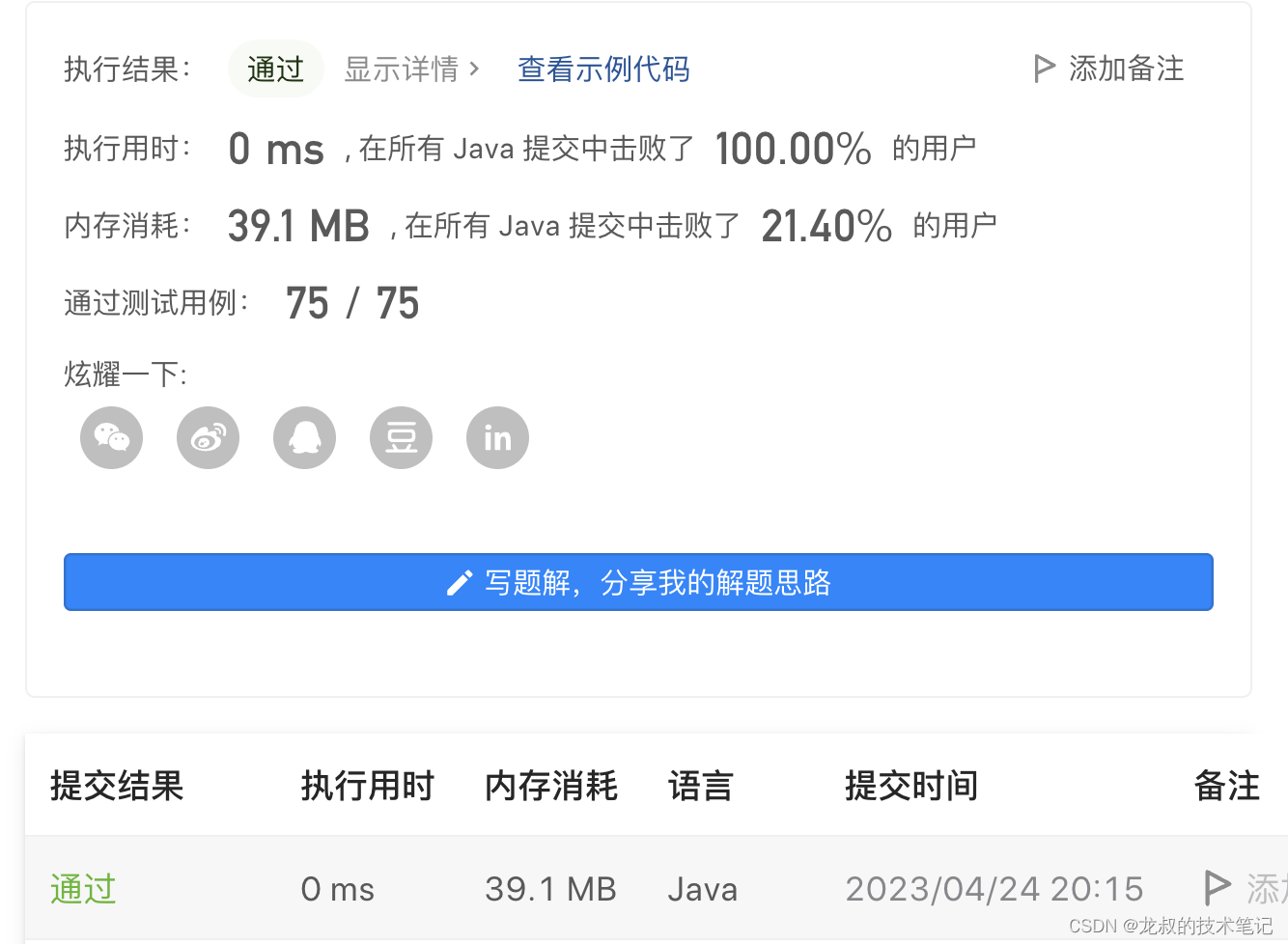
优点与缺点
优点
布隆过滤器的压缩有以下优点:
-
减少存储空间:布隆过滤器的基本结构是一个比特数组。如果使用传统的方式来表示比特数组,会占用大量的存储空间。当元素数量和误判率比较少的情况下,这样比特数组会占用过多的存储空间。而对比特数组进行压缩可以大幅减少存储空间的使用。
-
方便传输:在网络传输或者磁盘存储时,压缩布隆过滤器可以减少数据传输的时间和带宽占用,有助于提高程序的性能。
-
加速查询:压缩布隆过滤器可以减少读取数据的时间,提高查询的速度。在大规模数据查询的场景下,将布隆过滤器进行压缩可以显著提高查询速度。
缺点
-
压缩和解压缩的计算开销:压缩和解压缩布隆过滤器需要进行额外的计算,这会增加一定的计算开销。如果需要对大规模的布隆过滤器进行压缩和解压缩,则可能会影响查询的性能。
-
压缩后的误判率可能会发生变化:在对布隆过滤器进行压缩后,误判率可能会发生变化。因此,需要在设计布隆过滤器时充分考虑到压缩对误判率的影响,并根据实际需求来选择适当的误判率。
-
压缩后的数据无法动态更改:压缩布隆过滤器后,无法再直接对比特数组进行动态的
插入或删除操作,需要先将压缩后的数据解压缩还原为比特数组,然后再进行操作。因此,在设计布隆过滤器时需要考虑数据的可变性。
实现原理
是将其比特数组压缩为一个二进制数据流,具体的步骤如下:
- 将
布隆过滤器的比特数组拼接成一个长的二进制字符串(即将比特数组中的所有字节拼接成一个二进制字符串)。 - 对
二进制字符串进行压缩,常用的压缩算法有gzip、bzip2、LZ77/LZ78等。 - 将
压缩后的数据流与布隆过滤器的元数据一起保存到一个文件或传输到另一个系统中。 - 在解压时,
也需要先读取存储的元数据,根据元数据信息来还原布隆过滤器的比特数组。然后将比特数组用于查询元素是否存在于布隆过滤器中。
实现代码
实现
#include <iostream>
#include <vector>
#include <bitset>
using namespace std;
#include <zlib.h>
#include <string>
#include <xxhash.h>
// #include <MurmurHash3.h>
//在实际使用中,需要对每个哈希值进行分组,根据不同的压缩算法和参数进行压缩,将布隆过滤器压缩成字节数组,//在查询的时候,也需要进行解压缩,还原哈希值位比特数组class CompressBloomFilter
{
public:bitset<1024> bloomfilter_; //原始的布隆过滤器,用于数据的查询//压缩后的布隆过滤器及其相关的元数据
private:vector<char> compressData_; //压缩之后的数据uLongf compressed_size_ = 0; //被压缩之后的数据大小,uLongf,无符号浮点数uLongf uncompressed_size_ = 0; //还没被压缩之前的数据大小size_t count_ = 0;bool IsCompressed = false;public://往布隆过滤其中添加数据void add(const string &element){if (!IsCompressed){hash<string> h1;bloomfilter_.set(h1(element) % 1024); //设置进位图中// xxhash具有良好的分布型和低碰撞性unsigned long long hash = XXH32(element.c_str(), element.size(), 0); //这个是通过xxhash计算一个32位的hash值bloomfilter_.set(hash % 1024);count_++;}}//压缩void compress(){//如插入了{1,3,5}对应转化之后的就是101010string bitset_str = bloomfilter_.to_string(); //把位图变成一个字符串的形式(二进制的形式)//压缩位图中的数据uLongf buffersize = bitset_str.size();vector<char> buffer(buffersize, 0); //开buffersize个空间,每个空间上都是compress2((Bytef *)&buffer[0], &buffersize, (const Bytef *)bitset_str.c_str(), bitset_str.size(), Z_BEST_COMPRESSION);//记录压缩后的数据以及元数据,compressData_ = buffer; //现在bufer中的都是已经被压缩过的数据compressed_size_ = buffersize; //压缩的数据大小uncompressed_size_ = bitset_str.size(); //还没被压缩之前的数据IsCompressed = true;}//将压缩之后的bloom filter解压并还原成为比特数据bitset<1024> decompress(){//解压缩压缩后的数据uLongf buffersize = uncompressed_size_;vector<char> buffer(buffersize, 0); //把解压缩的数据放到这个buffer中//解压缩uncompress((Bytef *)&buffer[0], &buffersize, (const Bytef *)&compressData_[0], compressed_size_);//将解压缩后的数据转化成比特数组string uuncompressdata(buffer.begin(), buffer.end());bitset<1024> bitset(uuncompressdata); //使用字符串01串来初始化这个位图IsCompressed = false;return bitset; //直接返回一个位图}bool hashElement(const string &element){if (!IsCompressed){hash<string> h1;unsigned long long hash_ = XXH32(element.c_str(), element.size(), 0);return bloomfilter_.test(h1(element) % 1024) && bloomfilter_.test(hash_ % 1024);}return false;}//计数bloom filtersize_t size(){return count_;}
};使用示例
int main()
{CompressBloomFilter f;f.add("asd");//添加数据f.add("ddd");f.add("dddas");f.compress();//添加完进行压缩//压缩布隆过滤器处于压缩状态的时候,不能进行插入数据,因为此时布隆过滤器已经被压缩成二进制流了,插入数据后会影响数据的正确性f.add("123");cout<<f.hashElement("123")<<endl;//插入数据的时候,必须要保证处于解压缩状态f.bloomfilter_=f.decompress();//解压缩cout<<f.hashElement("f")<<endl;//判断数据的存在cout<<f.hashElement("asd")<<endl;cout<<f.hashElement("dddas")<<endl;cout<<f.hashElement("ddas")<<endl;cout<<f.hashElement("dddasdfas")<<endl;cout<<f.size()<<endl;return 0;
}使用场景
-
大规模数据查询:在需要对海量数据进行查询的场景下,使用布隆过滤器可以减少查询时间和计算开销。此时,如果可以通过压缩布隆过滤器来减少存储和传输的开销,可以进一步提高查询的效率。
-
分布式系统:在分布式系统中,经常需要对数据进行交换和传输。如果可以通过在布隆过滤器上应用压缩技术来减少
存储和传输的开销,可以提高系统的性能并降低网络带宽的使用。 -
内存受限的系统:在内存受限的系统中,使用布隆过滤器进行数据查询可以减少内存的使用,从而提高系统的性能。如果可以将布隆过滤器进行压缩,则可以进一步减少内存的使用。
-
低延迟的数据查询:在需要快速响应查询请求的场景下,使用布隆过滤器可以减少查询时间和计算开销。如果可以将布隆过滤器进行压缩,则可以进一步提高查询的速度和响应时间。因为多个位被压缩成了一个块,所以只需要进行依次哈希计算和一次位检查就可以判断某个元素是否存在
总之,布隆过滤器的压缩技术可以对存储、网络传输和计算等方面的开销进行优化,在数据查询、分布式计算和高性能系统等场景下具有广泛的应用前景。
redisBloom中就使用到了压缩布隆过滤器的方法,在需要存储和传输数据的时候,就对布隆过滤器进行压缩
传输的时候传输
bloom filter的位数组,元素个数和误判率,只需要把压缩后的位数组,元素个数,误判率进行发送即可,对方接收后进行解压缩