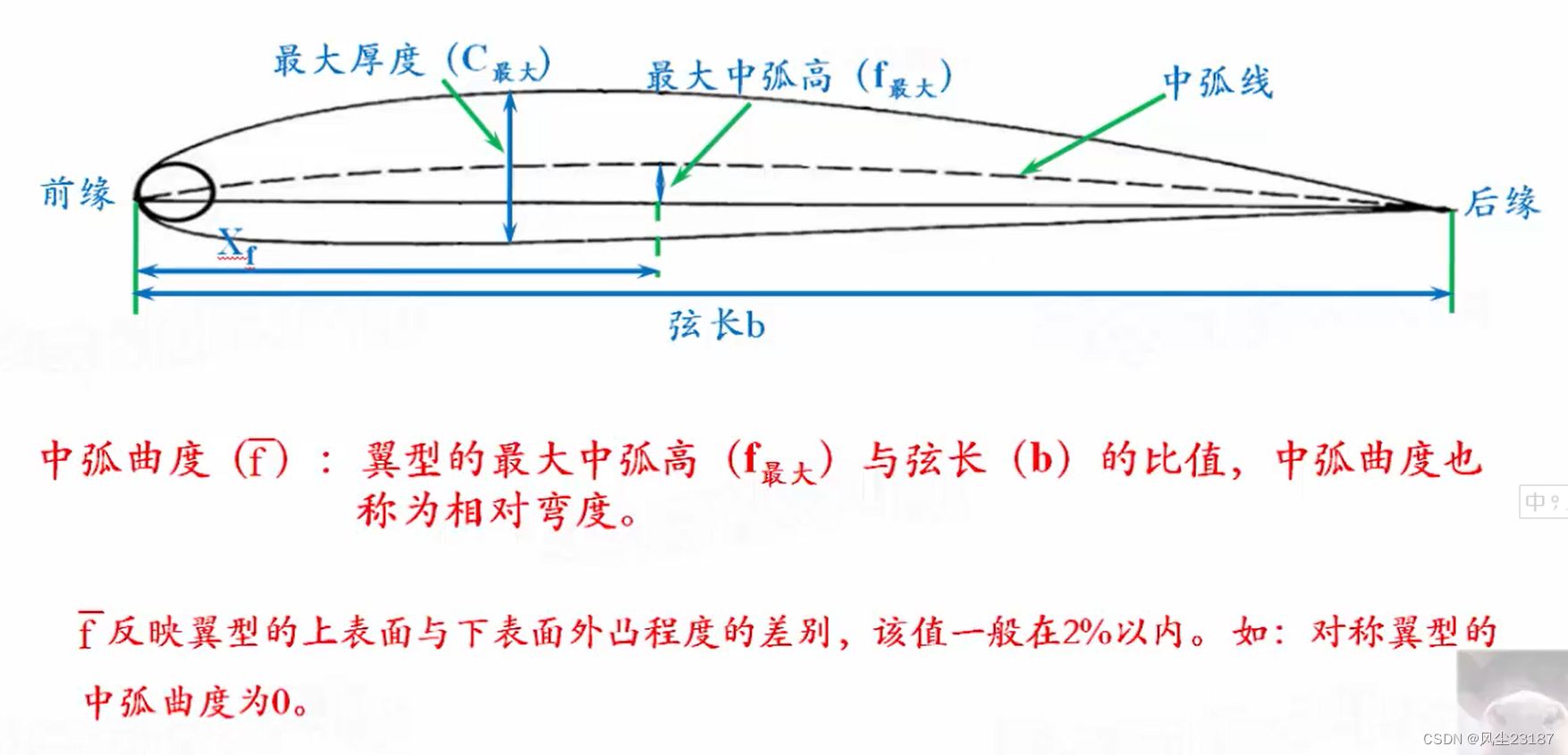
命名规则:

3.桨叶的工作状态参数
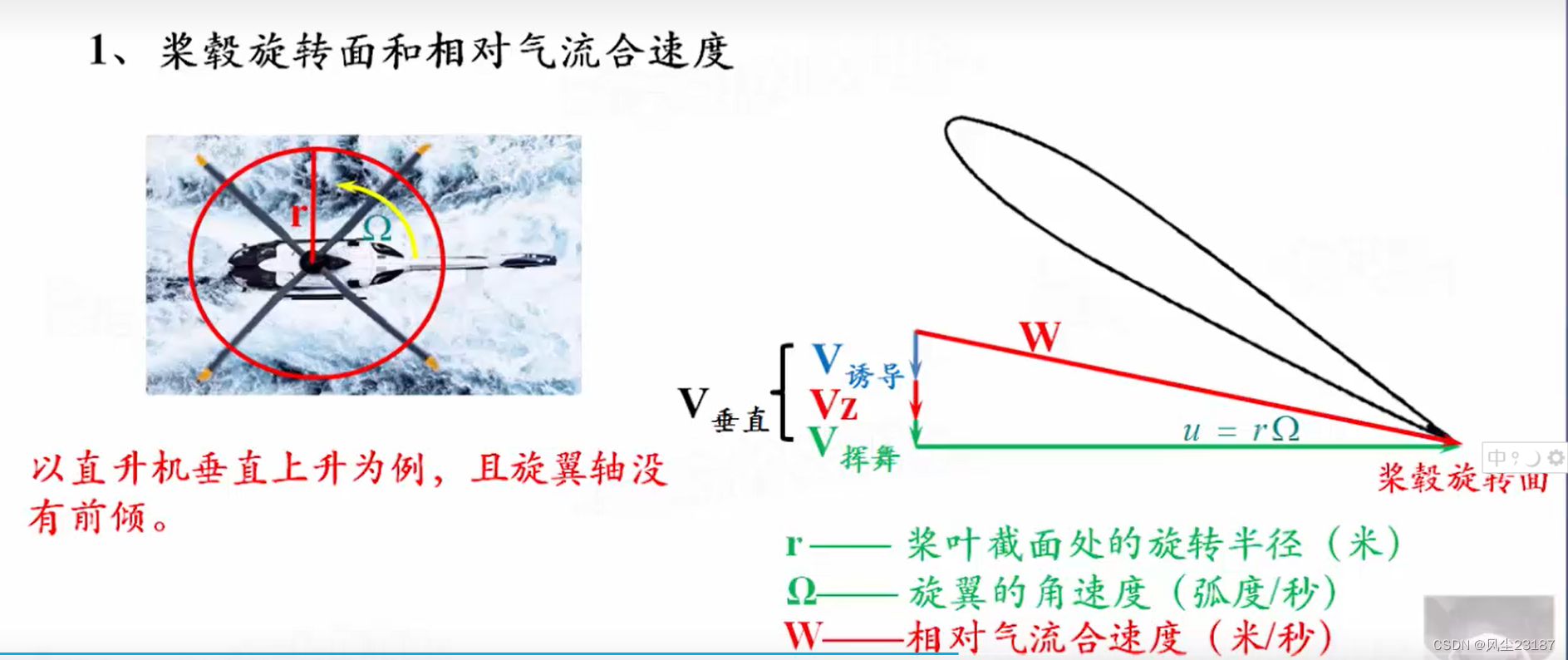
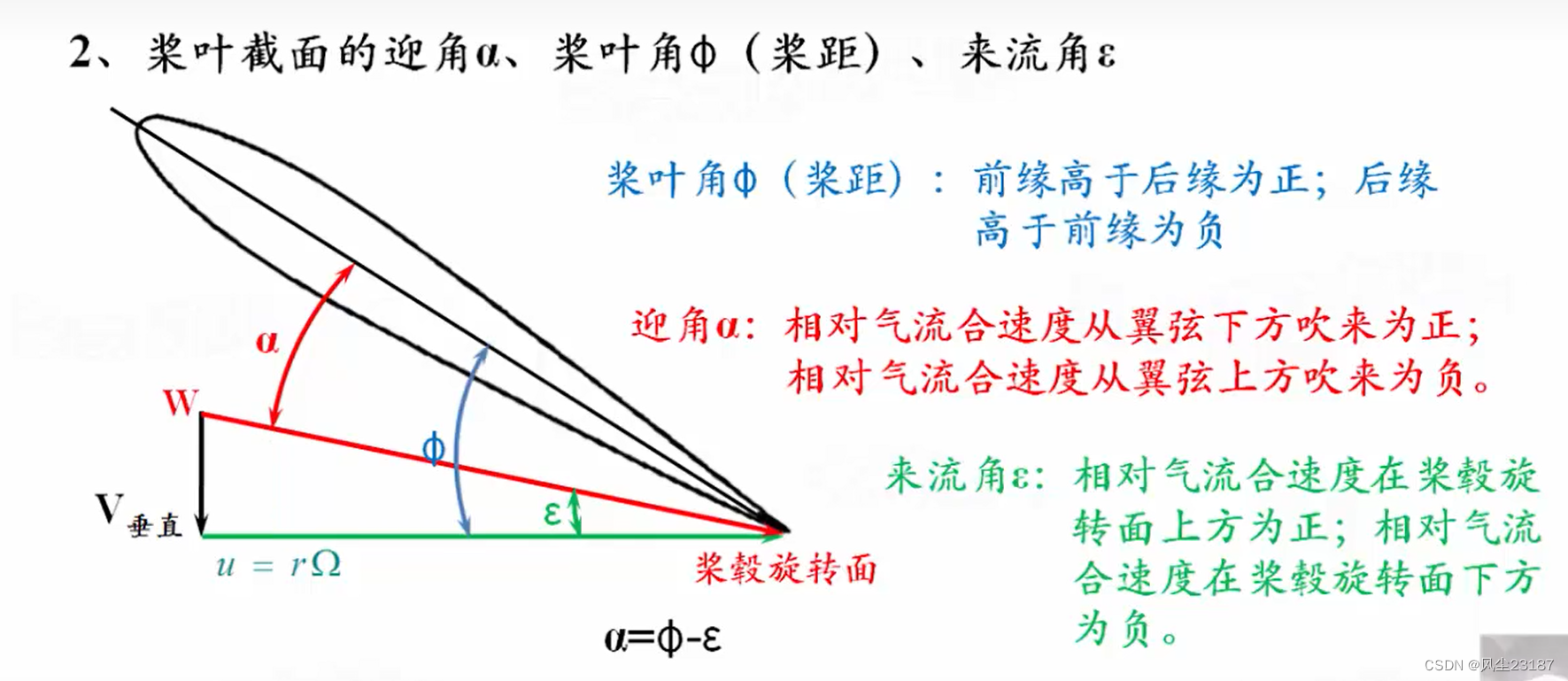
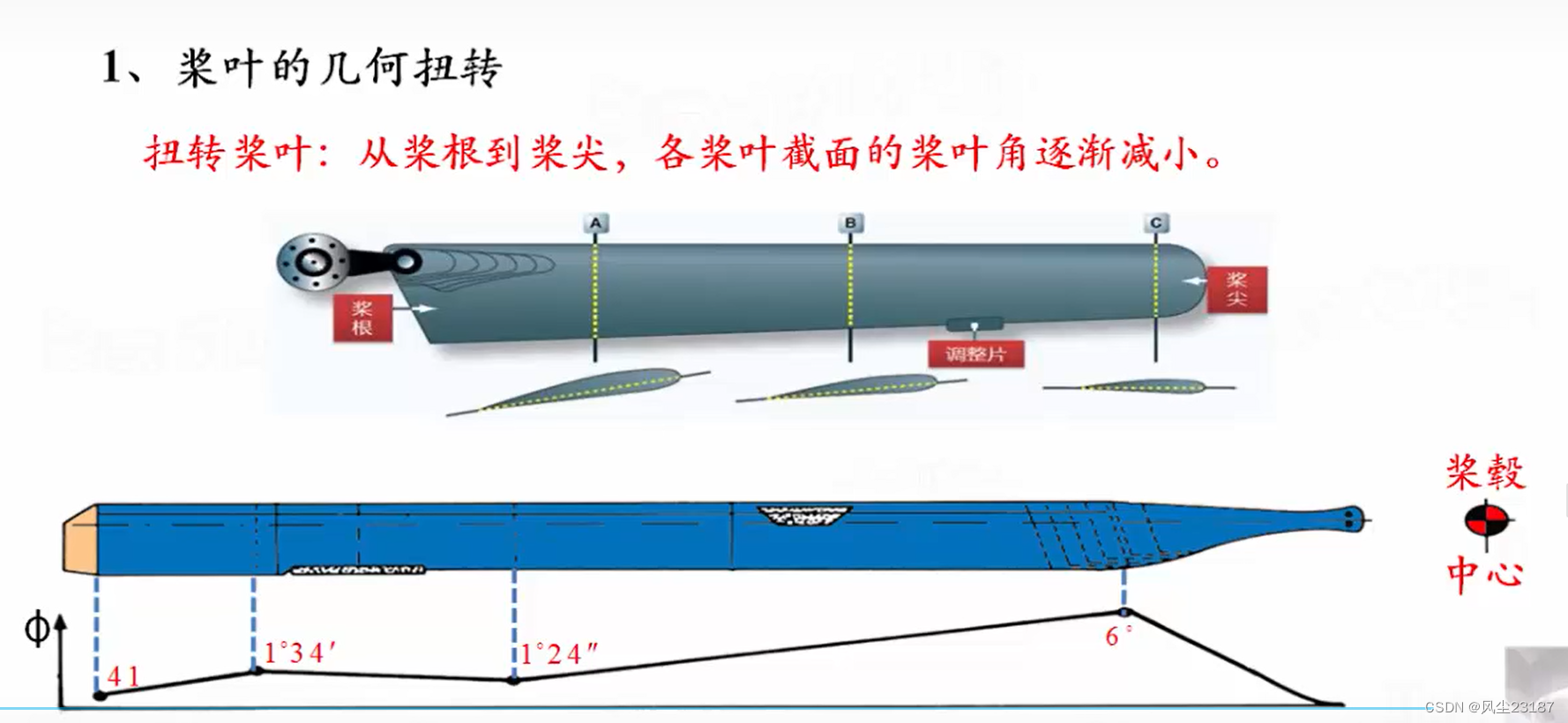
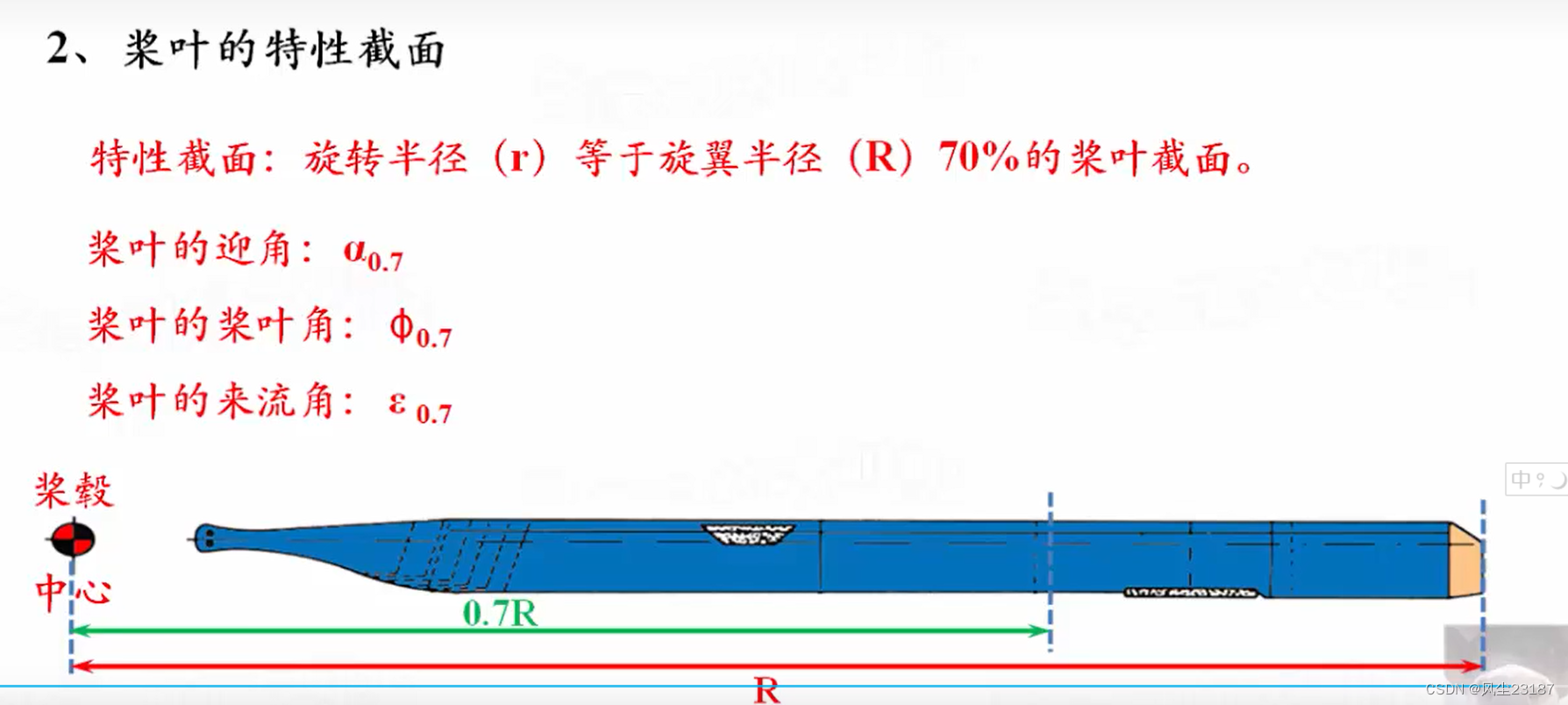
4.桨叶的几何扭转与特性截面