目录
一.引言
二.摘要 - ABSTRACT
三.介绍 - INTRODUCTION
四.相关工作 - RELATED WORK
1.因式分解机及其变体 - Factorization Machine and Its relevant variants
2. 基于深度学习的点击率模型 - Deep Learning based CTR Models
3.SENET Module
五.FiBiNet Model
1.SENET
- Squeeze 挤压
- Excitation 激发
- ReWeight 加权
2.Bilinear-Interaction
- Filed All Type
- Field Each Type
- Field Interaction Type
3.FiBiNet
- SENET Layer
- BiLinear-Interaction Layer
- Combination Layer
- Deep Model
六.实验 EXPERIMENTS
1.性能比较 [RQ1]
2.双线性相互作用层组合 [RQ2]
3.双线性相互作用的 Filed 类型(RQ3)
4.Hyper-parameter 参数实验 (RQ4)
5.消融实验 (RQ5)
七.总结
一.引言
FiBiNet 是新浪微博机器学习团队 2019 年发表在 RecSys19上的一项工作:FiBiNET: Combining Feature Importance and Bilinear feature Interaction for Click-Through Rate Prediction,其介绍了一种新的特征重要性和双线性特征交叉网络 FiBiNet 模型,本文对论文做简单回顾。
二.摘要 - ABSTRACT
广告和信息流排名对 Facebook 和新浪微博等许多互联网公司都至关重要。在许多现实世界的广告和 feed 排名系统中,点击率 (CTR) 预测扮演着核心角色。该领域提出了许多模型,如逻辑回归模型、基于树的模型、基于因式分解机器的模型和基于深度学习的CTR模型。
文章摘要中指出目前 CTR 的许多研究都是用简单的方法计算特征间的相互作用,如 Hadamard 积和内积,而很少考虑特征的重要性。本文提出了一种新的特征重要性和双线性特征交互网络 (FiBiNET) 模型,用于动态学习特征重要性和细粒度特征交互。
三.介绍 - INTRODUCTION
广告和信息流排名对 Facebook 和新浪微博等许多互联网公司来说至关重要。这些任务背后的主要技术是点击率预测,即CTR。早期 CTR 预估任务主要有下述算法:
- 逻辑回归 LR
- 多项式-2 Poly2
- 树模型 GBDT
- 贝叶斯模型 Navie Bayes
随着深度学习的发展,基于深度学习的 CTR 的预估算法也不断发布:
- FNN Factorization- machine - Supported neural Networks
- WDL Wide&Deep
- AFM attention Factorization Machines
- DeepFM
- XDeepFM
本文提出了一种动态学习特征重要性和细粒度特征交互的新模型 FiBiNET (Feature Importance and Bilinear Feature Interaction NETwork)。据我们所知,不同的特征对目标任务有不同的重要性。例如,当我们预测一个人的收入时,特征职业比特征爱好更重要。考虑到这一点,我们引入了一个压缩激励网络 (SENET) 来动态学习特征的权重。此外,特征交互是点击率预测领域的一个关键挑战,许多相关工作都采用 Hadamard 积和内积等简单的方法来计算特征交互。本文提出了一种新的细粒度方法来计算特征与双线性函数的相互作用。我们的主要贡献如下:
• SENET
受SENET在计算机视觉领域成功的启发,我们使用SENET机制来动态学习特征的权重。
• BiLinear Intercation
我们引入了三种类型的双线性交互层,以细粒度的方式学习特征交互。这也与之前的工作相反,前者计算的是与Hadamard积或内积的特征交互。
• SENET Combine BiLinear Intercation
将SENET 机制与双线性特征交互相结合,我们的浅层模型达到了 Criteo 和 Avazu 数据集上 FFM等浅层模型的最先进水平。
• DNN with SENET and BiLinear Intercation
为了进一步提高性能,我们将经典的深度神经网络 (DNN) 组件与浅层模型结合起来作为深层模型。深度 FiBiNET 在 Criteo 和 Avazu 数据集上的表现始终优于其他最先进的深度模型。
四.相关工作 - RELATED WORK
1.因式分解机及其变体 - Factorization Machine and Its relevant variants
因子分解机 (FM) 和场感知因子分解机 (FFM) 是两种最成功的 CTR 模型。FM 使用因子分解参数对变量之间的所有特征相互作用进行建模。它具有较低的时间复杂度和内存存储,它可以很好地处理大型稀疏数据。FFM 引入了场感知潜在向量,提高了模型的表达能力,但 FFM 受到大内存需求的限制,不容易在互联网公司中使用。
2. 基于深度学习的点击率模型 - Deep Learning based CTR Models
如何有效地对特征间的相互作用进行建模是近年来许多深度学习 CTR 模型的侧重点,下面总结了近年来常见得深度学习 CTR 预估模型:
FNN - 只能捕获高阶特征交叉作用
WDL - 宽部分的输入仍然需要专业特征工程,这意味着跨产品转换也需要手工设计
DeepFM - 用 FM 替换了 WDL 的宽部分,并在 FM 和 deep 组件之间共享特征嵌入
DCN - 深度交叉网络以显式方式有效地捕获有界度的特征交互
xDeepFM - 提出压缩交互网络 CIN,以一种显式的方式对低阶和高阶特征交互进行建模
AFM - 该模型使用注意网络来学习特征交互的权重,避免 FM 特征交叉等权重的问题
DIN - 用兴趣分布表示用户的多兴趣,引入注意力网络结构,根据候选广告在局部激活相关兴趣
可以看出推荐系统的发展经历了 人工特征组合 -> 自动特征组合、低阶特征交叉 -> 高阶特征交叉以及等权重预测 -> 加权预测的发展阶段。FiBiNet 于 2019 年提出,当下深度算法模型除了关注特征交叉外,还通过引入序列模型、因果推断、记忆模型等细化深度模型的表达能力。
3.SENET Module
Hu 提出了 "挤压-激励网络" (SENET),通过显式地建模各种图像分类任务中卷积特征通道之间的相互依赖关系,提高网络的表示能力。SENET在图像分类任务中被证明是成功的,并在 ILSVRC 2017分类任务中获得第一名,论文也引入 SENET 建模获取不同 Field 的重要性,解决了深度模型特征重要性不易解释的问题。
五.FiBiNet Model
FiBiNet 引入了两类特征交叉方式学习特征重要性:
• SENET
挤压激励网络 (SENET) 机制可以动态学习特征的重要性,即不同 Field 的重要性。
• Bilinear Interaction
使用双线性函数有效地学习特征间的相互作用,这里针对 Field 下的细分特征的重要性学习。
1.SENET
据我们所知,不同的特征对目标任务有不同的重要性。例如,当我们预测一个人的收入时,特征职业比特征爱好更重要。受 SENET 在计算机视觉领域成功的启发,我们引入了一种SENET机制,使模型更加关注特征的重要性。针对特定的CTR预测任务,我们可以通过 SENET 机制动态增加重要特征的权重,降低不重要特征的权重。
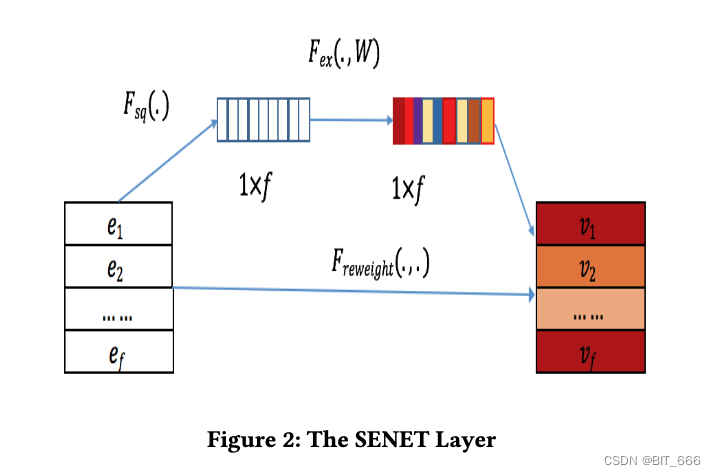
上图为论文中给出的 SENET 实现方式,共涉及 3 个部分:
- Squeeze 挤压
此步骤用于计算每个字段嵌入的 "汇总统计"。具体来说,我们使用 max 或 mean 等池化方法将原始 embedding = [e1,···,ef] 压缩成一个统计向量 Z = [z1,···,zi,···,zf],其中 i∈[1,···,f], zi 是表示第 i 个特征表示的全局信息的标量值。zi 可以计算为如下全局平均池化:
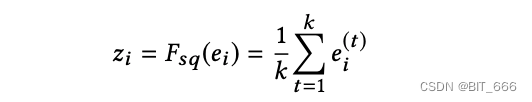
原始 SENET 论文中的挤压函数为 max pooling。然而,我们的实验结果表明,平均池化比最大池化性能更好。
- Excitation 激发
这一步可以用来学习基于统计向量 Z 的每个字段嵌入的权重。我们使用两个全连接 (FC) 层来学习权重。第一层 FC 为降维层,参数为 W1,降维比 r 为超参数,采用 σ1 作为非线性函数。第二个FC 层使用参数 W2 增加维数。形式上,场嵌入权值可计算如下:
![]()
其中 A∈Rf 为向量,σ1 和 σ2 为激活函数。
- ReWeight 加权
SENET 的最后一步是重权重步骤,在原论文中中称为重缩放。它在原域嵌入 E 和域权重向量 A 之间逐域相乘,输出新的嵌入 V = {v1,···,vi,···,vf}。类senet嵌入V的计算公式如下:
![]()
使用 multiply 直接把权重向量与原始 Embedding 相乘即可得到最终加权向量。
下面我们用详细的图描述下 SENET 的运作机制:
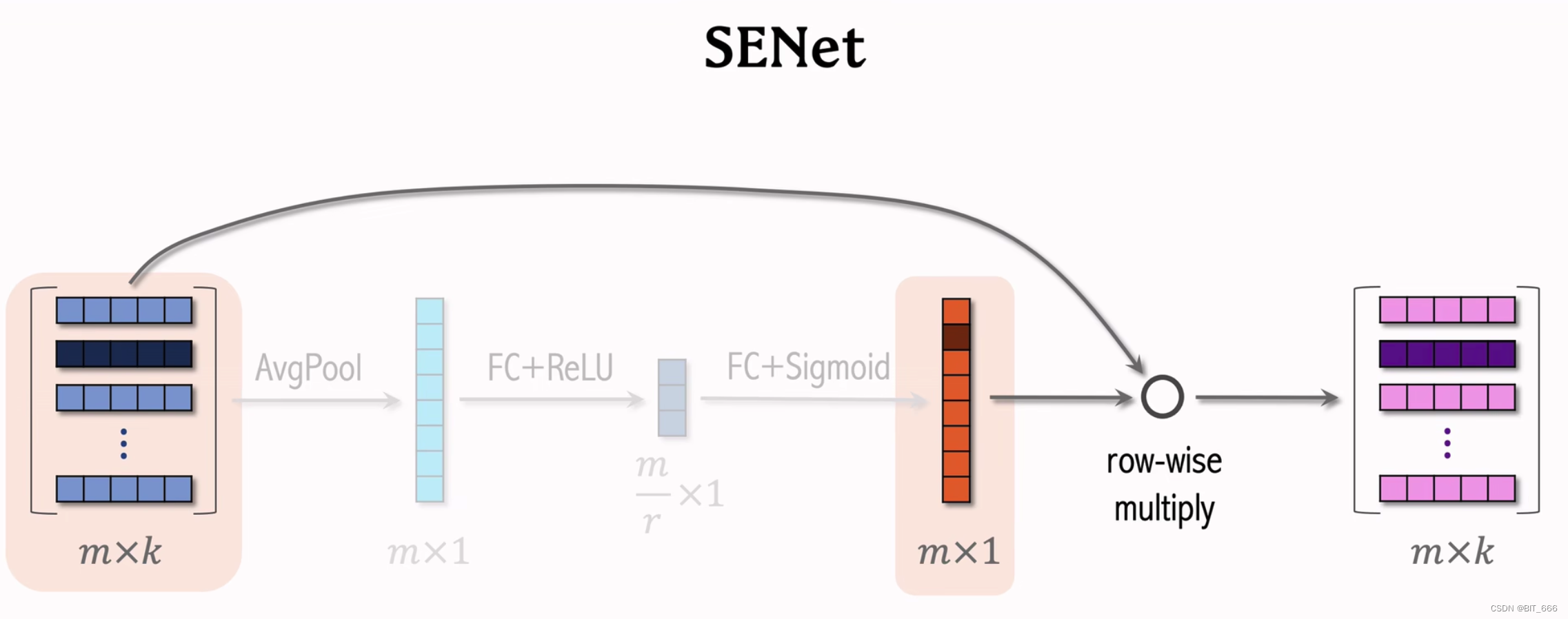
SENET 使用多个 Filed 特征的 Embeding 作为输入,通过 AvgPool 平均池化后获得 m x 1 的向量,随后通过 FC + Relu 对合并向量压缩,再使用 FC + Sigmoid 得到权重向量,然后通过 multiply 对原始 Embedding 向量加权。
Tips:
• Filed-Wise 加权
SENET 对离散特征做 Field-Wise 加权,这一点与前两天分析的 EGES 类似,其 Alpha 向量矩阵就是用于给不同 Field 即 Item 和侧信息 Embedding 不同权重。
• 输入输出相同
根据上面示意图可以看出 Input 维度为 mxk 输出维度依然为 mxk,这里 SENET 只负责动态 Field 加权。
2.Bilinear-Interaction
交互层是计算二阶特征交互的层。交互层特征交互的经典方法有内积和 Hadamard 积。内积广泛应用于 FM、FFM 等浅层模型,而 Hadamard 积则广泛应用于 AFM 和 NFM 等深层模型。内积和Hadamard积的形式分别表示为:
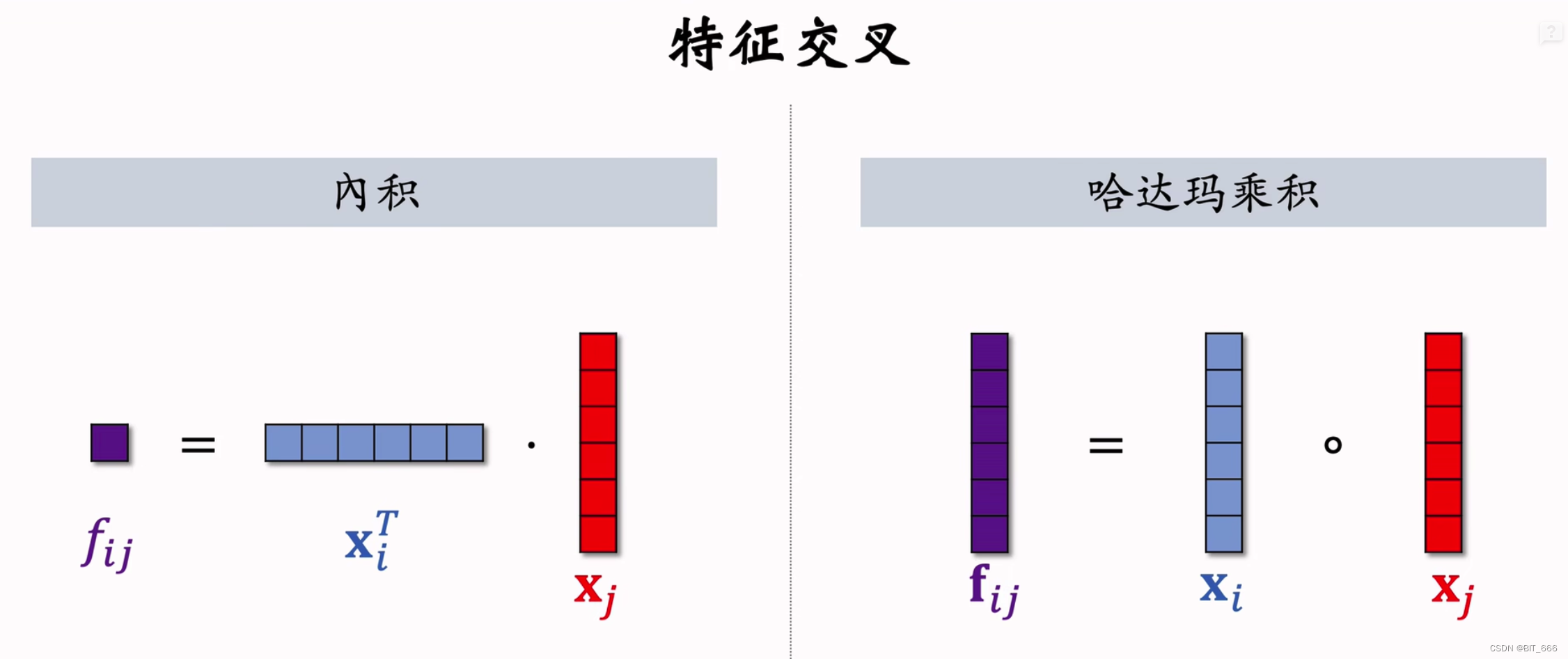
其中 · 表示正则内积,⊙ 表示Hadamard积,例如:
交互层中的内积和Hadamard积过于简单,无法有效地对稀疏数据集中的特征交互进行建模。因此,我们提出了一种更细粒度的方法,将内积和 Hadamard 积结合起来学习特征与额外参数的相互作用。
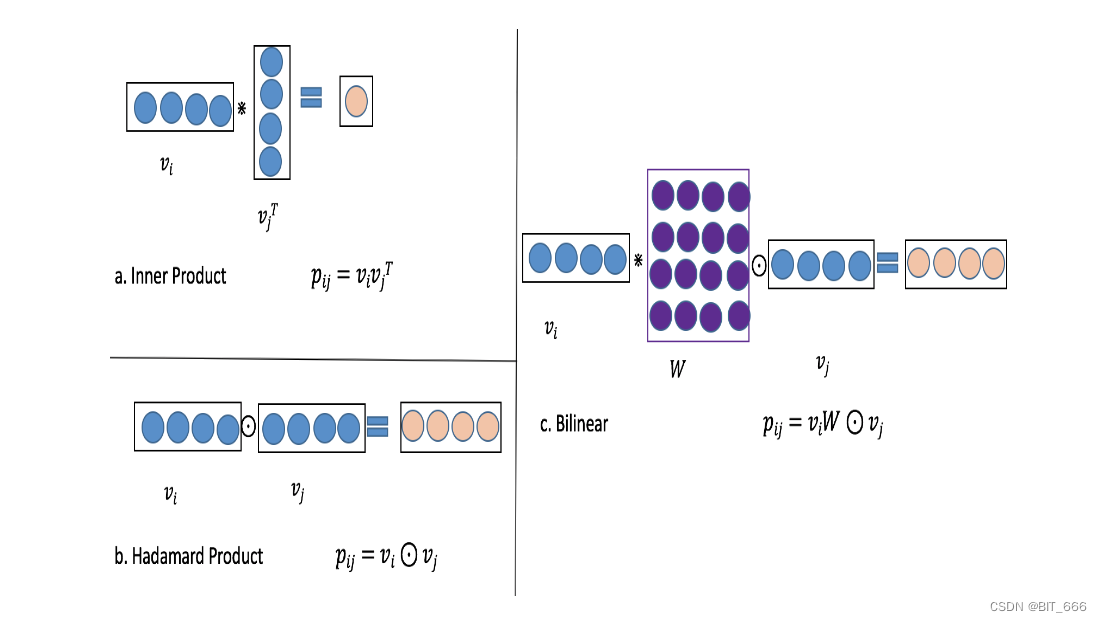
如上图所示,矩阵 W 与向量 vi 之间使用内积,矩阵 W 向量 vj 之间使用 Hadamard 积。具体来说,我们在这一层中提出了三种类型的双线性函数,并称之为双线性交互层。以第 i 个域嵌入 vi 和第 j 个域嵌入 vj 为例,特征交互的结果 Pij 可以分为三种情况:
- Filed All Type
![]()
此时所有交叉特征共享一个 KxK 的参数矩阵,K 为 Embedding 维度,共 K x K 个参数。
- Field Each Type
![]()
此时每个特征域 Field 维护一个参数矩阵 Wi,共 f x k x k 个参数。
- Field Interaction Type
![]()
此时每个 i-j 的特征组合维护一个参数矩阵 Wij,共 n x k x k 个参数,其中 n = (f-1) x f / 2。
3.FiBiNet
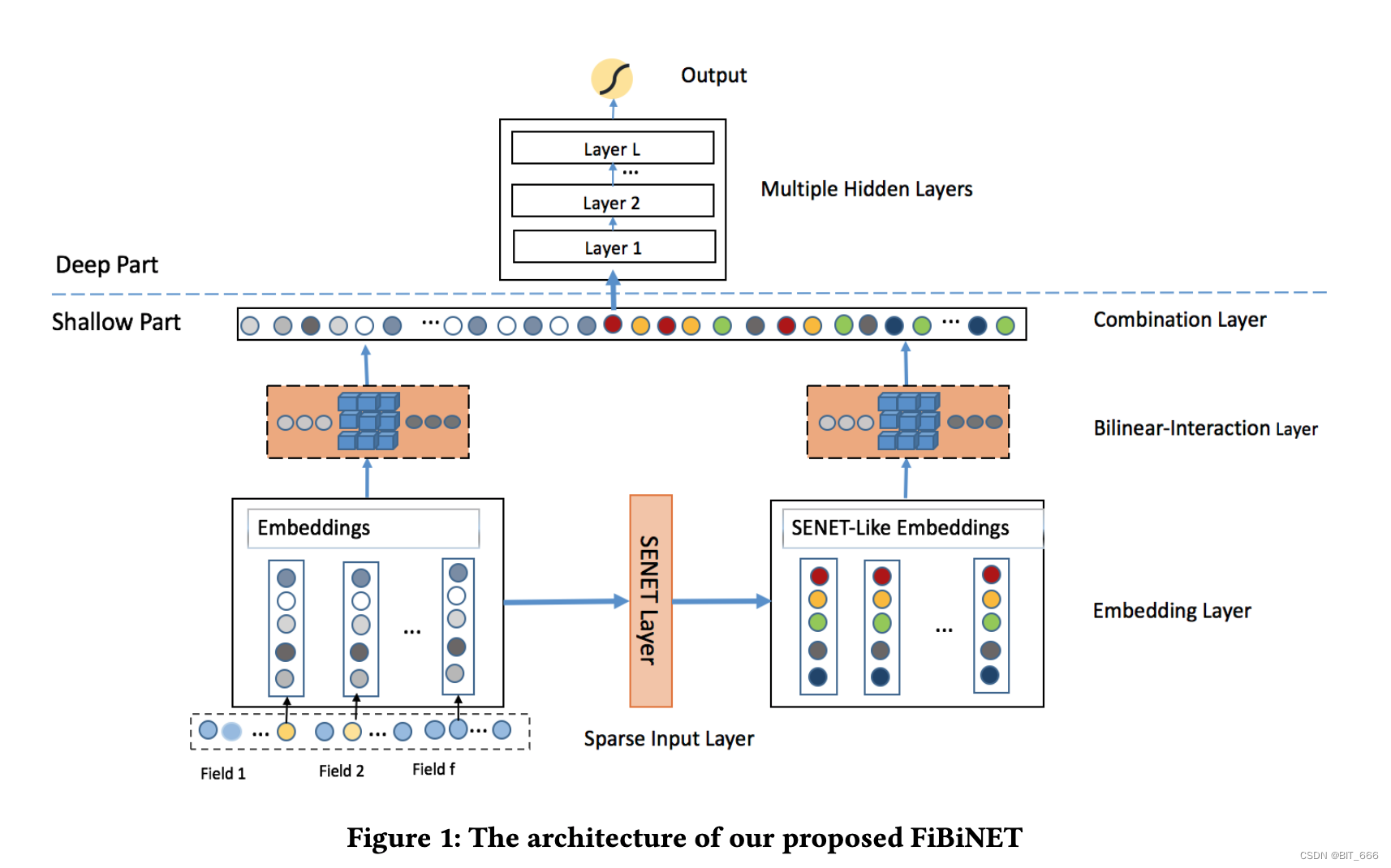
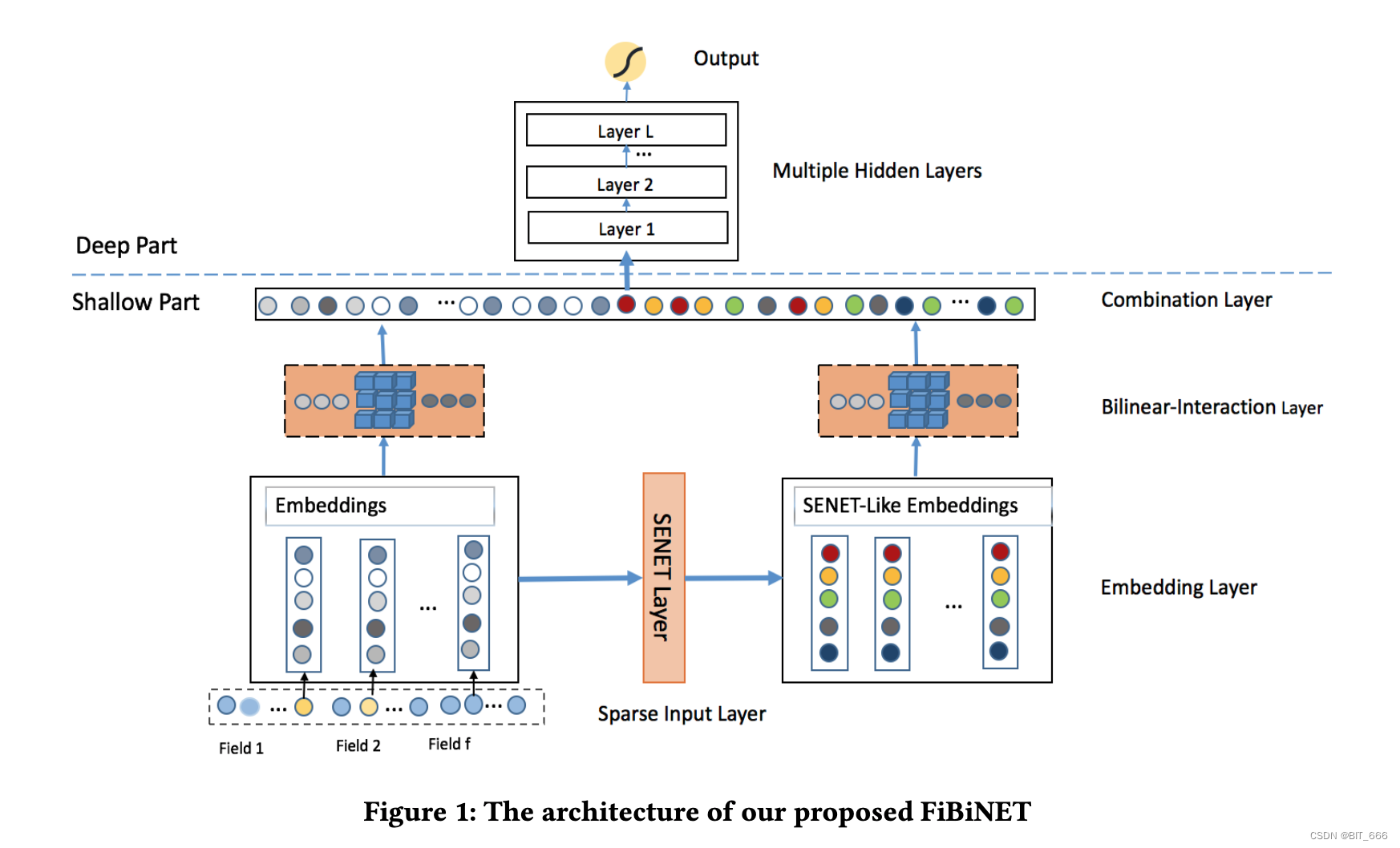
有了 SENET 和 BiLinear-Intercation 的知识,再看 FiBiNet 的架构图就很清晰了:
- SENET Layer
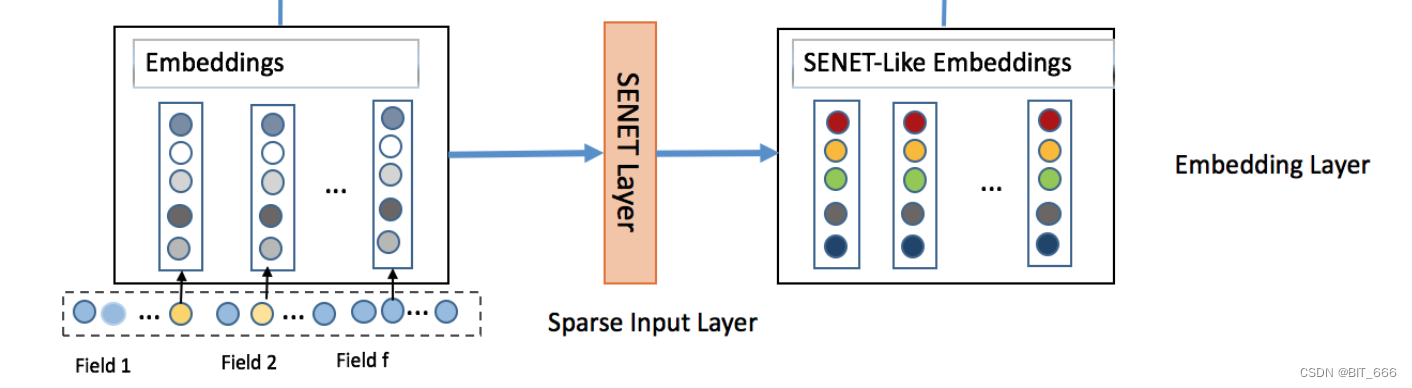
每个 Field 的特征 lookup 获取 M x K 维的 Embedding 向量,通过 SENET 对不同 Field 的 Embedding 加权生成与原始输入维度相同的 SENET-Like Embeddings,其维度同样为 M x K。
- BiLinear-Interaction Layer
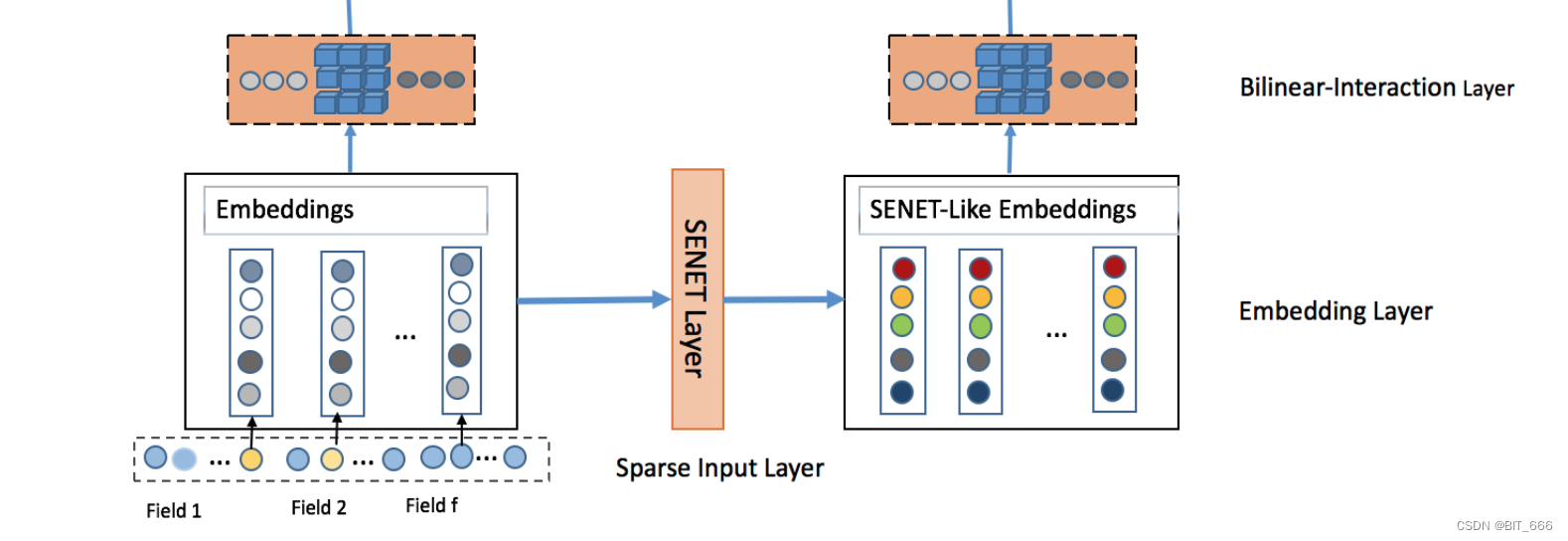
分别对 Embeddings 和 SENET-Like Embeddings 中的特征进行两两加权输出,假设输入的 Filed 数目为 n,则输出 (n-1) x n / 2 个加权的特征向量。其中 Embeddings 输出向量 p = [p1, p2 ... , pn],SENET-Like Embeddings 输出向量 q = [q1, q2, ... , qn]。
- Combination Layer

将 Embeddings 和 SENET-Like Embeddings 特征交互拼接并分别求和得到向量 c = [c1, c2, ..., c2n]:
![]()
针对每个特征组合的 Rk 向量进行求和,则 p1 ∈ Rk 可以得到一个标量,p、q 中各有 n 个向量,所以最后得到的 c 共有 2n 个元素。
- Deep Model
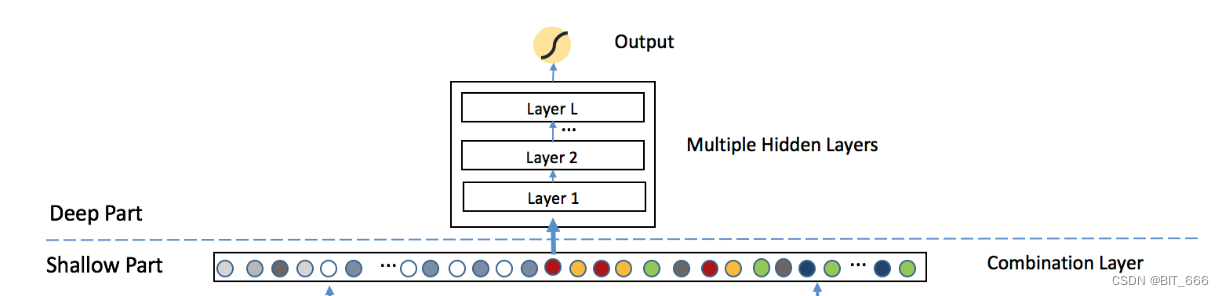
经过前面 SENET 的 Field 加权与 BiLinear Intercation 的二阶 Filed 交叉以及 Combination Layer 的合并,我们已经得到 c = [c1, c2, ... , c2n] 的输入向量,如果直接对 c 内元素求和再经过 sigmoid 我们就得到了一个浅层 CTR 预估模型,如果与 DNN 结合,则构成一个传统的深度网络结构,计算公式为:
![]()
其中 α 为激活函数,最后一层 Output 为 Sigmoid 输出,因为我们是 CTR 预估模型:
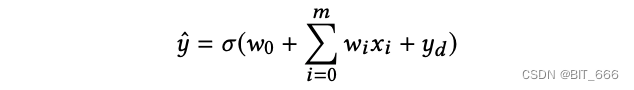
对应的损失函数为交叉熵 Cross Entropy:
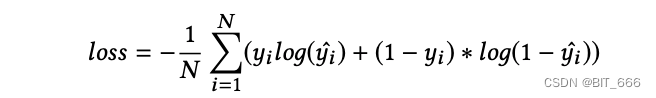
六.实验 EXPERIMENTS
在本节中,我们进行了大量的实验来回答以下问题:
(RQ1) 与目前最先进的CTR预测方法相比,我们的模型表现如何?
(RQ2) 双线性交互层中双线性和Hadamard函数的不同组合是否会影响其性能?
(RQ3) 双线性交互层的不同字段类型(field - all、field - each和field - interaction)会影响其性能吗?
(RQ4) 网络的设置如何影响我们的模型的性能?
(RQ5) FiBiNET中最重要的组件是什么?
Tips:数据、评估、对照与实践
- 实验数据 DataSets
Criteo 数据集被广泛应用于许多 CTR 模型评价中。它包含有 4500 万个数据实例的点击日志。Criteo数据集中有 26 个匿名分类字段和 13 个连续特征字段。我们将数据集随机分为两部分:90%用于训练,其余用于测试。
Avazu 数据集由几天的广告点击率数据组成,按时间顺序排列。它包含有 4000 万个数据实例的点击日志。对于每个点击数据,有 24 个字段表示单个广告印象的元素。我们将其随机分成两部分: 80% 用于培训,其余用于测试。
- 评估 Evaluation Metrics
在我们的实验中,我们采用了两个指标: AUC (Area Under ROC) 和 Log loss。AUC : ROC曲线下面积是评价分类问题中广泛使用的度量。此外,一些工作证实 AUC 是一个很好的 CTR 预测指标。AUC对分类阈值和阳性比值不敏感。AUC 的上界为 1,且越大越好。对数损失 : 对数损耗是二进制分类中广泛使用的度量,用于测量两个分布之间的距离。日志损失的下界为 0,表示两个分布完全匹配,值越小性能越好。
- 对照基准 Baseline Methods
为了验证 SENET 层与双线性交互层结合在浅模型和深模型中的有效性,我们将实验分为浅组和深组。我们还将基线模型分为两部分: 浅基线模型和深基线模型。浅基线模型包括 LR (logistic回归)、FM、FFM、AFM,深基线模型包括 FNN、DCN、DeepFM、XDeepFM。需要注意的是,AUC 提高 1‰ 通常被认为对 CTR 预测很重要,因为如果公司拥有非常大的用户基础,它将为公司带来大量的收入增长。
- 实施细节 Implementation Details
我们在实验中用 Tensorflow 实现了所有的模型。对于嵌入层,Criteo 数据集的嵌入层维数设置为10,Avazu数据集的嵌入层维数设置为 50。对于优化方法,我们使用 Adam,对于 Criteo 数据集的 mini-batch 大小为1000,对于 Avazu 数据集的 mini-batch 大小为 500,学习率设置为 0.0001。对于所有深度模型,层的深度设置为 3,所有的激活函数都是 RELU,每层神经元的数量为 400,对于 Criteo 数据集和 Avazu 数据集,每层神经元的数量分别为 400 和 2000,Dropout 率设置为 0.5。对于 SENET 部分,两个 FC 中的激活函数为 RELU 函数,还原比设置为 3。我们使用 2 个Tesla K40 GPU 进行实验。
1.性能比较 [RQ1]
- 浅模型在 Criteo 和 Avazu 测试集上的总体性能:
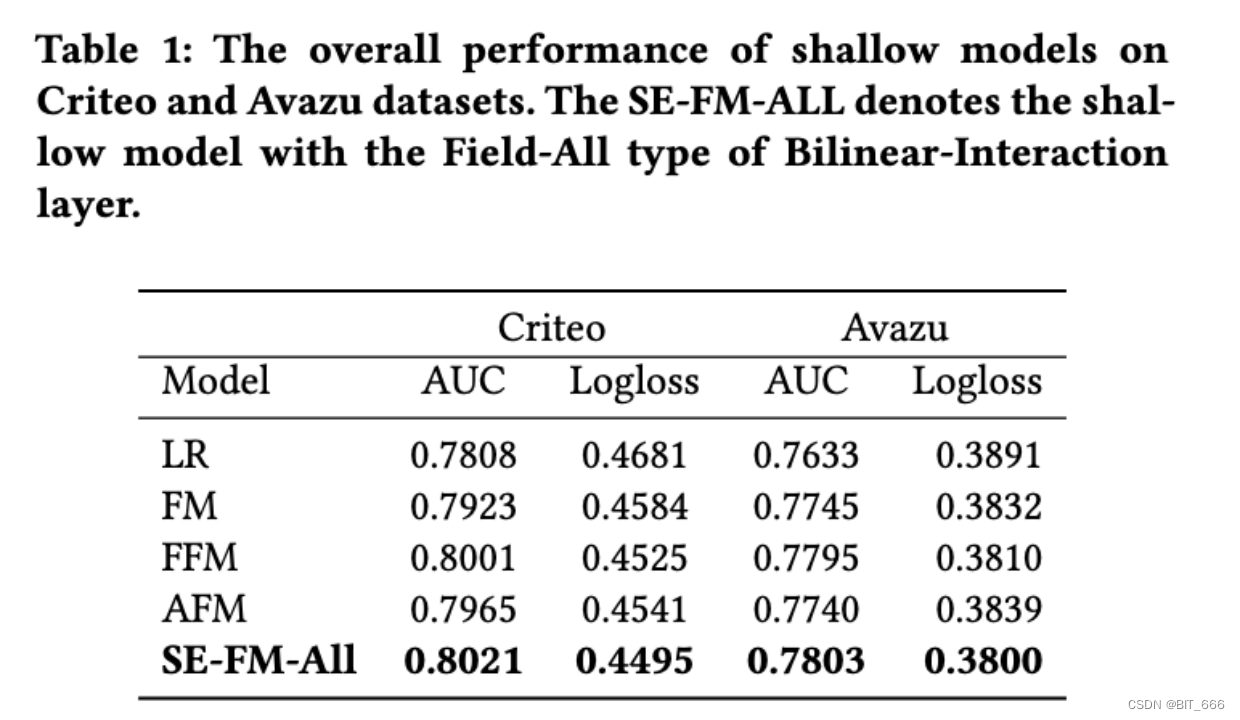
表1显示了浅层模型在 Criteo 和 Avazu 数据集上的结果。我们发现我们的浅 SE-FM-All 模型始终优于 FM、FFM、AFM 等其他模型。研究结果表明,将 SENET 机制与稀疏特征上的双线性相互作用相结合,对于许多真实数据集是一种有效的方法;另一方面,对于经典的浅模型,目前最先进的模型是 FFM 模型,但受大内存需求的限制,不容易在互联网公司中使用,我们的浅模型参数较少,但性能仍然优于 FFM。因此,它可以作为FFM的一种替代方案。
- 深模型在 Criteo 和 Avazu 测试集上的总体性能
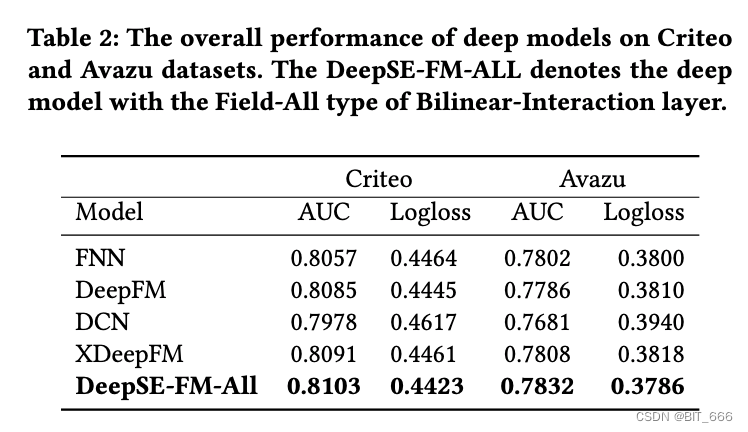
为了进一步提高性能,我们将浅层部分和 DNN 结合成一个深层模型。我们有以下观察结果:
• 深层网络可以进一步提高性能
将浅层部分和深度神经网络结合成一个统一的模型,可以进一步提高浅层模型的性能。从实验结果可以推断,隐式的高阶特征交互有助于浅层模型获得更强的表达能力。
• AUC 提升、Log Loss 减少
在所有的比较方法中,我们提出的深度FiBiNET达到了最好的性能。在Criteo和Avazu数据集上,我们的深度模型在AUC方面比FNN高出0.571%和0.386%(对数损失方面分别为0.918%和0.4%),在AUC方面比DeepFM高出0.222%和0.59%(对数损失方面分别为0.494%和0.6%)。
• SENET 与 BiLinear Intercation 结合的有效性
结果表明,将 SENET 机制与 DNN 中的双线性相互作用相结合进行预测是有效的。一方面,SENET 本质上引入了以输入为条件的动态,有助于提高特征的可判别性;另一方面,与传统的内积或 Hadamard 积等其他方法相比,双线性函数是一种有效的特征交互建模方法。
2.双线性相互作用层组合 [RQ2]
在本节中,我们将讨论在双线性交互层中,双线性函数与 Hadamard 积之间不同类型组合的影响。为了方便起见,我们用 0 和 1 表示在双线性交互层中使用哪个函数。"1" 表示使用双线性函数,"0" 表示使用 Hadamard积。我们有两个嵌入,所以使用了两个数字。第一个数字表示原始嵌入时使用的特征交互方法,第二个数字表示 SENET-Like 嵌入时使用的特征交互方法。例如,"10" 表示在原始嵌入上使用双线性函数作为特征交互方法,而在 SENET-Like 嵌入上使用 Hadamard 函数作为特征交互方法。同样,我们对浅层和深层模型进行了实验,并将结果汇总在下表:

• 浅层模型在不同数据集表现有差异
在 Criteo 数据集上,组合 "11" 在浅层模型中优于其他类型的组合。然而,组合 "11" 在 Avazu 数据集表现不佳。
• 深度模型首选 "01"
在深度模型中首选的组合应该是 "01",这种组合意味着双线性函数仅应用于 Senet-Like 嵌入层,这有利于在我们的模型中设计有效的网络体系结构。
3.双线性相互作用的 Filed 类型(RQ3)
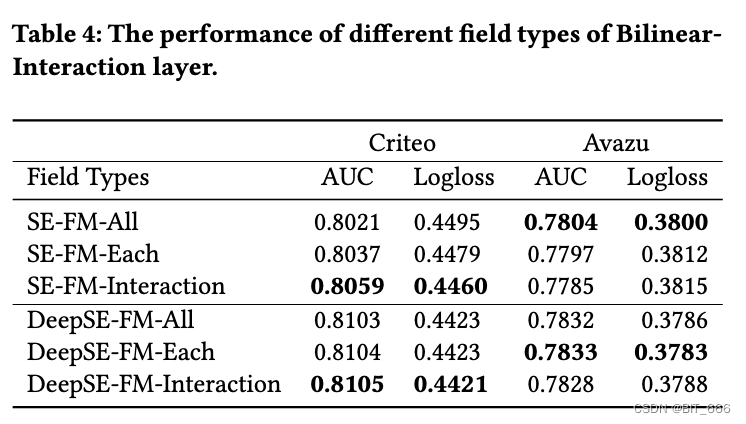
该实验主要分析 ALL、Each 与 Interaction 的表现差异:
• 浅层模型结果
对于浅层模型,与我们浅层模型的 Field-All 类型相比,Field-Interaction 类型在 Criteo 数据集上的AUC 提高了 0.382% (相对于0.476%)。
• 深度模型结果
对于深度模型,Field-Interaction 在 Criteo 数据集与 Field-Each 在 Avazu 数据集,可以分别获得一些改进。
4.Hyper-parameter 参数实验 (RQ4)
FiBiNET 中主要包含嵌入部分和 DNN 部分的参数。具体实验修改了:
- Embeddign 维度
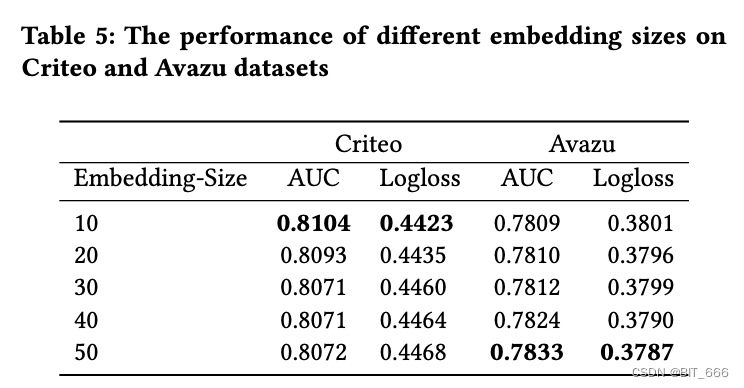
在不同数据集上,由于模型的复杂程度不同,需要 Emb 嵌入表达的信息也不同,所以维度有差异。
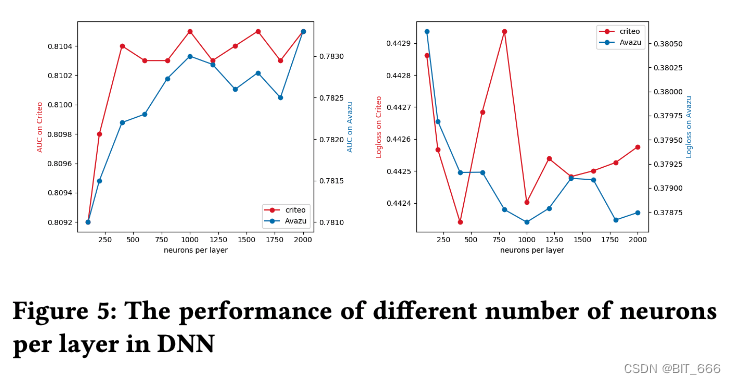
- DNN 每层神经元数量
对于 Avazu 数据集和 Criteo 数据集,将隐藏层的数量设置为 3 是一个不错的选择,因为此时 AUC 是最高的,且 LogLoss 相对较低。
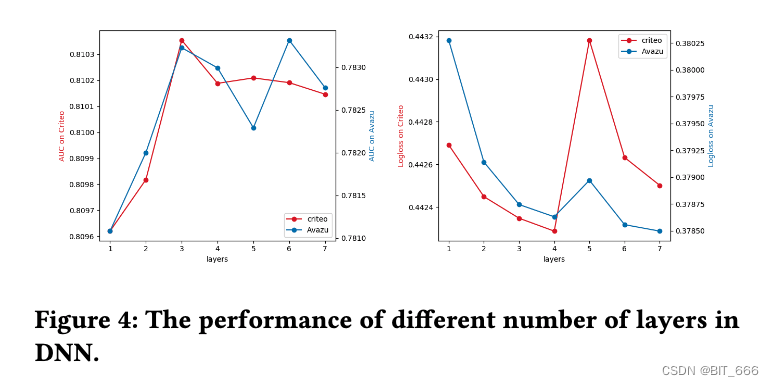
- DNN 深度
对于 Criteo 数据集每层设置 400 个神经元,Avazu 数据集每层设置 2000 个神经元效果更好,这同样与样本复杂度与模型表达能力相关。
5.消融实验 (RQ5)
该实验用于探索 FiBiNET 的每个组成部分的贡献。消融实验将 "deep - fm - interaction" 作为基本模型,并以以下方式执行:
1) No BI: 从 FiBiNET 中删除双线性交互层
2) No SE: 从 FiBiNET中删除 SENET 层。
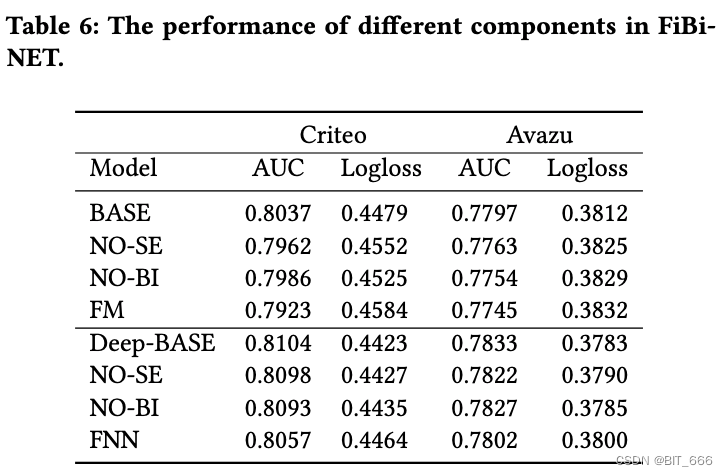
• 有效性
双线性交互层和 SENET 层都是 FiBiNET 性能所必需的。可以看到当我们删除任何组件时性能都会明显下降。
• 重要性
双线性交互层与 FiBiNET 中的 SENET 层一样重要。
Tips:
如果我们去掉 SENET 层和双线性交互层,我们的浅 FiBiNET 和深 FiBiNET 将降级为 FM 和FNN。
七.总结
FiBiNET (特征重要性和双线性特征交互网络),旨在动态学习特征重要性和细粒度特征交互:
• SENET 模块动态学习不同 Field 重要性
• 引入了 All、Each、Interaction 三种线性交互层学习特征交互
• 将 SENET 机制与双线性机制特征交互结合的浅层模型优于 FM 和 FFM 等浅层模型
• 为了进一步提高性能,将上述浅层模型与 DNN 结合得到 FiBiNet 由于 DeepFm 和 XdeepFm 等深层模型
上述特征交互方式使用不同的矩阵交叉特征在 FwFM、DCN-V2 中也有提及。本文一方面学到了两种新的特征重要性表征方法,另一方面通过最后第六章的实验,我们也可以看到如何调整参数并评估一个线上模型的表现在什么时候达到最佳。
论文参考:https://arxiv.org/abs/1905.09433
FiBiNet 讲解:特征交叉04:SENet 和 Bilinear 交叉