Java
快速入门 # 本文档提供了一个关于如何使用Flink ML的快速入门。阅读本文档的用户将被指导提交一个简单的Flink作业,用于训练机器学习模型并提供预测服务。
求助,我卡住了!# 如果你遇到困难,请查看社区支持资源。特别是,Apache Flink的用户邮件列表一直被评为Apache项目中最活跃的之一,是快速获得帮助的好途径。
前提条件 # 确保Java 8或更高版本已经安装在您的本地计算机上。要检查已安装的Java版本,请在终端中输入:
$ java -version 下载 Flink # 下载1.15或更高版本的Flink,然后解压缩存档文件:
$ tar -xzf flink-*.tgz 设置 Flink 环境变量 # 下载Flink后,请将$FLINK_HOME注册为本地环境中的环境变量。
cd ${path_to_flink} export FLINK_HOME=pwd 将 Flink ML库添加到 Flink 的库文件夹中 # 您需要将Flink ML的库文件复制到Flink的文件夹中以便正确初始化。
请下载相应的Flink ML二进制发行版,然后解压缩存档文件:
tar -xzf flink-ml-*.tgz 然后,您可以使用以下命令将解压后的库文件复制到Flink的文件夹中。
cd ${path_to_flink_ml} cp ./lib/*.jar $FLINK_HOME/lib/ 运行 Flink ML 示例作业 # 请使用以下命令在本地环境中启动一个Flink独立集群。
$FLINK_HOME/bin/start-cluster.sh 您应该能够导航至localhost:8081查看Flink仪表板并确认集群已启动并运行。
然后,您可以按照如下方式将Flink ML示例提交给集群。
$FLINK_HOME/bin/flink run -c org.apache.flink.ml.examples.clustering.KMeansExample $FLINK_HOME/lib/flink-ml-examples*.jar 上述命令将提交并执行Flink ML的KMeansExample作业。还有其他Flink ML算法的示例作业,您可以在flink-ml-examples模块中找到它们。
终端中的示例输出如下所示。
Features: [9.0, 0.0] Cluster ID: 1
Features: [0.3, 0.0] Cluster ID: 0
Features: [0.0, 0.3] Cluster ID: 0
Features: [9.6, 0.0] Cluster ID: 1
Features: [0.0, 0.0] Cluster ID: 0
Features: [9.0, 0.6] Cluster ID: 1
现在您已经成功运行了一个FlinkML Job。
您将构建什么? Kmeans是一种广泛使用的聚类算法,并得到了Flink ML的支持。本教程将指导您使用Flink ML创建一个Flink作业,初始化并训练一个Kmeans模型,最后使用它来预测某些数据点的聚类ID。
先决条件 # 本教程假定您对Java有一定了解,但即使您使用的是不同的编程语言,也应该能够跟随教程进行。
帮助,我遇到困难了!如果你遇到困难,请查看社区支持资源。特别是,Apache Flink的用户邮件列表一直被评为Apache项目中最活跃的之一,是快速获得帮助的好方法。
如何跟随教程 # 如果您想跟随教程,您需要一台具有以下配置的计算机:
Java 8 Maven 3 尽管在以下步骤中提供了要在CLI中执行的命令以完成此示例,但建议使用IDE,如IntelliJ IDEA,来管理、构建和执行下面的示例代码。
请使用以下命令创建一个Flink Maven Archetype,它提供了一个项目的基本框架,并附带一些必要的Flink依赖项。
$ mvn archetype:generate
-DarchetypeGroupId=org.apache.flink
-DarchetypeArtifactId=flink-quickstart-java
-DarchetypeVersion=1.15.1
-DgroupId=kmeans-example
-DartifactId=kmeans-example
-Dversion=0.1
-Dpackage=myflinkml
-DinteractiveMode=false 上面的命令将在您当前的目录中创建一个名为kmeans-example的maven项目,结构如下:
$ tree kmeans-example
kmeans-example
├── pom.xml
└── src
└── main
├── java
│ └── myflinkml
│ └── DataStreamJob.java
└── resources
└── log4j2.properties
将pom.xml中提供的依赖项更改为以下内容:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-ml-uber</artifactId>
<version>2.2-SNAPSHOT</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-runtime</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-loader</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>statefun-flink-core</artifactId>
<version>3.2.0</version>
<exclusions>
<exclusion>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.flink</groupId>
<artifactId>flink-metrics-dropwizard</artifactId>
</exclusion>
</exclusions>
</dependency>
创建文件src/main/java/myflinkml/KMeansExample.java,并将以下内容保存到文件中。您可以随意忽略并删除src/main/java/myflinkml/DataStreamJob.java,因为它在本教程中不会被使用。
package myflinkml;
import org.apache.flink.ml.clustering.kmeans.KMeans;
import org.apache.flink.ml.clustering.kmeans.KMeansModel;
import org.apache.flink.ml.linalg.DenseVector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
public class KMeansExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
String featuresCol = "features";
String predictionCol = "prediction";
// Generate train data and predict data as DataStream.
DataStream<DenseVector> inputStream = env.fromElements(
Vectors.dense(0.0, 0.0),
Vectors.dense(0.0, 0.3),
Vectors.dense(0.3, 0.0),
Vectors.dense(9.0, 0.0),
Vectors.dense(9.0, 0.6),
Vectors.dense(9.6, 0.0)
);
// Convert data from DataStream to Table, as Flink ML uses Table API.
Table input = tEnv.fromDataStream(inputStream).as(featuresCol);
// Creates a K-means object and initialize its parameters.
KMeans kmeans = new KMeans()
.setK(2)
.setSeed(1L)
.setFeaturesCol(featuresCol)
.setPredictionCol(predictionCol);
// Trains the K-means Model.
KMeansModel model = kmeans.fit(input);
// Use the K-means Model for predictions.
Table output = model.transform(input)[0];
// Extracts and displays prediction result.
for (CloseableIterator<Row> it = output.execute().collect(); it.hasNext(); ) {
Row row = it.next();
DenseVector vector = (DenseVector) row.getField(featuresCol);
int clusterId = (Integer) row.getField(predictionCol);
System.out.println("Vector: " + vector + "\tCluster ID: " + clusterId);
}
}
}
在将上述代码放入您的Maven项目之后,您可以使用以下命令或IDE来构建和执行示例作业。
cd kmeans-example/
mvn clean package
mvn exec:java -Dexec.mainClass="myflinkml.KMeansExample" -Dexec.classpathScope="compile"
如果您在IDE中运行项目,您可能会遇到java.lang.NoClassDefFoundError异常。这可能是因为您没有将所有所需的Flink依赖项隐式加载到类路径中。
IntelliJ IDEA:转到 Run > Edit Configurations > Modify options > 选择“Provided”的范围内的依赖项。此运行配置现在将包括所有从IDE内运行应用程序所需的类。
执行作业后,类似以下信息将输出到您的终端窗口。
Vector: [0.3, 0.0] Cluster ID: 1
Vector: [9.6, 0.0] Cluster ID: 0
Vector: [9.0, 0.6] Cluster ID: 0
Vector: [0.0, 0.0] Cluster ID: 1
Vector: [0.0, 0.3] Cluster ID: 1
Vector: [9.0, 0.0] Cluster ID: 0
程序可能在打印出上述信息后卡住,您可能需要输入^C终止进程。这种情况只会发生在本地执行程序时,而在提交作业到Flink集群时则不会发生。
解析代码#
执行环境#
前几行设置了StreamExecutionEnvironment以执行Flink ML作业。如果您有使用Flink的经验,您对此概念应该很熟悉。对于本文档中的示例程序,一个简单的StreamExecutionEnvironment,没有特定配置就足够了。
考虑到Flink ML使用Flink的Table API,接下来的程序还需要一个StreamTableEnvironment。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
创建训练和推理数据表#
接下来,程序创建了包含Kmeans算法训练和预测过程数据的表。Flink ML操作符会搜索输入表中的列名以获取输入数据,并将预测结果输出到指定的输出表列。
DataStream<DenseVector> inputStream = env.fromElements(
Vectors.dense(0.0, 0.0),
Vectors.dense(0.0, 0.3),
Vectors.dense(0.3, 0.0),
Vectors.dense(9.0, 0.0),
Vectors.dense(9.0, 0.6),
Vectors.dense(9.6, 0.0)
);
Table input = tEnv.fromDataStream(inputStream).as(featuresCol);
创建、配置、训练和使用Kmeans#
Flink ML的Kmeans算法类包括KMeans和KMeansModel。KMeans基于提供的训练数据实现Kmeans算法的训练过程,并最终生成一个KMeansModel。
将输入表与数据流相连接:
Table input = tEnv.fromDataStream(inputStream).as(featuresCol);
创建、配置、训练和使用 Kmeans #
Flink ML 中与 Kmeans 算法相关的类包括 KMeans 和 KMeansModel。KMeans 基于提供的训练数据实现 Kmeans 算法的训练过程,并最终生成一个 KMeansModel。KmeansModel.transform() 方法编码了此算法的转换逻辑,用于预测。
KMeans 和 KMeansModel 都为 Kmeans 算法的配置参数提供 getter/setter 方法。示例程序显式设置以下参数,其他配置参数将使用其默认值。
K,要创建的聚类数量
seed,用于初始化聚类中心的随机种子
featuresCol,包含输入特征向量的列名
predictionCol,用于输出预测结果的列名
当程序调用 KMeans.fit() 生成一个 KMeansModel 时,KMeansModel 将继承 KMeans 对象的配置参数。因此,可以直接在 KMeans 对象中设置 KMeansModel 的参数。
KMeans kmeans = new KMeans()
.setK(2)
.setSeed(1L)
.setFeaturesCol(featuresCol)
.setPredictionCol(predictionCol);
KMeansModel model = kmeans.fit(input);
Table output = model.transform(input)[0];
收集预测结果 #
与所有其他 Flink 程序一样,上述各节中描述的代码仅配置 Flink 作业的计算图,程序仅在调用 execute() 方法后评估计算逻辑并收集输出。从输出表收集的输出结果将是行,其中 featuresCol 包含输入特征向量,predictionCol 包含输出预测结果,即,簇 ID。
for (CloseableIterator<Row> it = output.execute().collect(); it.hasNext(); ) {
Row row = it.next();
DenseVector vector = (DenseVector) row.getField(featuresCol);
int clusterId = (Integer) row.getField(predictionCol);
System.out.println("Vector: " + vector + "\tCluster ID: " + clusterId);
}
Vector: [0.3, 0.0]Cluster ID: 1
Vector: [9.6, 0.0]Cluster ID: 0
Vector: [9.0, 0.6]Cluster ID: 0
Vector: [0.0, 0.0]Cluster ID: 1
Vector: [0.0, 0.3]Cluster ID: 1
Vector: [9.0, 0.0]Cluster ID: 0
Python
快速入门 # 本文档提供了关于使用 Flink ML 的快速入门。本文档的读者将被引导创建一个简单的 Flink 作业,用于训练一个机器学习模型,并使用它提供预测服务。
您将构建什么? # Kmeans 是一种广泛使用的聚类算法,已被 Flink ML 支持。本教程将指导您使用 Flink ML 创建一个 Flink 作业,初始化并训练一个 Kmeans 模型,最后使用它来预测某些数据点的簇 ID。
前提条件 # 本教程假定您对 Python 有一定的熟悉程度,但即使您使用的是其他编程语言,您也应该能够跟随进行。
我遇到困难了! # 如果你遇到困难,请查看社区支持资源。特别是,Apache Flink 的用户邮件列表一直被评为任何 Apache 项目中最活跃的之一,是快速获得帮助的好方法。
如何跟随操作 # 如果您想跟随操作,您需要一台电脑,配置如下:
Java 8 Python 3.6、3.7 或 3.8 本教程需要安装 Flink ML Python SDK,该 SDK 可在 PyPi 上获取,可使用 pip 轻松安装。
$ python -m pip install apache-flink-ml==2.2.0 编写 Flink ML Python 程序 # Flink ML 程序首先需要设置 StreamExecutionEnvironment 以执行 Flink ML 作业。如果您有使用 Flink 的经验,您应该已经熟悉这个概念。对于本文档中的示例程序,一个简单的 StreamExecutionEnvironment,不需要特定配置即可。
考虑到 Flink ML 使用 Flink 的 Table API,接下来的程序还需要一个 StreamTableEnvironment。
创建一个新的 StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
创建一个 StreamTableEnvironment
t_env = StreamTableEnvironment.create(env) 接下来,您可以创建包含以下 Kmeans 算法的训练和预测过程数据的表。Flink ML 操作符会搜索输入表的列名以获取输入数据,并将预测结果输出到指定的输出表的列中。
生成输入数据
input_data = t_env.from_data_stream(
env.from_collection([
(Vectors.dense([0.0, 0.0]),),
(Vectors.dense([0.0, 0.3]),),
(Vectors.dense([0.3, 3.0]),),
(Vectors.dense([9.0, 0.0]),),
(Vectors.dense([9.0, 0.6]),),
(Vectors.dense([9.6, 0.0]),),
],
type_info=Types.ROW_NAMED(
['features'],
[DenseVectorTypeInfo()])))
Flink ML 中与 Kmeans 算法相关的类包括 KMeans 和 KMeansModel。KMeans 基于提供的训练数据实现 Kmeans 算法的训练过程,并最终生成一个 KMeansModel。KmeansModel.transform() 方法编码了此算法的转换逻辑,用于预测。
KMeans 和 KMeansModel 都为 Kmeans 算法的配置参数提供 getter/setter 方法。此示例程序明确设置了以下参数,其他配置参数将使用其默认值。
k,要创建的聚类数量
seed,用于初始化聚类中心的随机种子
当程序调用 KMeans.fit() 生成一个 KMeansModel 时,KMeansModel 将继承 KMeans 对象的配置参数。因此,可以直接在 KMeans 对象中设置 KMeansModel 的参数。
创建一个 kmeans 对象并初始化其参数
kmeans = KMeans().set_k(2).set_seed(1)
训练 kmeans 模型
model = kmeans.fit(input_data)
使用 kmeans 模型进行预测
output = model.transform(input_data)[0]
与所有其他 Flink 程序一样,上述各节中描述的代码仅配置 Flink 作业的计算图,程序仅在调用 execute() 方法后评估计算逻辑并收集输出。从输出表收集的输出结果将是行,其中 featuresCol 包含输入特征向量,predictionCol 包含输出预测结果,即,簇 ID。
提取并显示结果
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
features = result[field_names.index(kmeans.get_features_col())]
cluster_id = result[field_names.index(kmeans.get_prediction_col())]
print('Features: ' + str(features) + ' \tCluster Id: ' + str(cluster_id))
到目前为止的完整代码:
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.linalg import Vectors, DenseVectorTypeInfo
from pyflink.ml.clustering.kmeans import KMeans
from pyflink.table import StreamTableEnvironment
# create a new StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# create a StreamTableEnvironment
t_env = StreamTableEnvironment.create(env)
# generate input data
input_data = t_env.from_data_stream(
env.from_collection([
(Vectors.dense([0.0, 0.0]),),
(Vectors.dense([0.0, 0.3]),),
(Vectors.dense([0.3, 3.0]),),
(Vectors.dense([9.0, 0.0]),),
(Vectors.dense([9.0, 0.6]),),
(Vectors.dense([9.6, 0.0]),),
],
type_info=Types.ROW_NAMED(
['features'],
[DenseVectorTypeInfo()])))
# create a kmeans object and initialize its parameters
kmeans = KMeans().set_k(2).set_seed(1)
# train the kmeans model
model = kmeans.fit(input_data)
# use the kmeans model for predictions
output = model.transform(input_data)[0]
# extract and display the results
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
features = result[field_names.index(kmeans.get_features_col())]
cluster_id = result[field_names.index(kmeans.get_prediction_col())]
print('Features: ' + str(features) + ' \tCluster Id: ' + str(cluster_id))
在本地执行 Flink ML Python 程序 # 在创建了一个 python 文件(例如 kmeans_example.py)并将上述代码保存到该文件后,你可以在命令行中运行示例:
python kmeans_example.py 上述命令将构建示例作业并在本地小型集群中运行。你的终端中的示例输出如下。
Features: [9.6,0.0] Cluster Id: 0
Features: [9.0,0.6] Cluster Id: 0
Features: [0.0,0.3] Cluster Id: 1
Features: [0.0,0.0] Cluster Id: 1
Features: [0.3,3.0] Cluster Id: 1
Features: [9.0,0.0] Cluster Id: 0
在 Flink 集群上执行 Flink ML Python 程序 #
先决条件 #
确保在本地计算机上已安装 Java 8 或更高版本。要检查已安装的 Java 版本,请在终端中键入:
$ java -version
下载 Flink #
下载 1.15 或更高版本的 Flink,然后解压缩存档:
$ tar -xzf flink-*.tgz
设置 Flink 环境变量 #
下载 Flink 后,请将 $FLINK_HOME 作为环境变量注册到本地环境中。
cd ${path_to_flink}
export FLINK_HOME=pwd
将 Flink ML 库添加到 Flink 的库文件夹中 #
你需要将 Flink ML 的库文件复制到 Flink 的文件夹以进行正确的初始化。
请下载 Flink ML 的相应二进制发布版本,然后解压缩存档:
tar -xzf flink-ml-*.tgz
然后,你可以使用以下命令将提取的库文件复制到 Flink 的文件夹。
cd ${path_to_flink_ml}
cp ./lib/*.jar $FLINK_HOME/lib/
运行 Flink ML 作业 #
请使用以下命令在本地环境中启动 Flink 独立集群。
$FLINK_HOME/bin/start-cluster.sh
你应该能够导航到 localhost:8081 的 web UI,查看 Flink 仪表板并查看集群已启动并运行。
在创建了一个 python 文件(例如 kmeans_example.py)并将上述代码保存到该文件后,你可以按照如下方式将示例作业提交给集群。
$FLINK_HOME/bin/flink run -py kmeans_example.py
终端中的示例输出如下
Features: [9.6,0.0] Cluster Id: 0
Features: [9.0,0.6] Cluster Id: 0
Features: [0.0,0.3] Cluster Id: 1
Features: [0.0,0.0] Cluster Id: 1
Features: [0.3,3.0] Cluster Id: 1
Features: [9.0,0.0] Cluster Id: 0
开发
概述#
本文档简要介绍了 Flink ML 中的基本概念。
Table API #
Flink ML 的 API 基于 Flink 的Table API。Table API 是 Java、Scala 和 Python 的语言集成查询 API,允许以非常直观的方式从关系运算符(如选择、过滤和连接)组成查询。
Table API 允许使用多种数据类型。Flink 文档数据类型页面提供了支持类型的列表。除这些类型外,Flink ML 还为 VectorType 提供支持。
Table API 与 Flink 的 DataStream API 无缝集成。您可以轻松在所有 API 和构建在其上的库之间切换。请参阅 Flink 文档了解如何在 Table 和 DataStream 之间转换,以及 Flink 表 API 的其他用法。
阶段 #
阶段(Stage)是 Pipeline 或 Graph 中的一个节点。它是 Flink ML 中的基本组件。这个接口只是一个概念,没有实际功能。其子类包括以下内容。
估算器:估算器(Estimator)是负责机器学习算法训练过程的阶段(Stage)。它实现了一个 fit() 方法,该方法接受一个Table列表并生成一个模型(Model)。
AlgoOperator:AlgoOperator 是一个阶段(Stage),用于编码通用多输入多输出计算逻辑。它实现了一个 transform() 方法,该方法将特定计算逻辑应用于给定输入Table,并返回结果Table列表。
转换器:转换器(Transformer)是具有语义差异的 AlgoOperator,它编码了转换逻辑,这样输出中的记录通常对应于输入中的一个记录。相比之下,AlgoOperator 更适合表达聚合逻辑,其中输出中的记录可以从输入中的任意数量的记录计算得出。
模型:模型(Model)是具有额外 API 用于设置和获取模型数据的转换器(Transformer)。它通常由在Table列表上拟合估算器(Estimator)生成。它提供了 getModelData() 和 setModelData(),允许用户显式地将模型数据表读取或写入转换器。每个Table都可以是无界的模型数据无界流。
典型的阶段(Stage)用法是首先创建一个估算器(Estimator)实例,通过调用其 fit() 方法触发其训练过程,并使用生成的模型(Model)实例进行预测。下面的代码示例了这种用法。
// 假设 SumModel 是 Model 的具体子类,SumEstimator 是 Estimator 的具体子类。
Table trainData = ...;
Table predictData = ...;
SumEstimator estimator = new SumEstimator();
SumModel model = estimator.fit(trainData);
Table predictResult = model.transform(predictData)[0];
构建器#
为了将 Flink ML 阶段组织成更复杂的格式以实现高级功能,例如将数据处理和机器学习算法链接在一起,Flink ML 提供了有助于管理 Flink 任务中阶段关系和结构的 API。这些 API 的入口包括 Pipeline 和 Graph。
管道#
Pipeline 充当 Estimator。它由有序阶段列表组成,每个阶段可以是 Estimator、Model、Transformer 或 AlgoOperator。其 fit() 方法按顺序遍历此管道的所有阶段,并在最后一个 Estimator(包括)之前的每个阶段执行以下操作。
如果一个阶段是 Estimator,它将使用输入表调用该阶段的 fit() 方法以生成 Model。如果在此阶段之后还有 Estimator,它将使用生成的 Model 转换输入表以获取结果表,然后将结果表作为输入传递给下一个阶段。
如果一个阶段是 AlgoOperator 且在此阶段之后有 Estimator,它将使用此阶段转换输入表以获取结果表,然后将结果表作为输入传递给下一个阶段。
在所有的 Estimators 都经过训练以适应其输入表之后,将使用与此管道中相同的阶段创建一个新的 PipelineModel,只是 PipelineModel 中的所有 Estimators 都被在上述过程中生成的模型替换。
PipelineModel 充当 Model。它由有序阶段列表组成,每个阶段可以是 Model、Transformer 或 AlgoOperator。其 transform() 方法按顺序将此 PipelineModel 中的所有阶段先应用于输入表。一个阶段的输出用作下一个阶段(如果有)的输入。最后一个阶段的输出作为此方法的结果返回。
可以通过将 Stages 列表传递给 Pipeline 的构造函数来创建 Pipeline。例如,
// 假设 SumModel 是 Model 的具体子类,SumEstimator 是 Estimator 的具体子类。
Model modelA = new SumModel().setModelData(tEnv.fromValues(10));
Estimator estimatorA = new SumEstimator();
Model modelB = new SumModel().setModelData(tEnv.fromValues(30));
List<Stage<?>> stages = Arrays.asList(modelA, estimatorA, modelB);
Estimator<?, ?> estimator = new Pipeline(stages);
以上命令创建了如下所示的管道。

编辑
添加图片注释,不超过 140 字(可选)
Graph#
AGraph充当估算器。AGraph由一个有向无环图(DAG)组成,每个阶段可以是估算器、模型、转换器或算法运算符(Estimator,Model,TransformerorAlgoOperator)。当调用Graph::fit时,按照拓扑排序顺序执行阶段。如果某个阶段是估算器,它的Estimator::fit方法将在输入Table(来自输入边)上调用,以适应模型。然后,该模型将用于转换输入表并生成输出表到输出边。如果某个阶段是算法运算符,那么其AlgoOperator::transform方法将在输入表上调用,并生成输出表到输出边。从AGraph拟合出的GraphModel由拟合的模型和算法运算符组成,对应于AGraph的阶段。
AGraphModel充当模型。AGraphModel由一个有向无环图(DAG)组成,每个阶段可以是估算器、模型、转换器或算法运算符。当调用GraphModel::transform时,按照拓扑排序顺序执行阶段。执行阶段时,将在输入表(来自输入边)上调用其AlgoOperator::transform方法,并生成输出表到输出边。
通过GraphBuilder类可以构建AGraph,它提供了如addAlgoOperator或addEstimator等方法来帮助向图中添加阶段。Flink ML还引入了TableId类来表示阶段的输入/输出,并帮助表示图中阶段之间的关系,从而允许用户在具体表可用之前构建DAG。
以下示例代码演示了如何构建AGraph。
// 假设 SumModel 是 Model 的具体子类。
GraphBuilder builder = new GraphBuilder();
// 创建节点。
SumModel stage1 = new SumModel().setModelData(tEnv.fromValues(1));
SumModel stage2 = new SumModel();
SumModel stage3 = new SumModel().setModelData(tEnv.fromValues(3));
// 创建输入和 modelDataInputs。
TableId input = builder.createTableId();
TableId modelDataInput = builder.createTableId();
// 输入数据并获取输出。
TableId output1 = builder.addAlgoOperator(stage1, input)[0];
TableId output2 = builder.addAlgoOperator(stage2, output1)[0];
builder.setModelDataOnModel(stage2, modelDataInput);
TableId output3 = builder.addAlgoOperator(stage3, output2)[0];
TableId modelDataOutput = builder.getModelDataFromModel(stage3)[0];
// 从图中构建模型。
TableId[] inputs = new TableId[] {input};
TableId[] outputs = new TableId[] {output3};
TableId[] modelDataInputs = new TableId[] {modelDataInput};
TableId[] modelDataOutputs = new TableId[] {modelDataOutput};
Model<?> model = builder.buildModel(inputs, outputs, modelDataInputs, modelDataOutputs);
上述代码构建了如下的AGraph。

编辑切换为居中
添加图片注释,不超过 140 字(可选)
参数#
Flink MLStage是WithParams的一个子类,它提供了一个统一的API来获取和设置参数。
Param是参数的定义,包括名称、类、描述、默认值和验证器(name, class, description,default value and the validator)。
为了设置算法的参数,用户可以使用以下任何一种方法。
调用参数的特定设置方法。例如,为了设置K-means算法的K值(聚类数目),用户可以直接在KMeans实例上调用setK()方法。
通过ParamUtils.updateExistingParams()方法将包含新值的参数映射传递给阶段。
如果一个Model是通过Estimator的fit()方法生成的,那么Model将继承Estimator对象的参数。因此,如果参数没有改变,就不需要再次设置参数。
迭代 #
迭代是机器学习库的基本构建块。在机器学习算法中,迭代可能用于离线或在线训练过程。通常需要两种类型的迭代,而Flink ML为了支持各种算法,支持这两种迭代。
有界迭代:通常用于离线情况。在这种情况下,算法通常在有界数据集上训练,更新多轮参数直到收敛。
无界迭代:通常用于在线情况,在这种情况下,算法通常在无界数据集上训练。它累积一小批数据,然后对参数进行一次更新。
迭代范式 #
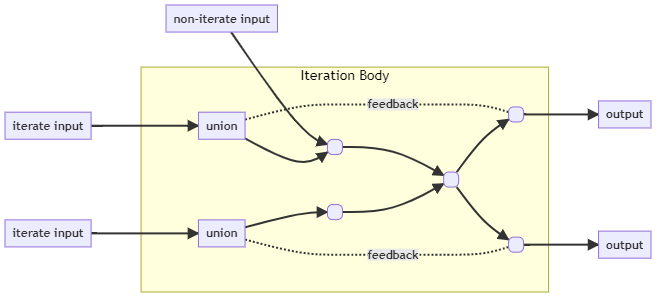
迭代算法具有以下行为模式:
迭代算法具有一个迭代主体,重复调用,直到达到某个终止条件(例如,达到用户指定的迭代次数)。迭代主体是一个算子子图,实现了例如迭代机器学习算法的计算逻辑,其输出可能被反馈作为该子图的输入。
在每次调用中,迭代主体根据用户提供的数据以及最新的模型参数更新模型参数。
迭代算法接受用户提供的数据和初始模型参数作为输入。
迭代算法可以输出任意用户定义的信息,如每个迭代的损失,或最终的模型参数。
因此,迭代算法的行为可以用以下迭代范式进行描述(关于Flink概念):
迭代主体是具有以下输入和输出的Flink子图:
输入:模型变量(作为数据流列表)和用户提供的数据(作为另一个数据流列表)
输出:反馈模型变量(作为数据流列表)和用户观察到的输出(作为数据流列表)
指定迭代主体的迭代执行何时终止的终止条件。
为了执行一个迭代主体,用户需要用以下输入执行迭代主体,并获得以下输出。
输入:初始模型变量(作为有界数据流列表)和用户提供的数据(作为数据流列表)
输出:迭代主体发出的用户观察到的输出。
需要注意的是,迭代主体期望的模型变量与用户提供的初始模型变量不同。相反,模型变量计算为反馈模型变量(由迭代主体发出)和初始模型变量(由迭代主体的调用者提供)的并集。Flink ML提供了实用类(参见Iterations),用于使用用户提供的输入运行迭代主体。
下图总结了上述描述的迭代范式。
编辑切换为居中
添加图片注释,不超过 140 字(可选)
API #
Flink ML迭代的主入口位于Iterations类中。它主要提供两个公共方法,用户可以根据输入数据是有界还是无界来选择使用其中一个。
public class Iterations {
public static DataStreamList iterateUnboundedStreams(
DataStreamList initVariableStreams, DataStreamList dataStreams, IterationBody body) {...}
...
public static DataStreamList iterateBoundedStreamsUntilTermination(
DataStreamList initVariableStreams,
ReplayableDataStreamList dataStreams,
IterationConfig config,
IterationBody body){...}
}
要构建一个迭代,用户需要提供:
initVariableStreams:每轮更新的变量数据流的初始值。
dataStreams:在迭代过程中使用的其他数据流,但不会更新。
iterationBody:指定更新变量流和输出的子图。
IterationBody将使用两个参数调用:第一个参数是输入变量流列表,它是初始变量流和相应的反馈变量流(由迭代主体返回)的并集;第二个参数是提供给此方法的数据流。
public interface IterationBody extends Serializable {
...
IterationBodyResult process(DataStreamList variableStreams, DataStreamList dataStreams);
...
}
在迭代主体的执行过程中,参与迭代的每个记录都附加了一个标记迭代进度的epoch。epoch的计算方式为:
初始变量流和初始数据流中的所有记录的epoch为0。
对于由此运算符发射到非反馈流的任何记录,发射记录的epoch=触发此发射的输入记录的epoch。如果此记录是由onEpochWatermarkIncremented()发射的,那么此记录的epoch=epochWatermark。
对于由此运算符发射到反馈变量流的任何记录,发射记录的epoch=触发此发射的输入记录的epoch+1。
在每个epoch结束时,框架会向实现IterationListener的运算符和UDF发送通知。
public interface IterationListener<T> {
void onEpochWatermarkIncremented(int epochWatermark, Context context, Collector<T> collector)
throws Exception;
...
void onIterationTerminated(Context context, Collector<T> collector) throws Exception;
}
示例用法
# 利用迭代的示例代码如下。
Example Usage #
Example codes of utilizing iterations is as below。
DataStream<double[]> initParameters = ...
DataStream<Tuple2<double[], Double>> dataset = ...
DataStreamList resultStreams = Iterations.iterateUnboundedStreams(
DataStreamList.of(initParameters),
ReplayableDataStreamList.notReplay(dataset),
IterationConfig.newBuilder().setOperatorRoundMode(ALL_ROUND).build();
(variableStreams, dataStreams) -> {
DataStream<double[]> modelUpdate = variableStreams.get(0);
DataStream<Tuple2<double[], Double>> dataset = dataStreams.get(0);
DataStream<double[]> newModelUpdate = ...
DataStream<double[]> modelOutput = ...
return new IterationBodyResult(
DataStreamList.of(newModelUpdate),
DataStreamList.of(modelOutput)
});
DataStream<double[]> finalModel = resultStreams.get("final_model");
initParameters:需要通过反馈边传输的输入数据。
dataset:不需要通过反馈边传输的输入数据。
newModelUpdate:需要通过反馈边传输的数据。
modelOutput:迭代主体的最终输出。
数据类型
# Flink ML 支持 Flink Table API 所支持的所有数据类型,以及下面部分中列出的数据类型。
向量
# Flink ML 提供对双精度值向量的支持。Flink ML 中的向量可以是密集(DenseVector)或稀疏(SparseVector),具体取决于用户根据向量的稀疏度创建它们的方式。
每个向量都以固定大小初始化,用户可以获取或设置向量中任何基于 0 的索引位置的双精度值。
Flink ML 还有一个名为 Vectors 的类,提供实例化向量的实用方法。
# 从 Python 列表或数字中创建一个 64 位浮点数的密集向量。
>>> Vectors.dense([1, 2, 3])
DenseVector([1.0, 2.0, 3.0])
>>> Vectors.dense(1.0, 2.0)
DenseVector([1.0, 2.0])
# 创建一个稀疏向量,可以使用字典、(索引, 值) 对的列表或两个分离的索引和值数组。
>>> Vectors.sparse(4, {1: 1.0, 3: 5.5})
SparseVector(4, {1: 1.0, 3: 5.5})
>>> Vectors.sparse(4, [(1, 1.0), (3, 5.5)])
SparseVector(4, {1: 1.0, 3: 5.5})
>>> Vectors.sparse(4, [1, 3], [1.0, 5.5])
SparseVector(4, {1: 1.0, 3: 5.5})
Java
int n = 4;
int[] indices = new int[] {0, 2, 3};
double[] values = new double[] {0.1, 0.3, 0.4};
SparseVector vector = Vectors.sparse(n, indices, values);
从源代码构建和安装Flink ML #
本页面介绍了如何从源代码构建和安装Flink ML。
构建和安装Java SDK #
为了构建Flink ML,您需要源代码。可以下载某个版本的源代码,或者克隆git仓库。
此外,您还需要Maven 3和一个JDK(Java开发工具包)。Flink ML的构建至少需要Java 8。
要从git克隆,请输入:
git clone https://github.com/apache/flink-ml.git
构建Flink ML的最简单方法是运行:
mvn clean install -DskipTests
这个指令告诉Maven(mvn)首先删除所有现有的构建(clean),然后创建一个新的Flink ML二进制文件(install)。
在构建完成后,您可以从Flink ML的根目录获取以下路径中的构建结果:
./flink-ml-dist/target/flink-ml--bin/flink-ml/
mvn clean install命令会将二进制文件安装到您的本地Maven仓库,以便其他项目可以引用它并从仓库获取。安装过程不需要其他额外步骤。
构建和安装Python SDK #
先决条件 #
构建Flink ML Java SDK
如果您想构建可用于pip安装的Flink ML的Python SDK,您必须先按照上面的章节描述构建Java SDK。
需要Python版本(3.6、3.7或3.8)
$ python --version
这里打印的版本必须是3.6、3.7或3.8
使用以下命令安装依赖项:
$ python -m pip install -r flink-ml-python/dev/dev-requirements.txt
安装 #
然后转到Flink ML源代码的根目录,并运行此命令以构建apache-flink-ml的sdist包:
cd flink-ml-python; python setup.py sdist; cd ..;
apache-flink-ml的sdist包将位于./flink-ml-python/dist/目录下。可以按照以下方式安装:
python -m pip install flink-ml-python/dist/*.tar.gz
KNN #
K 最近邻(KNN)是一种分类算法。KNN的基本假设是,如果提供样本的最近的 K 个邻居中的大部分属于同一标签,那么该样本很可能也属于该标签。
输入列 #
参数名称 类型 默认值 描述

编辑
添加图片注释,不超过 140 字(可选)
输出列 #
参数名称 类型 默认值 描述

编辑
添加图片注释,不超过 140 字(可选)
参数 #
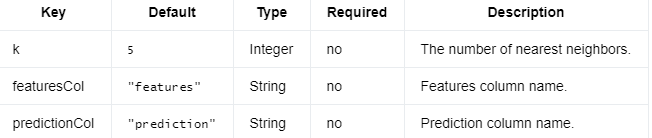
以下是 KnnModel 所需的参数。
键 默认值 类型 必需 描述
编辑切换为居中
添加图片注释,不超过 140 字(可选)
Knn 还需要以下参数。
键 默认值 类型 必需 描述

编辑
添加图片注释,不超过 140 字(可选)
示例 #
Java
import org.apache.flink.ml.classification.knn.Knn;
import org.apache.flink.ml.classification.knn.KnnModel;
import org.apache.flink.ml.linalg.DenseVector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
/** 简单的程序,用于训练 KNN 模型并将其用于分类。. */
public class KnnExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// 生成输入训练和预测数据。
DataStream<Row> trainStream =
env.fromElements(
Row.of(Vectors.dense(2.0, 3.0), 1.0),
Row.of(Vectors.dense(2.1, 3.1), 1.0),
Row.of(Vectors.dense(200.1, 300.1), 2.0),
Row.of(Vectors.dense(200.2, 300.2), 2.0),
Row.of(Vectors.dense(200.3, 300.3), 2.0),
Row.of(Vectors.dense(200.4, 300.4), 2.0),
Row.of(Vectors.dense(200.4, 300.4), 2.0),
Row.of(Vectors.dense(200.6, 300.6), 2.0),
Row.of(Vectors.dense(2.1, 3.1), 1.0),
Row.of(Vectors.dense(2.1, 3.1), 1.0),
Row.of(Vectors.dense(2.1, 3.1), 1.0),
Row.of(Vectors.dense(2.1, 3.1), 1.0),
Row.of(Vectors.dense(2.3, 3.2), 1.0),
Row.of(Vectors.dense(2.3, 3.2), 1.0),
Row.of(Vectors.dense(2.8, 3.2), 3.0),
Row.of(Vectors.dense(300., 3.2), 4.0),
Row.of(Vectors.dense(2.2, 3.2), 1.0),
Row.of(Vectors.dense(2.4, 3.2), 5.0),
Row.of(Vectors.dense(2.5, 3.2), 5.0),
Row.of(Vectors.dense(2.5, 3.2), 5.0),
Row.of(Vectors.dense(2.1, 3.1), 1.0));
Table trainTable = tEnv.fromDataStream(trainStream).as("features", "label");
DataStream<Row> predictStream =
env.fromElements(
Row.of(Vectors.dense(4.0, 4.1), 5.0), Row.of(Vectors.dense(300, 42), 2.0));
Table predictTable = tEnv.fromDataStream(predictStream).as("features", "label");
// 创建 KNN 对象并初始化其参数。
Knn knn = new Knn().setK(4);
// 训练 KNN 模型。
KnnModel knnModel = knn.fit(trainTable);
//使用 KNN 模型进行预测。
Table outputTable = knnModel.transform(predictTable)[0];
// 提取并显示结果。
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
DenseVector features = (DenseVector) row.getField(knn.getFeaturesCol());
double expectedResult = (Double) row.getField(knn.getLabelCol());
double predictionResult = (Double) row.getField(knn.getPredictionCol());
System.out.printf(
"Features: %-15s \tExpected Result: %s \tPrediction Result: %s\n",
features, expectedResult, predictionResult);
}
}
}
Python
# 简单的程序,用于训练 KNN 模型并将其用于分类。
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.linalg import Vectors, DenseVectorTypeInfo
from pyflink.ml.classification.knn import KNN
from pyflink.table import StreamTableEnvironment
# 创建一个新的 StreamExecutionEnvironment。
env = StreamExecutionEnvironment.get_execution_environment()
# 创建一个 StreamTableEnvironment。
t_env = StreamTableEnvironment.create(env)
#生成输入训练和预测数据。
train_data = t_env.from_data_stream(
env.from_collection([
(Vectors.dense([2.0, 3.0]), 1.0),
(Vectors.dense([2.1, 3.1]), 1.0),
(Vectors.dense([200.1, 300.1]), 2.0),
(Vectors.dense([200.2, 300.2]), 2.0),
(Vectors.dense([200.3, 300.3]), 2.0),
(Vectors.dense([200.4, 300.4]), 2.0),
(Vectors.dense([200.4, 300.4]), 2.0),
(Vectors.dense([200.6, 300.6]), 2.0),
(Vectors.dense([2.1, 3.1]), 1.0),
(Vectors.dense([2.1, 3.1]), 1.0),
(Vectors.dense([2.1, 3.1]), 1.0),
(Vectors.dense([2.1, 3.1]), 1.0),
(Vectors.dense([2.3, 3.2]), 1.0),
(Vectors.dense([2.3, 3.2]), 1.0),
(Vectors.dense([2.8, 3.2]), 3.0),
(Vectors.dense([300., 3.2]), 4.0),
(Vectors.dense([2.2, 3.2]), 1.0),
(Vectors.dense([2.4, 3.2]), 5.0),
(Vectors.dense([2.5, 3.2]), 5.0),
(Vectors.dense([2.5, 3.2]), 5.0),
(Vectors.dense([2.1, 3.1]), 1.0)
],
type_info=Types.ROW_NAMED(
['features', 'label'],
[DenseVectorTypeInfo(), Types.DOUBLE()])))
predict_data = t_env.from_data_stream(
env.from_collection([
(Vectors.dense([4.0, 4.1]), 5.0),
(Vectors.dense([300, 42]), 2.0),
],
type_info=Types.ROW_NAMED(
['features', 'label'],
[DenseVectorTypeInfo(), Types.DOUBLE()])))
# 创建 KNN 对象并初始化其参数。
knn = KNN().set_k(4)
# 训练 KNN 模型。
model = knn.fit(train_data)
# 使用 KNN 模型进行预测。
output = model.transform(predict_data)[0]
# 提取并显示结果。
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
features = result[field_names.index(knn.get_features_col())]
expected_result = result[field_names.index(knn.get_label_col())]
actual_result = result[field_names.index(knn.get_prediction_col())]
print('Features: ' + str(features) + ' \tExpected Result: ' + str(expected_result)
+ ' \tActual Result: ' + str(actual_result))
线性支持向量机 #
线性支持向量机(Linear SVC)是一种算法,它试图找到一个超平面来最大化分类样本之间的距离。
输入列 #
编辑
添加图片注释,不超过 140 字(可选)
输出列 #
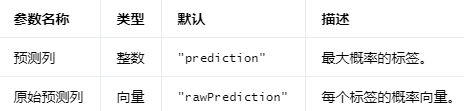
编辑
添加图片注释,不超过 140 字(可选)
参数 #
以下是LinearSVCModel.
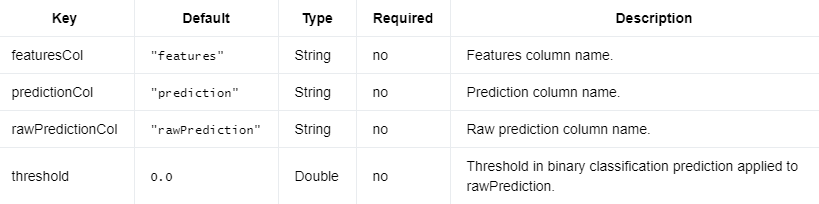
编辑切换为居中
添加图片注释,不超过 140 字(可选)

编辑
添加图片注释,不超过 140 字(可选)
LinearSVC需要上面和下面的参数。
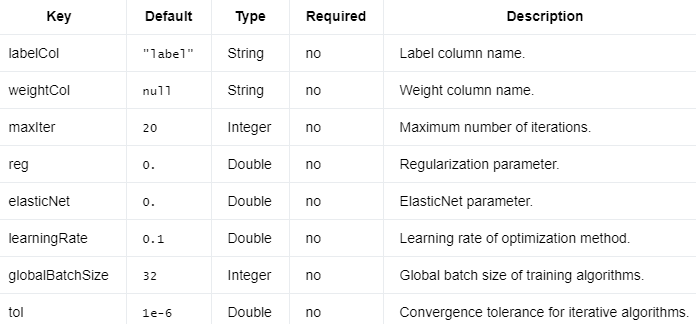
编辑切换为居中
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.classification.linearsvc.LinearSVC;
import org.apache.flink.ml.classification.linearsvc.LinearSVCModel;
import org.apache.flink.ml.linalg.DenseVector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
/** 简单的程序,用于训练 LinearSVC 模型并将其用于分类。 */
public class LinearSVCExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
DataStream<Row> inputStream =
env.fromElements(
Row.of(Vectors.dense(1, 2, 3, 4), 0., 1.),
Row.of(Vectors.dense(2, 2, 3, 4), 0., 2.),
Row.of(Vectors.dense(3, 2, 3, 4), 0., 3.),
Row.of(Vectors.dense(4, 2, 3, 4), 0., 4.),
Row.of(Vectors.dense(5, 2, 3, 4), 0., 5.),
Row.of(Vectors.dense(11, 2, 3, 4), 1., 1.),
Row.of(Vectors.dense(12, 2, 3, 4), 1., 2.),
Row.of(Vectors.dense(13, 2, 3, 4), 1., 3.),
Row.of(Vectors.dense(14, 2, 3, 4), 1., 4.),
Row.of(Vectors.dense(15, 2, 3, 4), 1., 5.));
Table inputTable = tEnv.fromDataStream(inputStream).as("features", "label", "weight");
// 创建 LinearSVC 对象并初始化其参数。
LinearSVC linearSVC = new LinearSVC().setWeightCol("weight");
// Trains the LinearSVC Model.
LinearSVCModel linearSVCModel = linearSVC.fit(inputTable);
// Uses the LinearSVC Model for predictions.
Table outputTable = linearSVCModel.transform(inputTable)[0];
// 提取并显示结果。
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
DenseVector features = (DenseVector) row.getField(linearSVC.getFeaturesCol());
double expectedResult = (Double) row.getField(linearSVC.getLabelCol());
double predictionResult = (Double) row.getField(linearSVC.getPredictionCol());
DenseVector rawPredictionResult =
(DenseVector) row.getField(linearSVC.getRawPredictionCol());
System.out.printf(
"Features: %-25s \tExpected Result: %s \tPrediction Result: %s \tRaw Prediction Result: %s\n",
features, expectedResult, predictionResult, rawPredictionResult);
}
}
}
Python
#简单的程序,用于训练 LinearSVC 模型并将其用于分类。
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.linalg import Vectors, DenseVectorTypeInfo
from pyflink.ml.classification.linearsvc import LinearSVC
from pyflink.table import StreamTableEnvironment
# create a new StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# create a StreamTableEnvironment
t_env = StreamTableEnvironment.create(env)
# generate input data
input_table = t_env.from_data_stream(
env.from_collection([
(Vectors.dense([1, 2, 3, 4]), 0., 1.),
(Vectors.dense([2, 2, 3, 4]), 0., 2.),
(Vectors.dense([3, 2, 3, 4]), 0., 3.),
(Vectors.dense([4, 2, 3, 4]), 0., 4.),
(Vectors.dense([5, 2, 3, 4]), 0., 5.),
(Vectors.dense([11, 2, 3, 4]), 1., 1.),
(Vectors.dense([12, 2, 3, 4]), 1., 2.),
(Vectors.dense([13, 2, 3, 4]), 1., 3.),
(Vectors.dense([14, 2, 3, 4]), 1., 4.),
(Vectors.dense([15, 2, 3, 4]), 1., 5.),
],
type_info=Types.ROW_NAMED(
['features', 'label', 'weight'],
[DenseVectorTypeInfo(), Types.DOUBLE(), Types.DOUBLE()])
))
# 创建 LinearSVC 对象并初始化其参数。
linear_svc = LinearSVC().set_weight_col('weight')
# train the linear svc model
model = linear_svc.fit(input_table)
# 使用 LinearSVC 模型进行预测。
output = model.transform(input_table)[0]
# 提取并显示结果。
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
features = result[field_names.index(linear_svc.get_features_col())]
expected_result = result[field_names.index(linear_svc.get_label_col())]
prediction_result = result[field_names.index(linear_svc.get_prediction_col())]
raw_prediction_result = result[field_names.index(linear_svc.get_raw_prediction_col())]
print('Features: ' + str(features) + ' \tExpected Result: ' + str(expected_result)
+ ' \tPrediction Result: ' + str(prediction_result)
+ ' \tRaw Prediction Result: ' + str(raw_prediction_result))
Logistic Regression #
Logistic regression is a special case of the Generalized Linear Model. It is widely used to predict a binary response.
Input Columns #
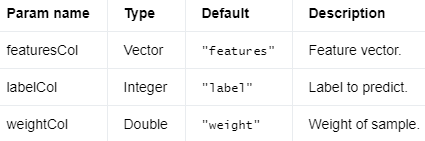
编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑切换为居中
添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
参数 #
以下是LogisticRegressionModel.
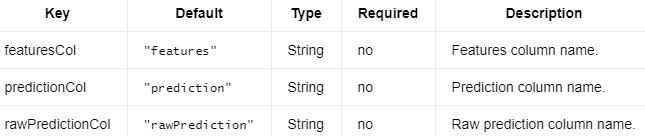
编辑切换为居中
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
LogisticRegression需要上面和下面的参数。
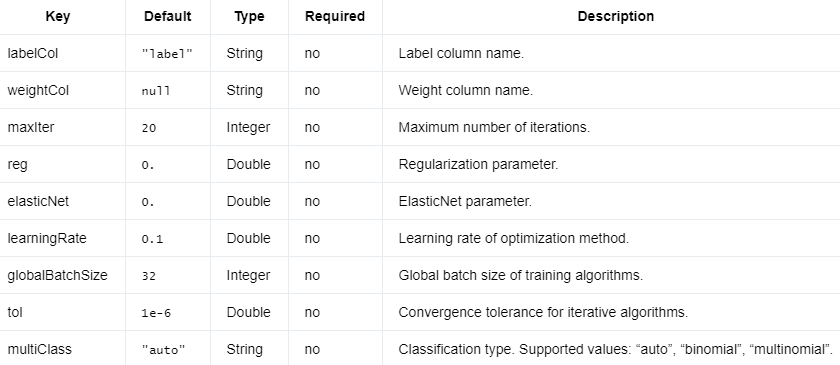
编辑切换为居中
添加图片注释,不超过 140 字(可选)

编辑
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.classification.logisticregression.LogisticRegression;
import org.apache.flink.ml.classification.logisticregression.LogisticRegressionModel;
import org.apache.flink.ml.linalg.DenseVector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
/** 简单的程序,用于训练 LogisticRegression 模型并将其用于分类。 */
public class LogisticRegressionExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
DataStream<Row> inputStream =
env.fromElements(
Row.of(Vectors.dense(1, 2, 3, 4), 0., 1.),
Row.of(Vectors.dense(2, 2, 3, 4), 0., 2.),
Row.of(Vectors.dense(3, 2, 3, 4), 0., 3.),
Row.of(Vectors.dense(4, 2, 3, 4), 0., 4.),
Row.of(Vectors.dense(5, 2, 3, 4), 0., 5.),
Row.of(Vectors.dense(11, 2, 3, 4), 1., 1.),
Row.of(Vectors.dense(12, 2, 3, 4), 1., 2.),
Row.of(Vectors.dense(13, 2, 3, 4), 1., 3.),
Row.of(Vectors.dense(14, 2, 3, 4), 1., 4.),
Row.of(Vectors.dense(15, 2, 3, 4), 1., 5.));
Table inputTable = tEnv.fromDataStream(inputStream).as("features", "label", "weight");
// 创建 LogisticRegression 对象并初始化其参数。
LogisticRegression lr = new LogisticRegression().setWeightCol("weight");
// Trains the LogisticRegression Model.
LogisticRegressionModel lrModel = lr.fit(inputTable);
// Uses the LogisticRegression Model for predictions.
Table outputTable = lrModel.transform(inputTable)[0];
// 提取并显示结果。
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
DenseVector features = (DenseVector) row.getField(lr.getFeaturesCol());
double expectedResult = (Double) row.getField(lr.getLabelCol());
double predictionResult = (Double) row.getField(lr.getPredictionCol());
DenseVector rawPredictionResult = (DenseVector) row.getField(lr.getRawPredictionCol());
System.out.printf(
"Features: %-25s \tExpected Result: %s \tPrediction Result: %s \tRaw Prediction Result: %s\n",
features, expectedResult, predictionResult, rawPredictionResult);
}
}
}
在线逻辑回归 #
在线逻辑回归支持在无限制的训练数据流上训练在线回归模型。
该算法的在线优化器是H.Brendan McMahan等人提出的The FTRL-Proximal。参见H. Brendan McMahan 等人,广告点击预测:实战观察。
https://dl.acm.org/doi/10.1145/2487575.2488200
输入列 #
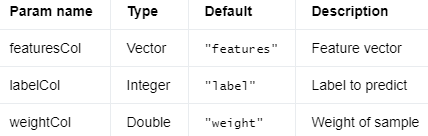
编辑
添加图片注释,不超过 140 字(可选)
输出列 #

编辑切换为居中
添加图片注释,不超过 140 字(可选)
编辑
添加图片注释,不超过 140 字(可选)
参数 #
以下是OnlineLogisticRegressionModel.
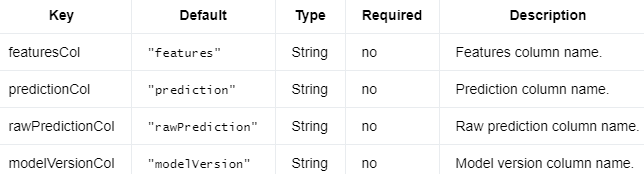
编辑切换为居中
添加图片注释,不超过 140 字(可选)
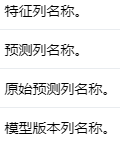
添加图片注释,不超过 140 字(可选)
OnlineLogisticRegression需要上面和下面的参数。
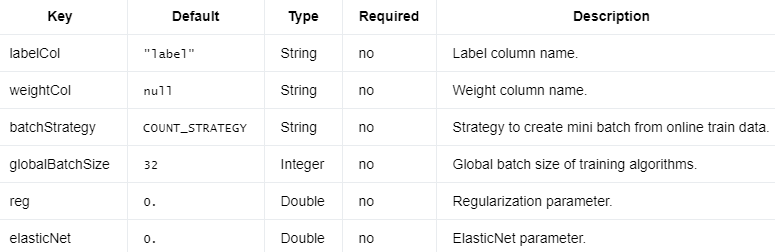
编辑切换为居中
添加图片注释,不超过 140 字(可选)
编辑
添加图片注释,不超过 140 字(可选)
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.typeutils.RowTypeInfo;
import org.apache.flink.ml.classification.logisticregression.OnlineLogisticRegression;
import org.apache.flink.ml.classification.logisticregression.OnlineLogisticRegressionModel;
import org.apache.flink.ml.examples.util.PeriodicSourceFunction;
import org.apache.flink.ml.linalg.DenseVector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.ml.linalg.typeinfo.DenseVectorTypeInfo;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
/** 简单的程序,用于训练 OnlineLogisticRegression 模型并将其用于分类。 */
public class OnlineLogisticRegressionExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// 生成输入训练和预测数据。它们都是周期性的无限流。
// 发送提供的数据以触发模型更新和预测。
List<Row> trainData1 =
Arrays.asList(
Row.of(Vectors.dense(0.1, 2.), 0.),
Row.of(Vectors.dense(0.2, 2.), 0.),
Row.of(Vectors.dense(0.3, 2.), 0.),
Row.of(Vectors.dense(0.4, 2.), 0.),
Row.of(Vectors.dense(0.5, 2.), 0.),
Row.of(Vectors.dense(11., 12.), 1.),
Row.of(Vectors.dense(12., 11.), 1.),
Row.of(Vectors.dense(13., 12.), 1.),
Row.of(Vectors.dense(14., 12.), 1.),
Row.of(Vectors.dense(15., 12.), 1.));
List<Row> trainData2 =
Arrays.asList(
Row.of(Vectors.dense(0.2, 3.), 0.),
Row.of(Vectors.dense(0.8, 1.), 0.),
Row.of(Vectors.dense(0.7, 1.), 0.),
Row.of(Vectors.dense(0.6, 2.), 0.),
Row.of(Vectors.dense(0.2, 2.), 0.),
Row.of(Vectors.dense(14., 17.), 1.),
Row.of(Vectors.dense(15., 10.), 1.),
Row.of(Vectors.dense(16., 16.), 1.),
Row.of(Vectors.dense(17., 10.), 1.),
Row.of(Vectors.dense(18., 13.), 1.));
List<Row> predictData =
Arrays.asList(
Row.of(Vectors.dense(0.8, 2.7), 0.0),
Row.of(Vectors.dense(15.5, 11.2), 1.0));
RowTypeInfo typeInfo =
new RowTypeInfo(
new TypeInformation[] {DenseVectorTypeInfo.INSTANCE, Types.DOUBLE},
new String[] {"features", "label"});
SourceFunction<Row> trainSource =
new PeriodicSourceFunction(1000, Arrays.asList(trainData1, trainData2));
DataStream<Row> trainStream = env.addSource(trainSource, typeInfo);
Table trainTable = tEnv.fromDataStream(trainStream).as("features");
SourceFunction<Row> predictSource =
new PeriodicSourceFunction(1000, Collections.singletonList(predictData));
DataStream<Row> predictStream = env.addSource(predictSource, typeInfo);
Table predictTable = tEnv.fromDataStream(predictStream).as("features");
// 创建在线 LogisticRegression 对象并初始化其参数和初始值。
// model data.
Row initModelData = Row.of(Vectors.dense(0.41233679404769874, -0.18088118293232122), 0L);
Table initModelDataTable = tEnv.fromDataStream(env.fromElements(initModelData));
OnlineLogisticRegression olr =
new OnlineLogisticRegression()
.setFeaturesCol("features")
.setLabelCol("label")
.setPredictionCol("prediction")
.setReg(0.2)
.setElasticNet(0.5)
.setGlobalBatchSize(10)
.setInitialModelData(initModelDataTable);
// Trains the online LogisticRegression Model.
OnlineLogisticRegressionModel onlineModel = olr.fit(trainTable);
// Uses the online LogisticRegression Model for predictions.
Table outputTable = onlineModel.transform(predictTable)[0];
// 提取并显示结果。随着训练数据流持续触发模型的更新,预测结果也会不断改变。
// 更新内部模型数据,同样预测数据集的原始预测结果也会更新。
// 随着时间的推移,将会发生变化。
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
DenseVector features = (DenseVector) row.getField(olr.getFeaturesCol());
Double expectedResult = (Double) row.getField(olr.getLabelCol());
Double predictionResult = (Double) row.getField(olr.getPredictionCol());
DenseVector rawPredictionResult = (DenseVector) row.getField(olr.getRawPredictionCol());
System.out.printf(
"Features: %-25s \tExpected Result: %s \tPrediction Result: %s \tRaw Prediction Result: %s\n",
features, expectedResult, predictionResult, rawPredictionResult);
}
}
}
朴素贝叶斯 #
朴素贝叶斯是一个多类分类器。基于贝叶斯定理,它假设每对特征之间存在强(朴素)独立性。
输入列 #

编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
参数 #
以下是NaiveBayesModel.

编辑切换为居中
添加图片注释,不超过 140 字(可选)
编辑
添加图片注释,不超过 140 字(可选)
NaiveBayes需要上面和下面的参数。

编辑
添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.classification.naivebayes.NaiveBayes;
import org.apache.flink.ml.classification.naivebayes.NaiveBayesModel;
import org.apache.flink.ml.linalg.DenseVector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
/** 简单的程序,用于训练 NaiveBayes 模型并将其用于分类。 */
public class NaiveBayesExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// 生成输入训练和预测数据。
DataStream<Row> trainStream =
env.fromElements(
Row.of(Vectors.dense(0, 0.), 11),
Row.of(Vectors.dense(1, 0), 10),
Row.of(Vectors.dense(1, 1.), 10));
Table trainTable = tEnv.fromDataStream(trainStream).as("features", "label");
DataStream<Row> predictStream =
env.fromElements(
Row.of(Vectors.dense(0, 1.)),
Row.of(Vectors.dense(0, 0.)),
Row.of(Vectors.dense(1, 0)),
Row.of(Vectors.dense(1, 1.)));
Table predictTable = tEnv.fromDataStream(predictStream).as("features");
// 创建 NaiveBayes 对象并初始化其参数。
NaiveBayes naiveBayes =
new NaiveBayes()
.setSmoothing(1.0)
.setFeaturesCol("features")
.setLabelCol("label")
.setPredictionCol("prediction")
.setModelType("multinomial");
// Trains the NaiveBayes Model.
NaiveBayesModel naiveBayesModel = naiveBayes.fit(trainTable);
// Uses the NaiveBayes Model for predictions.
Table outputTable = naiveBayesModel.transform(predictTable)[0];
// 提取并显示结果。
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
DenseVector features = (DenseVector) row.getField(naiveBayes.getFeaturesCol());
double predictionResult = (Double) row.getField(naiveBayes.getPredictionCol());
System.out.printf("Features: %s \tPrediction Result: %s\n", features, predictionResult);
}
}
}
Python
# 简单的程序,用于训练 NaiveBayes 模型并将其用于分类。
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.linalg import Vectors, DenseVectorTypeInfo
from pyflink.ml.classification.naivebayes import NaiveBayes
from pyflink.table import StreamTableEnvironment
# create a new StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# create a StreamTableEnvironment
t_env = StreamTableEnvironment.create(env)
# generate input training and prediction data
train_table = t_env.from_data_stream(
env.from_collection([
(Vectors.dense([0, 0.]), 11.),
(Vectors.dense([1, 0]), 10.),
(Vectors.dense([1, 1.]), 10.),
],
type_info=Types.ROW_NAMED(
['features', 'label'],
[DenseVectorTypeInfo(), Types.DOUBLE()])))
predict_table = t_env.from_data_stream(
env.from_collection([
(Vectors.dense([0, 1.]),),
(Vectors.dense([0, 0.]),),
(Vectors.dense([1, 0]),),
(Vectors.dense([1, 1.]),),
],
type_info=Types.ROW_NAMED(
['features'],
[DenseVectorTypeInfo()])))
# 创建 NaiveBayes 对象并初始化其参数。
naive_bayes = NaiveBayes() \
.set_smoothing(1.0) \
.set_features_col('features') \
.set_label_col('label') \
.set_prediction_col('prediction') \
.set_model_type('multinomial')
# train the naive bayes model
model = naive_bayes.fit(train_table)
# use the naive bayes model for predictions
output = model.transform(predict_table)[0]
# 提取并显示结果。
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
features = result[field_names.index(naive_bayes.get_features_col())]
prediction_result = result[field_names.index(naive_bayes.get_prediction_col())]
print('Features: ' + str(features) + ' \tPrediction Result: ' + str(prediction_result))
Agglomerative Clustering(凝聚层次聚类)是一种层次聚类方法,用于将相似的数据点聚集在一起,形成簇(cluster)。它是一种自底向上的聚类方法,开始时将每个数据点视为一个独立的簇,然后逐步合并最相似(距离最近)的簇,直到达到某个终止条件,如指定的簇的数量或距离阈值。
凝聚层次聚类的主要步骤如下:
初始化:将每个数据点作为一个独立的簇。
计算簇间距离:使用某种度量方法(如欧氏距离、曼哈顿距离等)计算所有簇之间的距离。
合并簇:找到距离最近的两个簇,并将它们合并为一个新的簇。
更新距离:重新计算新簇与其他簇之间的距离。
重复步骤3和4,直到满足终止条件。
凝聚层次聚类的关键在于如何计算簇之间的距离。有几种常用的方法,如单连接法(最小距离法)、全连接法(最大距离法)、平均连接法(平均距离法)和Ward法(最小方差法)等。
这种聚类方法的优点是可以生成树状图(dendrogram),方便可视化和解释。然而,它的缺点是计算复杂度较高,不适合处理大规模数据集。
Agglomerative Clustering(凝聚层次聚类)和K-means聚类是两种不同的聚类方法,它们在原理、过程和特性上有一些区别。
原理:凝聚层次聚类是一种自底向上的层次聚类方法,从单个数据点开始逐步合并最相似的簇。而K-means聚类是一种基于中心点的划分聚类方法,通过迭代优化中心点位置来划分簇。
簇的形状:凝聚层次聚类可以识别并处理非球形簇,而K-means聚类通常更适合处理球形簇。
聚类数量:在凝聚层次聚类中,可以通过截断树状图来确定簇的数量,这为确定最佳聚类数量提供了一定的灵活性。而在K-means聚类中,需要事先指定簇的数量,这可能需要尝试不同的K值来找到最佳聚类效果。
运行时间:凝聚层次聚类的计算复杂度较高,不适合处理大规模数据集。相比之下,K-means聚类的计算复杂度相对较低,适合处理大规模数据集。
可视化:凝聚层次聚类可以生成树状图(dendrogram),便于可视化和解释聚类结果。而K-means聚类没有类似的可视化方法。
确定性:凝聚层次聚类的结果是确定的,不受初始化影响。而K-means聚类的结果可能受到初始化中心点的影响,有时需要多次运行以获得较好的聚类效果。
AgglomerativeClustering 使用自下而上的方法执行层次聚类。每个观察都从它自己的集群开始,然后这些集群被一个接一个地合并在一起。
输出包含两个表。第一个为每个数据点分配一个集群 ID。第二个包含在每一步合并两个集群的信息。合并信息的数据格式为(clusterId1, clusterId2, distance, sizeOfMergedCluster)。
Input Columns #

编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
参数 #
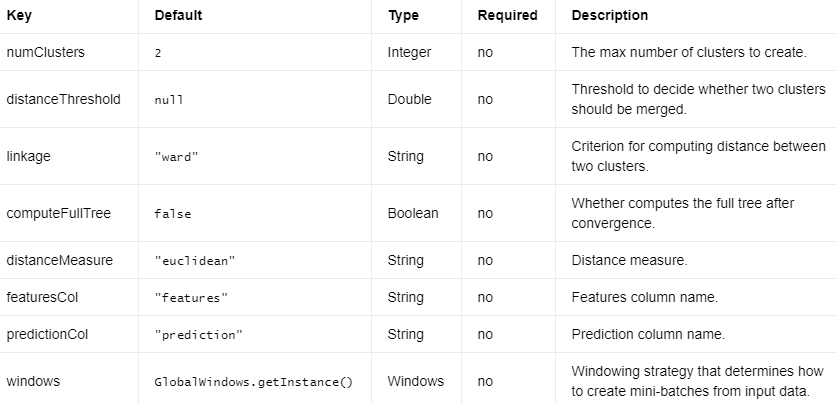
编辑切换为居中
添加图片注释,不超过 140 字(可选)

编辑
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.clustering.agglomerativeclustering.AgglomerativeClustering;
import org.apache.flink.ml.clustering.agglomerativeclustering.AgglomerativeClusteringParams;
import org.apache.flink.ml.common.distance.EuclideanDistanceMeasure;
import org.apache.flink.ml.linalg.DenseVector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
/** 简单的程序,用于创建 AgglomerativeClustering 实例并将其用于聚类。. */
public class AgglomerativeClusteringExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
DataStream<DenseVector> inputStream =
env.fromElements(
Vectors.dense(1, 1),
Vectors.dense(1, 4),
Vectors.dense(1, 0),
Vectors.dense(4, 1.5),
Vectors.dense(4, 4),
Vectors.dense(4, 0));
Table inputTable = tEnv.fromDataStream(inputStream).as("features");
// 创建 AgglomerativeClustering 对象并初始化其参数。
AgglomerativeClustering agglomerativeClustering =
new AgglomerativeClustering()
.setLinkage(AgglomerativeClusteringParams.LINKAGE_WARD)
.setDistanceMeasure(EuclideanDistanceMeasure.NAME)
.setPredictionCol("prediction");
// Uses the AgglomerativeClustering object for clustering.
Table[] outputs = agglomerativeClustering.transform(inputTable);
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputs[0].execute().collect(); it.hasNext(); ) {
Row row = it.next();
DenseVector features =
(DenseVector) row.getField(agglomerativeClustering.getFeaturesCol());
int clusterId = (Integer) row.getField(agglomerativeClustering.getPredictionCol());
System.out.printf("Features: %s \tCluster ID: %s\n", features, clusterId);
}
}
}
Python
# 简单的程序,用于创建 AgglomerativeClustering 实例并将其用于聚类。
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.linalg import Vectors, DenseVectorTypeInfo
from pyflink.ml.clustering.agglomerativeclustering import AgglomerativeClustering
from pyflink.table import StreamTableEnvironment
from matplotlib import pyplot as plt
from scipy.cluster.hierarchy import dendrogram
# Creates a new StreamExecutionEnvironment.
env = StreamExecutionEnvironment.get_execution_environment()
# Creates a StreamTableEnvironment.
t_env = StreamTableEnvironment.create(env)
# Generates input data.
input_data = t_env.from_data_stream(
env.from_collection([
(Vectors.dense([1, 1]),),
(Vectors.dense([1, 4]),),
(Vectors.dense([1, 0]),),
(Vectors.dense([4, 1.5]),),
(Vectors.dense([4, 4]),),
(Vectors.dense([4, 0]),),
],
type_info=Types.ROW_NAMED(
['features'],
[DenseVectorTypeInfo()])))
# 创建 AgglomerativeClustering 对象并初始化其参数。
agglomerative_clustering = AgglomerativeClustering() \
.set_linkage('ward') \
.set_distance_measure('euclidean') \
.set_prediction_col('prediction')
# Uses the AgglomerativeClustering for clustering.
outputs = agglomerative_clustering.transform(input_data)
# 提取并显示聚类结果。
field_names = outputs[0].get_schema().get_field_names()
for result in t_env.to_data_stream(outputs[0]).execute_and_collect():
features = result[field_names.index(agglomerative_clustering.features_col)]
cluster_id = result[field_names.index(agglomerative_clustering.prediction_col)]
print('Features: ' + str(features) + '\tCluster ID: ' + str(cluster_id))
# 可视化合并信息。
merge_info = [result for result in
t_env.to_data_stream(outputs[1]).execute_and_collect()]
plt.title("Agglomerative Clustering Dendrogram")
dendrogram(merge_info)
plt.xlabel("Index of data point.")
plt.ylabel("Distances between merged clusters.")
plt.show()
K-means #
K-means 是一种常用的聚类算法。它将给定的数据点分组到预定义数量的集群中。
输入列 #

编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
参数 #
以下是KMeansModel.
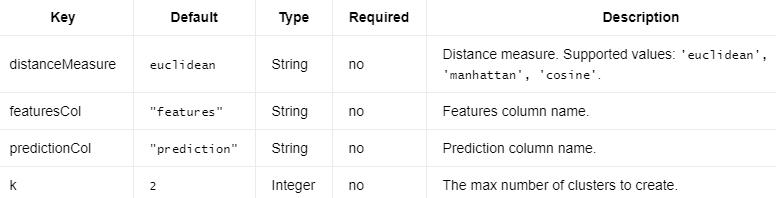
编辑切换为居中
添加图片注释,不超过 140 字(可选)
编辑
添加图片注释,不超过 140 字(可选)
KMeans需要上面和下面的参数。

编辑切换为居中
添加图片注释,不超过 140 字(可选)

编辑
添加图片注释,不超过 140 字(可选)
例子 #
Java
import org.apache.flink.ml.clustering.kmeans.KMeans;
import org.apache.flink.ml.clustering.kmeans.KMeansModel;
import org.apache.flink.ml.linalg.DenseVector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
/** 简单的程序,用于训练 KMeans 模型并将其用于聚类。 */
public class KMeansExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
DataStream<DenseVector> inputStream =
env.fromElements(
Vectors.dense(0.0, 0.0),
Vectors.dense(0.0, 0.3),
Vectors.dense(0.3, 0.0),
Vectors.dense(9.0, 0.0),
Vectors.dense(9.0, 0.6),
Vectors.dense(9.6, 0.0));
Table inputTable = tEnv.fromDataStream(inputStream).as("features");
// 创建 KMeans 对象并初始化其参数。
KMeans kmeans = new KMeans().setK(2).setSeed(1L);
// Trains the K-means Model.
KMeansModel kmeansModel = kmeans.fit(inputTable);
// Uses the K-means Model for predictions.
Table outputTable = kmeansModel.transform(inputTable)[0];
// 提取并显示结果。
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
DenseVector features = (DenseVector) row.getField(kmeans.getFeaturesCol());
int clusterId = (Integer) row.getField(kmeans.getPredictionCol());
System.out.printf("Features: %s \tCluster ID: %s\n", features, clusterId);
}
}
}
Python
# 简单的程序,用于训练 KMeans 模型并将其用于聚类。
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.linalg import Vectors, DenseVectorTypeInfo
from pyflink.ml.clustering.kmeans import KMeans
from pyflink.table import StreamTableEnvironment
# create a new StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# create a StreamTableEnvironment
t_env = StreamTableEnvironment.create(env)
# generate input data
input_data = t_env.from_data_stream(
env.from_collection([
(Vectors.dense([0.0, 0.0]),),
(Vectors.dense([0.0, 0.3]),),
(Vectors.dense([0.3, 3.0]),),
(Vectors.dense([9.0, 0.0]),),
(Vectors.dense([9.0, 0.6]),),
(Vectors.dense([9.6, 0.0]),),
],
type_info=Types.ROW_NAMED(
['features'],
[DenseVectorTypeInfo()])))
# 创建 KMeans 对象并初始化其参数。
kmeans = KMeans().set_k(2).set_seed(1)
# train the kmeans model
model = kmeans.fit(input_data)
# use the kmeans model for predictions
output = model.transform(input_data)[0]
# 提取并显示结果。
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
features = result[field_names.index(kmeans.get_features_col())]
cluster_id = result[field_names.index(kmeans.get_prediction_col())]
print('Features: ' + str(features) + ' \tCluster Id: ' + str(cluster_id))
在线 K 均值 #
Online K-Means 扩展了 K-Means 的功能,支持根据无界的训练数据流连续训练 K-Means 模型。
在线 K-Means 使用“小批量”K-Means 规则进行更新,一般化以包含健忘 forgetfulness (即衰减)。在获得当前批次的估计质心后,Online K-Means 根据原始质心和估计质心之间的加权平均值计算新质心。估计质心的权重是分配给它们的点数。原始质心的权重也是点数,但额外乘以衰减因子。
衰减因子缩放了迄今为止估计的集群的贡献。如果衰减因子为 1,则所有批次的权重相同。如果衰减因子为 0,则新质心完全由最近的数据确定。较低的值对应更多的遗忘。
Input Columns #

编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
参数 #
以下是OnlineKMeansModel.
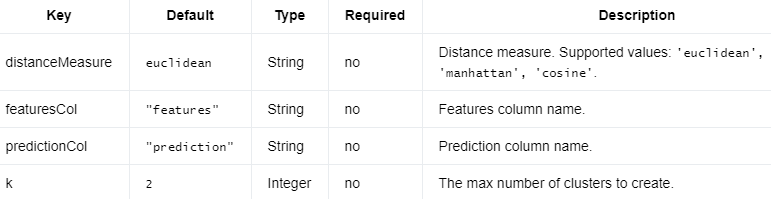
编辑切换为居中
添加图片注释,不超过 140 字(可选)
编辑
添加图片注释,不超过 140 字(可选)
OnlineKMeans需要上面和下面的参数。
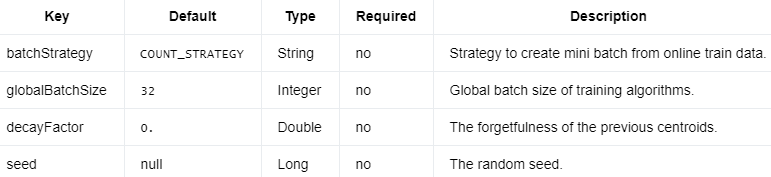
编辑切换为居中
添加图片注释,不超过 140 字(可选)
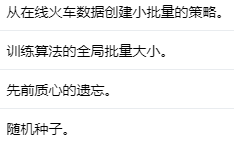
编辑
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.api.java.typeutils.RowTypeInfo;
import org.apache.flink.ml.clustering.kmeans.KMeansModelData;
import org.apache.flink.ml.clustering.kmeans.OnlineKMeans;
import org.apache.flink.ml.clustering.kmeans.OnlineKMeansModel;
import org.apache.flink.ml.examples.util.PeriodicSourceFunction;
import org.apache.flink.ml.linalg.DenseVector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.ml.linalg.typeinfo.DenseVectorTypeInfo;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
import java.util.Objects;
/** 简单的程序,用于训练 OnlineKMeans 模型并将其用于聚类。 */
public class OnlineKMeansExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// 生成输入训练和预测数据。它们都是周期性的无限流。
// 发送提供的数据以触发模型更新和预测。
List<Row> trainData1 =
Arrays.asList(
Row.of(Vectors.dense(0.0, 0.0)),
Row.of(Vectors.dense(0.0, 0.3)),
Row.of(Vectors.dense(0.3, 0.0)),
Row.of(Vectors.dense(9.0, 0.0)),
Row.of(Vectors.dense(9.0, 0.6)),
Row.of(Vectors.dense(9.6, 0.0)));
List<Row> trainData2 =
Arrays.asList(
Row.of(Vectors.dense(10.0, 100.0)),
Row.of(Vectors.dense(10.0, 100.3)),
Row.of(Vectors.dense(10.3, 100.0)),
Row.of(Vectors.dense(-10.0, -100.0)),
Row.of(Vectors.dense(-10.0, -100.6)),
Row.of(Vectors.dense(-10.6, -100.0)));
List<Row> predictData =
Arrays.asList(
Row.of(Vectors.dense(10.0, 10.0)), Row.of(Vectors.dense(-10.0, 10.0)));
SourceFunction<Row> trainSource =
new PeriodicSourceFunction(1000, Arrays.asList(trainData1, trainData2));
DataStream<Row> trainStream =
env.addSource(trainSource, new RowTypeInfo(DenseVectorTypeInfo.INSTANCE));
Table trainTable = tEnv.fromDataStream(trainStream).as("features");
SourceFunction<Row> predictSource =
new PeriodicSourceFunction(1000, Collections.singletonList(predictData));
DataStream<Row> predictStream =
env.addSource(predictSource, new RowTypeInfo(DenseVectorTypeInfo.INSTANCE));
Table predictTable = tEnv.fromDataStream(predictStream).as("features");
// 创建在线 KMeans 对象并初始化其参数和初始模型数据。
OnlineKMeans onlineKMeans =
new OnlineKMeans()
.setFeaturesCol("features")
.setPredictionCol("prediction")
.setGlobalBatchSize(6)
.setInitialModelData(
KMeansModelData.generateRandomModelData(tEnv, 2, 2, 0.0, 0));
// Trains the online K-means Model.
OnlineKMeansModel onlineModel = onlineKMeans.fit(trainTable);
// Uses the online K-means Model for predictions.
Table outputTable = onlineModel.transform(predictTable)[0];
// 提取并显示结果。随着训练数据流持续触发内部 k-means 模型数据的更新,同样预测数据集的聚类结果也会随着时间的推移而改变。
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row1 = it.next();
DenseVector features1 = (DenseVector) row1.getField(onlineKMeans.getFeaturesCol());
Integer clusterId1 = (Integer) row1.getField(onlineKMeans.getPredictionCol());
Row row2 = it.next();
DenseVector features2 = (DenseVector) row2.getField(onlineKMeans.getFeaturesCol());
Integer clusterId2 = (Integer) row2.getField(onlineKMeans.getPredictionCol());
if (Objects.equals(clusterId1, clusterId2)) {
System.out.printf("%s and %s are now in the same cluster.\n", features1, features2);
} else {
System.out.printf(
"%s and %s are now in different clusters.\n", features1, features2);
}
}
}
}
二元分类评估器(Binary Classification Evaluator)是一种评估机器学习模型在二元分类问题上性能的方法。在二元分类问题中,目标是预测一个实例属于两个类别(通常表示为0和1,或者正类和负类)中的哪一个。评估器用于衡量模型预测的准确性和其他性能指标。
常用的评估指标包括:
准确率(Accuracy):正确分类的实例占总实例数的比例。它是一个简单直观的评价指标,但在类别不平衡的情况下可能会产生误导。
精确度(Precision):真正例(TP)占所有被预测为正例的实例(TP + FP)的比例。这个指标关注的是模型预测为正类的样本中实际为正类的比例。
召回率(Recall):真正例(TP)占所有实际为正例的实例(TP + FN)的比例。这个指标关注的是模型能找到多少实际为正类的样本。
F1分数(F1 Score):精确度和召回率的调和平均值。它是一个综合指标,用于在精确度和召回率之间平衡。
AUC-ROC(Area Under the Receiver Operating Characteristic curve):ROC曲线下的面积,ROC曲线是以真正例率(TPR)为纵坐标、假正例率(FPR)为横坐标绘制的曲线。AUC值越接近1,模型性能越好。
二元分类评估器计算二元分类的评估指标。输入数据有rawPrediction、label和一个可选的权重列。rawPrediction可以是双精度类型(二进制 0/1 预测,或标签 1 的概率)或向量类型(原始预测、分数或标签概率的长度为 2 的向量)。输出可能包含参数定义的不同指标MetricsNames。
Input Columns #
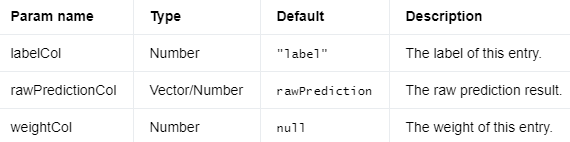
编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑切换为居中
添加图片注释,不超过 140 字(可选)
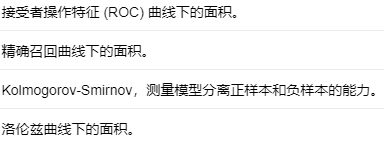
编辑
添加图片注释,不超过 140 字(可选)
参数 #
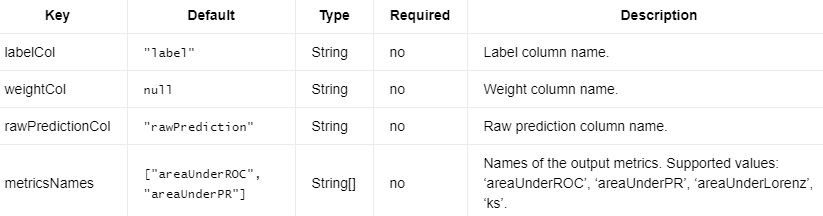
编辑切换为居中
添加图片注释,不超过 140 字(可选)

编辑
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.evaluation.binaryclassification.BinaryClassificationEvaluator;
import org.apache.flink.ml.evaluation.binaryclassification.BinaryClassificationEvaluatorParams;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
/** 简单的程序,用于创建 BinaryClassificationEvaluator 实例并将其用于评估。 */
public class BinaryClassificationEvaluatorExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
DataStream<Row> inputStream =
env.fromElements(
Row.of(1.0, Vectors.dense(0.1, 0.9)),
Row.of(1.0, Vectors.dense(0.2, 0.8)),
Row.of(1.0, Vectors.dense(0.3, 0.7)),
Row.of(0.0, Vectors.dense(0.25, 0.75)),
Row.of(0.0, Vectors.dense(0.4, 0.6)),
Row.of(1.0, Vectors.dense(0.35, 0.65)),
Row.of(1.0, Vectors.dense(0.45, 0.55)),
Row.of(0.0, Vectors.dense(0.6, 0.4)),
Row.of(0.0, Vectors.dense(0.7, 0.3)),
Row.of(1.0, Vectors.dense(0.65, 0.35)),
Row.of(0.0, Vectors.dense(0.8, 0.2)),
Row.of(1.0, Vectors.dense(0.9, 0.1)));
Table inputTable = tEnv.fromDataStream(inputStream).as("label", "rawPrediction");
// 创建 BinaryClassificationEvaluator 对象并初始化其参数。
BinaryClassificationEvaluator evaluator =
new BinaryClassificationEvaluator()
.setMetricsNames(
BinaryClassificationEvaluatorParams.AREA_UNDER_PR,
BinaryClassificationEvaluatorParams.KS,
BinaryClassificationEvaluatorParams.AREA_UNDER_ROC);
// 使用 BinaryClassificationEvaluator 对象进行评估。
Table outputTable = evaluator.transform(inputTable)[0];
// 提取并显示结果。
Row evaluationResult = outputTable.execute().collect().next();
System.out.printf(
"Area under the precision-recall curve: %s\n",
evaluationResult.getField(BinaryClassificationEvaluatorParams.AREA_UNDER_PR));
System.out.printf(
"Area under the receiver operating characteristic curve: %s\n",
evaluationResult.getField(BinaryClassificationEvaluatorParams.AREA_UNDER_ROC));
System.out.printf(
"Kolmogorov-Smirnov value: %s\n",
evaluationResult.getField(BinaryClassificationEvaluatorParams.KS));
}
}
Python
# 简单的程序,创建 BinaryClassificationEvaluator 实例并使用其进行评估。
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.linalg import Vectors, DenseVectorTypeInfo
from pyflink.ml.evaluation.binaryclassification import BinaryClassificationEvaluator
from pyflink.table import StreamTableEnvironment
# create a new StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# create a StreamTableEnvironment
t_env = StreamTableEnvironment.create(env)
# generate input data
input_table = t_env.from_data_stream(
env.from_collection([
(1.0, Vectors.dense(0.1, 0.9)),
(1.0, Vectors.dense(0.2, 0.8)),
(1.0, Vectors.dense(0.3, 0.7)),
(0.0, Vectors.dense(0.25, 0.75)),
(0.0, Vectors.dense(0.4, 0.6)),
(1.0, Vectors.dense(0.35, 0.65)),
(1.0, Vectors.dense(0.45, 0.55)),
(0.0, Vectors.dense(0.6, 0.4)),
(0.0, Vectors.dense(0.7, 0.3)),
(1.0, Vectors.dense(0.65, 0.35)),
(0.0, Vectors.dense(0.8, 0.2)),
(1.0, Vectors.dense(0.9, 0.1))
],
type_info=Types.ROW_NAMED(
['label', 'rawPrediction'],
[Types.DOUBLE(), DenseVectorTypeInfo()]))
)
# 创建 BinaryClassificationEvaluator 对象并初始化其参数。
evaluator = BinaryClassificationEvaluator() \
.set_metrics_names('areaUnderPR', 'ks', 'areaUnderROC')
# 使用 BinaryClassificationEvaluator 模型进行评估。
output = evaluator.transform(input_table)[0]
# 提取并显示结果。
field_names = output.get_schema().get_field_names()
result = t_env.to_data_stream(output).execute_and_collect().next()
print('Area under the precision-recall curve: '
+ str(result[field_names.index('areaUnderPR')]))
print('Area under the receiver operating characteristic curve: '
+ str(result[field_names.index('areaUnderROC')]))
print('Kolmogorov-Smirnov value: '
+ str(result[field_names.index('ks')]))
Binarizer(二值化器)是一种数据预处理方法,用于将数值特征转换为二进制形式。通过设定一个阈值,二值化器可以将输入特征值映射到0或1,通常表示为负类和正类。当特征值大于或等于阈值时,它被映射为1(正类);当特征值小于阈值时,它被映射为0(负类)。
二值化器常用于以下场景:
数据预处理:对于某些机器学习算法,特征的数值范围可能对模型性能产生影响。二值化可以将特征简化为二进制形式,从而降低模型复杂性。
特征工程:有时我们可能需要将连续值特征转换为离散值或类别特征,以便在特定算法中使用。二值化可以实现这一目标。
文本处理:在自然语言处理中,二值化器可以用于创建词袋模型(bag-of-words model),其中文本数据被表示为一个二进制向量,表示单词是否出现在给定文本中。
需要注意的是,二值化会丢失原始特征中的部分信息,因此在实际应用中需要根据任务和算法的特点来选择合适的预处理方法。
词袋模型(Bag-of-Words model,简称BoW)是自然语言处理和信息检索领域中一种简单但实用的文本表示方法。它将文本看作是一个词汇集合,忽略了语法和词序,仅关注文本中词汇的出现频率。
具体来说,词袋模型首先对整个文本数据集构建一个词汇表,然后将每个文本表示为一个与词汇表等长的向量。向量中的每个元素表示该词汇在文本中出现的次数。因此,词袋模型将文本转换为一个高维稀疏向量,其中每个维度对应于词汇表中的一个词汇。
词袋模型的优势在于其简单易实现,同时可以直接应用于许多文本挖掘任务,例如文本分类、聚类和情感分析等。然而,由于它忽略了语法和词序信息,因此可能损失掉一部分与语义相关的信息。为了克服这一缺陷,研究人员开发了其他更复杂的文本表示方法,如词嵌入(word embeddings)和序列模型(sequence models)。
二值化器 #
二值化器通过给定的阈值对连续特征的列进行二值化。连续特征可以是DenseVector(稠密向量)、SparseVector(稀疏向量)和Numerical Value(数值)。
Input Columns #

编辑
添加图片注释,不超过 140 字(可选)
要二值化的数字/向量。
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
Parameters #

编辑切换为居中
添加图片注释,不超过 140 字(可选)
编辑
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.feature.binarizer.Binarizer;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
import java.util.Arrays;
/** 简单的程序,用于创建 Binarizer 实例并将其用于特征工程。 */
public class BinarizerExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
DataStream<Row> inputStream =
env.fromElements(
Row.of(
1,
Vectors.dense(1, 2),
Vectors.sparse(
17, new int[] {0, 3, 9}, new double[] {1.0, 2.0, 7.0})),
Row.of(
2,
Vectors.dense(2, 1),
Vectors.sparse(
17, new int[] {0, 2, 14}, new double[] {5.0, 4.0, 1.0})),
Row.of(
3,
Vectors.dense(5, 18),
Vectors.sparse(
17, new int[] {0, 11, 12}, new double[] {2.0, 4.0, 4.0})));
Table inputTable = tEnv.fromDataStream(inputStream).as("f0", "f1", "f2");
// 创建 Binarizer 对象并初始化其参数。
Binarizer binarizer =
new Binarizer()
.setInputCols("f0", "f1", "f2")
.setOutputCols("of0", "of1", "of2")
.setThresholds(0.0, 0.0, 0.0);
// Transforms input data.
Table outputTable = binarizer.transform(inputTable)[0];
// 提取并显示结果。
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
Object[] inputValues = new Object[binarizer.getInputCols().length];
Object[] outputValues = new Object[binarizer.getInputCols().length];
for (int i = 0; i < inputValues.length; i++) {
inputValues[i] = row.getField(binarizer.getInputCols()[i]);
outputValues[i] = row.getField(binarizer.getOutputCols()[i]);
}
System.out.printf(
"Input Values: %s\tOutput Values: %s\n",
Arrays.toString(inputValues), Arrays.toString(outputValues));
}
}
}
Python
# 简单的程序,用于创建 Binarizer 实例并将其用于特征工程。
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.linalg import Vectors, DenseVectorTypeInfo
from pyflink.ml.feature.binarizer import Binarizer
from pyflink.table import StreamTableEnvironment
# create a new StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# create a StreamTableEnvironment
t_env = StreamTableEnvironment.create(env)
# generate input data
input_data_table = t_env.from_data_stream(
env.from_collection([
(1,
Vectors.dense(3, 4)),
(2,
Vectors.dense(6, 2))
],
type_info=Types.ROW_NAMED(
['f0', 'f1'],
[Types.INT(), DenseVectorTypeInfo()])))
# 创建 Binarizer 对象并初始化其参数。
binarizer = Binarizer() \
.set_input_cols('f0', 'f1') \
.set_output_cols('of0', 'of1') \
.set_thresholds(1.5, 3.5)
# 使用 Binarizer 进行特征工程。
output = binarizer.transform(input_data_table)[0]
# 提取并显示结果。
field_names = output.get_schema().get_field_names()
input_values = [None for _ in binarizer.get_input_cols()]
output_values = [None for _ in binarizer.get_output_cols()]
for result in t_env.to_data_stream(output).execute_and_collect():
for i in range(len(binarizer.get_input_cols())):
input_values[i] = result[field_names.index(binarizer.get_input_cols()[i])]
output_values[i] = result[field_names.index(binarizer.get_output_cols()[i])]
print('Input Values: ' + str(input_values) + '\tOutput Values: ' + str(output_values))
Bucketizer(桶化器)是一种数据预处理方法,用于将连续数值特征转换为离散的桶(buckets)或区间。桶化器通过预定义的分割点(splits)将数值特征划分为不同的区间。每个区间通常被赋予一个整数标签,表示特征值属于哪个区间。
Bucketizer的工作原理如下:
定义分割点:分割点是用来划分区间的一组数值。例如,分割点为[-∞, 0, 1, +∞]时,将数据划分为三个区间:(-∞, 0)、[0, 1)和[1, +∞)。
转换数据:将每个特征值映射到对应的区间,并用该区间的标签替换原始值。例如,对于上述分割点,特征值-1.5将映射到区间(-∞, 0),被替换为0;特征值0.5将映射到区间[0, 1),被替换为1。
桶化器常用于以下场景:
数据预处理:某些机器学习算法(如决策树和朴素贝叶斯)更适合处理离散特征。桶化器可以将连续特征转换为离散特征,使这些算法更容易处理。
特征工程:桶化器可以创建更高层次的抽象特征,有助于揭示数据中的潜在模式。例如,将年龄划分为不同的年龄段(如儿童、青少年、成年人和老年人)可以更好地捕捉年龄对目标变量的影响。
数据可视化:桶化器有助于创建直方图,以便更直观地查看数据分布和中心趋势。
需要注意的是,桶化过程可能会丢失原始特征中的部分信息,因此在实际应用中需要根据任务和算法的特点来选择合适的预处理方法。
分桶器 #
Bucketizer是一种将多列连续特征映射到多列离散特征的算法,即buckets indices。索引位于 [0, numSplitsInThisColumn - 1] 中。
输入列 #

编辑
添加图片注释,不超过 140 字(可选)
要分桶的连续特征。
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
离散化特征。
Parameters #

编辑切换为居中
添加图片注释,不超过 140 字(可选)
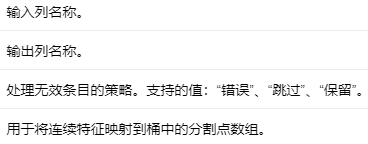
编辑
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.common.param.HasHandleInvalid;
import org.apache.flink.ml.feature.bucketizer.Bucketizer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
import java.util.Arrays;
/** 简单的程序,用于创建 Bucketizer 实例并将其用于特征工程。 */
public class BucketizerExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
DataStream<Row> inputStream = env.fromElements(Row.of(-0.5, 0.0, 1.0, 0.0));
Table inputTable = tEnv.fromDataStream(inputStream).as("f1", "f2", "f3", "f4");
// 创建 Bucketizer 对象并初始化其参数。.
Double[][] splitsArray =
new Double[][] {
new Double[] {-0.5, 0.0, 0.5},
new Double[] {-1.0, 0.0, 2.0},
new Double[] {Double.NEGATIVE_INFINITY, 10.0, Double.POSITIVE_INFINITY},
new Double[] {Double.NEGATIVE_INFINITY, 1.5, Double.POSITIVE_INFINITY}
};
Bucketizer bucketizer =
new Bucketizer()
.setInputCols("f1", "f2", "f3", "f4")
.setOutputCols("o1", "o2", "o3", "o4")
.setSplitsArray(splitsArray)
.setHandleInvalid(HasHandleInvalid.SKIP_INVALID);
// 使用 Bucketizer 对象进行特征转换。
Table outputTable = bucketizer.transform(inputTable)[0];
// 提取并显示结果。
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
double[] inputValues = new double[bucketizer.getInputCols().length];
double[] outputValues = new double[bucketizer.getInputCols().length];
for (int i = 0; i < inputValues.length; i++) {
inputValues[i] = (double) row.getField(bucketizer.getInputCols()[i]);
outputValues[i] = (double) row.getField(bucketizer.getOutputCols()[i]);
}
System.out.printf(
"Input Values: %s\tOutput Values: %s\n",
Arrays.toString(inputValues), Arrays.toString(outputValues));
}
}
}
Python
# 简单的程序,用于创建 Bucketizer 实例并将其用于特征工程。
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.feature.bucketizer import Bucketizer
from pyflink.table import StreamTableEnvironment
# create a new StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# create a StreamTableEnvironment
t_env = StreamTableEnvironment.create(env)
# generate input data
input_data = t_env.from_data_stream(
env.from_collection([
(-0.5, 0.0, 1.0, 0.0),
],
type_info=Types.ROW_NAMED(
['f1', 'f2', 'f3', 'f4'],
[Types.DOUBLE(), Types.DOUBLE(), Types.DOUBLE(), Types.DOUBLE()])
))
# 创建 Bucketizer 对象并初始化其参数。
splits_array = [
[-0.5, 0.0, 0.5],
[-1.0, 0.0, 2.0],
[float('-inf'), 10.0, float('inf')],
[float('-inf'), 1.5, float('inf')],
]
bucketizer = Bucketizer() \
.set_input_cols('f1', 'f2', 'f3', 'f4') \
.set_output_cols('o1', 'o2', 'o3', 'o4') \
.set_splits_array(splits_array)
# 使用 Bucketizer 模型进行特征工程。
output = bucketizer.transform(input_data)[0]
# extract and display the results
field_names = output.get_schema().get_field_names()
input_values = [None for _ in bucketizer.get_input_cols()]
output_values = [None for _ in bucketizer.get_input_cols()]
for result in t_env.to_data_stream(output).execute_and_collect():
for i in range(len(bucketizer.get_input_cols())):
input_values[i] = result[field_names.index(bucketizer.get_input_cols()[i])]
output_values[i] = result[field_names.index(bucketizer.get_output_cols()[i])]
print('Input Values: ' + str(input_values) + '\tOutput Values: ' + str(output_values))
CountVectorizer(计数向量化器)是一种用于处理文本数据的方法,将文本数据转换为特征向量,以便在机器学习模型中使用。它主要用于创建词袋模型(Bag-of-Words model),将文本表示为单词出现次数的向量。词袋模型不考虑单词顺序,仅关注单词在文本中的出现频率。
CountVectorizer的工作流程如下:
分词(Tokenization):将文本分解为单词(tokens)或其他基本文本单位(如n-grams)。
构建词汇表(Vocabulary):基于训练数据集创建一个词汇表,包含所有出现的单词。
向量化(Vectorization):将每个文本转换为一个向量,向量的长度等于词汇表的大小。每个向量的元素表示对应单词在文本中出现的次数。
例如,假设有以下两个文本:
文本1: "I love machine learning."
文本2: "Machine learning is great."
分词后,构建的词汇表为:["I", "love", "machine", "learning", "is", "great"]。
使用CountVectorizer,两个文本的向量表示分别为:
文本1: [1, 1, 1, 1, 0, 0]
文本2: [0, 0, 1, 1, 1, 1]
在这里,向量的每个元素表示词汇表中对应单词在文本中出现的次数。
CountVectorizer通常用于文本分类、聚类、主题建模等自然语言处理任务中。需要注意的是,词袋模型不能捕捉上下文信息和单词之间的关系,因此在处理复杂文本问题时可能不够准确。针对这类问题,可以使用词嵌入(Word Embeddings)等更先进的文本表示方法。
计数向量器 #
CountVectorizer 是一种将文本文档集合转换为标记计数向量的算法。当先验字典不可用时,可以使用 CountVectorizer 作为估计器来提取词汇,并生成 CountVectorizerModel。该模型在词汇表上为文档生成稀疏表示,然后可以将其传递给其他算法,如 LDA。
LDA(Latent Dirichlet Allocation,潜在狄利克雷分布)是一种生成式概率统计模型,主要应用于自然语言处理和主题建模领域。LDA的目标是在给定的文档集合中发现潜在主题,其中每个主题表示为一组相关词汇的概率分布。通过这种方式,LDA可以为每个文档分配一个主题分布,为每个主题分配一个词汇分布,从而使我们能够了解文档的主题结构和内容。
LDA的基本假设是,文档是由多个主题组合而成的,而主题是由多个词汇组合而成的。LDA使用狄利克雷分布(Dirichlet distribution)作为先验概率分布,来描述文档-主题分布和主题-词汇分布。
LDA模型的训练过程通常使用吉布斯抽样(Gibbs sampling)或变分贝叶斯方法(Variational Bayes methods)等近似推断技术进行。训练完成后,LDA可以为新文档分配主题分布,从而实现文档分类、聚类或推荐等任务。
值得注意的是,尽管LDA在许多场景中取得了成功,但它也有一些局限性。例如,LDA忽略了词汇之间的语法和语序信息,可能导致损失一些语义信息。此外,LDA需要事先设定主题数量,这可能需要对数据有一定的领域知识。为了克服这些问题,研究人员也提出了其他主题模型,如结构化主题模型(Structured Topic Models)和神经网络主题模型(Neural Topic Models)等。
输入列 #

编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
令牌计数向量。
参数 #
以下是CountVectorizerModel.
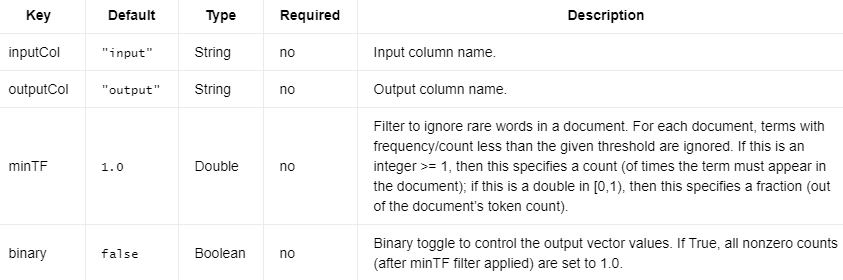
编辑切换为居中
添加图片注释,不超过 140 字(可选)

编辑切换为居中
添加图片注释,不超过 140 字(可选)
CountVectorizer需要上面和下面的参数。
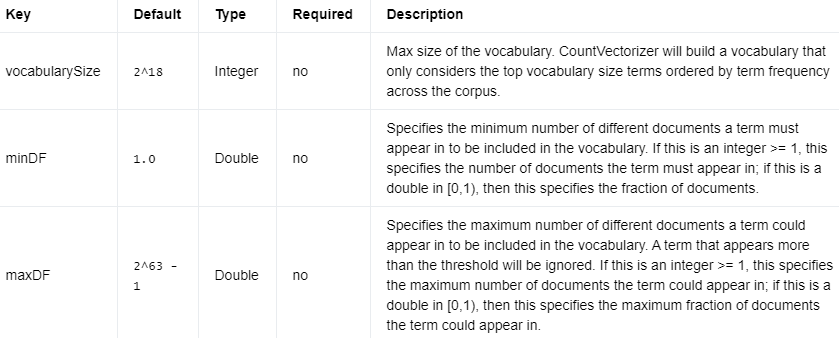
编辑切换为居中
添加图片注释,不超过 140 字(可选)

编辑切换为居中
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.feature.countvectorizer.CountVectorizer;
import org.apache.flink.ml.feature.countvectorizer.CountVectorizerModel;
import org.apache.flink.ml.linalg.SparseVector;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
import java.util.Arrays;
/**
* 简单的程序,用于训练 CountVectorizer 模型并将其用于特征工程。
*/
public class CountVectorizerExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input training and prediction data.
DataStream<Row> dataStream =
env.fromElements(
Row.of((Object) new String[] {"a", "c", "b", "c"}),
Row.of((Object) new String[] {"c", "d", "e"}),
Row.of((Object) new String[] {"a", "b", "c"}),
Row.of((Object) new String[] {"e", "f"}),
Row.of((Object) new String[] {"a", "c", "a"}));
Table inputTable = tEnv.fromDataStream(dataStream).as("input");
// 创建 CountVectorizer 对象并初始化其参数。
CountVectorizer countVectorizer = new CountVectorizer();
// Trains the CountVectorizer model
CountVectorizerModel model = countVectorizer.fit(inputTable);
// Uses the CountVectorizer model for predictions.
Table outputTable = model.transform(inputTable)[0];
// 提取并显示结果。
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
String[] inputValue = (String[]) row.getField(countVectorizer.getInputCol());
SparseVector outputValue = (SparseVector) row.getField(countVectorizer.getOutputCol());
System.out.printf(
"Input Value: %-15s \tOutput Value: %s\n",
Arrays.toString(inputValue), outputValue.toString());
}
}
}
Python
# 简单的程序,用于创建 CountVectorizer 实例并将其用于特征工程。
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.feature.countvectorizer import CountVectorizer
from pyflink.table import StreamTableEnvironment
# Creates a new StreamExecutionEnvironment.
env = StreamExecutionEnvironment.get_execution_environment()
# Creates a StreamTableEnvironment.
t_env = StreamTableEnvironment.create(env)
# Generates input training and prediction data.
input_table = t_env.from_data_stream(
env.from_collection([
(1, ['a', 'c', 'b', 'c'],),
(2, ['c', 'd', 'e'],),
(3, ['a', 'b', 'c'],),
(4, ['e', 'f'],),
(5, ['a', 'c', 'a'],),
],
type_info=Types.ROW_NAMED(
['id', 'input', ],
[Types.INT(), Types.OBJECT_ARRAY(Types.STRING())])
))
# 创建 CountVectorizer 对象并初始化其参数。
count_vectorizer = CountVectorizer()
# Trains the CountVectorizer Model.
model = count_vectorizer.fit(input_table)
# Uses the CountVectorizer Model for predictions.
output = model.transform(input_table)[0]
# 提取并显示结果。
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
input_index = field_names.index(count_vectorizer.get_input_col())
output_index = field_names.index(count_vectorizer.get_output_col())
print('Input Value: %-20s Output Value: %10s' %
(str(result[input_index]), str(result[output_index])))
DCT(离散余弦变换,Discrete Cosine Transform)是一种将信号从时域(或空域)转换到频域的方法。DCT用于表示数据(如图像和音频)中的模式和频率信息,广泛应用于数字信号处理、图像压缩、音频压缩等领域。
DCT的主要优点是具有良好的能量聚集性能,能将信号的大部分能量集中在较少的系数上。这使得DCT在压缩和去噪等应用中表现优异。
在图像处理中,最常用的DCT变种是二维DCT(2D-DCT)。它用于将图像分解为不同频率的子图像,包括直流分量(DC,低频信息,表示图像的整体亮度)和交流分量(AC,高频信息,表示图像的边缘和纹理等细节)。通过保留较少的系数并消除其他高频系数,可以实现图像的压缩。
JPEG图像压缩标准是DCT在图像压缩中的一个典型应用。JPEG压缩算法包括以下步骤:
颜色空间转换:将图像从RGB颜色空间转换为亮度和色度分量的颜色空间(如YCbCr)。
分块:将图像分割成8x8像素的小块。
二维DCT:对每个8x8像素块应用2D-DCT,得到相应的频率系数矩阵。
量化:根据预先定义的量化表对DCT系数进行量化,以减小高频系数的值并实现压缩。
熵编码:对量化后的系数进行编码(如哈夫曼编码),得到压缩后的数据。
在解压缩过程中,执行上述步骤的逆操作以恢复图像。需要注意的是,JPEG压缩是有损压缩,意味着在压缩过程中会丢失部分图像信息。根据压缩比和参数设置,压缩后的图像质量可能会受到影响。
双离合变速器 #
DCT 是一种 Transformer,它对实数向量进行一维离散余弦变换。不对输入向量执行零填充。它返回表示 DCT 的相同长度的实数向量。返回向量被缩放,使得变换矩阵是单一的(也称为缩放 DCT-II)。
输入列 #

编辑
添加图片注释,不超过 140 字(可选)
要进行余弦变换的输入向量。
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
余弦变换输出向量。
Parameters #

编辑切换为居中
添加图片注释,不超过 140 字(可选)

编辑
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.feature.dct.DCT;
import org.apache.flink.ml.linalg.Vector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
import java.util.Arrays;
import java.util.List;
/** 简单的程序,用于创建 DCT 实例并将其用于特征工程。 */
public class DCTExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
List<Vector> inputData =
Arrays.asList(
Vectors.dense(1.0, 1.0, 1.0, 1.0), Vectors.dense(1.0, 0.0, -1.0, 0.0));
Table inputTable = tEnv.fromDataStream(env.fromCollection(inputData)).as("input");
// 创建 DCT 对象并初始化其参数。
DCT dct = new DCT();
// 使用 DCT 对象进行特征转换。
Table outputTable = dct.transform(inputTable)[0];
// 提取并显示结果。.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
Vector inputValue = row.getFieldAs(dct.getInputCol());
Vector outputValue = row.getFieldAs(dct.getOutputCol());
System.out.printf("Input Value: %s\tOutput Value: %s\n", inputValue, outputValue);
}
}
}
ython
# 简单的程序,用于创建 DCT 实例并将其用于特征工程。
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.linalg import Vectors, DenseVectorTypeInfo
from pyflink.ml.feature.dct import DCT
from pyflink.table import StreamTableEnvironment
# create a new StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# create a StreamTableEnvironment
t_env = StreamTableEnvironment.create(env)
# generate input data
input_data = t_env.from_data_stream(
env.from_collection([
(Vectors.dense(1.0, 1.0, 1.0, 1.0),),
(Vectors.dense(1.0, 0.0, -1.0, 0.0),),
],
type_info=Types.ROW_NAMED(
['input'],
[DenseVectorTypeInfo()])))
# 创建 DCT 对象并初始化其参数。
dct = DCT()
# 使用 DCT 进行特征工程。
output = dct.transform(input_data)[0]
# 提取并显示结果。
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
input_value = result[field_names.index(dct.get_input_col())]
output_value = result[field_names.index(dct.get_output_col())]
print('Input Value: ' + str(input_value) + '\tOutput Value: ' + str(output_value))
ElementwiseProduct(逐元素乘积)是一种对向量或数组进行操作的方法,它将两个相同维度的向量或数组中的对应元素相乘。结果是一个与输入相同维度的向量或数组,其每个元素是输入向量或数组中相应元素的乘积。
例如,设有两个向量A和B:
A = [a1, a2, a3]
B = [b1, b2, b3]
ElementwiseProduct(A, B) 的结果为:
C = [a1 * b1, a2 * b2, a3 * b3]
这种操作在数学中通常称为哈达玛积(Hadamard product)或Schur积(Schur product),在机器学习、深度学习和数据分析等领域中广泛应用。它与点积(dot product)和矩阵乘法(matrix multiplication)等其他向量和矩阵操作有所不同。逐元素乘积保留了输入向量或数组的维度,而不会改变其结构
ElementwiseProduct #
ElementwiseProduct 使用 Hadamard 乘积将每个输入向量与给定的缩放向量相乘。如果输入向量的大小不等于缩放向量的大小,转换器将抛出 IllegalArgumentException。
Input Columns #

编辑
添加图片注释,不超过 140 字(可选)
要缩放的特征。
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
缩放功能。
Parameters #

编辑
添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.feature.elementwiseproduct.ElementwiseProduct;
import org.apache.flink.ml.linalg.Vector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
/**
* Simple program that creates an ElementwiseProduct instance and uses it for feature engineering.
*/
public class ElementwiseProductExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
DataStream<Row> inputStream =
env.fromElements(
Row.of(0, Vectors.dense(1.1, 3.2)), Row.of(1, Vectors.dense(2.1, 3.1)));
Table inputTable = tEnv.fromDataStream(inputStream).as("id", "vec");
// Creates an ElementwiseProduct object and initializes its parameters.
ElementwiseProduct elementwiseProduct =
new ElementwiseProduct()
.setInputCol("vec")
.setOutputCol("outputVec")
.setScalingVec(Vectors.dense(1.1, 1.1));
// Transforms input data.
Table outputTable = elementwiseProduct.transform(inputTable)[0];
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
Vector inputValue = (Vector) row.getField(elementwiseProduct.getInputCol());
Vector outputValue = (Vector) row.getField(elementwiseProduct.getOutputCol());
System.out.printf("Input Value: %s \tOutput Value: %s\n", inputValue, outputValue);
}
}
}
Python
# Simple program that creates an ElementwiseProduct instance and uses it for feature
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.linalg import Vectors, DenseVectorTypeInfo
from pyflink.ml.feature.elementwiseproduct import ElementwiseProduct
from pyflink.table import StreamTableEnvironment
# create a new StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# create a StreamTableEnvironment
t_env = StreamTableEnvironment.create(env)
# generate input data
input_data_table = t_env.from_data_stream(
env.from_collection([
(1, Vectors.dense(2.1, 3.1)),
(2, Vectors.dense(1.1, 3.3))
],
type_info=Types.ROW_NAMED(
['id', 'vec'],
[Types.INT(), DenseVectorTypeInfo()])))
# create an elementwise product object and initialize its parameters
elementwise_product = ElementwiseProduct() \
.set_input_col('vec') \
.set_output_col('output_vec') \
.set_scaling_vec(Vectors.dense(1.1, 1.1))
# use the elementwise product object for feature engineering
output = elementwise_product.transform(input_data_table)[0]
# extract and display the results
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
input_value = result[field_names.index(elementwise_product.get_input_col())]
output_value = result[field_names.index(elementwise_product.get_output_col())]
print('Input Value: ' + str(input_value) + '\tOutput Value: ' + str(output_value))