摘要:本文整理自阿里巴巴高级技术专家、Apache Flink PMC 贺小令,在 Flink Forward Asia 2022 生产实践专场的分享。本篇内容主要分为三个部分:
1. Flink SQL Insight
2. Best Practices
3. Future Works
Tips:点击「阅读原文」查看原文视频&演讲 ppt
01
Flink SQL Insight
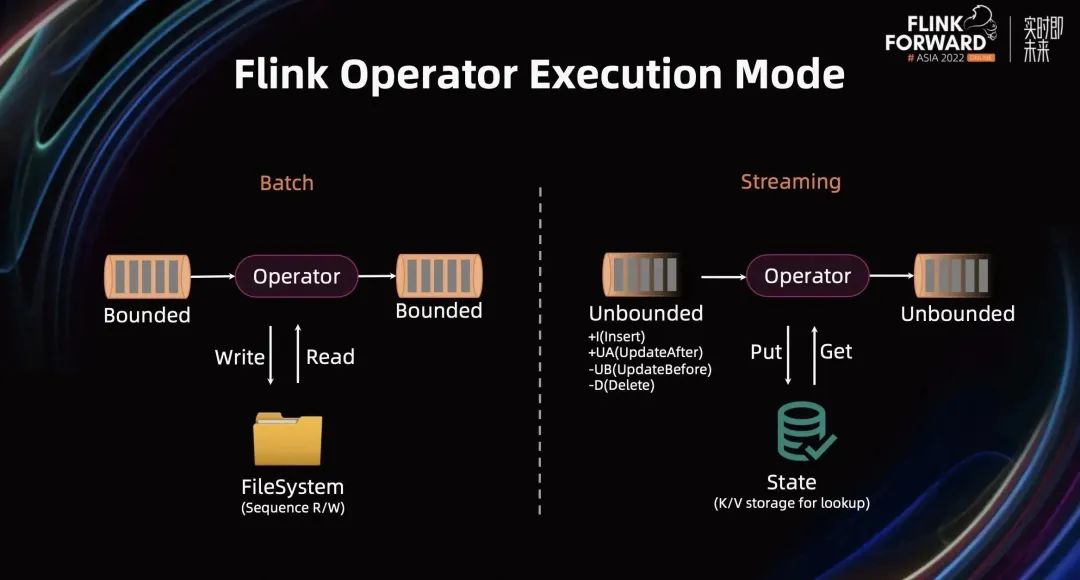
Flink 作为流批一体计算引擎,给大家提供了统一的 API,统一的算子描述,以及统一的调度。但 Flink 算子的底层仍有一些细微的差别。
对于一个批算子而言,它的输入是一个有限数据集。批算子会基于完整数据集进行计算,计算过程中如果内存装不下,数据会 Spill 到磁盘。
对于流算子而言,它的输入是一个无限数据集。与批算子不同,流算子不能在收集到所有输入数据之后才开始处理,也不可能将这些数据存到磁盘上。所以流算子的处理是一条一条的(也可能会按一小批进行计算)。
当流算子接收到上游的一条数据后,对于 Stateful 算子会从 State 里读取之前的计算结果,然后结合当前数据进行计算,并将计算结果存储到 State 里。因此 State 优化是流计算里非常重要的一部分。
批处理里仅有 Append 消息,而流处理中,不仅有 Append 消息,还有 UpdateBefore、UpdateAfter 和 Delete 消息,这些消息都是历史数据的订正。在算子的计算逻辑里,如果不能很好的处理订正消息,会导致下游数据膨胀,引发新的问题。
如何使一个作业运行更快?可以总结为 6 点:减少重复计算、减少无效数据计算、解决数据请求问题、提高计算吞吐、减少 State 访问、减少 State 的大小。

除了最后两个是针对流处理的,其余都是各个通用计算引擎都需要面对的。
接下来,通过剖析一个 Flink SQL 如何变成一个的 Flink 作业的过程,来介绍作业变得更优的手段。
Flink 引擎接收到一个 SQL 文本后,通过 SqlParser 将其解析成 SqlNode。通过查询 Catalog 中的元数据信息,对 SqlNode 中的表、字段、类型、udf 等进行校验,校验通过后会转换为 LogicalPlan,通过 Optimizer 优化后转换为 ExecPlan。ExecPlan 是 SQL 层的最终执行计划,通过 CodeGen 技术将执行计划翻译成可执行算子,用 Transformation 来描述,最后转换为 JobGraph 并提交到 Flink 集群上执行。
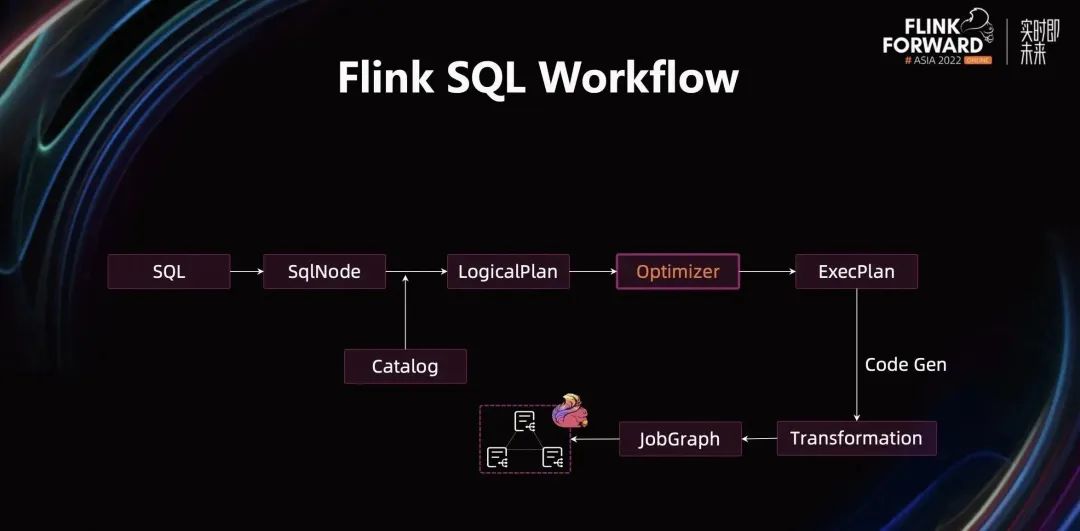
如何让 SQL 作业执行更快?Optimizer 在此发挥了重要作用。它将 SQL 语义等价的 LogicalPlan 转换为可高效执行的 ExecPlan,而 ExecPlan 到 JobGraph 转换过程都是确定的。
下图展示了优化器内部的细节。一个 Flink 作业通常包含多个 Insert 语句,当多个 Insert 语句翻译成 Logical Plan,会形成一个 DAG,我们称该优化器为 DAG 优化器。
Optimizer 的输入包括 5 部分:LogicalPlan、Flink 配置、约束信息(例如 PK 信息),统计信息、用户在 SQL 中提供的 Hints。
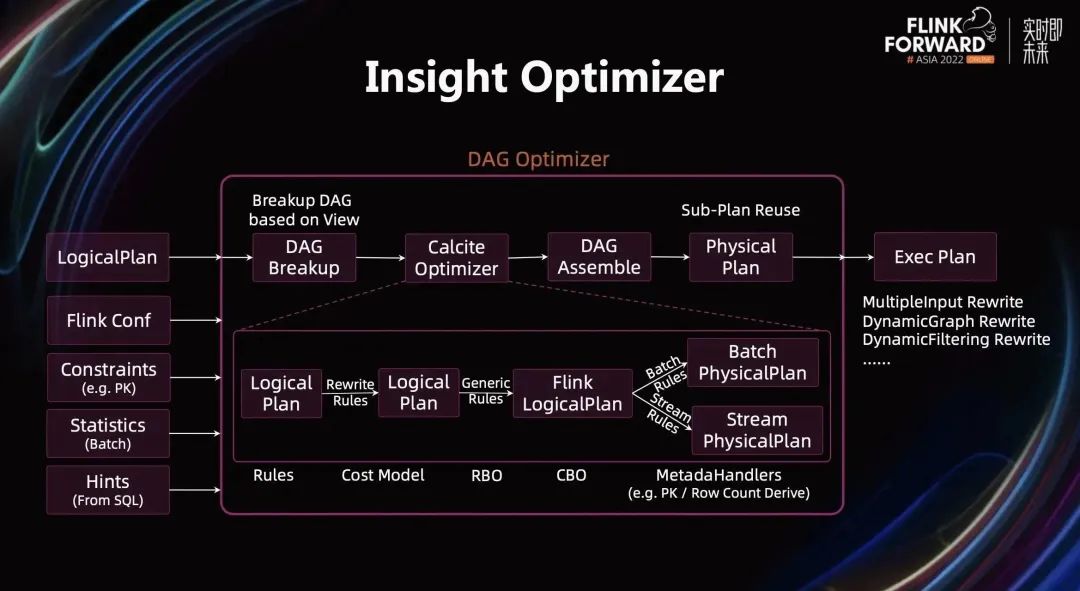
具体的优化过程包括:首先需要将 DAG 基于 View 进行分解,该做法是为了尽可能保证执行计划可复用。分解完后会得到一个个独立的 Tree,从叶子节点向根节点依次将这个 Tree 交给 Calcite 的 Optimizer 进行优化。然后将优化完的结果重新组装为 DAG,形成 PhysicalPlan 的 DAG,并使用子图复用技术继续改写 PhysicalPlan,进一步消除重复计算。最后将 PhysicalPlan 转换为 ExecPlan。基于 Exec DAG,可以做更多的优化:如 MultipleInput Rewrite,减少网络 Shuffle 带来的开销;DynamicFiltering Rewrite,减少无效数据的读取和计算等。
Calcite Optimizer 是经典的数据库中的关系代数优化,有基于规则的优化——RBO,基于代价模型的优化——CBO,同时还定义了大量的优化规则,大量的 Meta 信息的推导(如 PrimaryKey推导、RowCount 的推导),来帮助优化器获得最优的执行计划。
在 Calcite Optimizer 里,结合了经典的优化思路:首先是对 LogicalPlan 进行一些确定性的改写,例如 SubQuery 改写、解关联、常量折叠等。然后做一些通用的改写,例如各种 push down,形成 FlinkLogicalPlan。这部分优化是流批通用的。然后流和批根据各自底层的实现,进行特定的优化,例如批上会根据 Cost 选择不同的 Join 算法,流上会根据配置决定是否将 Retract 处理转换为 Upsert 处理,是否开启 Local/Global 解决数据热点问题等。
DAG 优化器解决了大量前面提到的各种问题,Flink SQL 是否足够 Fast 起到了非常关键作用。
02
Best Practices
接下来将结合生产中一些高频使用的场景和 SQL,介绍一些优化的最佳实践。
2.1 Sub-Plan Reuse
首先是 Sub-Plan Reuse(即子图复用)优化。下图中的两句 SQL 会被优化成两个独立的 Pipeline,见下图中左下角的执行计划,Scan 算子和 Filter 算子中 a>10 会计算两次。
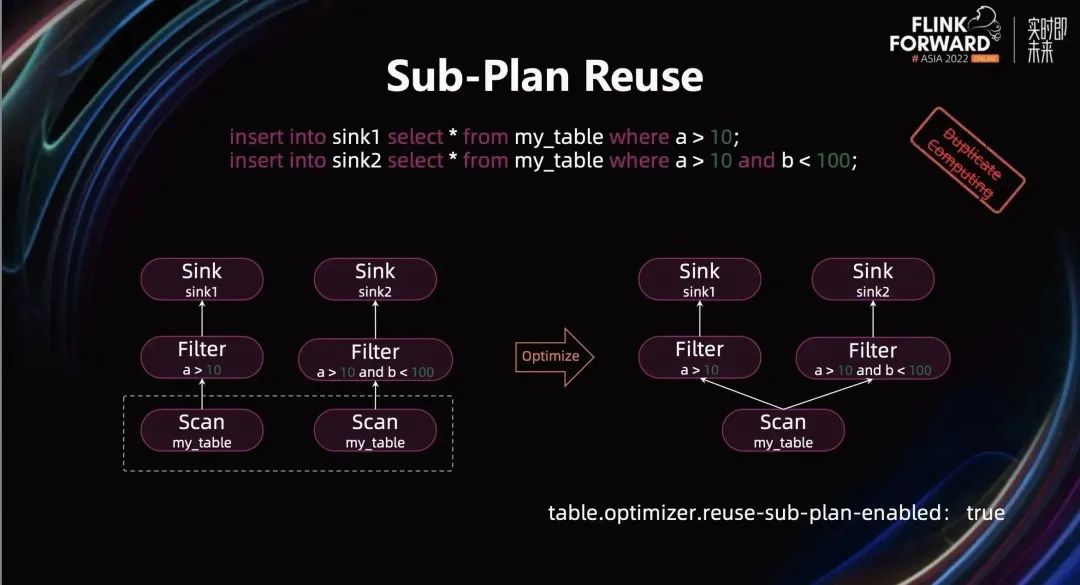
通过开启 Sub-Plan Reuse 优化,优化器会自动发现执行计划中计算逻辑完全一样的子图并将它们进行合并,从而避免重复计算。这个例子中,由于两个 Scan 算子完全一样,所以经过优化之后变成一个 Scan 算子,从而减小数据的读取的次数,优化后的 DAG 如上图右下角所示。
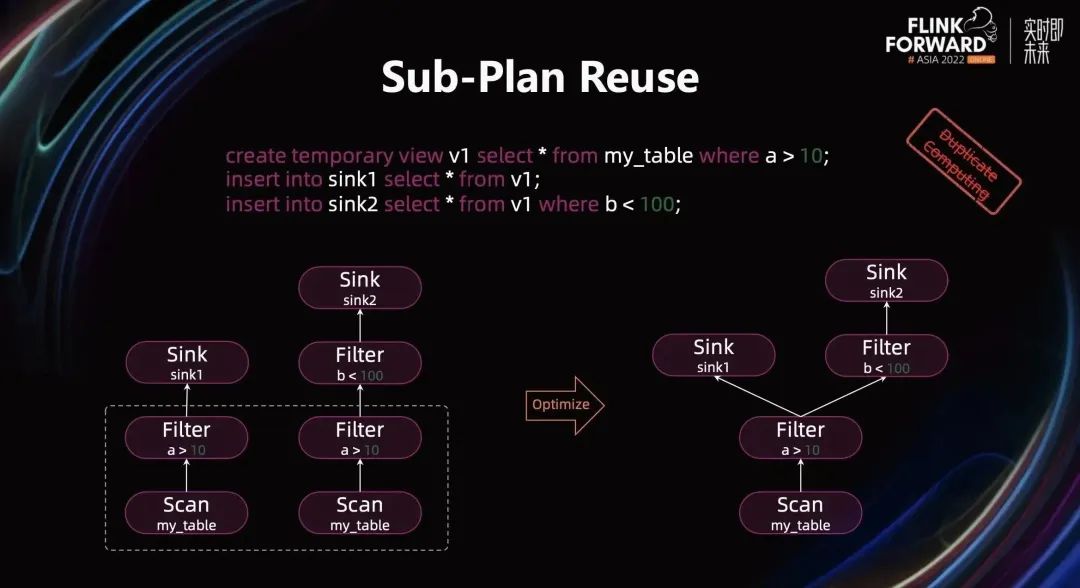
逻辑上,优化器也可以复用 Filter 中的 a>10 的部分的计算。但是当遇到非常复杂的 Query 时,同时结合各种 push down 的优化,要找到理想的可复用的执行计划是一件非常麻烦的事情。可以使用基于视图(View)的子图复用的方式来达到最大化子图复用的效果。
这里的 View,可以理解为一个子图复用单元。基于用户定义的 View,优化器能够自动识别哪些 View 能够被复用。下图中的 SQL 会翻译成左下角的执行计划,经过子图复用优化后 Scan 和 Filter a>10 都将被复用(如下图右下角执行计划所示)。
2.2 Fast Aggregation
Aggregation Query 在生产中被高频使用,这里以“select a,sum(b) from my_table group by a;”为例进行介绍 Aggregation 相关优化。该 SQL 将被翻译成下图中左边的逻辑执行计划,而图中右边是执行拓扑:Scan 算子的并发为 3,Aggregation 算子的并发为 2。
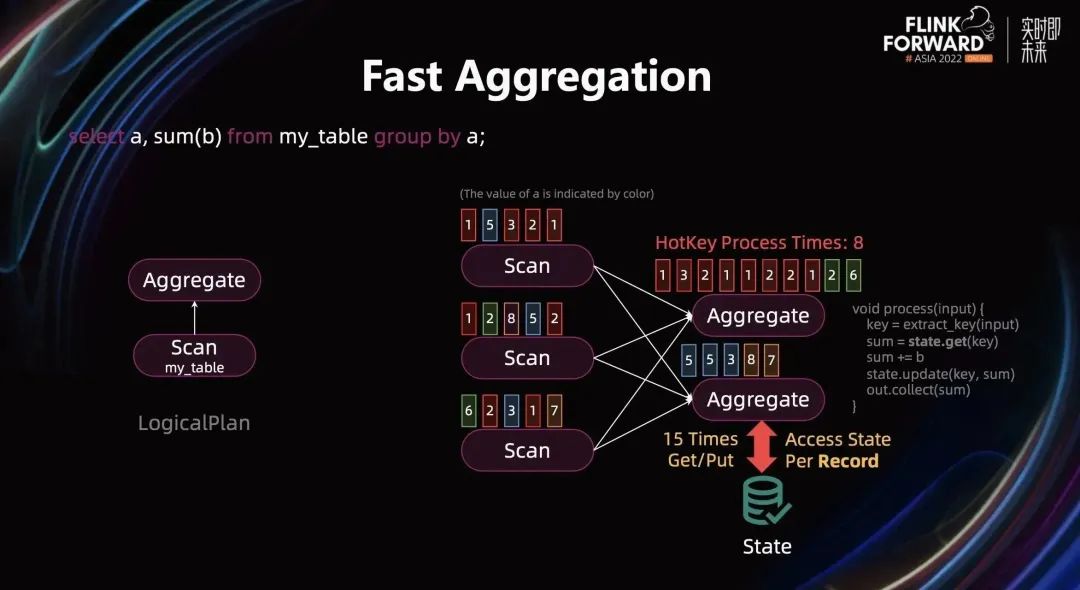
图中的一个小方框表示一条数据,用颜色来表示字段 a 的值,用数字表示字段 b 的值,所有的 Scan 算子的数据会按字段 a 进行 Shuffle 输出给 Aggregate 算子。流计算中,当 Aggregate 算子接收到一条数据后,首先会从数据中抽取它对应的 Group Key,然后从 State 里获得对应 Key 之前的聚合结果,并基于之前的聚合结果和当前的数据进行聚合计算。最后将结果更新到 State 里并输出到下游。(逻辑可参考上图中的伪代码)
上图中 Aggregate 算子的输入有 15 条数据,Aggregate 计算会触发 15 次 State 操作(15 次 get 和 put 操作),这么频繁的操作可能会造成性能影响。与此同时,第一个 Aggregate 实例接收了 8 条红色数据,会形成热点 Key。如何解决 State 访问频繁和热点 Key 的问题在生产中经常遇到。
通过开启 MiniBatch 能减少 State 的访问和减少热点 Key 的访问。对应的配置为:
table.exec.mini-batch.enabled: true
table.exec.mini-batch.allow-latency: 5s // 用户按需配置
allow-latency 表明了 MiniBatch 的大小是 5 秒,即 5 秒内的数据会成为为一个 Mini Batch。开启 Mini Batch 之后,Aggregation 的计算逻辑就会发生变化:当 Aggregate 算子接收到一条数据时,不会直接触发计算,而是把它放到一个 Buffer 里。当 Buffer 攒满之后,才开始计算:将 Buffer 的数据按 Key 进行分组,以每个组为单位进行计算。对于每个 Key,先从 State 中获取该 Key 对应的之前的聚合结果,然后逐条计算该 Key 对应的所有数据,计算完成后将结果更新 State 并输出给下游。
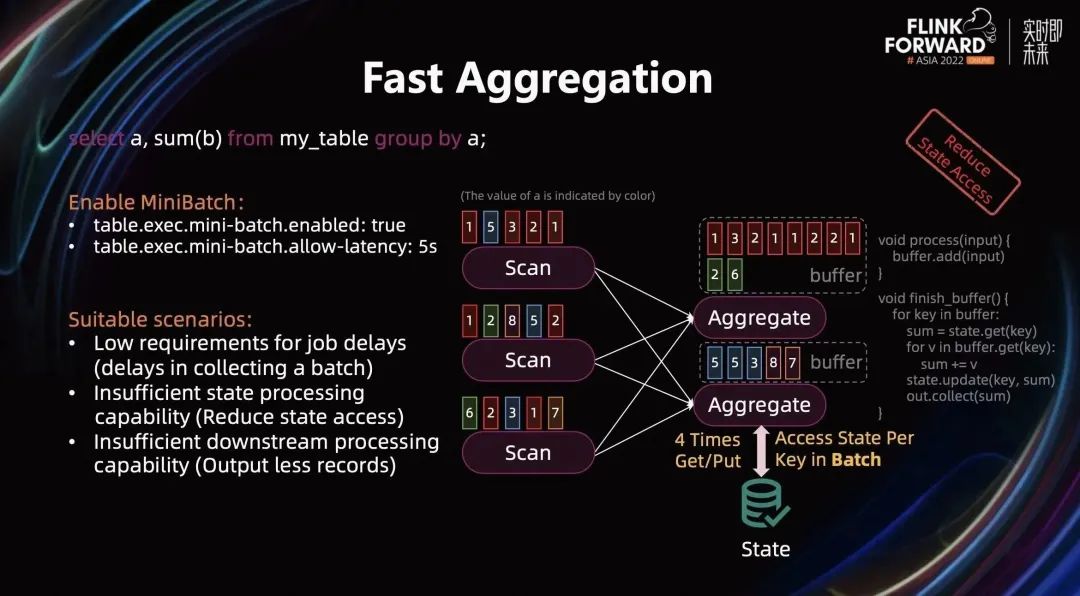
这里 State 的访问次数等于 Key 的个数。如果将上图中所示的数据都放到一个 Buffer 的话,这里 Key 的个数只有 4 个,因此只有 4 次 State 访问。相比于原来的 15 次访问,开启 MiniBatch 优化后大大减少了 State 访问的开销。
开启 MiniBatch 适用的场景为:
作业对延迟没有严格要求(因为攒 Batch 本身会带来延迟);
当前 Aggregate 算子访问 State 是瓶颈;
下游算子的处理能力不足(开启 MiniBatch 会减少往下游输出的数据量)。
上图中,我们观察到第一个 Aggregate 实例中虽然访问 State 频率很少,但是要处理的数据量还是没变,其整体数据量和单 Key 数据量相比其他 Aggregate 实例都多很多,即存在数据倾斜。我们可以通过两阶段 Aggregate(Local/Global)来解决数据倾斜避免热点。
开启两阶段 Aggregate 需要开启 MiniBatch 和将 agg-phase-strategy 设置为 TWO PHASE/AUTO,开启后的 Plan 如下图所示。
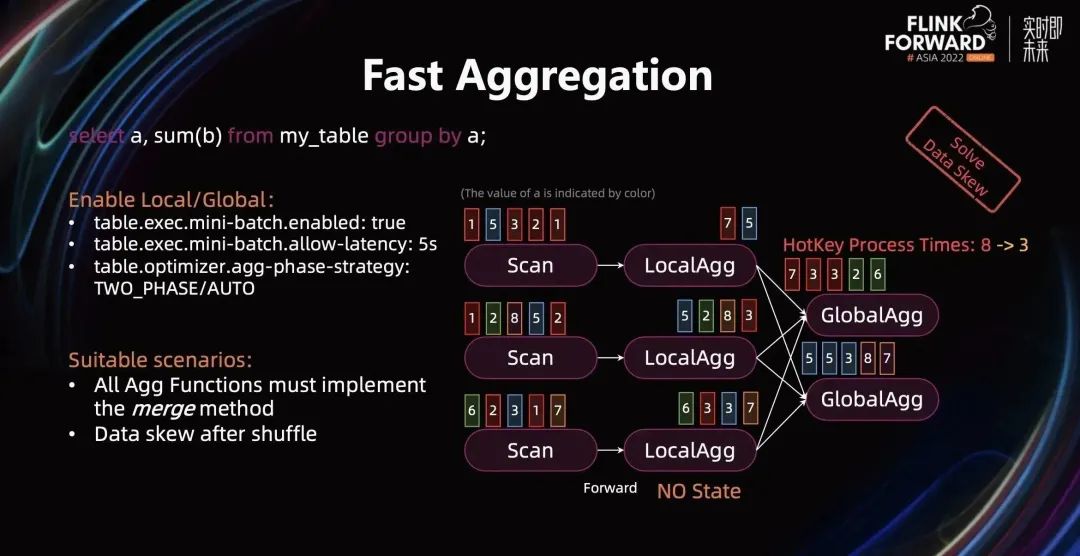
LocalAgg 和上游算子 chain 在一起,即 Scan 和 LocalAgg 采用相同并发,执行中间不存在数据 Shuffle。在 LocalAgg 里,会按照 MiniBatch 的大小进行聚合,并把聚合的结果输出到 GlobalAgg。
上图示例中,经过 LocalAgg 聚合后的红色数据在第一个 GlobalAgg 实例中从 8 条减到 3 条,各个 GlobalAgg 实例之间不存在数据倾斜。
开启 Local/Global 适用的场景为:
所有 Aggregate Function 都实现了 merge 方法,不然没法在 GlobalAgg 在对 LocalAgg 的结果进行合并;
LocalAgg 聚合度比较高,或者 GlobalAgg 存在数据倾斜,否则开启 LocalAgg 会引入额外的计算开销。
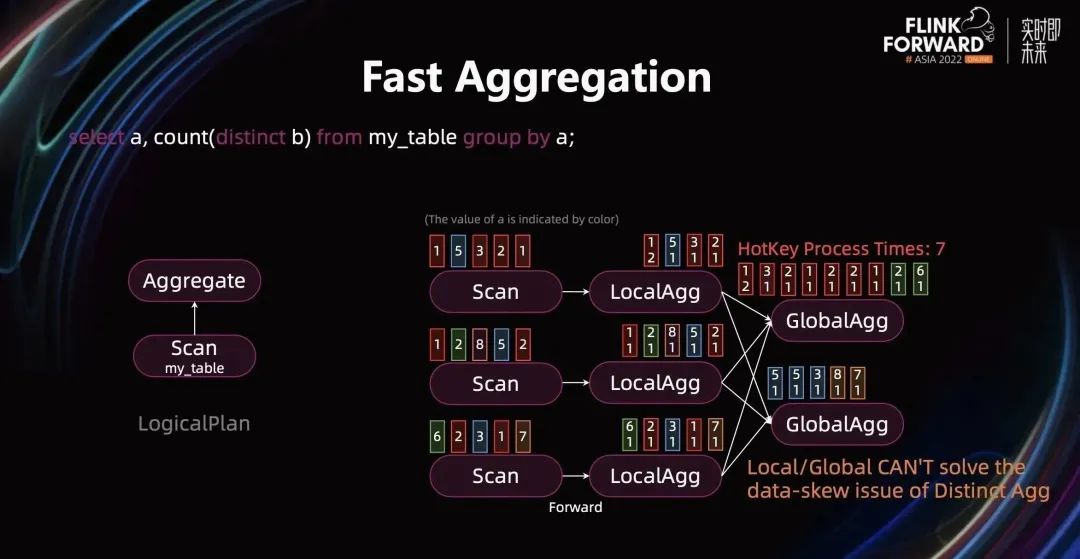
当 Query 中有 Distinct Aggreation Function 时,Local/Global 解决不了热点问题。通过下图的例子可以看出来,LocalAgg 按 a、b 字段进行聚合,聚合效果并不明显。因此,第一个 GlobalAgg 实例还是接收到大量的热点数据,共 7 条红色数据。LocalAgg 的聚合 Key(a、b)和下游的 Shuffle Key(a)不一致导致 Local/Global 无法解决 DistinctAgg 的数据热点问题。
我们可以通过开启 Partial/Final Aggreation 来解决 DistinctAgg 的数据热点问题。PartialAgg 通过 Group Key + Distinct Key 进行 Shuffle,这样确保相同的 Group Key + Distinct Key 能被 Shuffle 到同一个 PartialAgg 实例中,完成第一层的聚合,从而减少 FinalAgg 的输入数据量。可以通过下面配置开启 Partial/Final 优化:
table.optimizer.distinct-agg.split.enabled: true;
table.optimizer.distinct-agg.split.bucket-num:1024
开启配置之后,优化器会将原来的 plan 翻译成下图的 plan:
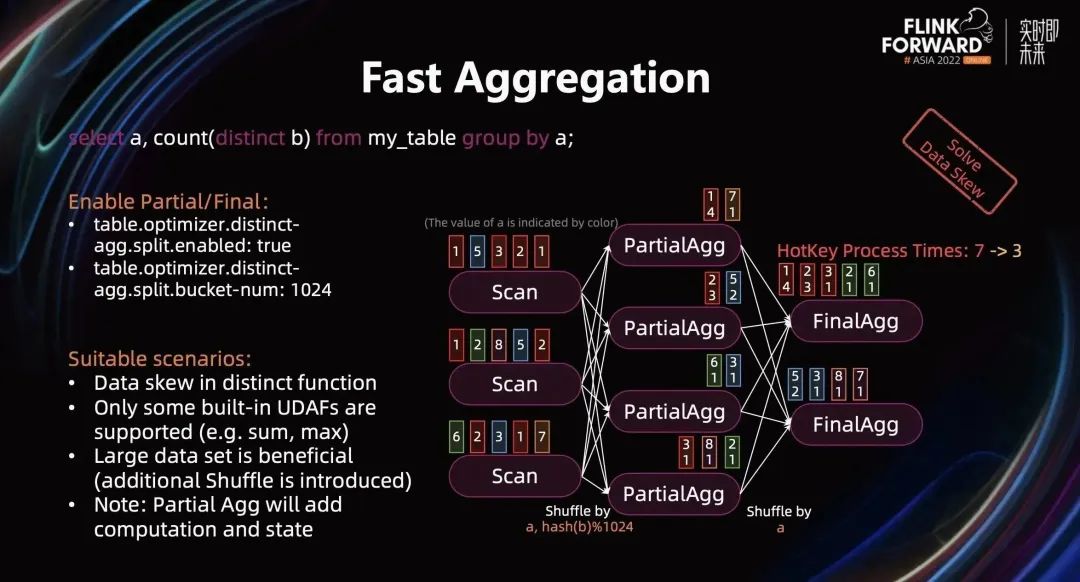
上图例子中,经过 PartialAgg 的聚合之后,第一个 FinalAgg 实例的热点 Key 从 7 条减少到 3 条。开启 Partial/Final 适用的场景为:
Query 中存在 Distinct Function,且存在数据倾斜;
非 Distinct Function 只能是如下函数:count,sum,avg,max,min;
数据集比较大的时候效果更好,因为 Partial/Final 两层 Agg 之间会引入额外的网络 Shuffle 开销;
Partial Agg 还会引入额外的计算和 State 的开销。
和 LocalAgg 不一样,PartialAgg 会将结果存放在 State 中,这会造成 State 翻倍。为了解决 PartialAgg 引入额外的 State 开销的问题,在 Partital/Final 基础上引入 Increment 优化。它同时结合了 Local/Global 和 Partial/Final 优化,并将 Partial 的 GlobalAgg 和 Final 的 LocalAgg 合并成一个 IncrementalAgg 算子,它只存放 Distinct Value 相关的值,因此减少了 State 的大小。开启 IncrementalAgg 之后的执行计划如下图所示:

一些 Query 改写也能减少 Aggregate 算子的 State。很多用户使用 COUNT DISTICNT + CASE WHEN 统计同一个维度不同条件的结果。在 Aggregate 算子里,每个 COUNT DISTICNT 函数都采用独立的 State 存储 Distinct 相关的数据,而这部分数据是冗余的。可以通过将 CASE WHEN 改写为 FILTER,优化器会将相同维度的 State 数据共享,从而减少 State 大小。

2.3 Fast Join
Join 是我们生产中非常常见的 Query,Join 的优化带来的性能提升效果非常明显。以下图简单的 Join Query 为例介绍 Join 相关的优化:该 Query 将被翻译成 Regular Join(也常被称为双流 Join),其 State 会保留 left 端和 right 端所有的数据。当数据集较大时,Join State 也会非常大,在生产中可能会造成严重的性能问题。优化 Join State 是流计算非常重要的内容。
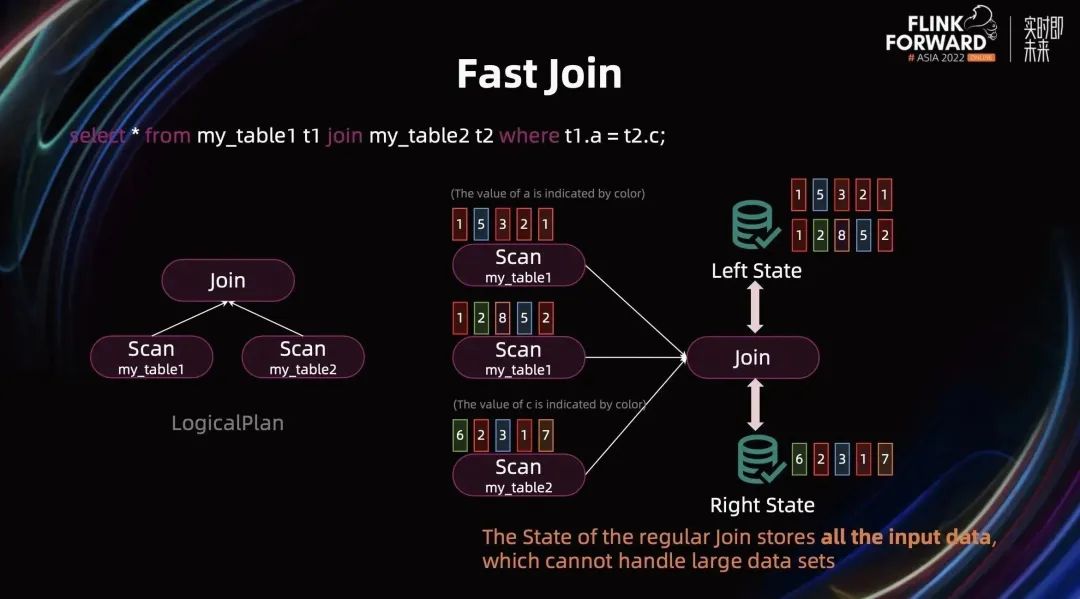
针对 Regular Join,有两种常见的优化方式:
当 Join Key 中带有 PrimaryKey(以下简称 PK) 时,State 中存储的数据较少,它只存了输入数据和对应的关联次数。当 Join 的输入存有 PK 时,State 中存储了一个 Map,Map Key 是 PK,Value 是输入数据以及关联的次数。当 Join Key 和 Join 输入都没有 PK 时,State 仍用 Map 存储,但它的 Key 是输入的数据,Value 是这一行数据的出现次数和关联次数。虽然它们都是用 Map 存储,Join 输入带 PK 时的 State 访问效率高于没有 PK 的情况。因此建议用户在 Query 中尽量定义 PK 信息,帮助优化器更好的优化。
建议在 Join 之前只保留必要的字段,让 Join State 里面存储的数据更少。

除了 Regular Join 外,Flink 还提供了其他类型的 Join:Lookup Join、Interval Join、Temporal Join、Window Join。在满足业务需求的条件下,用户可以将 Regular Join 进行改写成其他类型的 Join 以节省 State。Regular Join 和其他 Join 的转换关系如下图所示:
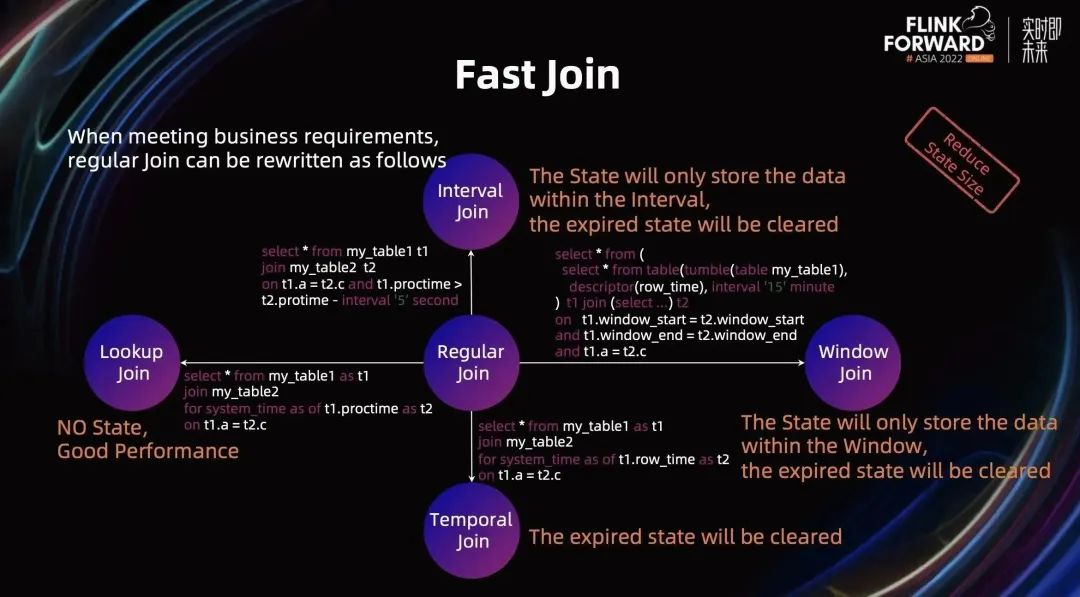
将 Regular Join 改写成 Lookup Join。主流来一条数据会触发 Join 计算,Join 会根据主流的数据查找维表中相关最新数据,因此 Lookup Join 不需要 State 存储输入数据。目前很多维表 Connector 提供了点查机制和缓存机制,执行性能非常好,在生产中被大量使用。后面章节会单独介绍 Lookup Join 相关优化。Lookup Join 的缺点是当维表数据有更新时,无法触发 Join 计算。
将 Regular Join 改写为 Interval Join。Interval Join 是在 Regluar Join 基础上对 Join Condition 加了时间段的限定,从而在 State 中只需要存储该时间段的数据即可,过期数据会被及时清理。因此 Interval Join 的 State 相比 Regular Join 要小很多。
把 Regular Join 改写成 Window Join。Window Join 是在 Regluar Join 基础上定义相关 Window 的数据才能被 Join。因此,State 只存放的最新 Window,过期数据会被及时清理。
把 Regular Join 改写成 Temporal Join。Temporal Join 是在 Regular Join 上定义了相关版本才能被 Join。Temporal Join 保留最新版本数据,过期数据会被及时清理。
2.4 Fast Lookup Join
Lookup Join 在生产中被广泛使用,因此我们这里对其做单独的优化介绍。当前 Flink 对 Lookup Join 提供了多种优化方式:
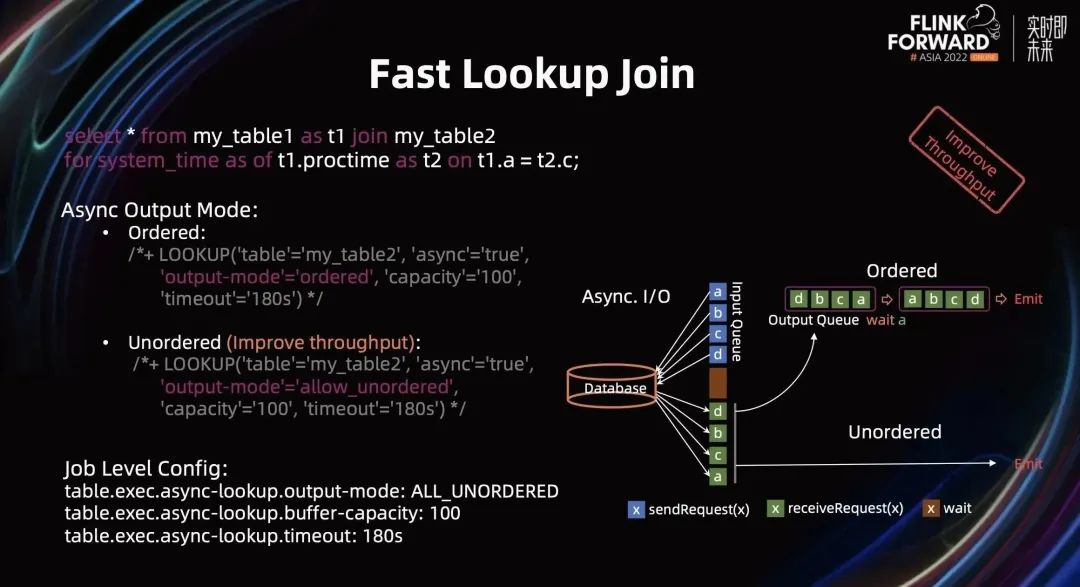
第一种,提供同步和异步查询机制。如下图所示,在同步查询中,当一条数据发送给维表 Collector 后,需要等结果返回,才能处理下一条,中间会有大量的时间等待。在异步查询过程中,会将一批数据同时发送给维表 Collector,在这批数据完成查询会统一返回给下游。通过异步查询模式模式,查询性能得到极大提升。Flink 提供了 Query Hint 的方式开启同步和异步模式,请参考下图所示。

第二种,在异步模式下,提供了 Ordered 和 Unordered 机制。在 Order 模式之下,需要等所有数据返回后并对数据排序,以确保输出的顺序和输入的顺序一致,排序完成才能发送给下游。在 Unordered 模式下,对输出顺序没有要求,只要查询到结果,就可以直接发送给下游。因此,相比于 Order 模式,Unordered 模式能够有极大提升性能。Flink 提供了 Query Hint 的方式开启 Ordered 和 Unordered 模式,请参考下图所示。(Flink 也提供 Job 级别的配置,开启所有维表查询的都采用相同输出模式。)
第三种,Cache 机制。这是一种很常见的优化,用 本地 Memory Lookup 提高查询效率。目前,Flink 提供了三种 Cache 机制:
Full Caching,将所有数据全部 Cache 到内存中。该方式适合小数据集,因为数据量过大会导致 OOM。Flink 提供了 Table Hints 开启。同时,还可以通过 Hints 定义 reload 策略。
Partial Caching,适合大数据集使用,框架底层使用 LRU Cache 保存最近被使用的数据。当然,也可以通过 Hint 定义 LRU Cache 的大小和 Cache 的失效时间。
No Caching,即关闭 Cache。

2.5 Fast Deduplication
流计算中经常遇到数据重复,因此“去重”使用频率非常高。在早期版本,Flink 通过 group by + first_value 的方式查找第一行数据;通过 group by + last_value 查找最后一行数据。示例如下图所示:

上述 Query 会被转换为 Aggregate 算子,它的 State 非常大且无法保证语义完整。因为下游的输出数据可能来源于不同行,导致与按行去重的语义语义相悖。
在最近版本中,Flink 提供了更高效的去重方式。由于 Flink 没有专门提供去重语法,目前通过 Over 语句表达去重语义,参考下图所示。对于查找第一行场景,可以按照时间升序,同时输出 row_number,再基于 row_number 进行过滤。此时,算子 State 只需要存储去重的 Key 即可。对于查找最后一行场景,把时间顺序变为降序,算子 State 只需要存储最后一行数据即可。

2.6 Fast TopN
TopN(也称为 Rank) 在生产中也经常遇到,Flink 中没有提供专门的 TopN 的语法,也是通过 Over 语句实现。目前,TopN 提供了三种实现方式(它们性能依次递减)。

第一种,AppendRank,要求输入是 Append 消息,此时 TopN 算子中 State 仅需要为每个 Key 存放满足要求的 N 条数据。
第二种,UpdateFastRank, 要求输入是 Update 消息,同时要求上游的 Upsert Key 必须包含 Partition Key,Order-by 字段必须是单调的且其单调方向需要与 Order-by 的方向相反。以上图中右边的 Query 为例,Group By a,b 会产生以 a,b 为 Key 的更新流。在 TopN 算子中,上游产生的 Upsert Key (a,b) 包含 Over 中 Partition Key(a,b);Sum 函数的入参都是正数(where c >= 0), 所以 Sum 的结果将是单调递增的,从而字段 c 是单调递增,与排序方向相反。因此这个 Query 就可以被翻译成 UpdateFastRank。
第三种,RetractRank,对输入没有任何要求。State 中需要存放所有输入数据,其性能也是最差的。
除了在满足业务需求的情况下修改 Query 以便让优化器选择更优的算子外,TopN 还有一些其他的优化方法:
不要输出 row_number 字段,这样可以大大减少下游处理的数据量。如果下游需要排序,可以在前端拿到数据后重排。
增加 TopN 算子中 Cache 大小,减少对 State 的访问。Cache 命中率的计算公式为:cache_hit = cache_size * parallelism / top_n_num / partition_key_num。由此可见,增加 Cache 大小可以增加 Cache 命中率(可以通过 table.exec.rank.topn-cache-size 修改 Cache 大小,默认值是 1 万)。需要注意的是,增加 Cache 大小时,TaskManager 的内存也需要相应增加。
分区字段最好与时间相关。如果 Partition 字段不与时间属性关联,无法通过 TTL 进行清理,会导致 State 无限膨胀。(配置了 TTL,数据被过期清理可能导致结果错误,需要慎重)

2.7 Efficient User Defined Connector
Flink 提供了多种 Connector 相关接口,帮助优化器生成更优的执行计划。用户可以根据 Connector 的能力,实现对应的接口从而提高 Collector 的执行性能。

SupportsFilterPushDown,将 Filter 条件下推到 Scan 里,从而减少 Scan 的读 IO,以提高性能。
SupportsProjectionPushDown,告诉 Scan 只读取必要的字段,减少无效的字段读取。
SupportsPartitionPushDown,在静态优化时,告诉 Scan 只需要读取有效分区,避免无效分区读取。
SupportsDynamicFiltering,在作业运行时,动态识别出哪些分区是有效的,避免无效分区读取。
SupportsLimitPushDown,将 limit 值下推到 Scan 里,只需要读取 limit 条数据即可,大大减少了 Scan I/O。
SupportsAggregatePushDown,直接从 Scan 中读取聚合结果,减少 Scan 的读 I/O,同时输出给下游的数据更少。
SupportsStatisticReport,Connector 汇报统计信息给优化器,以便优化器产生更优的执行计划。
2.8 Use Hints Well
任何优化器都不是完美的,Flink 提供了 Hints 机制来影响优化器以获得更优的执行计划。目前有两种 Hints:

Table Hints,主要用于改变 Table 表的配置,例如 Lookup Table 的缓存策略可以通过 Table Hint 进行修改。
Query Hints,当前它可以建议优化器选择合适的 Join 策略。Lookup Join 可以通过 Hint 修改 Lookup 策略,请参考上述 Lookup Join 相关优化的介绍;也可以通过 Hint 让优化器为批作业选择对应的 Join 算法,具体请参考上图所示。
03
Future Works
在未来,我们将提供更有深度、更多场景、更智能的优化,以进一步提高 Flink 引擎的执行效率。
首先,我们将会在优化的深度上会持续挖掘,例如多个连续的 Join 会有 State 重复的问题,可以将它优化成一个 Join,避免 State 重复。
其次,我们希望扩大优化的广度,结合不同的业务场景进行有针对性的优化。
最后,我们希望优化更加智能,会探索做一些动态优化相关工作,例如根据流量变化,在线自动优化 plan。

往期精选





▼ 登录「Flink-learning 学训平台」,加入学习 ▼

▼ 关注「Apache Flink」,获取更多技术干货 ▼

 点击「阅读原文」,查看原文视频&演讲 PPT
点击「阅读原文」,查看原文视频&演讲 PPT