我们非常高兴地宣布 AutoDev v0.2.0 的发布!AutoDev 是一款强大的 AI 辅助编程工具,可以与 Jetbrains 系列 IDE 无缝集成(VS Code 支持正在开发中)。通过与需求管理系统(如 Github Issue 等)直接对接,AutoDev 为您提供了更便捷的编程体验。
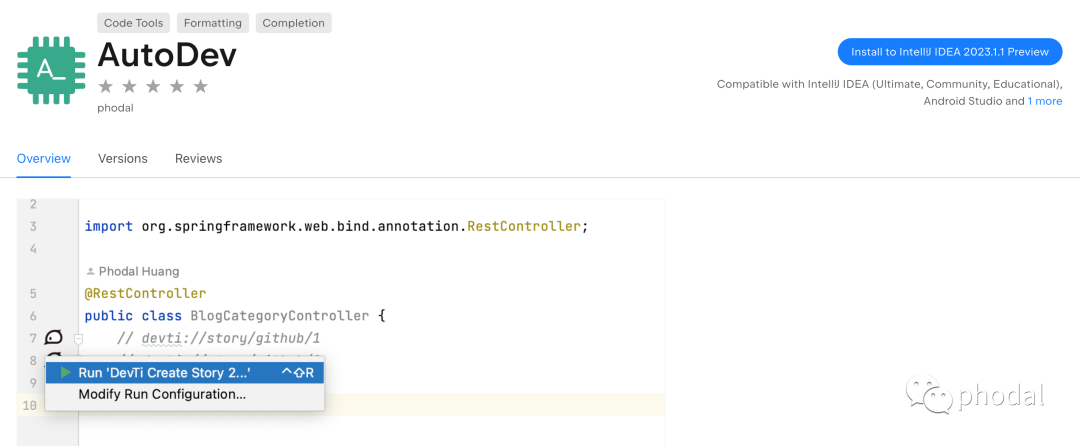
搜索 AutoDev,并配置一下你的 AI Key,或者自定义的 OpenAI Host,就可以 🚀 了。未来,我们将支持更多的国产大语言模型(如果有人有兴趣一起开发的)。
🔥 惊艳功能:增强模式 & 自动模式
在 Jetbrains IDE 中,您只需简单点击,AutoDev 就可以根据您的需求自动生成代码。您所需做的,仅仅是对生成的代码进行质量检查。
✨ 增强模式
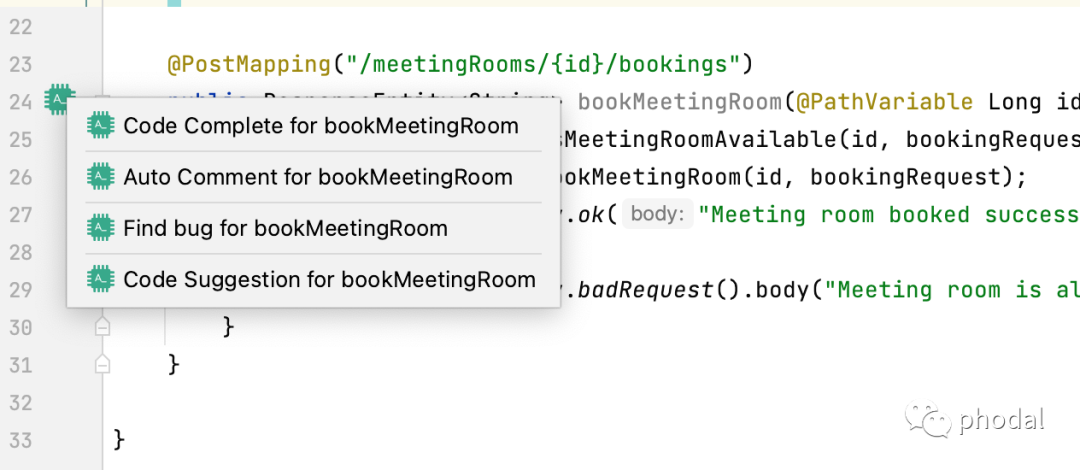
仅需一键,AutoDev 就能为您提供以下功能:
自动完成代码。
代码添加注释。
寻找代码中的 bug。
对代码进行 Code Review。
……
🤖 AutoCRUD 自动模式
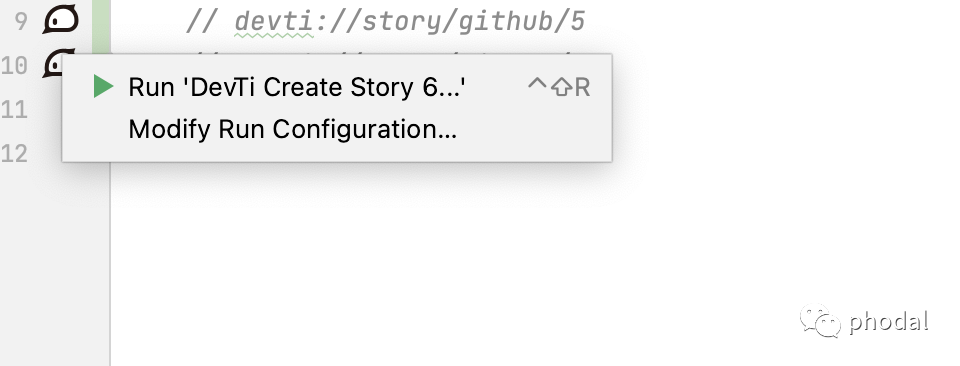
AutoDev 可以自动处理以下步骤:
对接需求系统,获取需求文档。
根据需求文档,自动分析并完善需求。
寻找最适合的 Endpoint(即 Controller)。
自动生成 Controller 代码。
自动生成 Service 代码。
自动生成 Repository 代码。(进行中)
未来
AutoDev 已经支持 Java,正在支持 Kotlin 和 TypeScript,未来还将支持更多的编程语言。我们还在不断地更新和改进 AutoDev,使得它更加智能、更加高效。AutoDev 目前已经与许多公司合作(GPT 编说的,没有很多),为他们提供了高效的编程工具。我们相信,AutoDev 也将会是您的最佳选择,让您的编程体验更加高效和愉悦。
如果您还没有尝试过 AutoDev,现在是一个绝佳的机会!AutoDev 现在已经上架 Jetbrains 插件市场,可以直接在您的 IDE 中搜索并安装。我们期待着您的反馈和建议,让我们一起打造更加优秀的编程工具!
Jetbrains 版本:https://github.com/unit-mesh/auto-dev
VS Code 版本:https://github.com/unit-mesh/auto-dev-vscode