多少分及格?
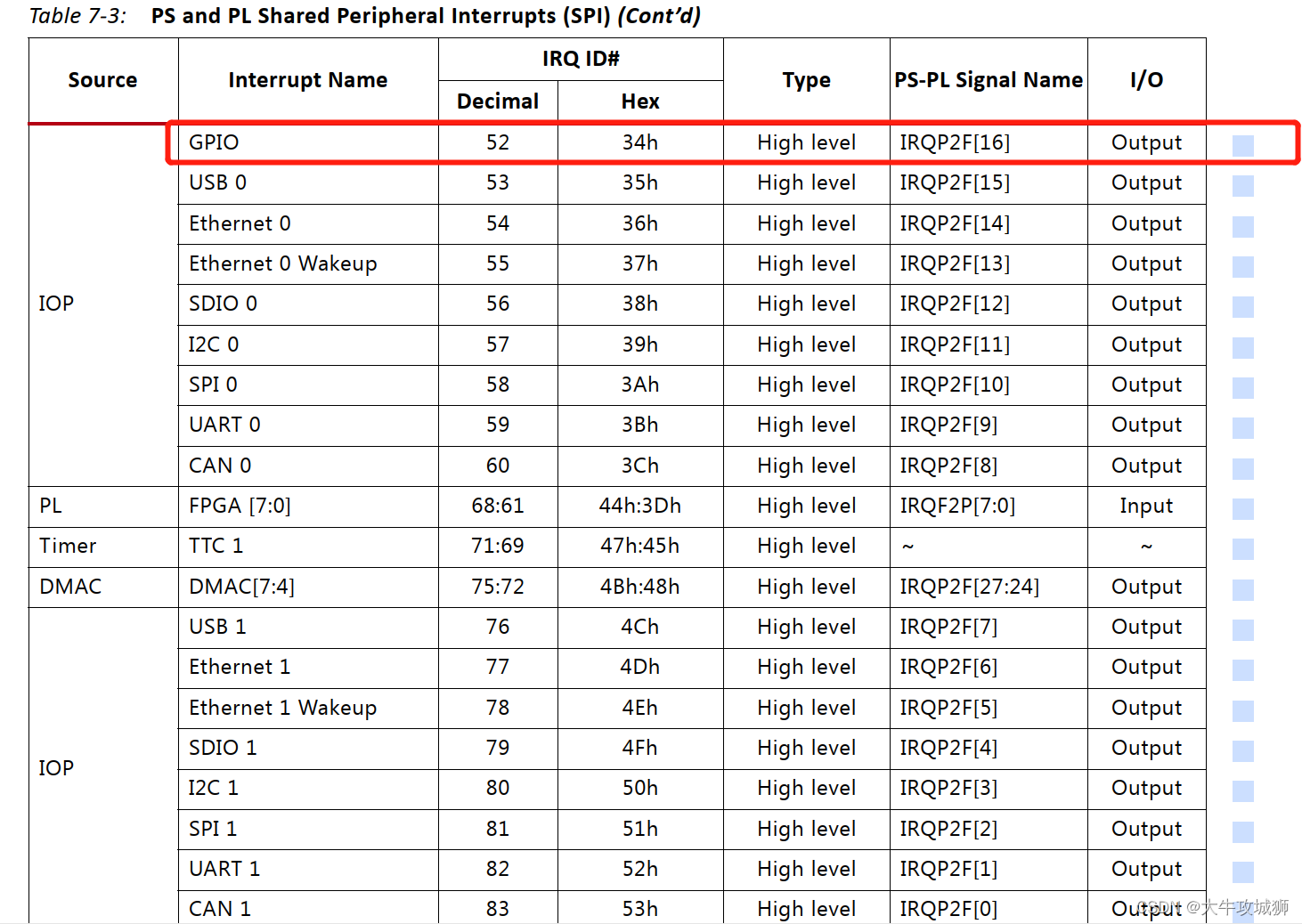
2023年,PMP考试是180道单项选择题,多少分通过呢?
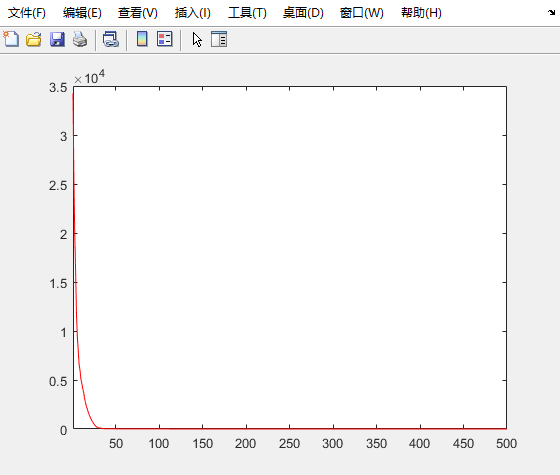
180题里面,有5道题是不计分的(很多资料说是25题,是错误的,过时信息,最新的是5题不计分),但是这5道题是随机抽取的,就是不论你答的对还错,都不算入总分。
所以PMP通过分数在106分到111分之间,考111分是最保险的,正确率在61%。PMP考试最后的结果就是通过或不通过,没有分数。
PMP认证有级别吗?
1、PMP认证是不分等级的,最终的成绩只有两种:Pass(通过)和通知下一次的考试安排,无论以什么分数通过了考试,PMP证书都是统一的样式。
2、PMP认证成绩一般以A\T\B\N来展示,PMP考试内容分为3大模块,考生最终得到的成绩就是每个模块所获得的等级。模块等级:Above Target(高于目标)、Target(达到目标)、Below Target(低于目标)、Needs Improvement(有待提高),最好的成绩为3A,即都是Above Target(高于目标)。
3、PMP认证并不存在等级的划分,只要通过考试,即可拿到PMP证书,即表示考生的项目管理水平达到了国际的标准,有能力从事项目管理方面的工作。PMI美国项目管理协会名下的证书分很多种,PMP本身不再区分级别,但项目管理分不同等级,从高到低依次是:组织级项目管理OPM3、项目组合管理PfMP、项目集管理PgMP、项目管理PMP、助理项目管理CAPM;另外,还包括一些专业方向的证书,比如项目风险管理PMI-RMP、进度管理PMI-SP、商业分析师PMI-PBA、敏捷项目管理PMI-ACP。
成绩什么时候出?
PMP考试结束后大概6-8周左右会出成绩,成绩公布时间不确定,具体时间要以官方发布的通知为准。PMI协会在成绩结果出来后会发送邮件告知考生,到时候考生可以登录“PMI网站”个人账号进行成绩查询。
纸质证书何时领
PMP 纸质版证书,首次申请证书将会在考后12个月左右到达。届时,基金会会通知学员领取证,也可关注短信或邮件通知,注意查收即可!
续证问题
PDU 是英文 Professional Development Units 的缩写,中文译为:专业发展单位。PDU 是一个考核单位,用来量化认证人士所参与的学习和专业服务活动。
通过考试的项目管理人士,每3年需续证一次,续证需60个 PDU 积分和150美金费用,以保证证书的有效性。