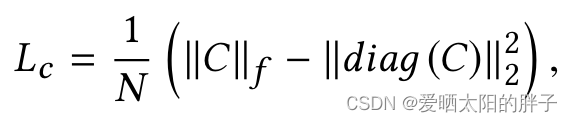在大数据集群数据迁移的项目中涉及到很多技术细节,本博客记录了迁移的大致的操作步骤。
迁移借用Hadoop自带的插件:distcp。
一、Hadoop集群数据迁移
**DistCp(分布式拷贝)**是用于大规模集群内部和集群之间拷贝的工具。它使用Map/Reduce实现文件分发(DistCp原理是在Hadoop集群中使用MapReduce分布式拷贝数据),错误处理和恢复,以及报告生成。它把文件和目录的列表作为map任务的输入,每个任务会完成源列表中部分文件的拷贝。
1. 迁移之前需要考虑的问题
- 迁移总数据量有多少?
- 新老集群之间的带宽有多少?能否全部用完?为了减少对线上其他业务的影响最多可使用多少带宽?
- 如何限制迁移过程中使用的带宽?
- 迁移过程中,哪些文件可能发生删除,新增数据的情况?新数据和旧数据怎么处理?哪些目录可能会发生新增文件的情况?
- 迁移后的数据一致性校验怎么做?
- 迁移后的HDFS文件权限如何跟老集群保持一致?
2. 迁移方案
1、迁移数据量评估
通过hdfs dfs -du -h / 命令查看各目录总数据量。按业务划分,统计各业务数据总量。
2、制定迁移节奏
由于数据量大,带宽有限,HDFS中的文件每天随业务不断变化,所以在文件变化之前全部迁移完成是不现实的。建议按业务、分目录、分批迁移。
3、迁移工具选择
使用Hadoop自带数据迁移工具Distcp,只需要简单的命令即可完成数据迁移。
命令示意:
hadoop distcp hdfs://nn1:8020/data hdfs://nn2:8020/
4、迁移时间评估
由于老集群每天仍然在使用,为了减小对线上业务的影响,尽量选择老集群低负载运行的时间段来进行数据迁移
5、对新老集群之间的网络进行硬件改造
咨询运维同学,新老集群之间的最大传输带宽是多少,如果带宽跑满的话会不会影响线上其他业务。能否对新老集群之间的网络进行硬件改造,例如通过新老集群之间搭网线的方式来提升网络传输的带宽并消除对其他线上业务的影响。
6、数据迁移状况评估
在完成上面所有准备之后,先尝试进行小数据量的迁移,可以先进行100G的数据迁移、500G的数据迁移、1T的数据迁移,以评估数据迁移速率并收集迁移过程中遇到的问题。
3. 迁移工具Distcp
工具使用很简单,只需要执行简单的命令即可开始数据迁移,可选参数如下:
hadoop distcp 源HDFS文件路径 目标HDFS文件路径
同版本集群拷贝(或者协议兼容版本之间的拷贝)使用HDFS协议
hadoop distcp hdfs://src-name-node:3333/user/src/dir hdfs://dst-namenode:4444/user/dst/dir
不同版本集群拷贝(比如1.x到2.x)使用hxp协议或者webhdfs协议,都是使用hdfs的HTTP端口
hadoop distcp hftp://src-name-node:80/user/src/dir hftp://dst-namenode:80/user/dst/dir
hadoop distcp webhdfs://src-name-node:80/user/src/dir webhdfs://dst-namenode:80/user/dst/dir
1、Distcp的原理
Distcp的本质是一个MapReduce任务,只有Map阶段,没有Reduce阶段,具备分布式执行的特性。在Map任务中从老集群读取数据,然后写入新集群,以此来完成数据迁移。
2、迁移期间新老两个集群的资源消耗是怎样的?
Distcp是一个MapReduce任务,如果在新集群上执行就向新集群的Yarn申请资源,老集群只有数据读取和网络传输的消耗。
3、如何提高数据迁移速度?
Distcp提供了 -m 参数来设置map任务的最大数量(默认20),以提高并发性。注意这里要结合最大网络传输速率来设置。
4、带宽如何限制?
Distcp提供了 -bandwidth 参数来控制单个Map任务的最大带宽,单位是MB。
5、迁移之后的数据一致性怎么校验?
Distcp负责进行CRC校验,可以通过-skipcrccheck参数来跳过校验来提供性能。
6、迁移之后的文件权限是怎样的?
Distcp提供了 -p 参数来在新集群里保留状态(rbugpcaxt)(复制,块大小,用户,组,权限,校验和类型,ACL,XATTR,时间戳)。如果没有指定 -p 参数,权限是执行MapReduce任务的用户权限,迁移完成以后需要手动执行chown命令变更。
7、迁移的过程中老集群目录新增了文件,删除了文件怎么办?
把握好迁移节奏,尽量避免这些情况的出现。Distcp在任务启动的时候就会将需要copy的文件列表从源HDFS读取出来。如果迁移期间新增了文件,新增的文件会被漏掉。删除文件会导致改文件copy失败,可以通过 -i参数忽略失败。
8、迁移中遇到文件已存在的情况怎么办?
Distcp提供了-overwrite 参数来覆盖已存在的文件。
9、迁移了一半,任务失败了怎么办?
删除掉新集群中的脏数据,重新执行迁移命令。不加-overwrite参数,来跳过已存在的文件。
10、遇到需要对一个文件增量同步怎么办?
Distcp提供-append参数将源HDFS文件的数据新增进去而不是覆盖它。
二、迁移步骤演示
1)准备两套集群,我这使用apache集群和CDH集群。
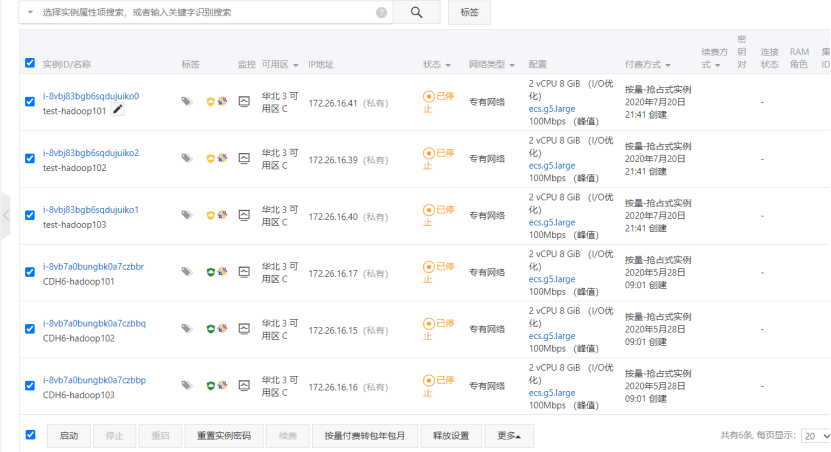
2)启动集群
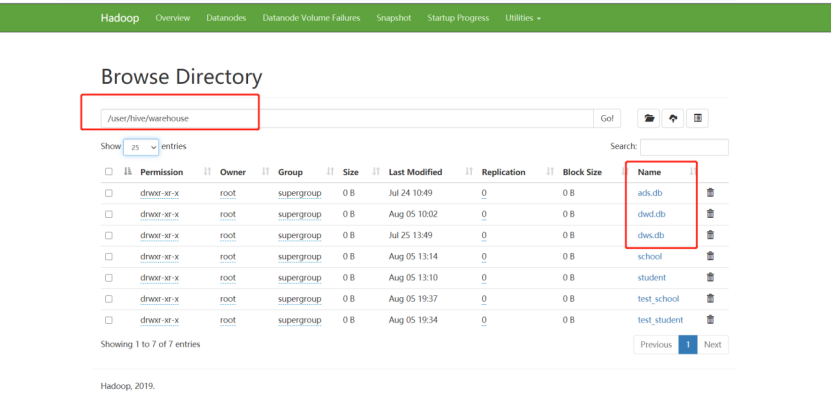
3)启动完毕后,将apache集群中,hive库里dwd,dws,ads三个库的数据迁移到CDH集群
4)在apache集群里hosts加上CDH Namenode对应域名并分发给各机器
[root@hadoop101 ~]# vim /etc/hosts
[root@hadoop101 ~]# scp /etc/hosts hadoop102:/etc/ [root@hadoop101 ~]# scp /etc/hosts hadoop103:/etc/
5)因为集群都是HA模式,所以需要在apache集群上配置CDH集群,让distcp能识别出CDH的nameservice
[root@hadoop101 hadoop]# vim /opt/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml <!--配置nameservice-->
<property><name>dfs.nameservices</name><value>mycluster,nameservice1</value>
</property><!--指定本地服务-->
<property><name>dfs.internal.nameservices</name><value>mycluster</value>
</property><!--配置多NamenNode-->
<property><name>dfs.ha.namenodes.mycluster</name><value>nn1,nn2,nn3</value>
</property><property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>hadoop101:8020</value>
</property><property><property><name>dfs.namenode.rpc-address.mycluster.nn2</name><value>hadoop102:8020</value>
</property><property><name>dfs.namenode.rpc-address.mycluster.nn3</name><value>hadoop103:8020</value>
</property><!--配置nameservice1的namenode服务--><property><name>dfs.ha.namenodes.nameservice1</name><value>namenode30,namenode37</value></property><property><name>dfs.namenode.rpc-address.nameservice1.namenode30</name><value>hadoop104:8020</value></property>
<property><name>dfs.namenode.rpc-address.nameservice1.namenode37</name><value>hadoop106:8020</value></property><property><name>dfs.namenode.http-address.nameservice1.namenode30</name><value>hadoop104:9870</value></property><property><name>dfs.namenode.http-address.nameservice1.namenode37</name><value>hadoop106:9870</value></property><property><name>dfs.client.failover.proxy.provider.nameservice1</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><!--为NamneNode设置HTTP服务监听--><property><name>dfs.namenode.http-address.mycluster.nn1</name><value>hadoop101:9870</value>
</property><property><name>dfs.namenode.http-address.mycluster.nn2</name><value>hadoop102:9870</value>
</property><property><name>dfs.namenode.http-address.mycluster.nn3</name><value>hadoop103:9870</value>
</property><!--配置HDFS客户端联系Active NameNode节点的Java类--><property><name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
6)修改CDH hosts
[root@hadoop101 ~]# vim /etc/hosts
7)进行分发,这里的hadoop104,hadoop105,hadoop106分别对应apache的hadoop101,hadoop102,hadoop103
[root@hadoop101 ~]# scp /etc/hosts hadoop102:/etc/
[root@hadoop101 ~]# scp /etc/hosts hadoop103:/etc/
8)同样修改CDH集群配置,在所有hdfs-site.xml文件里修改配置
<property><name>dfs.nameservices</name><value>mycluster,nameservice1</value>
</property><property><name>dfs.internal.nameservices</name><value>nameservice1</value>
</property><property><name>dfs.ha.namenodes.mycluster</name><value>nn1,nn2,nn3</value>
</property><property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>hadoop104:8020</value>
</property><property><name>dfs.namenode.rpc-address.mycluster.nn2</name><value>hadoop105:8020</value>
</property><property><name>dfs.namenode.rpc-address.mycluster.nn3</name><value>hadoop106:8020</value>
</property><property><name>dfs.namenode.http-address.mycluster.nn1</name><value>hadoop104:9870</value>
</property><property><name>dfs.namenode.http-address.mycluster.nn2</name><value>hadoop105:9870</value>
</property><property><name>dfs.namenode.http-address.mycluster.nn3</name><value>hadoop106:9870</value>
</property><property><name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property>
9)最后注意:重点由于Apahce集群和CDH集群3台集群都是hadoop101,hadoop102,hadoop103所以要关闭域名访问,使用IP访问
CDH把钩去了
10)apache设置为false
11)再使用hadoop distcp命令进行迁移,-Dmapred.job.queue.name指定队列,默认是default队列。上面配置集群都配了的话,那么在CDH和apache集群下都可以执行这个命令
[root@hadoop101 hadoop]# hadoop distcp -Dmapred.job.queue.name=hive webhdfs://mycluster:9070/user/hive/warehouse/dwd.db/ hdfs://nameservice1/user/hive/warehouse
12)会启动一个MR任务,正在迁移
13)查看cdh 9870 http地址
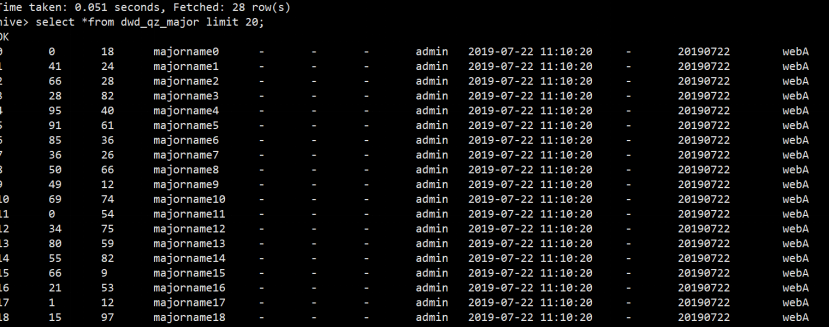
14)数据已经成功迁移。数据迁移成功之后,接下来迁移hive表结构,编写shell脚本
[root@hadoop101 module]# vim exportHive.sh #!/bin/bashhive -e "use dwd;show tables">tables.txtcat tables.txt |while read eachlinedohive -e "use dwd;show create table $eachline">>tablesDDL.txtecho ";" >> tablesDDL.txtdone
15)执行脚本后将tablesDDL.txt文件分发到CDH集群下
[root@hadoop101 module]# scp tablesDDL.txt hadoop104:/opt/module/
16)然后CDH下导入此表结构,先进到CDH的hive里创建dwd库
[root@hadoop101 module]# hive
hive> create database dwd;
17)创建数据库后,边界tablesDDL.txt在最上方加上use dwd;
18)并且将createtab_stmt都替换成空格
[root@hadoop101 module]# sed -i s"#createtab_stmt# #g" tablesDDL.txt
19)最后执行hive -f命令将表结构导入
[root@hadoop101 module]# hive -f tablesDDL.txt
20)最后将表的分区重新刷新下,只有刷新分区才能把数据读出来,编写脚本
[root@hadoop101 module]# vim msckPartition.sh
#!/bin/bashhive -e "use dwd;show tables">tables.txtcat tables.txt |while read eachlinedohive -e "use dwd;MSCK REPAIR TABLE $eachline"done[root@hadoop101 module]# chmod +777 msckPartition.sh [root@hadoop101 module]# ./msckPartition.sh
21)刷完分区后,查询表数据