集合分为两大类:List Set
1.Collection是单例集合的顶层接口,所有方法被List和Set集合共享
2.常见成员方法:
Add clear remove contains isEmpty size
LIst:有索引 有序 可重复
set:无索引 无序 不可重复
Collection的遍历方式
迭代器遍历
Iterator<String> it = coll.iterator();//3.利用循环不断的去获取集合中的每一个元素while (it.hasNext()){//4.next方法的两件事情:获取元素并移动指针String str = it.next();System.out.println(str);}细节注意
1.报错NoSuchElementException 移动到最后一位还移动就会报错
2.迭代器遍历完毕,指针不会复位(需要复位 重新获取迭代去对象)
3.循环中只能用一次next方法
4.迭代器遍历时,不能用集合的方法进行增加或者删除
5.迭代器在遍历集合的时候是不依赖索引的
增强for遍历
增强for的底层就是迭代器,为了简化迭代器的代码书写的
它是jdk5之后出现的,其内部原理就是一个iterator迭代器
所有的单例集合和数组才能用增强for进行遍历
格式
for (String s : coll) {System.out.println();}细节
修改增强for变量,不会改变集合中原本的数据
Lambda表达式遍历
得益于jdk8开始的新技术Lambda表达式、提供了一种更简单、更直接的遍历集合的方式
格式直接遍历
coll.forEach(s -> System.out.println(s));List中常见的方法和五种遍历方式
List得特点:
1.有序:存和取得元素一直
2.有索引:可以通过索引操作元素
3.可重复:存储的元素可以重复
4.Collection的方法List都继承了
| 方法名称 | 说明 |
| void add(int index,E element) | 在此集合中的指定位置插入指定的元素 |
| E remove(index) | 删除指定位置的元素i |
| E Set(int index,e element) | 修改索引处的元素,返回修改元素 |
| E Get(int index) | 返回指定索引处的元素 |
List集合的遍历方式
1.迭代器遍历
2.列表迭代器遍历 可以添加元素
3.增强for遍历
4Lambda表达式遍历
5普通for循环(因为List中集合存在集合)想要操作索引
package mylist;import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.ListIterator;public class A02_collectionDemo {public static void main(String[] args) {/*1.迭代器遍历2.列表迭代器遍历3.增强for遍历4Lambda表达式遍历5普通for循环(因为List中集合存在集合)*///创建集合并添加元素List<String> list=new ArrayList<>();list.add("aaa");list.add("bbb");list.add("ccc");list.add("ddd");list.add("eee");/*Iterator<String> it = list.iterator();while (it.hasNext()){String s = it.next();System.out.println(s);}*///增强forfor (String s : list) {System.out.println(s);}System.out.println("===================");list.forEach((String s)->{System.out.println(s);});//普通for方法/*for (int i = 0; i < list.size(); i++) {String s=list.get(i);System.out.println(s);}*/System.out.println("===================");//列表迭代器//在遍历的过程中,可以添加元素ListIterator<String> it=list.listIterator();while (it.hasNext()){String next = it.next();System.out.println(next);}}
}
数据结构
1.栈 :后进先出,先进后出
2.队列:先进先出,后进后出
3.数组:查询快 删除低 添加效率低
4.链表:查询慢 无论查找都是从头开始 增删快(相对数组比)
5.二叉树:
6.二叉查找树
7.平衡二叉树
8.红黑树
ArrayList集合底层原理
1.ArrayList底层是数组结构的
2.利用空参创建的集合,在底层创建一个默认长度为0的数组(elementDdata)
3.添加第一个元素时,底层会创建一个新的长度为10的数组
4.size 元素个数 下次存入的位置
5.存满时,会扩容1.5倍
6.如果一次添加多个元素,1.5倍都不能放下,则新创建数组长度以实际为准
LinkedList集合
1.底层数据结构是双链表,查询慢,增删快,但是如果操作的是首尾元素,速度也是极快的
2.有特有的API
| 特有方法 | 说明 |
| addFirst | 在该列开头插入指定的元素 |
| addLast | 将指定的元素追加到此列表的末尾 |
| getFirst | 返回此列表的第一个元素 |
| getLast | 返回此列表中的最后一个元素 |
| removeFirst | 从列表中删除并返回第一个元素 |
| removeLast | 从列表中删除并返回最后一个元素 |
ArrayList和LinkedList的区别如下:
1. ArrayList的实现是基于数组,LinkedList的实现是基于双向链表。
2. 对于随机访问,ArrayList优于LinkedList,ArrayList可以根据下标以O(1)时间复杂度对元素进行随机访问。而LinkedList的每一个元素都依靠地址指针和它后一个元素连接在一起,在这种情况下,查找某个元素的时间复杂度是O(n)
3. 对于插入和删除操作,LinkedList优于ArrayList,因为当元素被添加到LinkedList任意位置的时候,不需要像ArrayList那样重新计算大小或者是更新索引。
4. LinkedList比ArrayList更占内存,因为LinkedList的节点除了存储数据,还存储了两个引用,一个指向前一个元素,一个指向后一个元素。
集合进阶
泛型
是Jdk5中引入的特性,可以在编译阶段约束操作的数据类型,并进行检查
格式:<数据类型>
注意:泛型只能支持引用数据类型。
好处:统一数据类型
把运行时期的问题提到了编译期间 避免了强制类型转换可能出现的异常,因为在编译阶段类型就能确定下来
Java中的泛型是伪泛型
泛型细节
泛型中不能写基本数据类型
指定泛型的具体类型后,传入数据时,可以传入该类型或者子类类型
如果不写泛型,类型默认是Object
泛型可以在
泛型类
当一个类中,,某个变量的数据类型不确定时,就可以定义带有泛型的类
public class ArrayList<E>{ }
public class MyArrayList<E> {Object[] obj=new Object[10];int size;public boolean add(E e){obj[size] = e;size++;return true;}
}
泛型方法
方法中形参类型不确定时
方案1:使用类名后面定义的泛型 所有方法都能用
方案2:在方法申明上定义自己的泛型
格式 public <T> void show(){}
泛型接口
如何使用一个带泛型的接口
方式1:实现类给出的具体类型
方式2:实现类延续泛型,创建对象时再确定
泛型的通配符和综合练习
数据结构—>树
Set系列集合
:添加的元素是无序,不重复,无索引 不能使用普通for循环遍历
Set实现类
HashSet:无序、不重复、无索引LinkedHashSet:有序、不重复,无索引
TreeSet:可排序、不重复、无索引
利用Set系列的集合 添加字符串 并使用多种方式进行遍历
1.迭代器
2.增强for
3.Lambda表达式
public static void main(String[] args) {//创建一个Set集合HashSet<String> s = new HashSet<>();//2.添加元素boolean aa = s.add("aa");boolean aa1 = s.add("aa");System.out.println(aa);//trueSystem.out.println(aa1);//falseSystem.out.println(s);//aa}迭代器遍历Set
s.add("zhansan");s.add("wangwu");s.add("lisi");s.add("laoqi");Iterator<String> in = s.iterator();while (in.hasNext()){String next = in.next();System.out.println(next);}//增强for循环for (String s1 : s) {System.out.println(s1);}//lamdba表达式s.forEach((String str)-> System.out.println(str));}Hash底层原理
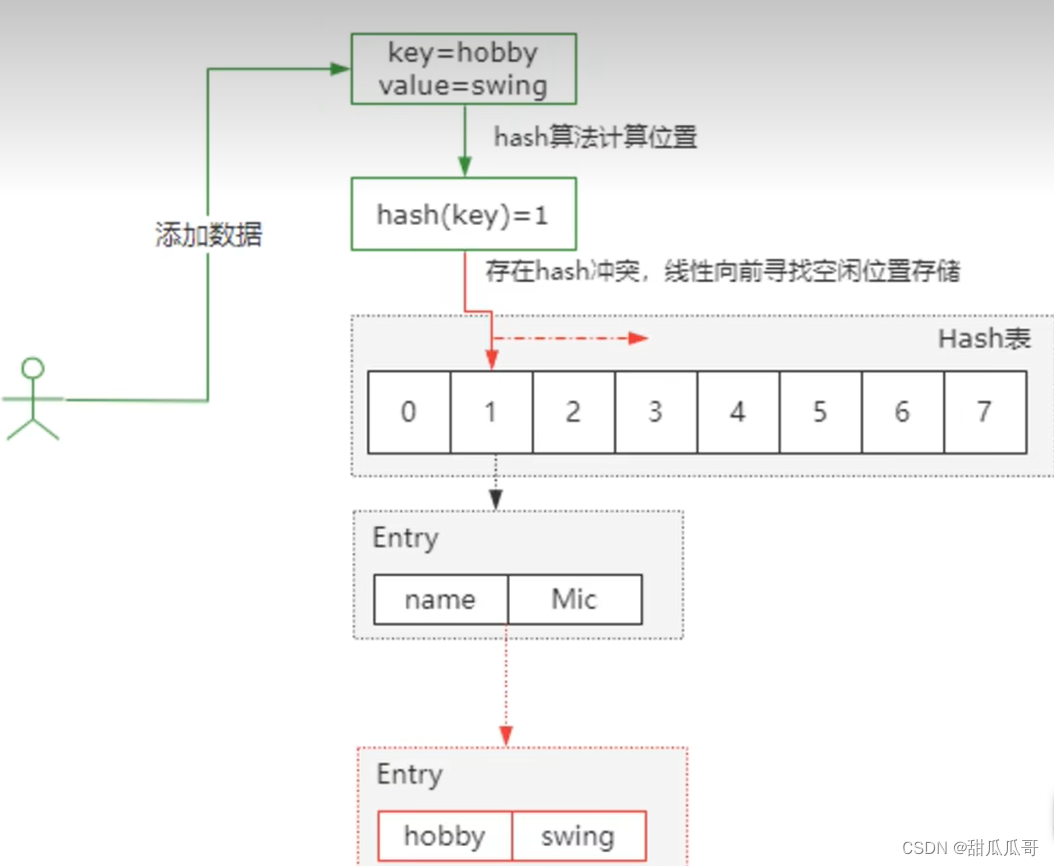
HashSet集合底层采取哈希表存储数据
哈希表是一种对于增删查改数据性能都比较好的结构
哈希表组成:
JDK8之前:数组+链表
JDK8开始:数组+链表+红黑树
JDK8以后,当链表长度超过8,而且长度大于等于64时,自动转换成红黑树
如果集合中存储的是自定义对象,必须要重写hashCode和equals方法
哈希值:
- 根据hashCode方法计算出来的int类型的整数
- 该方法定义在Object类中,所有对象都可以调用,默认使用的地址值进行计算
- 一般情况下,会重写hashCode方法,利用对象内部的属性值计算哈希值
对象的哈希值特点
- 如果没有重写hashCode方法,不同对象计算出来的哈希值是不同的
- 如果重写了hashCode方法,不同的对象只要属性值相同,计算出来的哈希值是一样的
- 小部分情况下 不同的属性值或者不同的地址计算出来的哈希值也有可能一样 哈希碰撞
HashSet
1.hashset为什么存和取的顺序不一样?
2.hashSet为什么没有索引?
3.HashSet是利用什么机制保证数据去重的 HashCode equals
4.HashSet集合的底层数据结构是什么样的?
5.HashSet添加元素过程
LinkedHashSet
1.有序、无重复、无索引
2.这里有序是指保证数据存储和取出的元素顺序一致
3.原理:底层数据结构依然是哈希表,只是每一个元素又额外的多了一个双链表的机制纪录存储的顺序
4.如果要求去重且存取有序,才能使用LinkedHashSet